数据结构( Pyhon 语言描述 ) — —第11章:集和字典
- 使用集
- 集是没有特定顺序的项的一个集合,集中的项中唯一的
- 集上可以执行的操作
- 返回集中项的数目
- 测试集是否为空
- 向集中添加一项
- 从集中删除一项
- 测试给定的项是否在集中
- 获取两个集的并集
- 获取两个集的交集
- 获取两个集的差集
- 判断一个集是否是另一个集的子集
- 集上的差集和子集操作是不对称的
- Python 中的 set 类
- set 类中常用的方法

- 使用示例
.5 时,即重新哈希表。这样会将 DELETED 状态的单元格全部变为当前占用的单元格或者空单元格
- 如果表有一些方法记录了访问给定项的频率,即可以按照这个频率递减的顺序来插入项。从而将较为频繁访问的项放置的更加接近于主索引
- 聚簇
- 当导致冲突的项重复放置到数组的相同区域(一个聚簇)中的时候,会发生这种情况
- 示例
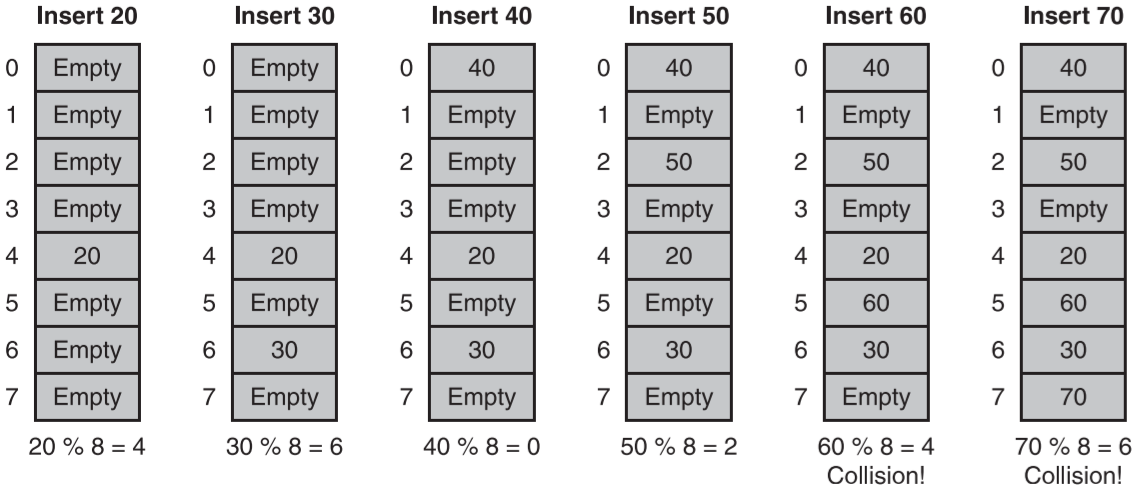
- 聚簇通常会导致和其它重新定位的项之间的冲突,在应用的过程中,几个聚簇可能发展并联合成更大的聚簇,从而增加平均的访问时间
- 二次探测
- 避免和线性探测相关的聚簇的一种方式是,从冲突位置将对空位置的索引向前推进一定的距离
- 二次探测通过将主索引增加每一次尝试距离的平方来实现这一点
- 代码
# Set the initial key, index, and distance
key = abs(hash(item))
distance = 1
homeIndex = key % len(table)
# Stop searching when an unoccupied cell is encountered
while table[index] not in (EMPTY, DELETED):
# Increment the index and warp around to the first position if necessary.
index = (homeIndex + distance ** 2) % len(table)
distance += 1
# An empty cell is found, so store the item.
tabel[index] = item
- 二次探测的主要问题是会跳过一些单元格,从而导致空间的浪费
- 链化 -- 桶链策略
- 示意图
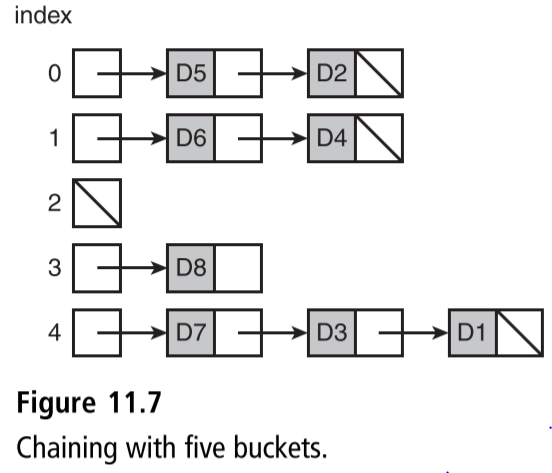
- 访问和删除操作执行的步骤
- 计算项在数组中的主索引
- 搜索该项在链表中的索引
- 插入项执行的步骤
- 计算项在数组中的主索引
- 如果数组单元格为空,创建一个带有该项的节点,并将该节点赋值给单元格
- 如果不为空,会产生冲突。在该位置已有的项,是链表的头部。在这个链表的头部插入新的项
- 示意代码
# Get the home index
index = abs(hash(item)) % len(table)
# Access a bucket and store the item at the head of its linked list
table[index] = Node(item, table[index])
- 复杂度分析
- 线性探测方法
- 失败搜索(所要查找的项不存在)复杂度为
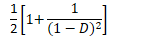
- 其中 为数组的装填因子

- 二次方法
- 成功搜索的复杂度(所要查找的项存在)
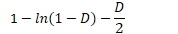
- 失败搜索的复杂度
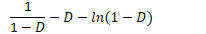
- 桶和链方法的分析
- 定位一个项
- 过程
- 计算主索引
- 当发生冲突时搜索一个链表
- 第一部分是常数时间的行为,而第二部分是线性时间的行为
- 案例学习:探查哈希策略
- 需求
- 编写一个程序,来探查不同的哈希策略
- 分析
- HashTable 中的方法

- Profiler 中的方法

- 设计
- HashTable
- insert 方法假设数组中有用于新项的空间,并且新项不会和已有的项重复
- 代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: hasetable.py
"""
from arrays import Array
class HashTable(object):
"""Represent a hash table"""
EMPTY = None
DELETED = True
def __init__(self, capacity=29, hashFunction=hash, liner=True):
self._table = Array(capacity, HashTable.EMPTY)
self._size = 0
self._hash = hashFunction
self._homeIndex = -1
self._actualIndex = -1
self._liner = liner
self._probeCount = 0
# Accessor method
def __len__(self):
return self._size
def loadFactor(self):
return self._size / len(self._table)
def homeIndex(self):
return self._homeIndex
def actualIndex(self):
return self._actualIndex
def probeCount(self):
return self._probeCount
# Mutator method
def insert(self, item):
"""Insert item into the table.
Precondition: There is at least one empty cell or one previously occupied cell.
There is not a duplicate item."""
self._probeCount = 0
# Get the home index
self._homeIndex = self._hash(item) % len(self._table)
distance = 1
index = self._homeIndex
# Stop searching when an empty cell in encountered
while self._table[index] not in (HashTable.EMPTY, HashTable.DELETED):
# Increment the index and wrap around to the first position if necessary.
if self._liner:
increment = index + 1
else:
# Quadratic probing
increment = index + distance ** 2
distance += 1
index = increment % (len(self._table))
self._probeCount += 1
# An empty cell is found, so store the item
self._table[index] = item
self._size += 1
self._actualIndex = index
- Profiler
- 代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: profiler.py
"""
from hashtable import HashTable
class Profiler(object):
"""Represent a profiler for hash table."""
def __init__(self):
self._table = None
self._collisions = 0
self._probeCount = 0
self._result = ""
def test(self, table, data):
"""Inserts the data into table and gathers statistics"""
self._table = table
self._collisions = 0
self._probeCount = 0
self._result = "Load Factor | Item Inserted | Home Index | Actual Index | Probes\n"
for item in data:
loadFactor = table.loadFactor()
table.insert(item)
homeIndex = table.homeIndex()
actualIndex = table.actualIndex()
probes = table.probeCount()
self._probeCount += probes
if probes > 0:
self._collisions += 1
self._result += "%8.3f%14d%12d%12d%14d" % (loadFactor, item, homeIndex, actualIndex, probes)\
+ "\n"
self._result += "Total collisions: " + str(self._collisions) + \
"\nTotal probes: " + str(self._probeCount) + \
"\nAverage probes per collision: " + str(self._probeCount / self._collisions)
def __str__(self):
if self._table is None:
return "No test has been run yet."
else:
return self._result
def collisions(self):
return self._collisions
def probeCount(self):
return self._probeCount
def main():
# Create a table with 8 cells, an identity hash function and liner probing.
table = HashTable(8, lambda x: x)
data = list(range(10, 71, 10))
profiler = Profiler()
profiler.test(table, data)
print(profiler)
if __name__ == "__main__":
main()
- 输出示例
Load Factor | Item Inserted | Home Index | Actual Index | Probes
0.000 10 2 2 0
0.125 20 4 4 0
0.250 30 6 6 0
0.375 40 0 0 0
0.500 50 2 3 1
0.625 60 4 5 1
0.750 70 6 7 1
Total collisions: 3
Total probes: 3
Average probes per collision: 1.0
- 集的哈希实现
- 采用桶/链策略来处理冲突
- __contains__方法可以将一些实例变量的值设置为可以在插入、访问和删除过程中使用的信息

- 代码实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
from node import Node
from arrays import Array
from abstractset import AbstractSet
from abstractcollection import AbstractCollection
class HashSet(AbstractCollection, AbstractSet):
"""A hashing implementation of a set."""
DEFAULT_CAPACITY = 3
def __init__(self, sourceCollection=None, capacity=None):
if capacity is None:
self._capacity = HashSet.DEFAULT_CAPACITY
else:
self._capacity = capacity
self._items = Array(self._capacity)
self._foundNode = self._priorNode = None
self._index = -1
AbstractCollection.__init__(self, sourceCollection)
# Accessor method
def __contains__(self, item):
"""Return True if item is in the set or False otherwise."""
self._index = hash(item) % len(self._items)
self._priorNode = None
self._foundNode = self._items[self._index]
while self._foundNode is not None:
if self._foundNode.data == item:
return True
else:
self._priorNode = self._foundNode
self._foundNode = self._foundNode.next
return False
def __iter__(self):
"""Supports iteration over a view of self."""
for item in self._items:
while item is not None:
yield item.data
item = item.next
def __str__(self):
"""Return a string representation of self"""
return "{" + ", ".join(map(str, self)) + "}"
# Mutator methods
def clear(self):
"""Makes self becomes empty."""
self._size = 0
self._items = Array(HashSet.DEFAULT_CAPACITY)
def add(self, item):
"""Adds item to the set if if is not in the set."""
if item not in self:
newNode = Node(item, self._items[self._index])
self._items[self._index] = newNode
self._size += 1
def remove(self, item):
"""Precondition: item is in self.
Raise: KeyError if item is not in self.
return the removed item if item is in self"""
if item not in self:
raise KeyError("Missing: " + str(item))
if self._priorNode is None:
self._items[self._index] = self._foundNode.next
else:
self._priorNode.next = self._foundNode.next
self._size -= 1
return self._foundNode.data
- 字典的哈希实现
- 采用桶/链策略来处理冲突
- __contains__方法同样将一些实例变量的值设置为可以在插入、访问和删除过程中使用的信息
- 代码实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: hashdict.py
"""
from abstractdict import AbstractDict, Item
from node import Node
from arrays import Array
class HashDict(AbstractDict):
"""Represents a hash-based dictionary"""
DEFAULT_CAPACITY = 9
def __init__(self, sourceDictionary=None):
"""Will copy items to collection from sourceDictionary if it's present."""
self._array = Array(HashDict.DEFAULT_CAPACITY)
self._foundNode = self._priorNode = None
self._index = -1
AbstractDict.__init__(self, sourceDictionary)
# Accessor method
def __contains__(self, key):
"""Return True if item is in self, or False otherwise."""
self._index = hash(key) % len(self._array)
self._priorNode = None
self._foundNode = self._array[self._index]
while self._foundNode is not None:
if self._foundNode.data.key == key:
return True
else:
self._priorNode = self._foundNode
self._foundNode = self._foundNode.next
return False
def __iter__(self):
"""Serves up the key in the dictionary."""
for item in self._array:
while item is not None:
yield item.data.key
item = item.next
def __getitem__(self, key):
"""Precondition: the key is in the dictionary
Raise KeyError if the key is not in the dictionary
Return the value associated with the key.
"""
if key not in self:
raise KeyError("Missing: " + str(key))
return self._foundNode.data.value
# Mutator method
def __setitem__(self, key, value):
"""If the key is not in the dictionary, adds the key and value to it,
otherwise, replace the old value with the new one."""
if key in self:
self._foundNode.data.value = value
else:
newNode = Node(Item(key, value), self._array[self._index])
self._array[self._index] = newNode
self._size += 1
def pop(self, key):
"""Precondition: the key is in the dictionary.
Raise: KeyError if the key is not in the dictionary.
Remove the key and return the associated value if the key is in the dictionary."""
if key not in self:
raise KeyError("Missing: " + str(key))
if self._priorNode is None:
self._array[self._index] = self._foundNode.next
else:
self._priorNode.next = self._foundNode.next
self._size -= 1
return self._foundNode.data.value
- 有序的集和字典
- 集中的项和字典中的键必须是可比较的,才可能创建有序的集。有序的集必须要放弃哈希策略
- 可以用二叉搜索树来实现有序的集和字典
- 有序的集
- 代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: treesortedset.py
"""
from linkedbst import LinkedBST
from abstractcollection import AbstractCollection
from abstractset import AbstractSet
class TreeSortedSet(AbstractCollection, AbstractSet):
"""A tree-based implementation of a sorted set."""
def __init__(self, sourceCollection=None):
self._items = LinkedBST()
AbstractCollection.__init__(self, sourceCollection)
def __contains__(self, item):
"""Return True if item is in the set or False otherwise."""
return item in self._items
def __iter__(self):
"""Supports iteration over a view of self."""
return self._items.inorder()
def __str__(self):
"""Return a string representation of self"""
return "{" + ", ".join(map(str, self)) + "}"
# Mutator method
def add(self, item):
"""Adds item to the set if if is not in the set."""
if item not in self:
self._items.add(item)
self._size += 1
def clear(self):
"""Makes self becomes empty."""
self._size = 0
self._items = LinkedBST()
def remove(self, item):
"""Precondition: item is in self.
Raise: KeyError if item is not in self.
return the removed item if item is in self"""
if item not in self:
raise KeyError("Missing: " + str(item))
self._items.remove(item)
self._size -= 1
- 有序的字典
- 代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: treesorteddict.py
"""
from linkedbst import LinkedBST
from abstractdict import AbstractDict, Item
class TreeSortedDict(AbstractDict):
"""A tree-based implementation of a sorted dictionary."""
def __init__(self, sourceCollection=None):
"""Will copy items to collection from sourceCollection if it's present."""
self._items = LinkedBST()
self._foundItem = None
AbstractDict.__init__(self, sourceCollection)
# Accessor
def __iter__(self):
"""Serves up the key in the dictionary."""
for item in self._items.inorder():
yield item.key
def __getitem__(self, key):
"""Precondition: the key is in the dictionary
Raise KeyError if the key is not in the dictionary
Return the value associated with the key.
"""
if key not in self:
raise KeyError("Missing: " + str(key))
return self._foundItem.value
def __contains__(self, key):
"""Set the self._index to the target position if key is in self."""
newItem = Item(key, None)
self._foundItem = self._items.find(newItem)
if self._foundItem is None:
return False
else:
return True
# Mutator
def __setitem__(self, key, value):
"""If the key is not in the dictionary, adds the key and value to it,
otherwise, replace the old value with the new one."""
if key not in self:
self._items.add(Item(key, value))
self._size += 1
else:
self._foundItem.value = value
def pop(self, key):
"""Precondition: the key is in the dictionary.
Raise: KeyError if the key is not in the dictionary.
Remove the key and return the associated value if the key is in the dictionary."""
if key not in self:
raise KeyError("Missing: " + str(key))
self._size -= 1
removedItem = self._items.remove(Item(key, None))
return removedItem.value
数据结构( Pyhon 语言描述 ) — —第11章:集和字典的更多相关文章
- 数据结构( Pyhon 语言描述 ) — —第10章:树
树的概览 树是层级式的集合 树中最顶端的节点叫做根 个或多个后继(子节点). 没有子节点的节点叫做叶子节点 拥有子节点的节点叫做内部节点 ,其子节点位于层级1,依次类推.一个空树的层级为 -1 树的术 ...
- 数据结构( Pyhon 语言描述 ) — — 第7章:栈
栈概览 栈是线性集合,遵从后进先出原则( Last - in first - out , LIFO )原则 栈常用的操作包括压入( push ) 和弹出( pop ) 栈的应用 将中缀表达式转换为后缀 ...
- 数据结构( Pyhon 语言描述 ) — — 第5章:接口、实现和多态
接口 接口是软件资源用户可用的一组操作 接口中的内容是函数头和方法头,以及它们的文档 设计良好的软件系统会将接口与其实现分隔开来 多态 多态是在两个或多个类的实现中使用相同的运算符号.函数名或方法.多 ...
- 数据结构( Pyhon 语言描述 ) — —第9章:列表
概念 列表是一个线性的集合,允许用户在任意位置插入.删除.访问和替换元素 使用列表 基于索引的操作 基本操作 数组与列表的区别 数组是一种具体的数据结构,拥有基于单个的物理内存块的一种特定的,不变的实 ...
- 数据结构( Pyhon 语言描述 ) — — 第2章:集合概览
集合类型 定义 个或多个其他对象的对象.集合拥有访问对象.插入对象.删除对象.确定集合大小以及遍历或访问集合的对象的操作 分类 根据组织方式进行 线性集合 线性集合按照位置排列其项,除了第一项,每一项 ...
- 数据结构( Pyhon 语言描述 ) — — 第4章:数据和链表结构
数据结构是表示一个集合中包含的数据的一个对象 数组数据结构 数组是一个数据结构 支持按照位置对某一项的随机访问,且这种访问的时间是常数 在创建数组时,给定了用于存储数据的位置的一个数目,并且数组的长度 ...
- 数据结构( Pyhon 语言描述 ) — — 第1章:Python编程基础
变量和赋值语句 在同一条赋值语句中可以引入多个变量 交换变量a 和b 的值 a,b = b,a Python换行可以使用转义字符\,下一行的缩进量相同 )\ 帮助文档 help() 控制语句 条件式语 ...
- 数据结构( Pyhon 语言描述 ) — — 第8章:队列
队列概览 队列是线性的集合 队列的插入限制在队尾,删除限制在队头.支持先进先出协议( FIFIO, first-in first-out ) 两个基本操作 add:在队尾添加一项 pop:从队头弹出一 ...
- 数据结构( Pyhon 语言描述 ) — — 第6章:继承和抽象类
继承 新的类通过继承可以获得已有类的所有特性和行为 继承允许两个类(子类和超类)之间共享数据和方法 可以复用已有的代码,从而消除冗余性 使得软件系统的维护和验证变得简单 子类通过修改自己的方法或者添加 ...
随机推荐
- __getitem__,__setitem__,__delitem__
__getitem__.__setitem__.__delitem__ 总结: __getitem__,__setitem_,__delitem__ : obj[‘属性’]的方式去操作属性时触发的方法 ...
- Xenu使用随记
经试验发现,如果配置了host进行网站检测时,Xenu和浏览器一样,都需要配置了host之后,重新打开Xenu程序(浏览器),host的配置才能生效.
- 牛客网Java刷题知识点之Java为什么不能支持多继承,但可以用接口来间接实现多继承
不多说,直接上干货! java只支持单继承,这是由于安全性的考虑,如果子类继承的多个父类里面有相同的方法或者属性,子类将不知道具体要继承哪个,而接口可以多实现,是因为接口只定义方法,而没有具体的逻辑实 ...
- 解决织梦 \include\userlogin.class.php on line 21(或16) 报错的方法
用了下DEDECMS v5.7 SP1版本,发现很多问题,其中一个比较严重的是,架到服务器上的dede网站后台打开菜单选项卡得不能动,等半天显示505服务器错误,这个真让人纠结,在本地调试明明好好的, ...
- Linux 安装gcc4.8版本
1.下载安装包 http://ftp.tsukuba.wide.ad.jp/software/gcc/releases/gcc-4.8.1/ 2.解压 .tar.gz 3.下载编译所需的依赖包 cd ...
- kafka基础四
消费者消费过程(二) 消费组状态机:消息的产生存储消费看似是杂乱无章的,但万物都会遵循一定的规则成长,任何事物的发展都是有迹可循的. 开始消费组初始状态为Stable,经过第一次Rebalance之后 ...
- Windows下Apache+PHP+MySQL开发环境的搭建(WAMP)
准备工作: 1.下载apache服务器安装包,官网http://www.apache.org/,下载地址:http://httpd.apache.org/download.cgi 2.下载MySQL, ...
- hihocoder1766 字符串问题
思路: 不断贪心增加即可. 实现: #include <iostream> #include <cstring> using namespace std; ][]; int m ...
- (转)RAM、ROM、SRAM、DRAM、SSRAM、SDRAM、FLASH、EEPROM的区别
RAM(Random Access Memory) 随机存储器.存储单元的内容可按需随意取出或存入,且存取的速度与存储单元的位置无关的存储器.这种存储器在断电时将丢失其存储内容,故主要用于存储短时间使 ...
- Alpha-beta pruning
function alphabeta(node, depth, α, β, maximizingPlayer) or node is a terminal node return the heuris ...