Linux内核中链表的学习
一、自己学习链表
数组的缺点:(1)数据类型一致;(2)数组的长度事先定好,不能灵活更改。
从而引入了链表来解决数组的这些缺点:(1)结构体解决多数据类型(2)链表的组合使得链表的长度可以灵活设置。
基本概念:
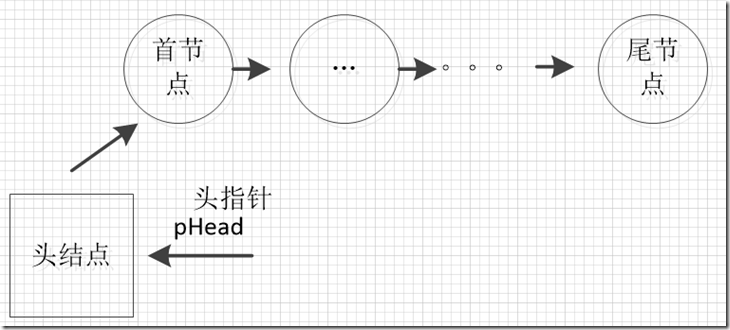
头结点:
这个节点是为了便于管理链表的节点,这个节点并不保存数据;虽然和其他节点一样,但是这个头结点是指向首节点的节点。
首节点:
第一个保存有效数据的节。
尾节点:
最后一个保存有效数据的节点
头指针:
头指针是指向头节点的指针。
单链表:
链表节点的数据结构定义:
- typedef struct Node
- {
- int data;
- struct Node *PNEXT;
- }NODE,*PNODE;
单链表的代码:
- typedef struct Node
- {
- int data;
- struct Node *PNEXT;
- }NODE,*PNODE;
- // 创建链表的节点
- PNODE create_node(int data)
- {
- // 创建结点
- PNODE p = (PNODE)malloc(sizeof(NODE));
- if (NULL == p)
- {
- printf("malloc error\n");
- exit(-);
- }
- memset(p, , sizeof(NODE));
- p->data = data;
- p->PNEXT = NULL;
- return p;
- }
- // 链表的初始化
- PNODE create_list()
- {
- int iLen_list = ;
- int iData_list = ;
- // 创建头结点
- PNODE pHead = NULL;
- pHead = (PNODE)malloc(sizeof(NODE));
- if (NULL == pHead)
- {
- printf("malloc pHead error\n");
- exit(-);
- }
- pHead->data = NULL;
- pHead->PNEXT = NULL;
- // 定义一个尾指针
- PNODE pTail = pHead;
- printf("输出链表的长度,n = \n");
- scanf("%d", &iLen_list);
- // 初始化创建节点的数据
- for (size_t i = ; i < iLen_list; i++)
- {
- PNODE pNew = NULL;
- printf("输出链表第 %d 个的值", i + );
- scanf("%d", &iData_list);
- // 创建节点
- pNew = create_node(iData_list);
- // 保证尾指针是一直指向最后一个节点
- pTail->PNEXT = pNew;
- pTail = pNew;
- }
- return pHead;
- }
- // 判断链表是否为空
- bool is_list_empty(PNODE pHead)
- {
- if (pHead->PNEXT == nullptr)
- return true;
- else
- return false;
- }
- // 链表的长度
- int len_list(PNODE pHead)
- {
- PNODE pNew = pHead;
- int i = ;
- while ( pNew->PNEXT != nullptr )
- {
- i++;
- pNew = pNew->PNEXT;
- }
- return i;
- }
- // 遍历链表的所有节点
- void traver_all_list(PNODE pHead)
- {
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- exit(-);
- }
- PNODE pNew = pHead;
- while (pNew->PNEXT != nullptr )
- {
- pNew = pNew->PNEXT;
- printf("%d\n", pNew->data);
- }
- }
- // 链表的尾部添加数据
- bool list_append_tail(PNODE pHead,int data)
- {
- int i = NULL;
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- return false;
- }
- PNODE pNew = pHead;
- while ((pNew->PNEXT != nullptr) )
- { // pNew 最后指向最后一个节点
- pNew = pNew->PNEXT;
- }
- PNODE pNewOne = create_node(data);
- pNew->PNEXT = pNewOne;
- pNewOne->data = data;
- pNewOne->PNEXT = nullptr;
- return true;
- }
- // 链表的尾部插入数据
- bool list_insert_tail(PNODE pHead, int data)
- {
- int i = NULL;
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- return false;
- }
- PNODE pNew = pHead;
- while ( (pNew->PNEXT != nullptr) && ( i<len_list(pHead) - ) )
- { // pNew 最后指向最后一个节点
- pNew = pNew->PNEXT;
- i++;
- }
- PNODE pNewOne = create_node(data);
- pNewOne->PNEXT = pNew->PNEXT;
- pNewOne->data = data;
- pNew->PNEXT = pNewOne;
- return true;
- }
- // 链表的头也就是添加一个新的链表的首节点
- bool list_insert_head(PNODE pHead, int data)
- {
- PNODE pNew = pHead;
- // 创建新的首节点,并使之节点指向旧的首节点
- PNODE pNewOne = create_node(data);
- pNewOne->data = data;
- pNewOne->PNEXT = pNew->PNEXT;
- // 头结点指向首节点
- pNew->PNEXT = pNewOne;
- return true;
- }
- // 插入链表 N 位置
- bool list_N_insert(PNODE pHead,int n, int data)
- {
- PNODE pNew = pHead;
- int i = ;
- // 空的链表就不要插入了
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- return false;
- }
- // 插入首节点
- if (n >len_list(pHead) + )
- {
- cout << "添加的位置大于链表的长度" << endl;
- return false;
- }
- else if ( == n )
- {
- return list_insert_head(pHead,data);
- }
- else if (n == len_list(pHead))
- {
- // 插入尾节点
- return list_insert_tail(pHead,data);
- }
- else
- {
- while ( (pNew->PNEXT != nullptr) && (i<n-))
- {
- // 在 N 的位置插入,则必须使得 pNew 指向 n-1 的位置
- pNew = pNew->PNEXT;
- i++;
- }
- PNODE pNewOne = create_node(data);
- pNewOne->data = data;
- pNewOne->PNEXT = pNew->PNEXT;
- pNew->PNEXT = pNewOne;
- return true;
- }
- }
- // 删除链表的首节点
- bool delete_list_heap(PNODE pHead)
- {
- if (is_list_empty(pHead))
- { // 空的链表的话,就没有什么好删除的
- printf("空链表,不需要删除\n");
- return false;
- }
- // 指向首节点
- PNODE pNew = pHead->PNEXT;
- // 头结点指向第二个节点
- pHead->PNEXT = pNew->PNEXT;
- cout << "删除节点的数值是:" << pNew->data << endl;
- free (pNew);
- pNew = nullptr;
- return true;
- }
- // 删除链表的尾节点
- bool delete_list_tail(PNODE pHead)
- {
- int i = NULL;
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- return false;
- }
- PNODE pNew = pHead;
- while ((pNew->PNEXT != nullptr) && (i < len_list(pHead))-)
- { // 使得 pNew 指向尾节点的倒数一个节点
- pNew = pNew->PNEXT;
- i++;
- }
- PNODE pDelOne = pNew->PNEXT;
- cout << "删除节点的数值是:" << pDelOne->data << endl;
- pNew->PNEXT = nullptr;
- free(pDelOne);
- pDelOne = nullptr;
- return true;
- }
- // 删除链表 N 位置
- bool delete_N_list(PNODE pHead, int n)
- {
- PNODE pNew = pHead;
- int i = ;
- // 空的链表就不要插入了
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- return false;
- }
- if (n > len_list(pHead))
- {
- cout << "删除的位置大于链表的长度" << endl;
- return false;
- }
- else if ( == n )
- {// 删除首节点
- return delete_list_heap(pHead);
- }
- else if (n == len_list(pHead))
- { // 删除尾节点
- return delete_list_tail(pHead);
- }
- else
- { // 删除除了首节点尾节点以外的节点,pNew 指向删除节点前面的那个节点
- while ((pNew->PNEXT != nullptr) && (i<n-) )
- {
- pNew = pNew->PNEXT;
- i++;
- }
- PNODE pDelOne = pNew->PNEXT;
- pNew->PNEXT = pDelOne->PNEXT;
- cout << "删除节点的数值是:" << pDelOne->data << endl;
- free(pDelOne);
- pDelOne = nullptr;
- return true;
- }
- }
- // 链表的排序
- bool sort_list(PNODE pHead)
- {
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- return false;
- }
- int n = len_list(pHead);
- PNODE pp = nullptr;
- PNODE qq = nullptr;
- int i, j;
- int Temp;
- for (pp = pHead->PNEXT, i = ; i < n-; i++, pp = pp->PNEXT)
- {
- for (qq = pp->PNEXT, j = i+; j < n; j++,qq = qq->PNEXT)
- {
- if ( pp->data > qq->data )
- {
- Temp = pp->data;
- pp->data = qq->data;
- qq->data = Temp;
- }
- }
- }
- return true;
- }
- int main(int argc, char *argv[])
- {
- PNODE pHead = NULL;
- int iLen_lis = NULL;
- // 创建链表已经初始化
- pHead = create_list();
- // 链表的遍历
- traver_all_list(pHead);
- // 计算链表长度
- iLen_lis = len_list(pHead);
- cout << "链表的长度是:" << iLen_lis << endl;
- // 链表尾部添加数据
- if (list_append_tail(pHead, ))
- {
- cout << "链表的尾部添加数据成功" << endl;
- iLen_lis = len_list(pHead);
- cout << "链表的长度是:" << iLen_lis << endl;
- traver_all_list(pHead);
- }
- // 链表头部添加数据
- cout << endl;
- if (list_insert_head(pHead, ))
- {
- cout << "链表的首节点添加数据成功" << endl;
- iLen_lis = len_list(pHead);
- cout << "链表的长度是:" << iLen_lis << endl;
- traver_all_list(pHead);
- }
- // 指定位置插入数据
- cout << endl;
- if (list_N_insert(pHead,,))
- {
- cout << "插入成功" << endl;
- iLen_lis = len_list(pHead);
- cout << "链表的长度是:" << iLen_lis << endl;
- traver_all_list(pHead);
- }
- // 指定位置删除数据
- cout << endl;
- if (delete_N_list(pHead, ))
- {
- cout << "删除成功" << endl;
- iLen_lis = len_list(pHead);
- cout << "链表的长度是:" << iLen_lis << endl;
- traver_all_list(pHead);
- }
- // 链表的排序
- cout << endl;
- if ( sort_list(pHead) )
- {
- cout << "排序成功" << endl;
- traver_all_list(pHead);
- }
- while ();
- }
经过自己的实测是正确的:
- 输出链表的长度,n =
- 输出链表第 个的值1
- 输出链表第 个的值2
- 输出链表第 个的值3
- 链表的长度是:
- 链表的尾部添加数据成功
- 链表的长度是:
- 链表的首节点添加数据成功
- 链表的长度是:
- 插入成功
- 链表的长度是:
- 删除节点的数值是:
- 删除成功
- 链表的长度是:
- 排序成功
补充:单链表的逆序
- bool reverse_list(PNODE pHead)
- {
- if (is_list_empty(pHead))
- {
- printf("空链表\n");
- return false;
- }
- PNODE Temp0 = pHead;
- PNODE Temp1 = pHead;
- PNODE Temp3 = pHead->PNEXT;
- PNODE Temp2 = nullptr;
- int i = ;
- while (Temp3->PNEXT != nullptr)
- {
- Temp2 = Temp3;
- Temp3 = Temp3->PNEXT;
- if ( == i)
- {
- Temp2->PNEXT = nullptr;
- }
- else
- {
- Temp2->PNEXT = Temp1;
- }
- i++;
- Temp1 = Temp2;
- }
- Temp3->PNEXT = Temp2;
- Temp0->PNEXT = Temp3;
- return true;
- }
传入了头结点的指针,
首先 T2 接替 T3,T2指向了下一个节点,而 T1 接替 T2,就这样一部一部,使之 T2 永远指向 T1,当 T3 结束的时候,T3 是没有指向 T2 的,所以退出循环就执行Temp3->PNEXT = Temp2;,而头结点 T0->PNEXT
= T3.
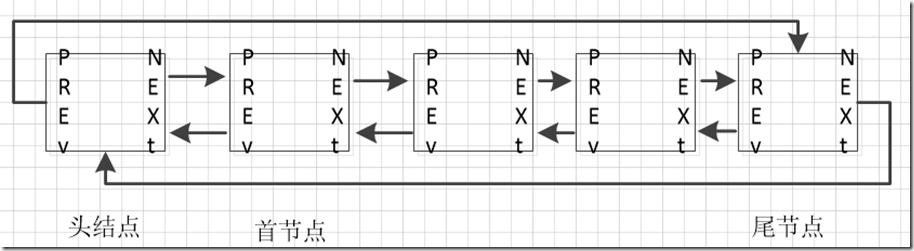
双链表:
因为单链表的操作的不便(一旦指针指向一个节点,就无法返回来,必须重新进行循环),所以就引入了双向链表。
双向链表的数据定义:
- typedef struct Node
- {
- int data;
- struct Node * PPREV;
- struct Node * PNEXT;
- }NODE, *PNODE;
因为是双向链表,所以就定义了两个指向节点的指针,prev 往前指,next 指向后面的节点。
特殊的是:头结点的 prev 是指向尾节点(最后一个节点),而尾节点的 next 是指向头结点的。
代码:
- #define DEBUG
- #ifdef DEBUG
- #define DBG(fmt, args,...) printf(fmt, ##args)
- #else
- #define DBG(fmt, args...) do {} while (0)
- #endif
- typedef struct Node
- {
- int data;
- struct Node * PPREV;
- struct Node * PNEXT;
- }NODE, *PNODE;
- // 创建单个节点
- PNODE create_node(int data)
- {
- PNODE pNew = nullptr;
- pNew = (PNODE)malloc(sizeof(NODE));
- if ( nullptr == pNew)
- {
- cout << " malloc error" << endl;
- exit(-);
- }
- pNew->PNEXT = nullptr;
- pNew->PPREV = nullptr;
- pNew->data = data;
- return pNew;
- }
- // 链表的初始化
- PNODE create_list()
- {
- int i = ;
- int iLenList = NULL;
- int iDataList = NULL;
- PNODE pHead = nullptr;
- PNODE pTail = nullptr;
- pHead = (PNODE)malloc(sizeof(NODE));
- if ( nullptr == pHead )
- {
- cout << " malloc error" << endl;
- exit(-);
- }
- pHead->data = NULL;
- pHead->PNEXT = pHead->PPREV = nullptr;
- pTail = pHead;
- printf("输入链表的长度 n = ");
- scanf("%d", &iLenList);
- for ( i = ; i < iLenList; i++)
- {
- printf("输入创建 第 %d 节点的数据\n", i + );
- scanf("%d", &iDataList);
- PNODE pNew = create_node( iDataList );
- pTail->PNEXT = pNew;
- pHead->PPREV = pNew;
- pNew->PPREV = pTail;
- pNew->PNEXT = pHead;
- pTail = pNew;
- }
- return pHead;
- }
- bool list_is_empty(PNODE pHead)
- {
- PNODE pNew = pHead;
- if ( pNew->PNEXT == nullptr )
- {
- return true;
- }
- else
- {
- return false;
- }
- }
- // 双向链表的遍历
- bool traver_list(PNODE pHead)
- {
- if ( list_is_empty(pHead))
- {
- cout << "空链表" << endl;
- return false;
- }
- PNODE pNew = pHead, pHeadNew = pHead;
- while (pNew->PNEXT != pHeadNew)
- {
- pNew = pNew->PNEXT;
- cout << pNew->data << endl;
- }
- return true;
- }
- // 计算链表的长度
- int len_list(PNODE pHead)
- {
- PNODE pHeadNew = pHead;
- int i = NULL;
- PNODE pNew = pHead;
- while ( pNew->PNEXT != pHeadNew )
- {
- pNew = pNew->PNEXT;
- i++;
- }
- return i;
- }
- // 链表的尾部添加数据
- bool list_tail_append_data(PNODE pHead, int data)
- {
- PNODE pHeadNew = pHead;
- PNODE pTail = pHead;
- DBG("%d \n", __LINE__);
- int n = len_list(pHead);
- int i = ;
- // 抱枕 pTail 指向最后一个节点
- while ( i < (n) ) // 从头结点到尾节点需要移动 n(链表长度)次数
- {
- pTail = pTail->PNEXT;
- i++;
- }
- // 创建新的节点
- PNODE pNewOne = (PNODE)malloc(sizeof(NODE));
- if ( nullptr == pNewOne )
- {
- cout << "malloc error" << endl;
- return false;
- }
- pNewOne->data = data;
- DBG("%d \n", __LINE__);
- pTail->PNEXT = pNewOne;
- pNewOne->PPREV = pTail;
- pNewOne->PNEXT = pHeadNew;
- pHeadNew->PPREV = pNewOne;
- DBG("%d \n", __LINE__);
- return true;
- }
- // 链表的头部添加数据
- bool list_heap_insert_data(PNODE pHead, int data)
- {
- if ( list_is_empty(pHead))
- {
- printf("空链表 \n");
- return false;
- }
- PNODE pHeadNew = pHead;
- PNODE pNewOne = (PNODE)malloc(sizeof(NODE));
- pNewOne->data = data;
- pNewOne->PNEXT = pHeadNew->PNEXT;
- pHeadNew->PNEXT->PPREV = pNewOne;
- pHeadNew->PNEXT = pNewOne;
- return true;
- }
- bool list_tail_insert(PNODE pHead,int data)
- {
- PNODE pHeadNew = pHead;
- PNODE pNew = pHead;
- int i = ;
- int n = len_list(pHeadNew);
- while (i<(n-))
- { // pNew 指向尾节点的前面一个节点,
- i++;
- pNew = pNew->PNEXT;
- }
- PNODE pNewOne = (PNODE)malloc(sizeof(NODE));
- pNewOne->data = data;
- pNewOne->PNEXT = pNew->PNEXT;
- pNew->PNEXT->PPREV = pNewOne;
- pNewOne->PNEXT = pNew;
- pNew->PNEXT = pNewOne;
- return true;
- }
- // 指定位置插入数据
- bool list_N_insert(PNODE pHead, int iPos, int data)
- {
- PNODE pHeadNew = pHead;
- PNODE pNew = pHead;
- if (list_is_empty(pHead))
- {
- printf("空链表 \n");
- return false;
- }
- int i = NULL;
- int n = len_list(pHeadNew);
- if ( iPos > n)
- {
- printf("出入位置大于链表的长度,不能执行插入\n");
- return false;
- }
- else if ( n == )
- {// 在首结点插入数据
- return list_heap_insert_data(pHeadNew, data);
- }
- else if ( n == iPos)
- {// 在尾节点插入数据
- return list_tail_insert(pHeadNew,data);
- }
- else
- {
- // 在除了尾节点首节点插入数据
- while (i < (iPos - ))
- {// 使得 pNew 指向删除节点的前面一个节点
- pNew = pNew->PNEXT;
- i++;
- }
- PNODE pNewOne = create_node(data);
- pNewOne->PNEXT = pNew->PNEXT;
- pNew->PNEXT->PPREV = pNewOne;
- pNew->PNEXT = pNewOne;
- pNewOne->PPREV = pNew;
- return true;
- }
- }
- // 删除链表首节点
- bool delete_heap_list(PNODE pHead)
- {
- PNODE pHeadNew = pHead;
- PNODE pNew;
- int n = len_list(pHead);
- if ( n == )
- {
- pNew = pHeadNew->PNEXT;
- pHeadNew->PNEXT = pHeadNew;
- pHeadNew->PNEXT = pHeadNew;
- printf("删除数据是%d\n", pNew->data);
- free(pNew);
- pNew = nullptr;
- return true;
- }
- else
- {
- pNew = pHeadNew->PNEXT;
- pHeadNew->PNEXT = pHeadNew->PNEXT->PNEXT;
- pHeadNew->PNEXT->PPREV = pHeadNew;
- printf("删除数据是%d\n", pNew->data);
- free(pNew);
- pNew = nullptr;
- return true;
- }
- }
- // 删除链表的尾节点
- bool delete_tail_list(PNODE pHead)
- {
- PNODE pHeadNew = pHead;
- PNODE pNew = pHead;
- PNODE pNewOne = nullptr;
- int n = len_list(pHead);
- int i = NULL;
- while (i < (n - ))
- {// pNew 指向删除节点的前面一个节点
- pNew = pNew->PNEXT;
- i++;
- }
- pNewOne = pNew->PNEXT;
- printf("删除数据是%d\n", pNewOne->data);
- pNew->PNEXT = pHeadNew;
- pHeadNew->PPREV = pNew;
- free(pNewOne);
- pNewOne = nullptr;
- return true;
- }
- // 删除链表的任意的位置
- bool delete_N_list(PNODE pHead,int iPos)
- {
- if (list_is_empty(pHead))
- {
- printf("空链表 \n");
- return false;
- }
- PNODE pNew = pHead;
- PNODE pNewOne = pHead;
- int i = NULL;
- int n = len_list(pHead);
- if (iPos > n)
- {
- printf("删除位置大于链表的长度,不能执行删除\n");
- return false;
- }
- else if ( iPos == )
- {
- return delete_heap_list(pHead);
- }
- else if (iPos == n)
- {
- return delete_tail_list(pHead);
- }
- else
- {
- while (i<(iPos - ))
- {
- pNew = pNew->PNEXT;
- i++;
- }
- pNewOne = pNew->PNEXT;
- pNew->PNEXT = pNewOne->PNEXT;
- pNewOne->PNEXT->PPREV = pNew;
- printf("删除数据是%d\n", pNewOne->data);
- free(pNewOne);
- pNewOne = nullptr;
- return true;
- }
- }
- // 对链表进行排序
- bool list_sort(PNODE pHead)
- {
- if (list_is_empty(pHead))
- {
- printf("空链表,排序失败\n");
- return false;
- }
- int n = len_list(pHead);
- PNODE ppNew = nullptr;
- PNODE qqNew = nullptr;
- int i = , j = ;
- int TempDat = NULL;
- for (ppNew = pHead->PNEXT, i = ; i < (n - );i++,ppNew = ppNew->PNEXT)
- {
- for (qqNew = ppNew->PNEXT, j = i+; j < n;j++,qqNew=qqNew->PNEXT)
- {
- if ( ppNew->data > qqNew->data)
- {
- TempDat = ppNew->data;
- ppNew->data = qqNew->data;
- qqNew->data = TempDat;
- }
- }
- }
- return true;
- }
- int main(int argc, char **argv)
- {
- int iLenList = NULL;
- PNODE pHead = nullptr;
- // 双向链表的初始化
- pHead = create_list();
- if (traver_list(pHead))
- {
- cout << "遍历成功" << endl;
- }
- iLenList = len_list(pHead);
- printf("链表长度等于 %d\n", iLenList);
- // 链表的尾部添加数据
- if (list_tail_append_data(pHead, ))
- {
- list_tail_append_data(pHead, );
- printf("尾部添加数据成功\n");
- traver_list(pHead);
- }
- if (list_heap_insert_data(pHead, ))
- {
- list_heap_insert_data(pHead, );
- printf("头部添加数据成功\n");
- traver_list(pHead);
- }
- // 链表的任意位置添加数据
- if (list_N_insert(pHead,,))
- {
- printf("位置3添加数据成功\n");
- traver_list(pHead);
- }
- // 任意位置删除数据
- if (delete_N_list(pHead, ))
- {
- printf("位置8删除数据成功\n");
- traver_list(pHead);
- }
- // 排序
- if ( list_sort(pHead) )
- {
- printf("排序成功\n");
- traver_list(pHead);
- }
- while ();
- }
双链表和单链表的操作其实很多的类似,参考者编写代码,还是比较简单的。参照了单链表,也是设置了头结点用于帮助设计双向链表,然后还有首尾节点,这些才是正真保存数据的开始的节点和结束的节点。
二、内核链表的学习
对于链表的操作自己编写的话过于麻烦,而Linux内核提供了对应的API,可以直接调用方便使用:D:\source insight\linux2.6.35.7\android-kernel-samsung-dev\include\linux 的 list.h。
0、链表节点的指针
- struct list_head
- {
- struct list_head *next, *prev;
- };
链表结构体的指针有两个:next 指向下一个节点,prev 指向上一个节点。也就是说内核链表具备了双向链表的功能,而且链表只是纯链表,并不具备数据类型,所以具备非常大的通用性,这样可以自己根据自己的实际的需求去设计。
1、链表头结点的初始化
(1)定义且初始化
- #define LIST_HEAD_INIT(name) { &(name), &(name) }
- #define LIST_HEAD(name) \
- struct list_head name = LIST_HEAD_INIT(name)
链表头结点定义的时候且完成初始化,将上面的宏进行进行展开:
- #define LIST_HEAD(name) \
- struct list_head name = { &(name), &(name) }
是将链表的头结点的两个指针分别都指向了自己,从而完成链表头结点的初始化。
(2)先定义后完成初始化
- static inline void INIT_LIST_HEAD(struct list_head *list)
- {
- list->next = list;
- list->prev = list;
- }
对于一个已经完成链表头节点初始化,那么对这个链表头则是调用这个函数来完成初始化。这里函数实现链表头节点的初始化与上面宏完成初始化是一样的,差别无非是定义且初始化,一个是先定义头结点后完成初始化。
2、链表节点的添加
- static inline void __list_add(struct list_head *new,
- struct list_head *prev,
- struct list_head *next)
- {
- next->prev = new;
- new->next = next;
- new->prev = prev;
- prev->next = new;
- }
对于链表节点的添加,这里需要知道,默认的都是进行尾添加,也就是在节点的后面进行添加。
注意:
学习发现,内核的双向链表是其实也是借助了头结点了。
2.1、链表的头结点进行添加
- static inline void list_add(struct list_head *new, struct list_head *head)
- {
- __list_add(new, head, head->next);
- }
new 指向全新的节点,而 head 是指向头节点,而head->next 是指头首节点的下一个节点,也就是第二个节点。所以插入的节点 new 是在第一个和第二个节点直接之间完成节点的插入。
2.2、链表尾部节点的添加
- static inline void list_add_tail(struct list_head *new, struct list_head *head)
- {
- __list_add(new, head->prev, head);
- }
new 指向新的节点,而 head->prev 指向链表的尾节点,head 指向链表的首节点。所以 new 是被插入在首节点和尾节点之间。
3、链表删除一个节点
- static inline void __list_del(struct list_head * prev, struct list_head * next)
- {
- next->prev = prev;
- prev->next = next;
- }
- static inline void list_del(struct list_head *entry)
- {
- __list_del(entry->prev, entry->next);
- entry->next = LIST_POISON1;
- entry->prev = LIST_POISON2;
- }
entry 是指向删除节点的指针。 entry->prev 是指向删除节点的前面一个节点,而 entrt->next 指向删除节点的下一个节点。而将删除节点的 prev 和 next 分别设置为 position,对它的定义为:
- /*
- * These are non-NULL pointers that will result in page faults
- * under normal circumstances, used to verify that nobody uses
- * non-initialized list entries.
- */
- #define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
- #define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)
理解内核的注释, position 不是一个空指针,但是会引起页的错误。
4、节点的替换
- static inline void list_replace(struct list_head *old,
- struct list_head *new)
- {
- new->next = old->next;
- new->next->prev = new;
- new->prev = old->prev;
- new->prev->next = new;
- }
代码还是比较的简单,完成新老节点替换,使得新的节点的指针指向老节点的指向。
- static inline void list_replace_init(struct list_head *old,
- struct list_head *new)
- {
- list_replace(old, new);
- INIT_LIST_HEAD(old);
- }
完成新老节点的替换,然后将老节点进行初始化。
5、节点的移动
- /**
- * list_move - delete from one list and add as another's head
- * @list: the entry to move
- * @head: the head that will precede our entry
- */
- static inline void list_move(struct list_head *list, struct list_head *head)
- {
- __list_del(list->prev, list->next);
- list_add(list, head);
- }
将 list 指向的节点从 head 为开始的头结点的链表删除之后,又移动到这个链表的首节点。也就是在头结点的后面。
- /**
- * list_move_tail - delete from one list and add as another's tail
- * @list: the entry to move
- * @head: the head that will follow our entry
- */
- static inline void list_move_tail(struct list_head *list,
- struct list_head *head)
- {
- __list_del(list->prev, list->next);
- list_add_tail(list, head);
- }
将节点 list 从链表 中删除,并将节点 list 添加到链表(以 head 为头结点)的尾部。
6、链表的判断
- /**
- * list_is_last - tests whether @list is the last entry in list @head
- * @list: the entry to test
- * @head: the head of the list
- */
- static inline int list_is_last(const struct list_head *list,
- const struct list_head *head)
- {
- return list->next == head;
- }
判断节点 list 是不是链表的最后一个节点。
list 是判断的链表的节点。
head:是双向量表的头结点。
代码和简单,就是判断 list 节点的下一个节点是不是 head(头结点)。
- /**
- * list_empty - tests whether a list is empty
- * @head: the list to test.
- */
- static inline int list_empty(const struct list_head *head)
- {
- return head->next == head;
- }
判断链表是否为空:
其实就是判断自己的下一个节点是不是指向了自己,因为只有空的链表,也就是只有一个头结点的话,才会自己指向自己。
- /**
- * list_empty_careful - tests whether a list is empty and not being modified
- * @head: the list to test
- *
- * Description:
- * tests whether a list is empty _and_ checks that no other CPU might be
- * in the process of modifying either member (next or prev)
- *
- * NOTE: using list_empty_careful() without synchronization
- * can only be safe if the only activity that can happen
- * to the list entry is list_del_init(). Eg. it cannot be used
- * if another CPU could re-list_add() it.
- */
- static inline int list_empty_careful(const struct list_head *head)
- {
- struct list_head *next = head->next;
- return (next == head) && (next == head->prev);
- }
判断链表是否为空,这次的判断是通过头结点的前驱和后驱是不是指向同一个节点。按照字面上面的解释,是怕在判断的时候被CPU 的其他的线程修改了数据,因此这种判断的方法是比较的正确的。
7、链表的首节点放到尾节
- /**
- * list_rotate_left - rotate the list to the left
- * @head: the head of the list
- */
- static inline void list_rotate_left(struct list_head *head)
- {
- struct list_head *first;
- if (!list_empty(head)) {
- first = head->next;
- list_move_tail(first, head);
- }
- }
显示判断链表不为空的时候,让链表的首节点放到尾节点。
8、判断链表是否只有一个的节点(首节点)
- /**
- * list_is_singular - tests whether a list has just one entry.
- * @head: the list to test.
- */
- static inline int list_is_singular(const struct list_head *head)
- {
- return !list_empty(head) && (head->next == head->prev);
- }
当链表只有一个节点的时候,也就是存在一个头结点和首节点,所以这个时候头结点的头指针和尾指针都是指向首节点的。
9、链表的遍历
- #define list_entry(ptr, type, member) \
- container_of(ptr, type, member)
type :结构体的类型
member:结构体的成员变量
ptr:返回结构体的起始的地址,我估计这个点应该是链表的头结点的地址
- #define list_first_entry(ptr, type, member) \
- list_entry((ptr)->next, type, member)
返回结构体的初始地址的下一个节点的初始地址(我估计应该是链表的首节点的地址)。
上面的介绍,已经可以基本对内核有了基本的认识。
三、内核链表的使用
内核链表提供的都是纯链表,而对于链表的数据类型是通过自己灵活指定的,是将链表的结构整个内嵌到链表的结构体里面。
- struct
- {
- int goal;
- int id;
- struct list_head head;
- }
goal和 id 是数据,而 head 在是链表的指针的结构;而自己可以灵活去设置自己的数据区域。
因为单链表的操作的不便(一旦指针指向一个节点,就无法返回来,必须重新进行循环),所以就引入了双向链表。
对于链表的操作自己编写的话过于麻烦,而Linux内核提供了对应的API,可以直接调用方便使用:D:\source insight\linux2.6.35.7\android-kernel-samsung-dev\include\linux 的 list.h。
0、链表节点的指针
struct list_head
{
struct list_head *next, *prev;
};
链表结构体的指针有两个:next 指向下一个节点,prev 指向上一个节点。
1、链表头结点的初始化
(1)定义且初始化
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
链表头结点定义的时候且完成初始化,将上面的宏进行进行展开:
#define LIST_HEAD(name) \
struct list_head name = { &(name), &(name) }
是将链表的头结点的两个指针分别都指向了自己,从而完成链表头结点的初始化。
(2)先定义后完成初始化
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
对于一个已经完成链表头节点初始化,那么对这个链表头则是调用这个函数来完成初始化。这里函数实现链表头节点的初始化与上面宏完成初始化是一样的,差别无非是定义且初始化,一个是先定义头结点后完成初始化。
Linux内核中链表的学习的更多相关文章
- linux内核中链表代码分析---list.h头文件分析(一)【转】
转自:http://blog.chinaunix.net/uid-30254565-id-5637596.html linux内核中链表代码分析---list.h头文件分析(一) 16年2月27日17 ...
- linux内核中链表代码分析---list.h头文件分析(二)【转】
转自:http://blog.chinaunix.net/uid-30254565-id-5637598.html linux内核中链表代码分析---list.h头文件分析(二) 16年2月28日16 ...
- Linux内核中链表实现
关于双链表实现,一般教科书上定义一个双向链表节点的方法如下: struct list_node{ stuct list_node *pre; stuct list_node *next; ElemTy ...
- Linux内核中链表的实现与应用【转】
转自:http://blog.chinaunix.net/uid-27037833-id-3237153.html 链表(循环双向链表)是Linux内核中最简单.最常用的一种数据结构. ...
- Linux内核中的机制学习总结
一.驱动中的poll机制 1.简介:select()和poll()系统调用的本质一样,前者在 BSD UNIX 中引入的,后者在 System V 中引入的. 应用程序使用 select() 或 po ...
- Linux内核中的list用法和实现分析
这些天在思考知识体系的完整性,发现总是对消息队列的实现不满意,索性看看内核里面的链表实现形式,这篇文章就当做是学习的i笔记吧.. 内核代码中有很多的地方使用了list,而这个list的用法又跟我们平时 ...
- linux内核中的C语言常规算法(前提:你的编译器要支持typeof和type)
学过C语言的伙伴都知道,曾经比较两个数,输出最大或最小的一个,或者是比较三个数,输出最大或者最小的那个,又或是两个数交换,又或是绝对值等等,其实这些算法在linux内核中通通都有实现,以下的代码是我从 ...
- Linux内核中的算法和数据结构
算法和数据结构纷繁复杂,但是对于Linux Kernel开发人员来说重点了解Linux内核中使用到的算法和数据结构很有必要. 在一个国外问答平台stackexchange.com的Theoretica ...
- LINUX内核分析第二周学习总结——操作系统是如何工作的
LINUX内核分析第二周学习总结——操作系统是如何工作的 张忻(原创作品转载请注明出处) <Linux内核分析>MOOC课程http://mooc.study.163.com/course ...
随机推荐
- css iframe边框去掉
[IE6以下] iframe边框通过css设定在FF下正常在ie下却还存在边框,通过在iframe标签内部设置属性 frameborder="no" border="0& ...
- 【07】react 之 生命周期
阅读目录(Content) 实例化 getDefaultProps getInitialState componentWillMount render componentDidMount 存在期 co ...
- httpclient与webapi
System.Net.Http 是微软推出的最新的 HTTP 应用程序的编程接口, 微软称之为“现代化的 HTTP 编程接口”, 主要提供如下内容: 1. 用户通过 HTTP 使用现代化的 Web S ...
- linux解决无法打开资源管理器
前两天升级系统,使用命令pacman -Syyu,大概是使用的是testing缘故,今天发现dolphin无法打开了,使用命令行打开,提示ldmp.so有问题. 解决方法如下: 一,使用命令:pacm ...
- 一个.java文件定义多个类的情况
一个.java文件中定义多个类: 注意一下几点: (1) public权限类只能有一个(也可以一个都没有,但最多只有一个): (2)这个.java文件名只能是public 权限的类的类名: (3)倘若 ...
- Android进阶之Fragment与Activity之间的数据交互
1 为什么 因为Fragment和Activity一样是具有生命周期,不是一般的bean通过构造函数传值,会造成异常. 2 Activity把值传递给Fragment 2.1 第一种方式,也是最常用的 ...
- TensorFlow——Checkpoint为模型添加检查点
1.检查点 保存模型并不限于在训练模型后,在训练模型之中也需要保存,因为TensorFlow训练模型时难免会出现中断的情况,我们自然希望能够将训练得到的参数保存下来,否则下次又要重新训练. 这种在训练 ...
- 可靠UDP设计
最近加入了一个用帧同步的项目,帧同步方案对网络有着极大的影响,于是采用了RUDP(可靠UDP),那么为什么要摒弃TCP,而费尽心思去采用UDP呢?要搞明白这个问题,首先要了解TCP和UDP的区别 , ...
- CodeForces - 103D Time to Raid Cowavans
Discription As you know, the most intelligent beings on the Earth are, of course, cows. This conclus ...
- 分布式配置中心介绍--Spring Cloud学习第六天(非原创)
文章大纲 一.分布式配置中心是什么二.配置基本实现三.Spring Cloud Config服务端配置细节(一)四.Spring Cloud Config服务端配置细节(二)五.Spring Clou ...