爬去豆瓣图书top250数据存储到csv中
from lxml import etree
import requests
import csv
fp=open('C://Users/Administrator/Desktop/lianxi/doubanbook.csv','w+',newline='',encoding='utf-8')
writer=csv.writer(fp)
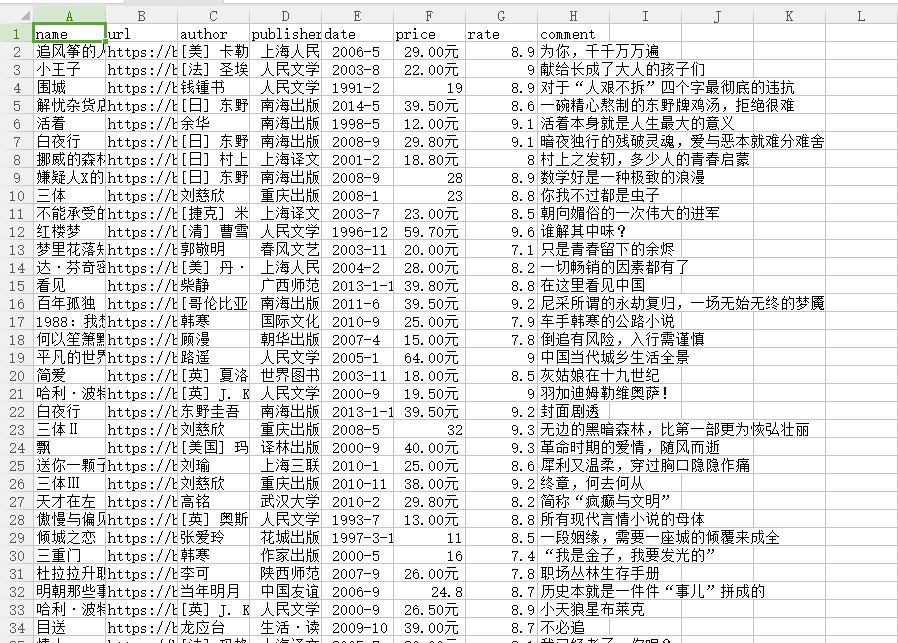
writer.writerow(('name','url','author','publisher','date','price','rate','comment'))
headers={
#'User-Agent':'Nokia6600/1.0 (3.42.1) SymbianOS/7.0s Series60/2.0 Profile/MIDP-2.0 Configuration/CLDC-1.0'
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
urls=['https://book.douban.com/top250?start={}'.format(str(i))for i in range(0,50,25)]
for url in urls:
html=requests.get(url,headers=headers)
selector=etree.HTML(html.text)
infos=selector.xpath('//tr[@class="item"]')
for info in infos:
name=info.xpath('td/div/a/@title')[0]
url=info.xpath('td/div/a/@href')[0]
book_infos=info.xpath('td/p/text()')[0]
author=book_infos.split('/')[0]
publisher=book_infos.split('/')[-3]
date=book_infos.split('/')[-2]
price=book_infos.split('/')[-1]
rate=info.xpath('td/div/span[2]/text()')[0]
comments=info.xpath('td/p/span/text()')
comment=comments[0] if len(comments) != 0 else "空"
writer.writerow((name,url,author,publisher,date,price,rate,comment))
fp.close()
爬去豆瓣图书top250数据存储到csv中的更多相关文章
- Python 2.7_利用xpath语法爬取豆瓣图书top250信息_20170129
大年初二,忙完家里一些事,顺带有人交流爬取豆瓣图书top250 1.构造urls列表 urls=['https://book.douban.com/top250?start={}'.format(st ...
- Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP.但也不要太频繁爬取. 涉及知识点:requests.html.xpath.csv 一.准备工作 需要安装reques ...
- 实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB 豆瓣TOP网址:传送门 一.连接数据库 打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,d ...
- 实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev 网址:https://book.douban.com/top250?start=0 from lxml import etree #解析提取数据 ...
- 爬取豆瓣电影top250并存储到mysql数据库
import requests from lxml import etree import re import pymysql import time conn= pymysql.connect(ho ...
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- python系列之(3)爬取豆瓣图书数据
上次介绍了beautifulsoup的使用,那就来进行运用下吧.本篇将主要介绍通过爬取豆瓣图书的信息,存储到sqlite数据库进行分析. 1.sqlite SQLite是一个进程内的库,实现了自给自足 ...
- 【Python数据分析】Python3操作Excel-以豆瓣图书Top250为例
本文利用Python3爬虫抓取豆瓣图书Top250,并利用xlwt模块将其存储至excel文件,图片下载到相应目录.旨在进行更多的爬虫实践练习以及模块学习. 工具 1.Python 3.5 2.Bea ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
随机推荐
- posix 正则库程序
使用的是posix 正则库,参考: http://see.xidian.edu.cn/cpp/html/1428.html 执行匹配的时: gcc myreg.c ip.pat 内容: ip.*[0- ...
- HDU - 6025 Coprime Sequence(gcd+前缀后缀)
Do you know what is called ``Coprime Sequence''? That is a sequence consists of nnpositive integers, ...
- iOS三方支付--微信支付/支付宝支付
一.微信支付 1.注册账号并申请app支付功能 公司需要到微信开放品台进行申请app支付功能 , 获得appid和微信支付商户号(mch_id)和API秘钥(key) . Appsecret(secr ...
- 从扫码支付想到的超级APP主宰一切,数据!数据!还是数据!
前言 做室内定位的人其实内心都明白:基于指纹方法的移动端定位,无论paper每年出来多少,距离真正的大规模应用的距离还有多么遥远.指纹采集,指纹更新,似乎在生产实践上就是不可能的难题.所有还在基于人工 ...
- 洛谷 - P3952 - 时间复杂度 - 模拟
https://www.luogu.org/problemnew/show/P3952 这个模拟,注意每次进入循环的时候把新状态全部入栈,退出循环的时候就退栈. 第一次就错在发现ERR退出太及时,把剩 ...
- poj3164(最小树形图&朱刘算法模板)
题目链接:http://poj.org/problem?id=3164 题意:第一行为n, m,接下来n行为n个点的二维坐标, 再接下来m行每行输入两个数u, v,表点u到点v是单向可达的,求这个有向 ...
- bzoj 2535: [Noi2010]Plane 航空管制2【拓扑排序+堆】
有个容易混的概念就是第一问的答案不是k[i]字典序最小即可,是要求k[i]大的尽量靠后,因为这里前面选的时候是对后面有影响的(比如两条链a->b c->d,ka=4,kb=2,kc=3,k ...
- Codevs 1688 求逆序对(权值线段树)
1688 求逆序对 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 查看运行结果 题目描述 Description 给定一个序列a1,a2,…, ...
- NET Core 2.0 介绍和使用
NET Core 2.0 特性介绍和使用指南 阅读目录 前言 特性概述 使用指南 .NET Core 2.0和1.0/1.1之间的关系 .NET CORE Rumtime改进 .NET Core SD ...
- @Slf4j注解的使用
项目中使用Slf4j日志: private static final Logger log=LoggerFactory.getLogger(TestMain.class); 使用@Slf4j以后,默认 ...