推荐系统系列(六):Wide&Deep理论与实践
背景
在CTR预估任务中,线性模型仍占有半壁江山。利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,且可解释性强。但这种方式有着较为明显的缺点:首先,特征工程需要耗费太多精力。其次,因为模型是强行记住这些组合特征的,所以对于未曾出现过的特征组合,权重系数为0,无法进行泛化。
为了加强模型的泛化能力,研究者引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。但是,现实世界是没有银弹的。基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。
2016年,Google提出Wide&Deep模型,将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。Wide&Deep这种线性模型与DNN的并行连接模式,后来成为推荐领域的经典模式。今天与大家一起分享这篇paper,向经典学习。
分析
1. Motivation
在这篇论文中,主要围绕模型的两部分能力进行探讨:Memorization与Generalization。原文定义如下 [1]:
Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data. Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past.
模型能够从历史数据中学习到高频共现的特征组合的能力,这是模型的Memorization。而Generalization代表模型能够利用相关性的传递性去探索历史数据中从未出现过的特征组合。
广义线性模型能够很好地解决Memorization的问题,但是在Generalization方面表现不足。基于Embedding的DNN模型在Generalization表现优异,但在数据分布较为长尾的情况下,对于长尾数据的处理能力较弱,容易造成过度泛化。
能否将二者进行结合,取彼之长补己之短?使得模型同时兼顾Memorization与Generalization。为此,作者提出二者兼备的Wide&Deep模型,并在Google Play store的场景中成功落地。
2. 模型结构
模型结构示意图如下:
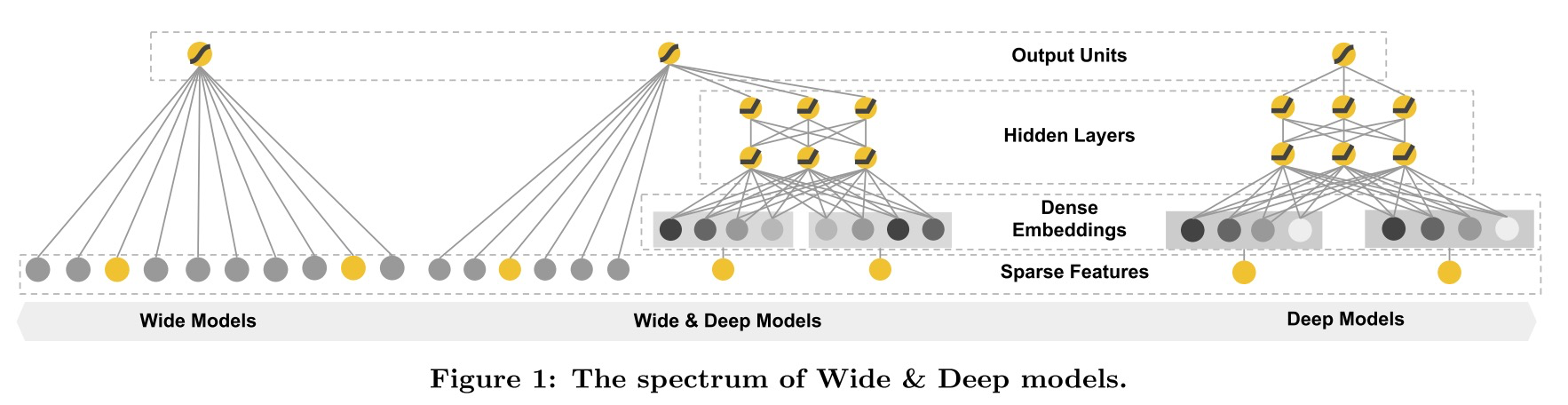
示意图中最左边便是模型的Wide部分,这个部分可以使用广义线性模型来替代,如LR便是最简单的一种。由此可见,Wide&Deep是一类模型的统称,将LR换成FM同样也是一个Wide&Deep模型(与DeepFM的差异见后续博文)。模型的Deep部分是一个简单的基于Embedding的全连接网络,结构与FNN一致 [2]。
2.1 Wide part
这部分是一个广义线性模型,即 \(y=W^T[X, \phi(X)]+b\) 。其中,\(X=[x_1, x_2, \dots,x_d]\) 是 \(d\) 维特征向量。\(\phi(X)=[\phi_1(X),\phi_2(X),\dots,\phi_k(X)]\) 是 \(k\) 维特征转化函数向量。
最常用的特征转换函数便是特征交叉函数,定义为 \(\phi_k(X)=\prod_{i=1}^dx_i^{c_{ki}}, c_{ki} \in \{0,1\}\) ,当且仅当 \(x_i\) 是第 \(k\) 个特征变换的一部分时,\(c_{ki}=1\) 。否则为0。
举例来说,对于二值特征,一个特征交叉函数为 \(And(gender=female,language=en)\) ,这个函数中只涉及到特征 \(female\) 与 \(en\) ,所以其他特征值对应的 \(c_{ki}=0\) ,即可忽略。当样本中 \(female\) 与 \(en\) 同时存在时,该特征交叉函数为1,否则为0。这种特征组合可以为模型引入非线性。
2.2 Deep part
Deep侧是简单的全连接网络:\(a^{(l+1)}=f(W^{(l)}a^{(l)}+b^{(l)})\) ,其中 \(a^{(l)},b^{(l)},W^{(l)},f\) 分别代表第 \(l\) 层的输入、偏置项、参数项与激活函数。
2.3 Output part
Wide与Deep侧都准备完毕之后,对两部分输出进行简单 加权求和 即可作为最终输出。对于简单二分类任务而言可以定义为:
P(Y=1|X)=\sigma(W_{wide}^T[X,\phi(X)]+W_{deep}^Ta^{(l_f)}+b)
\end{aligned}
\]
其中,\(W_{wide}^T[X,\phi(X)]\) 为Wide输出结果,\(W_{deep}\) 为Deep侧作用到最后一层激活函数输出的参数,Deep侧最后一层激活函数输出结果为 \(a^{(l_f)}\) ,\(b\) 为全局偏置项,\(\sigma\) 为 \(sigmoid\) 激活函数 。
将Wide与Deep侧进行联合训练,需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了 \(FTRL\) 算法优化,而Deep侧使用的是 \(AdaGrad\) 。
3. 工程实现
Google使用的pipeline如下,共分为三个部分:Data Generation、Model Training与Model Serving。

3.1 Data Generation
本阶段负责对数据进行预处理,供给到后续模型训练阶段。其中包括用户数据收集、样本构造。对于类别特征,首先过滤掉低频特征,然后构造映射表,将类别字段映射为编号,即token化。对于连续特征可以根据其分布进行离散化,论文中采用的方式为等分位数分桶方式,然后再放缩至[0,1]区间。
3.2 Model Training
针对Google paly场景,作者构造了如下结构的Wide&Deep模型。在Deep侧,连续特征处理完之后直接送入全连接层,对于类别特征首先输入到Embedding层,然后再连接到全连接层,与连续特征向量拼接。在Wide侧,作者仅使用了用户历史安装记录与当前候选app作为输入。
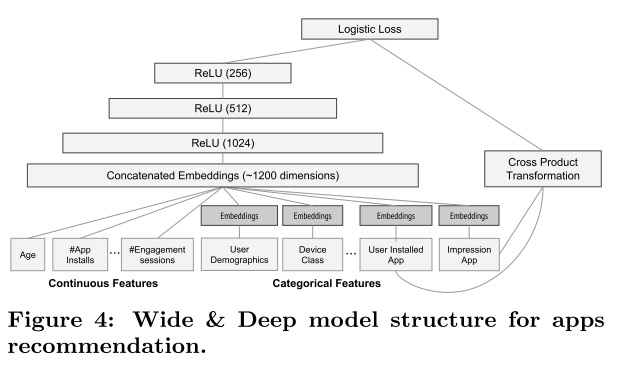
作者采用这种“重Deep,轻Wide”的结构完全是根据应用场景的特点来的。Google play因为数据长尾分布,对于一些小众的app在历史数据中极少出现,其对应的Embedding学习不够充分,需要通过Wide部分Memorization来保证最终预测的精度。
作者在训练该模型时,使用了5000亿条样本(惊呆),这也说明了Wide&Deep并没有那么容易训练。为了避免每次从头开始训练,每次训练都是先load上一次模型的得到的参数,然后再继续训练。有实验说明,类似于FNN使用预训练FM参数进行初始化可以加速Wide&Deep收敛。
3.3 Model Serving
在实际推荐场景,并不会对全量的样本进行预测。而是针对召回阶段返回的一小部分样本进行打分预测,同时还会采用多线程并行预测,严格控制线上服务时延。
4. 实验结果
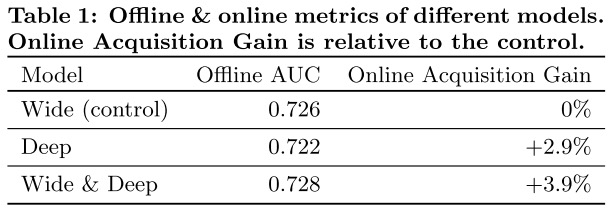
作者在线上线下同时进行实验,线上使用A/B test方式运行3周时间,对比收益结果如下。Wide&Deep线上线下都有提升,且提升效果显著。
5. 优缺点分析
优点:
简单有效。结构简单易于理解,效果优异。目前仍在工业界广泛使用,也证明了该模型的有效性。
结构新颖。使用不同于以往的线性模型与DNN串行连接的方式,而将线性模型与DNN并行连接,同时兼顾模型的Memorization与Generalization。
缺点:
- Wide侧的特征工程仍无法避免。
实践
依旧使用 \(MovieLens100K dataset\) ,核心代码如下。其中需要注意的是,针对Wide部分采用了 \(FTRL\) 优化器,Deep部分使用了 \(Adam\) 优化器。
class WideDeep(object):
def __init__(self, vec_dim=None, field_lens=None, dnn_layers=None, wide_lr=None, l1_reg=None, deep_lr=None):
self.vec_dim = vec_dim
self.field_lens = field_lens
self.field_num = len(field_lens)
self.dnn_layers = dnn_layers
self.wide_lr = wide_lr
self.l1_reg = l1_reg
self.deep_lr = deep_lr
assert isinstance(dnn_layers, list) and dnn_layers[-1] == 1
self._build_graph()
def _build_graph(self):
self.add_input()
self.inference()
def add_input(self):
self.x = [tf.placeholder(tf.float32, name='input_x_%d'%i) for i in range(self.field_num)]
self.y = tf.placeholder(tf.float32, shape=[None], name='input_y')
self.is_train = tf.placeholder(tf.bool)
def inference(self):
with tf.variable_scope('wide_part'):
w0 = tf.get_variable(name='bias', shape=[1], dtype=tf.float32)
linear_w = [tf.get_variable(name='linear_w_%d'%i, shape=[self.field_lens[i]], dtype=tf.float32) for i in range(self.field_num)]
wide_part = w0 + tf.reduce_sum(
tf.concat([tf.reduce_sum(tf.multiply(self.x[i], linear_w[i]), axis=1, keep_dims=True) for i in range(self.field_num)], axis=1),
axis=1, keep_dims=True) # (batch, 1)
with tf.variable_scope('dnn_part'):
emb = [tf.get_variable(name='emb_%d'%i, shape=[self.field_lens[i], self.vec_dim], dtype=tf.float32) for i in range(self.field_num)]
emb_layer = tf.concat([tf.matmul(self.x[i], emb[i]) for i in range(self.field_num)], axis=1) # (batch, F*K)
x = emb_layer
in_node = self.field_num * self.vec_dim
for i in range(len(self.dnn_layers)):
out_node = self.dnn_layers[i]
w = tf.get_variable(name='w_%d' % i, shape=[in_node, out_node], dtype=tf.float32)
b = tf.get_variable(name='b_%d' % i, shape=[out_node], dtype=tf.float32)
in_node = out_node
if out_node != 1:
x = tf.nn.relu(tf.matmul(x, w) + b)
else:
self.y_logits = wide_part + tf.matmul(x, w) + b
self.y_hat = tf.nn.sigmoid(self.y_logits)
self.pred_label = tf.cast(self.y_hat > 0.5, tf.int32)
self.loss = -tf.reduce_mean(self.y*tf.log(self.y_hat+1e-8) + (1-self.y)*tf.log(1-self.y_hat+1e-8))
# set optimizer
self.global_step = tf.train.get_or_create_global_step()
wide_part_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='wide_part')
dnn_part_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='dnn_part')
wide_part_optimizer = tf.train.FtrlOptimizer(learning_rate=self.wide_lr, l1_regularization_strength=self.l1_reg)
wide_part_op = wide_part_optimizer.minimize(loss=self.loss, global_step=self.global_step, var_list=wide_part_vars)
dnn_part_optimizer = tf.train.AdamOptimizer(learning_rate=self.deep_lr)
# set global_step to None so only wide part solver gets passed in the global step;
# otherwise, all the solvers will increase the global step
dnn_part_op = dnn_part_optimizer.minimize(loss=self.loss, global_step=None, var_list=dnn_part_vars)
self.train_op = tf.group(wide_part_op, dnn_part_op)
reference
[1] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. ACM, 2016.
[2] Zhang, Weinan, Tianming Du, and Jun Wang. "Deep learning over multi-field categorical data." European conference on information retrieval. Springer, Cham, 2016.
[3] https://zhuanlan.zhihu.com/p/53361519
知识分享
个人知乎专栏:https://zhuanlan.zhihu.com/c_1164954275573858304
欢迎关注微信公众号:SOTA Lab
专注知识分享,不定期更新计算机、金融类文章

推荐系统系列(六):Wide&Deep理论与实践的更多相关文章
- 巨经典论文!推荐系统经典模型Wide & Deep
今天我们剖析的也是推荐领域的经典论文,叫做Wide & Deep Learning for Recommender Systems.它发表于2016年,作者是Google App Store的 ...
- 计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践
计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践 2018年06月13日 16:38:11 轻春 阅读数 6004更多 分类专栏: 机器学习 机器学习荐货情报局 版 ...
- 推荐系统系列(四):PNN理论与实践
背景 上一篇文章介绍了FNN [2],在FM的基础上引入了DNN对特征进行高阶组合提高模型表现.但FNN并不是完美的,针对FNN的缺点上交与UCL于2016年联合提出一种新的改进模型PNN(Produ ...
- 深度学习在美团点评推荐平台排序中的应用&& wide&&deep推荐系统模型--学习笔记
写在前面:据说下周就要xxxxxxxx, 吓得本宝宝赶紧找些广告的东西看看 gbdt+lr的模型之前是知道怎么搞的,dnn+lr的模型也是知道的,但是都没有试验过 深度学习在美团点评推荐平台排序中的运 ...
- 【RS】Wide & Deep Learning for Recommender Systems - 广泛和深度学习的推荐系统
[论文标题]Wide & Deep Learning for Recommender Systems (DLRS'16) [论文作者] Heng-Tze Cheng, Levent Koc, ...
- 高翔《视觉SLAM十四讲》从理论到实践
目录 第1讲 前言:本书讲什么:如何使用本书: 第2讲 初始SLAM:引子-小萝卜的例子:经典视觉SLAM框架:SLAM问题的数学表述:实践-编程基础: 第3讲 三维空间刚体运动 旋转矩阵:实践-Ei ...
- 深度排序模型概述(一)Wide&Deep/xDeepFM
本文记录几个在广告和推荐里面rank阶段常用的模型.广告领域机器学习问题的输入其实很大程度了影响了模型的选择,因为输入一般维度非常高,稀疏,同时包含连续性特征和离散型特征.模型即使到现在DeepFM类 ...
- ARM NEON指令集优化理论与实践
ARM NEON指令集优化理论与实践 一.简介 NEON就是一种基于SIMD思想的ARM技术,相比于ARMv6或之前的架构,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bi ...
- Java 理论与实践: 流行的原子——新原子类是 java.util.concurrent 的隐藏精华(转载)
简介: 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 java.util.concurrent 中添加原子变量类之后,这种情况发生了变化.请跟随并 ...
随机推荐
- 高性能MySQL3_笔记1_Mysql的架构与历史
第一层:连接处理.授权认证.安全 第二层:mysql的核心功能,包括查询解析.分析.优化.缓存以及所有的内置函数(例如日期.加密.数学函数), 所有跨存储引擎的功能都在这一层实现:存储过程.触发器.视 ...
- APOC官网触发器示例执行后Web页面一直转圈
apoc使用触发器:如apoc官网指导 CREATE (d:Person {name:'Daniel'}) CREATE (l:Person {name:'Mary'}) CREATE (t:Pers ...
- JSON函数表2
[class] Json::Reader [public] [将字符串或者输入流转换为JSON的Value对象] bool parse( const std::string &document ...
- 进阶Java编程(9)反射与类操作
1,反射获取类结构信息 在反射机制的处理过程之中不仅仅只是一个实例化对象的处理操作,更多的情况下还有类的组成结构操作,任何一个类的基本组成结构:父类(父接口).包.属性.方法(构造方法与普通方法). ...
- 【vue】computed 和 watch
计算属性:computed 监听多个变量且变量是在vue实例中(依赖某个变量,变量发生改变就会触发) 侦听器: watch 监听一个变量的变化 使用场景:watch(异步场景) ...
- js 的一些小技巧
来源:https://www.w3cplus.com/javascript/javascript-tips.html 1.确保数组的长度 在处理网格结构时,如果原始数据每行的长度不相等,就需要重新创建 ...
- Databus&canal对比
Databus和canal都能够提供实时从数据库获取变更,并提供给下游的实时消费流的功能. 本文针对两个系统实现和应用上的不同点,做了一个简单的对比: 对比项 Databus canal 结论 支持的 ...
- hourglassnet网络解析
hourglassnet中文名称是沙漏网络,起初用于人体关键点检测,代码,https://github.com/bearpaw/pytorch-pose 后来被广泛的应用到其他领域,我知道的有双目深度 ...
- 【漏洞分析】Discuz! X系列全版本后台SQL注入漏洞
0x01漏洞描述 Discuz!X全版本存在SQL注入漏洞.漏洞产生的原因是source\admincp\admincp_setting.php在处理$settingnew['uc']['appid' ...
- Django框架——forms.ModelForm使用
使用模型创建表单 django提供了这种简便的方式,使用方法如下: 1.在项目的一个app目录中,创建forms.py文件 2.导入模块: from django import forms from ...