使用htmlparser爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚然,我们的重点在于如何灵活运用我们已学的技术,这就需要我们不断的练习,不停的思索和深入发掘,在了解了精髓和意义之后运用到实践中才是技术的最高境界。
今天呢,本着昨天的兴趣,想来爬一爬电影资源,中途为了找一个好用趁手的工具,也是费了不少心思,早上半天基本上都在学习和找资料的过程中度过,下午开始才进入状态,那么, 今天我们就来利用htmlparse爬取电影网页中的全部电影下载链接。
我们先来认识一下htmlparser:
HTMLParser具有小巧,快速的优点,缺点是相关文档比较少(英文的也少),很多功能需要自己摸索。对于初学者还是要费一些功夫的,而一旦上手以后,会发现HTMLParser的结构设计很巧妙,非常实用,基本你的各种需求都可以满足。
TMLParser的核心模块是org.htmlparser.Parser类,这个类实际完成了对于HTML页面的分析工作。这个类有下面几个构造函数:
- public Parser ();
- public Parser (Lexer lexer, ParserFeedback fb);
- public Parser (URLConnection connection, ParserFeedback fb) throws ParserException;
- public Parser (String resource, ParserFeedback feedback) throws ParserException;
- public Parser (String resource) throws ParserException;public Parser (Lexer lexer);
- public Parser (URLConnection connection) throws ParserException;
- public static Parser createParser (String html, String charset);
对于大多数使用者来说,使用最多的是通过一个URLConnection或者一个保存有网页内容的字符串来初始化Parser,或者使用静态函数来生成一个Parser对象。ParserFeedback的代码很简单,是针对调试和跟踪分析过程的,一般不需要改变.
这里比较有趣的一点是,如果需要设置页面的编码方式的话,不使用Lexer就只有静态函数一个方法了。对于大多数中文页面来说,好像这是应该用得比较多的一个方法。
1、前期准备,下载htmlparse压缩包并配置到eclipse上,到下面网址可以下载
http://htmlparser.sourceforge.net/,解压后如下图所示

2、网页的分析与根据网页源码使用htmlparse
1、这里先分析与获取一个电影介绍页面的内容
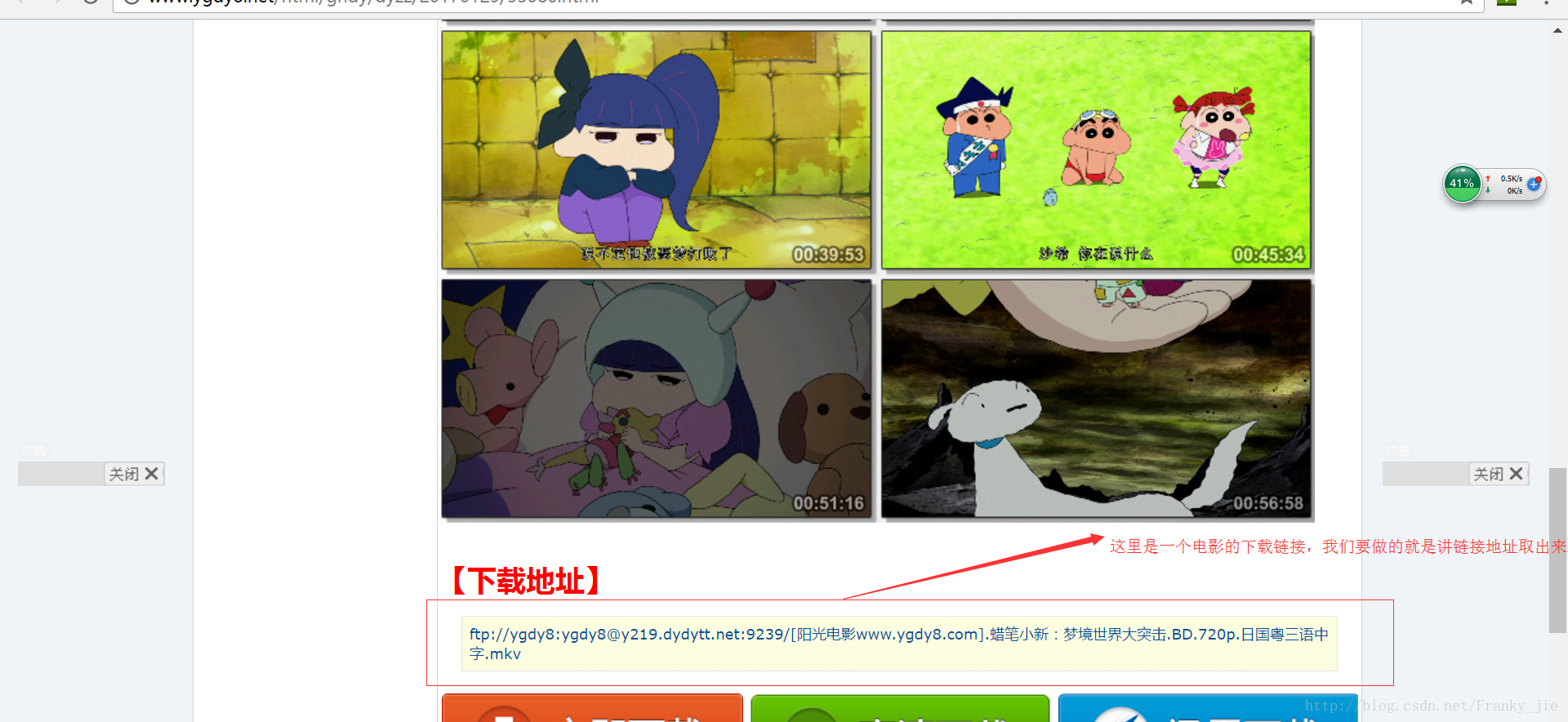

我们现在先来获取一个页面的下载链接
/**
* 获取一个页面的下载链接
*/
public static String getMoiveDownloadUrl(String moiveIntroUrl) {
// 页面下载连接保存在这里
String moiveDownLoadUrl = "";
try {
// 首先根据页面URL建立一个Parser.
Parser parser = new Parser(moiveIntroUrl);
// 使用parser中extractAllNodesThatMatch方法,这个有许多的过滤器,可以帮助我们过滤出我们想要的内容,具体可以看api的介绍
// 这里我们使用链接文本过滤器,可以过滤出链接里面含ftp的内容,这样就可以取出我们想要的链接
NodeList nodelist = parser.extractAllNodesThatMatch(new LinkStringFilter("ftp"));
for (int i = 0; i < nodelist.size(); i++) {
LinkTag tag = (LinkTag) nodelist.elementAt(i);
moiveDownLoadUrl = tag.getLink();
}
} catch (ParserException e) {
e.printStackTrace();
}
return moiveDownLoadUrl;
}
2、获取一个分页里的所有电影介绍页面


/**
*
* 获取一个分页里的所有电影介绍页面
*/
public static List getAllMoiveUrlFromOneList(String pageListUrl) {
// 将链接地址以集合的形式返回出去
List<String> allMoiveUrl = new ArrayList<String>();
try {
Parser parser = new Parser(pageListUrl);
// 这里我们使用属性过滤器,可以帮助我们过滤一些属性特殊或者属性里面值唯一的标签
NodeList nodelist = parser.extractAllNodesThatMatch(new HasAttributeFilter("class", "ulink"));
for (int i = 0; i < nodelist.size(); i++) {
LinkTag tag = (LinkTag) nodelist.elementAt(i);
// 将取出的分页链接拼接一下,放入到集合中来。
allMoiveUrl.add("http://www.ygdy8.net" + tag.getLink());
}
} catch (ParserException e) {
e.printStackTrace();
}
return allMoiveUrl;
}
3、获取电影网里面的所有分页

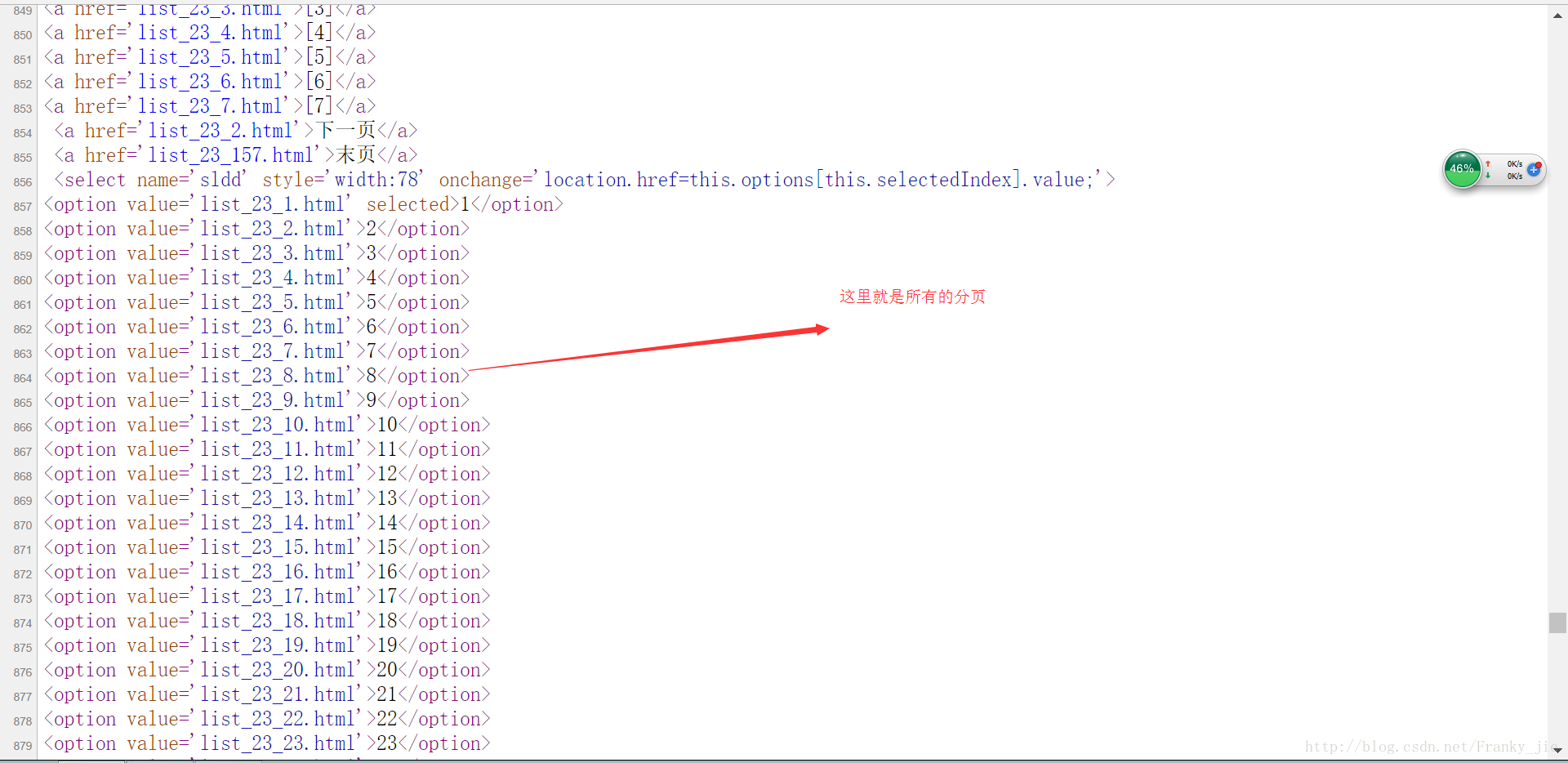
/**
*获取电影网里面的所有的分页
*/
public static List getAllPage() {
// 将链接地址以集合的形式返回出去
List<String> allPage = new ArrayList<String>();
try {
Parser parser = new Parser("http://www.ygdy8.net/html/gndy/jddy/index.html");
//http://www.ygdy8.net/html/gndy/jddy/index.html
NodeList nodelist = parser.extractAllNodesThatMatch(new TagNameFilter("option"))
.extractAllNodesThatMatch(new HasAttributeFilter("value"));
for (int i = 0; i < nodelist.size(); i++) {
OptionTag tag = (OptionTag) nodelist.elementAt(i);
if (tag.getAttribute("value").contains("list")) {
allPage.add("http://www.ygdy8.net/html/gndy/jddy/" + tag.getAttribute("value"));
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return allPage;
}
OK。至此,我们就可以得到全部分页的链接,各个电影介绍页面的链接,介绍页面里的下载链接。接下来我们要做的就是将这三个方法整合起来,获得全部电影的下载链接。
/**
*
* 功能:保存数据到文件中
* @param content 要保存的内容
* @param fileName 目标文件名(路径)
*
*/
public static boolean writeContentToFileTwo(String content, String fileName) {
boolean flag = false;
try {
PrintWriter pw = new PrintWriter(new OutputStreamWriter(new FileOutputStream(fileName, true)));
pw.println();
pw.print(content);
pw.flush();
pw.close();
flag = true;
} catch (FileNotFoundException e) {
e.printStackTrace();
flag = false;
}
return flag;
} public static List getAllMoive() {
List<String> movieList = new ArrayList<String>();
// 得到全部的分页链接
List<String> allPage = getAllPage();
for (Iterator iterator = allPage.iterator(); iterator.hasNext();) {
String pageListUrl = (String) iterator.next();
List<String> allMoiveUrl = getAllMoiveUrlFromOneList(pageListUrl);
for (Iterator iterator2 = allMoiveUrl.iterator(); iterator2.hasNext();) {
String moiveIntroUrl = (String) iterator2.next();
String moiveDownLoadUrl = getMoiveDownloadUrl(moiveIntroUrl);
writeContentToFileTwo(moiveDownLoadUrl, "a.txt");
movieList.add(moiveDownLoadUrl);
}
}
return movieList;
}
public static void main(String[] args) {
getAllMoive();
}
效果如下图所示:
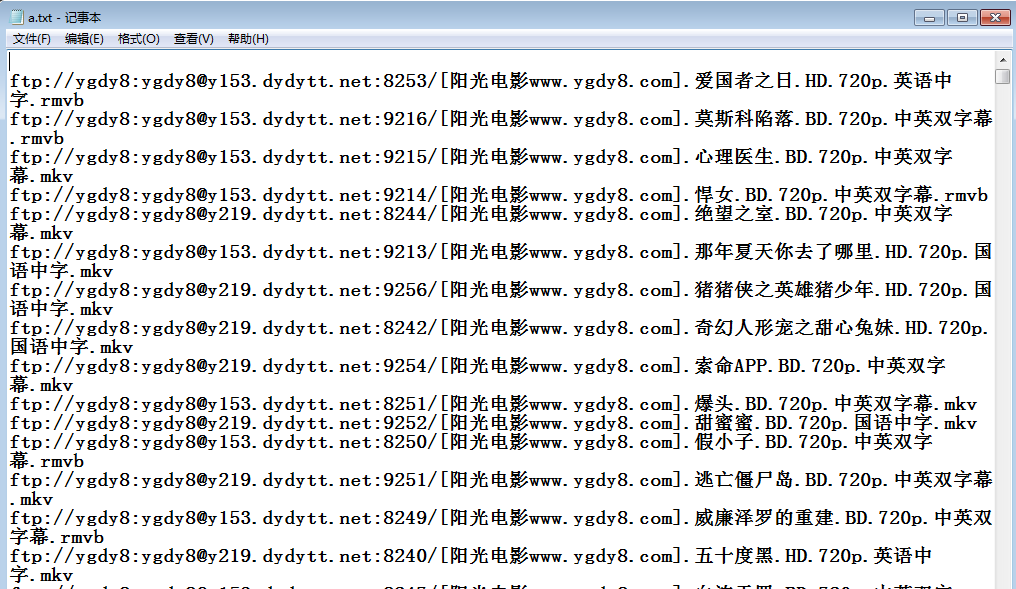
好啦,大功告成啦!是不是很简答呢。
其实这个工具的使用是不复杂的,流程也很清晰,问题的关键在于如何在一个庞大的html页面中获取你想要的内容,可以多一点查看各种的节点过滤器,它可以帮助我们选出我们想要的内容,每次在爬取网页之前我们都要花大量时间去分析一个网页,找到我们想要的内容,不能多也不能少,这我觉得才是爬虫的使用的重点。
如果您对本文有什么异议或者发现有什么问题,欢迎留言,发表您的看法和观点。
附上项目源码和全部电影下载链接的excel:https://git.oschina.net/AuSiang/myBug/attach_files
使用htmlparser爬虫技术爬取电影网页的全部下载链接的更多相关文章
- 使用htmlparse爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- 利用python的爬虫技术爬取百度贴吧的帖子
在爬取糗事百科的段子后,我又在知乎上找了一个爬取百度贴吧帖子的实例,为了巩固提升已掌握的爬虫知识,于是我打算自己也做一个. 实现目标:1,爬取楼主所发的帖子 2,显示所爬去的楼层以及帖子题目 3,将爬 ...
- Selenium爬取电影网页写成csv文件
绪论 首先写这个文章的时候仅仅花了2个晚上(我是菜鸟所以很慢),自己之前略懂selenium,但是不是很懂csv,这次相当于练手了. 第一章 环境介绍 具体实验环境 系统 Windows10教育版 1 ...
- 爬虫之爬取电影天堂(request)
#需要通过代码打开https://www.dytt8.net/网站,拿到网站内容 from urllib.request import urlopen #拿到urlopen import re con ...
- 用php实现一个简单的爬虫,抓取电影网站的视频下载地址
昨天没什么事,先看一下电影,就用php写了一个爬虫在视频网站上进行视频下载地址的抓取,这里总结一下抓取过程中遇到的问题 1:通过访问浏览器来执行php脚本这种访问方式其实并不适合用来爬网页,因为要受到 ...
- python爬虫:爬取百度云盘资料,保存下载地址、链接标题、链接详情
在网上看到的教程,但是我嫌弃那个教程写的乱(虽然最后显示我也没高明多少,哈哈),就随手写了一个 主要是嫌弃盘搜那些恶心的广告,这样直接下载下来,眼睛清爽多了. 用pyinstall 打包成EXE文件, ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
随机推荐
- [egret+pomelo]实时对战游戏杂记(5)
之前大体了解了pomelo服务端的运行的大体运行流程,下面详细的学习一下在服务端比较重要的一个容器模块bearcat,在bearcat的wiki中我们可以对其有个大概的了解,在服务端示例的代码中也大量 ...
- Cmder配置
中文乱码和重叠 当我们使用ls命令查看文件目录时,发现,中文被显示成了一些奇怪的乱码,将以下几行代码配置在cmder/config/user-aliases下即可解决问题: l=ls --show-c ...
- 用ant编译打包时 警告:编码 GBK 的不可映射字符
原因,参考http://zhidao.baidu.com/question/26901568.html 添加如下的红色一行后编译通过<target name="compile" ...
- <J2EE学习笔记>关于Servlet的讲义
题外话:接触java又是半年之前的事情了,当初好好学了java却把cpp给忘了,到现在又把手里发热的cpp给放下重新捡起来java,究竟这两种OOP语言我能不能清晰分开记住呢 以下全部课件来自于同济大 ...
- smokeping高级配置
摘自: http://mayulin.blog.51cto.com/1628315/514367 自定义报警 http://www.cnblogs.com/thatsit/p/6395506.html
- BZOJ 1600 [Usaco2008 Oct]建造栅栏:dp【前缀和优化】
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1600 题意: 给你一个长度为n的木板,让你把这个木板切割成四段(长度为整数),并且要求这四 ...
- 转载h5问题总结
判断微信浏览器 function isWeixin(){ var ua = navigator.userAgent.toLowerCase(); if(ua.match(/MicroMessenger ...
- listen 59
Different Brain Regions Handle Different Music Types (Vivaldi) versus (the Beatles) . Both great. Bu ...
- VirtualBox下安装MacOS11
8.键盘选中 “简体中文” -- > "拼音模式".VirtualBox安装Mac OS 10.11 ,安装日期:2016 / 5 / 14 用虚拟机装黑苹果本人也装了不下3 ...
- bzoj 1004 Cards & poj 2409 Let it Bead —— 置换群
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1004 关于置换群:https://www.cnblogs.com/nietzsche-oie ...