SQL Server 深入解析索引存储(上)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/堆/聚集索引
概述
最近要分享一个课件就重新把这块知识整理了一遍出来,篇幅有点长,想要理解的透彻还是要上机实践。
聚集索引
--创建测试数据库
CREATE DATABASE Ixdata
GO
USE [Ixdata]
GO
---创建测试表
CREATE TABLE Orders
(ID INT PRIMARY KEY IDENTITY(1,1),
NAME CHAR(80)NOT NULL,
IDATE DATETIME NOT NULL DEFAULT(GETDATE())
);
GO
---插入1000条测试数据
DECLARE @ID INT=1
WHILE(@ID<=1000)
BEGIN
INSERT INTO Orders(NAME)VALUES('商品'+CONVERT(NVARCHAR(20),@ID))
SET @ID=@ID+1
END
GO
SELECT * FROM Orders
GO
分析新创建的表的页的信息
---显示跟踪标志的状态
DBCC TRACESTATUS ---开启跟踪标志
DBCC TRACEON(3604,2588)
--DBCC TRACEOFF(3604,2588)
---获取对象的数据页,结构:数据库、对象、显示
DBCC IND(Ixdata,Orders,-1)
/*
1:显示所有分页的信息,包括IAM分页,数据分页,所有存在的LOB分页和行溢出页,索引分页
-1: 显示所有IAM、数据分页、及指定对象上全部索引的索引分页.
-2: 显示指定对象的所有IAM分页
0:显示所有IAM、数据分页.
*/
DBCC IND的表结构

还可以通过另一种方法来测试:
SELECT DISTINCT so.name, so.object_id,i.name AS index_name,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page
FROM sys.objects so
INNER JOIN sys.partitions sp ON so.object_id = sp.object_id
INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id
INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id
LEFT JOIN sys.indexes i ON so.object_id=i.object_id AND sp.index_id=i.index_id
WHERE so.object_id = object_id('orders')

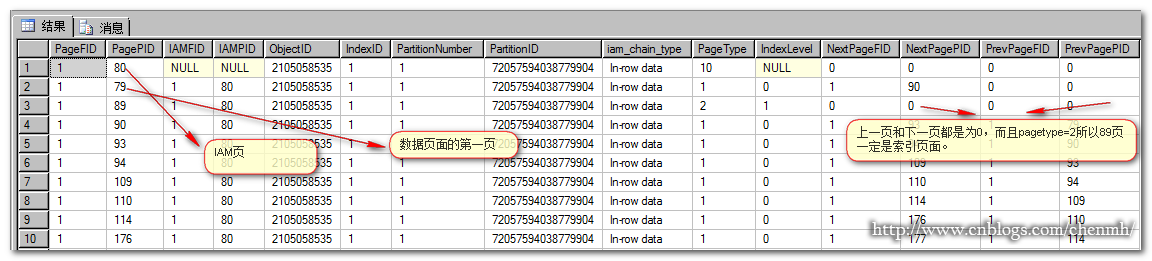
最后三个字段分别是IAM页,根页,和第一个数据页;它们分别用16进制来表示,拿first_iam_page来分析,首先将编码从右往左一个字节接着一个字节反过来排行(0X代表16进制),结果就是0X,00 01,00 00 00 50;前两个字节代表文件组号,最后4个字节代表页号。16进制的0001转换成10进制就是1;16进制的00 00 00 50转换成10进制就是5*16的1次方=5*16=80,所以第一个数据页是4*16+15=79,根页是5*16+9=89 结果和前面的查询出来的结果是一样的。从表格的otal_pages,used_pages,data_pages得到的结果也和前面查询出来的结果是一致的,总分配了17个页,使用了15个页包括13个数据页+1个IAM页+1个索引页。
手绘一张当前表格的聚集索引体系结构图:

分析索引页
---DBCC page的格式为(数据库,文件id,页号,显示)
DBCC page(Ixdata,1,89,3)

分析结果89页下面的子页总共有13页,每页80条记录,89索引页记录了每页的的键值的最小值,第一页就是id为1-80,第二页81-160,所以当你要找ID为150的数据的时候直接就可以去第90页里面找了。
PAGE HEADER

分析数据页

通过这些数据我们基本上可以知道90页的基本情况了,包括它的字段长度,上一页、下一页,还有该页的所以记录(这里没有截图出来).
插入20万条记录分析索引结构
--插入20万条记录分析索引结构
DECLARE @ID INT=1
WHILE(@ID<=200000)
BEGIN
INSERT INTO Orders(NAME)VALUES('商品'+CONVERT(NVARCHAR(20),@ID))
SET @ID=@ID+1
END CREATE TABLE Page
(
PageFID TINYINT,
PagePID INT,
IAMFID TINYINT,
IAMPID INT,
ObjectID INT,
IndexID TINYINT,
PartitionNumber TINYINT,
PartitionID BIGINT,
iam_chain_type VARCHAR(30),
PageType TINYINT,
IndexLevel TINYINT,
NextPageFID TINYINT,
NextPagePID INT,
PrevPageFID TINYINT,
PrevPagePID INT
);
GO
INSERT INTO Page EXEC('DBCC IND(Ixdata,Orders,-1)') ---查询索引页
SELECT [PageFID]
,[PagePID]
,[IAMFID]
,[IAMPID]
,[ObjectID]
,[IndexID]
,[PartitionNumber]
,[PartitionID]
,[iam_chain_type]
,[PageType]
,[IndexLevel]
,[NextPageFID]
,[NextPagePID]
,[PrevPageFID]
,[PrevPagePID]
FROM [Ixdata].[dbo].[Page]
WHERE PageType=2
go
select so.name, so.object_id, sp.index_id, internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page,
first_page, root_page
from sys.objects so
inner join sys.partitions sp on so.object_id = sp.object_id
inner join sys.allocation_units sa on sa.container_id = sp.hobt_id
inner join sys.system_internals_allocation_units internals on internals.container_id = sa.container_id
where so.object_id = object_id('orders')
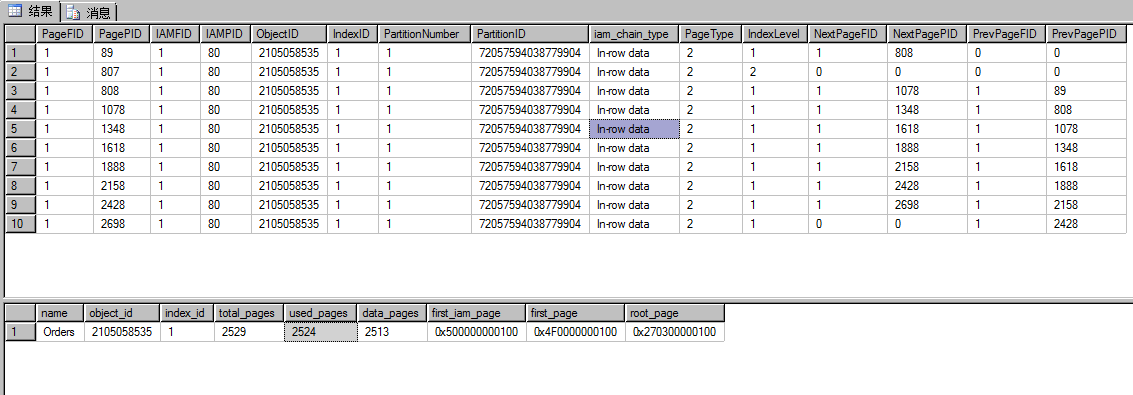
通过两种方法查询到的索引页的数量是一样的,下面的这种计算方法是2524-2513-1(IAM页)=10,其中807页是root_page页它在第二级,其它的是中间级索引页页就是第一级;页可以通过下面的16进制计算出来,IAM=5*16=80,ROOT_PAGE=3*16*16+2*16+7=807
再分析89页
---DBCC page的格式为(数据库,文件id,页号,显示)
DBCC page(Ixdata,1,89,3)
查询结果总共有269行,页就是269个数据页,orders表总共插入了201000条记录,一个页面存80条记录,就需要2513个页面和上面查询到的data_page是一样的。每个索引页存储269个数据页面就需要(‘select 2513*1.0/269’除不尽加1)10个索引页,查询最后一个索引页2698发现它还没分页共存储了361条记录,总共8*269+361=2513
手绘存储结构

手绘的有点难看,但是意思差不多表达出来了。
大型对象 (LOB) 列
根据聚集索引中的数据类型,每个聚集索引结构将有一个或多个分配单元,将在这些单元中存储和管理特定分区的相关数据。每个聚集索引的每个分区中至少有一个 IN_ROW_DATA 分配单元。如果聚集索引包含大型对象 (LOB) 列,则它的每个分区中还会有一个 LOB_DATA 分配单元。如果聚集索引包含的变量长度列超过 8,060 字节的行大小限制,则它的每个分区中还会有一个 ROW_OVERFLOW_DATA 分配单元。
---创建测试表
CREATE TABLE Orderslob
(ID INT PRIMARY KEY IDENTITY(1,1),
NAME CHAR(80)NOT NULL,
Product NVARCHAR(MAX) NOT NULL,
IDATE DATETIME NOT NULL DEFAULT(GETDATE())
);
GO
---插入1000条测试数据
DECLARE @ID INT=1
WHILE(@ID<=1000)
BEGIN
INSERT INTO Orderslob(NAME,Product)VALUES(CONVERT(NVARCHAR(20),@ID)+'商品',REPLICATE(@ID,2))
SET @ID=@ID+1
END
--REPLICATE(@ID,200)
GO DBCC IND(Ixdata,Orderslob,1)

--查看2719数据页的信息
DBCC page(Ixdata,1,2719,1)

结果记录了每一条记录的偏移量。
每个人在自己的电脑上面测试页面id会不一样,但是反应的结果是一样的。
总结
本来想全部写完的,等写完这部分的时候发现篇幅已经有点长了,而且自己也有的吃不消熬到1点才写完,接下来还有中下两部分会尽快在几天内写完,欢迎关注。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |
SQL Server 深入解析索引存储(上)的更多相关文章
- SQL Server 深入解析索引存储(下)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- SQL Server 深入解析索引存储(非聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- SQL Server 深入解析索引存储(中)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/堆 概述 本篇文章是关于堆的存储结构.堆是不含聚集索引的表(所以只有非聚集索引的表也是堆).堆的 sys.parti ...
- SQL Server 深入解析索引存储(堆)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/堆 概述 本篇文章是关于堆的存储结构.堆是不含聚集索引的表(所以只有非聚集索引的表也是堆).堆的 sys.parti ...
- SQL Server 深入解析索引存储(聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/堆/聚集索引 概述 最近要分享一个课件就重新把这块知识整理了一遍出来,篇幅有点长,想要理解的透彻还是要上机实践. 聚 ...
- SQL Server 表和索引存储结构
在上一篇文章中,我们介绍了SQL Server数据文件的页面类型,系统通过96个字节的头部信息和系统表从逻辑层面上将表的存储结构管理起来,具体到表的存储结构上,SQL Server引入对象.分区.堆或 ...
- SQL SERVER全面优化-------索引有多重要?
想了好久索引的重要性应该怎么写?讲原理结构?我估计大部分人不愿意看,也不愿意花那么多时间仔细研究.光写应用?感觉不明白原理一样不会用.举例说明?情况太多也写不全....到底该怎么写呢? 随便写吧,想到 ...
- SQL Server 堆表行存储大小(Record Size)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 堆表行记录存储格式(Heap) 案例分析(Case) 参考文献(References) 二.背 ...
- Sql Server系列:索引基础
1 索引概念 索引用于快速查找在某个列中某个特定值的行,不使用索引,数据库必须从第1条记录开始读完整个表,知道找出需要的行.表越大,查询数据所花费的时间越多.如果表中查询的列有索引,数据库能快速到达一 ...
随机推荐
- 在WebStorm环境中给nodejs项目中添加packages
照前文 http://www.cnblogs.com/wtang/articles/4133820.html 给电脑设置了WebStorm的IDE的nodejs开发环境.新建了个express的网站 ...
- for in 结构
in 运算符也是一个二元运算符,但是对运算符左右两个操作数的要求比较严格.in 运算符要求第 1 个(左边的)操作数必须是字符串类型或可以转换为字符串类型的其他类型,而第 2 个(右边的)操作数必须是 ...
- GAMBIT、ICEM、HYPERMESH耦合面的处理方法
前两天在论坛里碰到有朋友问关于使用fluent仿真流固耦合,使用hypermesh作为前处理时的耦合面的方法,刚好今天有点时间,借此机会总结一下GAMBIT.ICEM和HYPERMESH这三款软件作为 ...
- LeetCode 387. First Unique Character in a String
Problem: Given a string, find the first non-repeating character in it and return it's index. If it d ...
- Python for Infomatics 第14章 数据库和SQL应用三(译)
14.5 SQL 总结 到目前为止,我们在Python示例程序中使用了SQL,并且涉及了许多SQL基础.在这一小节中,我们特别审视SQL语言,并对其语法进行回顾. 虽然有很多不同的数据库供应商,但因S ...
- 浅说如何制作javascript类库
理论 对于静态的类来说,JavaScript 对象直接量就已经够用了,但使用继承和实例来创建经典的类往往更有帮助. JavaScript 是基于原型的编程语言,并没有包含内置类的实现. 但通过Java ...
- 第一章 DeepLab的创作动机
这一段时间一直在做深度学习方面的研究,目前市场上的深度学习工具主要分为两大块.一块是基于Python语言的theano:另一块是可以在多个语言上使用并能够在GPU和CPU之间随意切换的Caffe.但是 ...
- 从一个控制器调到另一个控制器的[UIViewController _loadViewFromNibNamed:bundle:]崩溃
一,现象和分析: 1.崩溃的主要地方是[UIViewController _loadViewFromNibNamed:bundle:] ,是从 A 控制器 push 到 B 控制器后, B 控制器的v ...
- duplicate symbols for architecture arm64 after xCode 8.0 update
Xcode IDE 从7.3.1 update 到 8.0 之后出现的问题 一个错误把我困扰了两天之久,最终找到解决办法我欣喜若狂. 错误发生原因:Xcode IDE 从7.3.1 update ...
- 运行错误:error while loading shared libraries: xxx.so.0:cannot open shared object file: No such file or
链接时可以通过-L和-l来指定自己的库,因此链接可以通过,但是运行时,系统仍无法找到指定的库,需要简单配置一下. 解决方法: 可以直接在将自己的库所在路径添加到/etc/ld.so.conf文件中.但 ...