分享知识-快乐自己:论Hibernate中的缓存机制
Hibernate缓存
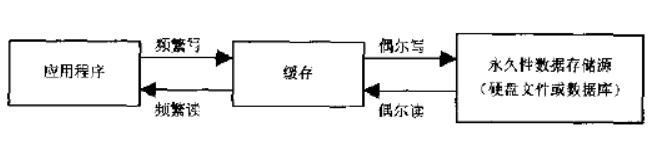
缓存:
是计算机领域的概念,它介于应用程序和永久性数据存储源之间。
缓存:
一般人的理解是在内存中的一块空间,可以将二级缓存配置到硬盘。用白话来说,就是一个存储数据的容器。我们关注的是,哪些数据需要被放入二级缓存。
缓存作用:
降低应用程序直接读写数据库的频率,从而提高程序的运行性能。缓存中的数据是数据存储源中数据的拷贝。缓存的物理介质通常是【内存】。
Hibernate缓存分类:
1):Session缓存(又称作事务缓存):Hibernate内置的,不能卸除。
缓存范围:
缓存只能被当前Session对象访问。
缓存的生命周期依赖于Session的生命周期,当Session被关闭后,缓存也就结束生命周期。
2):SessionFactory缓存(又称作应用缓存):使用第三方插件,可插拔。
缓存范围:
缓存被应用范围内的所有session共享,不同的Session可以共享。
这些session有可能是并发访问缓存,因此必须对缓存进行更新。
缓存的生命周期依赖于应用的生命周期,应用结束时,缓存也就结束了生命周期,二级缓存存在于应用程序范围。
一级缓存:
Hibernate一些与一级缓存相关的操作(时间点):
数据放入缓存:
1. save()。当session对象调用save()方法保存一个对象后,该对象会被放入到session的缓存中。
2. get()和load()。当session对象调用get()或load()方法从数据库取出一个对象后,该对象也会被放入到session的缓存中。
3.list()、iterate()查询出来的数据也会存放到缓存中
注意:这里的 list()只能往缓存中存放数据,不能从缓存中优先读取。
使用 get() 举例证明缓存的存在。
举例如下:
@Before
public void before() {
//获取会话
session = SessionTool.getSession();
//开启事务
transaction = session.beginTransaction();
}
/***
* 这里只产生一条SQL语句
*/
@Test
public void evictSession() {
System.out.println("*********前***********");
User user = (User) session.get(User.class, 20180001);
System.out.println("*********后***********");
//清除指定的对象
//session.evict(user);
user = (User) session.get(User.class, 20180001);
System.out.println(user);
}
@After
public void after() {
//提交事务
transaction.commit();
//关闭会话
if (session != null) {
session.clear();
}
}
控制台输出结果:

其原理是:
在同一个Session里面,第一次调用get()方法, Hibernate先检索缓存中是否有该查找对象,
发现没有,Hibernate发送SELECT语句到数据库中取出相应的对象,然后将该对象放入缓存中,以便下次使用,
第二次调用get()方法,Hibernate先检索缓存中是否有该查找对象,发现正好有该查找对象,就从缓存中取出来,不再去数据库中检索,没有再次发送select语句。
数据从缓存中清除:
1):evit()将指定的持久化对象从缓存中清除,释放对象所占用的内存资源,指定对象从持久化状态变为脱管状态,从而成为游离对象。
2):clear()将缓存中的所有持久化对象清除,释放其占用的内存资源。
其他缓存操作:
1):contains()判断指定的对象是否存在于缓存中。
2):flush()刷新缓存区的内容,使之与数据库数据保持同步。
二级缓存:
在上述都是说的一级缓存,那么现在我们首先来测试一下二级缓存是否生效那?
举例如下:
/***
*测试默认二级缓存是否生效
*/
@Test
public void er() {
//首次获取会话、事物
session = SessionTool.getSession();
transaction = session.beginTransaction();
System.out.println("*********前***********");
User user = (User) session.get(User.class, 20180001);
transaction.commit();
session.close();
System.out.println("*********后***********");
//重新获取会话、事物
session = SessionTool.getSession();
transaction = session.beginTransaction();
user = (User) session.get(User.class, 20180001);
System.out.println(user);
transaction.commit();
session.close();
}
控制台输出结果:

当我们重启一个Session,第二次调用load或者get方法检索同一个对象的时候会重新查找数据库,会发select语句信息。
原因:一个session不能取另一个session中的缓存。
性能上的问题:假如是多线程同时去取Category这个对象,load一个对象,这个对像本来可以放到内存中的,可是由于是多线程,是分布在不同的session当中的,
所以每次都要从数据库中取,这样会带来查询性能较低的问题。
解决方案:使用二级缓存。
1):什么是二级缓存?
SessionFactory级别的缓存,可以跨越Session存在,可以被多个Session所共享。
2):适合放到二级缓存中:
1)经常被访问
2)改动不大
3)数量有限
4)不是很重要的数据,允许出现偶尔并发的数据。
这样的数据非常适合放到二级缓存中的。
用户的权限:用户的数量不大,权限不多,不会经常被改动,经常被访问。
例如组织机构。
思考:什么样的类,里面的对象才适合放到二级缓存中?
改动频繁,类里面对象特别多,BBS好多帖子,这些帖子20000多条,哪些放到缓存中,不能确定。除非你确定有一些经常被访问的,数据量并不大,改动非常少,这样的数据非常适合放到二级缓存中的。
二级缓存实现原理:
Hibernate如何将数据库中的数据放入到二级缓存中?
注意,你可以把缓存看做是一个Map对象,它的Key用于存储对象OID,Value用于存储POJO。
首先,当我们使用Hibernate从数据库中查询出数据,获取检索的数据后,Hibernate将检索出来的对象的OID放入缓存中key 中,然后将具体的POJO放入value中,
等待下一次再次向数据查询数据时,Hibernate根据你提供的OID先检索一级缓存,若有且配置了二级缓存,则检索二级缓存,如果还没有则才向数据库发送SQL语句,然后将查询出来的对象放入缓存中。
使用二级缓存:
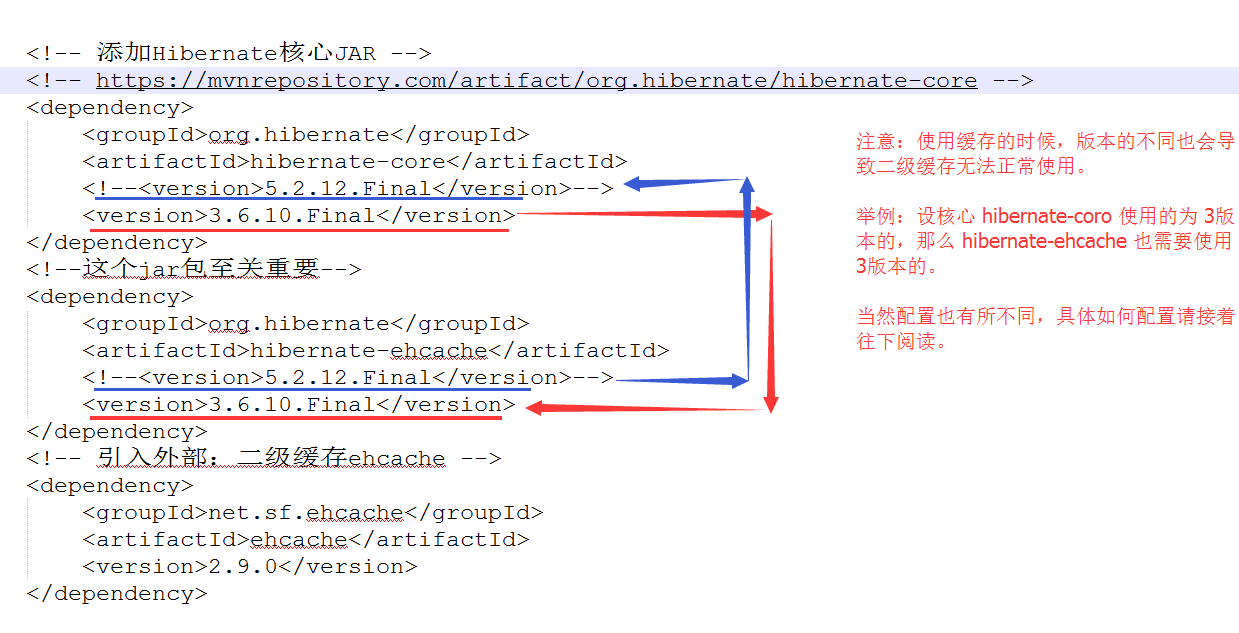
引入的JAR:
<!-- 添加Hibernate核心JAR -->
<!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-core -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<!--<version>5.2.12.Final</version>-->
<version>3.6.10.Final</version>
</dependency>
<!--这个jar包至关重要-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-ehcache</artifactId>
<!--<version>5.2.12.Final</version>-->
<version>3.6.10.Final</version>
</dependency>
<!-- 引入外部:二级缓存ehcache -->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.9.0</version>
</dependency>
1)打开二级缓存:
为Hibernate配置二级缓存:
在主配置文件中hibernate.cfg.xml :
<!-- 使用二级缓存 -->
<!-- 使用二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!--设置缓存的类型,设置缓存的提供商-->
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property> -------------------------以上为3-4版本的配置---------------------------------
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
-------------------------以上为 5 版本的配置---------------------------------
<property name="hibernate.cache.provider_class"> net.sf.ehcache.hibernate.EhCacheProvider</property>
-------------------------以上为 3 版本使用引入外部的缓存JAR(类)-----------------------------
或者当hibernate与Spring整合后直接配到Spring配置文件applicationContext.xml中
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mappingResources">
<list>
<value>com/lp/ecjtu/model/Employee.hbm.xml</value>
<value>com/lp/ecjtu/model/Department.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<value>
hibernate.dialect=org.hibernate.dialect.OracleDialect
hibernate.hbm2ddl.auto=update
hibernate.show_sql=true
hibernate.format_sql=true
hibernate.cache.use_second_level_cache=true
hibernate.cache.provider_class=org.hibernate.cache.EhCacheProvider
hibernate.generate_statistics=true
</value>
</property>
</bean>
2)配置ehcache.xml:
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<!--
缓存到硬盘的路径
-->
<diskStore path="d:/ehcache"></diskStore> <!--
默认设置
maxElementsInMemory : 在內存中最大緩存的对象数量。
eternal : 缓存的对象是否永远不变。
timeToIdleSeconds :可以操作对象的时间。
timeToLiveSeconds :缓存中对象的生命周期,时间到后查询数据会从数据库中读取。
overflowToDisk :内存满了,是否要缓存到硬盘。
-->
<defaultCache maxElementsInMemory="200" eternal="false"
timeToIdleSeconds="50" timeToLiveSeconds="60" overflowToDisk="true"></defaultCache> <!--
指定缓存的对象。
下面出现的的属性覆盖上面出现的,没出现的继承上面的。
-->
<cache name="com.suxiaolei.hibernate.pojos.Order" maxElementsInMemory="200" eternal="false"
timeToIdleSeconds="50" timeToLiveSeconds="60" overflowToDisk="true"></cache> </ehcache>
3)使用二级缓存需要在实体类中加入注解:
需要ehcache-1.2.3.jar包:
还需要 commons_loging1.1.1.jar包
在实体类中通过注解可以配置实用二级缓存:
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
Load默认使用二级缓存,就是当查一个对象的时候,它先会去二级缓存里面去找,如果找到了就不去数据库中查了。
Iterator默认的也会使用二级缓存,有的话就不去数据库里面查了,不发送select语句了。
List默认的往二级缓存中加数据,假如有一个query,把数据拿出来之后会放到二级缓存,但是执行查询的时候不会到二级缓存中查,会在数据库中查。原因每个query中查询条件不一样。
4)也可以在大配置文件 Hibernate.cfg.xml 中设置缓存对象:
<class-cache class="com.mlq.pojo.User" usage="read-write"/>
5)也可以在需要被缓存的对象中hbm文件中的<class>标签下添加一个<cache>子标签:
<hibernate-mapping>
<class name="com.suxiaolei.hibernate.pojos.Order" table="orders">
<cache usage="read-only"/>
<id name="id" type="string">
<column name="id"></column>
<generator class="uuid"></generator>
</id> <property name="orderNumber" column="orderNumber" type="string"></property>
<property name="cost" column="cost" type="integer"></property> <many-to-one name="customer" class="com.suxiaolei.hibernate.pojos.Customer"
column="customer_id" cascade="save-update">
</many-to-one>
</class>
</hibernate-mapping>
存在一对多的关系,想要在在获取一方的时候将关联的多方缓存起来,需要再集合属性下添加<cache>子标签,这里需要将关联的对象的 hbm文件中必须在存在<class>标签下也添加<cache>标签,不然Hibernate只会缓存OID。
<hibernate-mapping>
<class name="com.suxiaolei.hibernate.pojos.Customer" table="customer">
<!-- 主键设置 -->
<id name="id" type="string">
<column name="id"></column>
<generator class="uuid"></generator>
</id> <!-- 属性设置 -->
<property name="username" column="username" type="string"></property>
<property name="balance" column="balance" type="integer"></property> <set name="orders" inverse="true" cascade="all" lazy="false" fetch="join">
<cache usage="read-only"/>
<key column="customer_id" ></key>
<one-to-many class="com.suxiaolei.hibernate.pojos.Order"/>
</set>
</class>
</hibernate-mapping>
Face your past without regret. Handle your present with confidence.Prepare for future without fear. keep the faith and drop the fear.
面对过去无怨无悔,把握现在充满信心,备战未来无所畏惧。保持信念,克服恐惧!一点一滴的积累,一点一滴的沉淀,学技术需要不断的积淀!
分享知识-快乐自己:论Hibernate中的缓存机制的更多相关文章
- hibernate中的缓存机制
一.为什么要用Hibernate缓存? Hibernate是一个持久层框架,经常访问物理数据库. 为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能. 缓存内的数据是对物理数据源中的数 ...
- 分享知识-快乐自己:Hibernate 中 get() 和 load()、sava、update、savaOrUpdate、merge,不同之处及执行原理?
1):Hibernate 中 get() 和 load() 有什么不同之处? 1)Hibernate的 get方法,会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在缓存中查 ...
- 分享知识-快乐自己:Hibernate中的 quert.list() 与 quert.iterate() 方法区别
区别如下: quert.list() : 1):每次都是通过一条语句直接操作数据库取出所有的数据返回(并且将对象存入hibernate缓存中): 2):不会从一二级缓存中查询数据: 3):之执行一条S ...
- 分享知识-快乐自己:Hibernate 中的 HQL 语句的实际应用
概要: Hibernate 支持三种查询方式: HQL查询.Criteria查询及原声 SQL (Native SQL)查询. HQL(Hibernate Query Language,Hiberna ...
- 分享知识-快乐自己:Hibernate 中Criteria Query查询详解
1):Hibernate 中Criteria Query查询详解 当查询数据时,人们往往需要设置查询条件.在SQL或HQL语句中,查询条件常常放在where子句中. 此外,Hibernate还支持Cr ...
- 分享知识-快乐自己:MyBtis内置缓存机制
在实际的项目开发中,通常对数据库的查询性能要求很高,而mybatis提供了查询缓存来缓存数据,从而达到提高查询性能的要求. mybatis的查询缓存分为一级缓存和二级缓存,一级缓存是SqlSessio ...
- 【Hibernate】解析hibernate中的缓存
Hibernate中的缓存一共有三种,一级缓存.二级缓存.查询缓存.缓存除了使用Hibernate自带的缓存,还可以使用redis进行缓存,或是MongoDB进行缓存. 所使用的Demo: User. ...
- 使用Redis在Hibernate中进行缓存
Hibernate是Java编程语言的开放源代码,对象/关系映射框架.Hibernate的目标是帮助开发人员摆脱许多繁琐的手动数据处理任务.Hibernate能够在Java类和数据库表之间以及Java ...
- JavaWeb_(Hibernate框架)Hibernate中一级缓存
Hibernate中一级缓存 Hibernate 中的缓存分为一级缓存和二级缓存,这两个级别的缓存都位于持久化层,并且存储的都是数据库数据的备份.其中一级缓存是 Hibernate 的内置缓存,在前面 ...
随机推荐
- 使用FDTemplateLayout框架打造个性App
效果展示 project下载地址 · 进入构建结构 首先我们新建一个project 接下来我们拖进来一个Table View Controller,将Storyboard Entry Point指向我 ...
- IE对CSS样式的数量和大小的限制
项目中遇到的问题,css写的样式无法渲染,各种百度后发现大概是这个原因: IE对CSS样式的数量和大小的限制 文档中只有前31个link或style标记关联的CSS能够应用. 从第32个开始,其标记关 ...
- Splash动画启动app时空白屏
相信大多数人一开始都会对启动app的时候出现先白瓶或者黑屏然后才进入第一个界面,例如:SplashActivity.那这是什么原因造成的呢? <style name="Splash_T ...
- 前端PC页面,移动端页面问题笔记~~
<!DOCTYPE html> <html> <head> <meta charset="gbk"/> <meta name= ...
- OpenStack安装CentOS镜像:Device eth0 does not seem to be present, delaying initialization
解决办法:删除 /etc/udev/rules.d/70-persistent-net.rules 后重启机器.70-persistent-net.rules这个文件确定了网卡与MAC地址的绑定,cl ...
- eclipse maven 刷新报错
问题描述: An internal error occurred during: "Loading descriptor for cmbc_wms.".java.lang.Null ...
- Python 爬虫常见的坑和解决方法
1.请求时出现HTTP Error 403: Forbidden headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23. ...
- 广播、多播和IGMP的一点记录
广播和多播:仅应用于UDP 广播分为: 1.受限的广播(255.255.255.255) 2.指向网络的广播(eg:A类网络 netid.255.255.255)主机号为全1的地址 3.指向子网的广播 ...
- 绿色版Tomcat的配置
在环境变量中不配置JAVA_HOME或者JRE_HONE的情况下(正确配置java的路径)不影响java的使用 可以正常使用 java -version .... 但是这种情况下 无法在Tomcat的 ...
- cmake policy
1 cmake policy是什么? cmake policy可以理解为cmake的语法标准,也就是说,它规定了cmake在解析CMakeLists.txt文件时的行为. 2 cmake policy ...