pandas模块的基本用法
一、读取文件
import pandas as pd
data = pd.read_csv("F:\\ml\\机器学习\\01\\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件
print(data) #显示data的值
"""name a b c d e
0 hyan 90 69 23.0 35 134
1 ytt 34 45 24.0 35 14
2 hy 34 56 67.0 69 26
3 cz 35 84 94.0 72 61
4 wh 72 15 16.0 61 27
5 hj 62 61 NaN 28 38
"""
print(data.dtypes) #显示data里面参数的类型
"""
name object
a int64
b int64
c float64
d int64
e int64
dtype: object"""
print(type(data)) #显示data的类型------<class 'pandas.core.frame.DataFrame'>
print(help(pd.read_csv)) #寻求帮助
data.columns #显示每类的类名------Index(['name', 'a', 'b', 'c', 'd', 'e'], dtype='object') data.shape #显示维度------(6, 6)
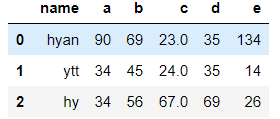
data.head(3) #显示前三行的数据,默认前5行
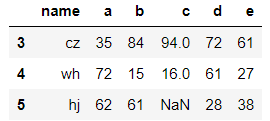
data.tail(3) #显示后3行的数据,默认后5行
二、索引与计算
import pandas as pd
data = pd.read_csv("F:\\ml\\机器学习\\01\\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件
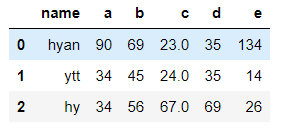
data.loc[0:2] #读取行,通过loc形式读取,比如data.loc[0]读取第0行,也可以通过切片,如这样就可以读取前三行,注意的是包括索引2所在的行
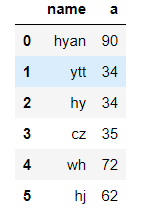
data[["name", "a"]] #读列,默认第一行的为列名,如果单独读取某个列,比如data["name"],如果读取好几个列的话,放进数组的里读取。
#读取列名中的含a的列-----一般寻找的特殊列的过程
col_names = data.columns.tolist() #将所有的列名放进列表中 print(col_names) #------['name', 'a', 'b', 'c', 'd', 'e'] select_col = [] for name in col_names:
if 'a' in name:
select_col.append(name) print(data[select_col])

#新增列,先通过运算得到的列
f = data['d'] + data['e'] print(f)
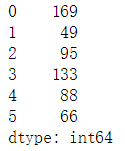
#再将列填进去
data['f'] = f print(data.shape) #------(6, 7) data[['d', 'e', 'f']]
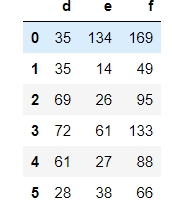
#将f列进行归一化操作
data['f'].min() #取f列的最小值------49 data['f'].max() #取f列的最大值------169 f_normalized = data['f'] / data['f'].max() print(f_normalized)
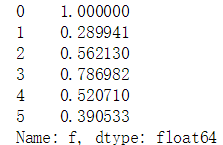
三、数据预处理实例
data.sort_values('f', inplace = True, ascending = True) #排序,inplace=True表示会改变原来的数据,ascending = True表示升序,默认就是升序。NaN表示之前没有数据,用NaN代替
print(data)
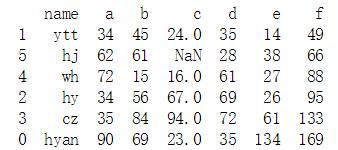
#寻找c列的NaN的个数,也就是缺失值的个数。
c = data['c'] c_is_null = pd.isnull(c) #判断c列的值,NaN为True,否则为False print(c_is_null)

nan = c[c_is_null] #以c_is_null为索引,只返回True的值 print(nan)
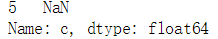
count = len(nan) #显示nan的个数 print(count) #------1
#去掉NaN求均值的两个方法
#方法一
c_isnot_null = data['c'][c_is_null == False] #去掉NaN所得到的列 mean_c = sum(c_isnot_null) / len(c_isnot_null) print(mean_c) #------44.8 #调用自己的函数
mean_c_1 = data['c'].mean() print(mean_c_1) #------44.8
#统计以a为等级的对应e的平均值
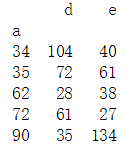
e_mean = data.pivot_table(index = 'a', values = 'e', aggfunc = np.mean) print(e_mean)

#统计以a为等级对应d、e的总和 sum_d_e = data.pivot_table(index = 'a', values = ['d', 'e'], aggfunc = np.sum) #如果不写参数aggfunc,默认为平均值 print(sum_d_e)
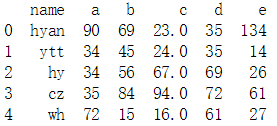
#去掉NaN所在的行或者列
new_data = data.dropna(axis = 1) #去掉含NaN所在的列 print(new_data)

new_data_1 = data.dropna(axis = 0, subset = ['c', 'd']) #去掉NaN所在的行 print(new_data_1)
#确定寻找某个值
b_2 = data.loc[2, 'b'] print(b_2) #------56
import pandas as pd
data = pd.read_csv("F:\\ml\\机器学习\\01\\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件
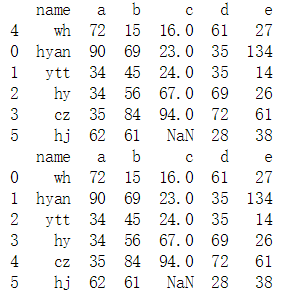
data.sort_values('c', inplace = True, ascending = True)
print(data)
#排序后行号发生的改变,这时候重新从头设定的话
new_data = data.reset_index(drop = True) #drop = True表示原来的索引不要了,重新从头开始设定
print(new_data)
四、自定义函数
import pandas as pd
data = pd.read_csv("F:\\ml\\机器学习\\01\\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件
#自定义函数,取data的DataFrame的第4行数据
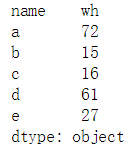
def a_values(data):
return data.loc[4]
a_value = data.apply(a_values) #调用自定义函数
print(a_value)
五、Series结构
import pandas as pd
import numpy as np
from pandas import Series #取出DataFrame中的某一行或者某一列都是Series类型 data = pd.read_csv("F:\\ml\\机器学习\\01\\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件 d_data = data['d'] print(type(d_data)) #------<class 'pandas.core.series.Series'> d = d_data.values #将Series类型转化为ndarry类型 print(d) #------[35 35 69 72 61 28] print(type(d))#------<class 'numpy.ndarray'> #对于两个ndarray类型,只要维度一样,就可以将其中的一个ndarray作为索引形成Series类型。
num = np.array([1, 2, 3, 4, 5, 6]) name = np.array(['a', 'b', 'c', 'd', 'e', 'f']) name_num = Series(num, index = name) print(name_num)
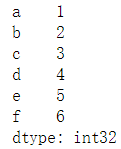
#也可以直接创建
Series([1, 2, 3, 4])
0 1
1 2
2 3
3 4
dtype: int64
Series({'a':1, 'b':2, 'c':3})
a 1
b 2
c 3
dtype: int64
Series([1, 2, 3, 4, 5], index = ['a', 'b', 'c', 'd', 'e'])
a 1
b 2
c 3
d 4
e 5
dtype: int64
v = Series([1, 2, 3, 4, 5], index = ['a', 'b', 'c', 'd', 'e']) print(v.cumsum()) #cumsum()是累计求和
a 1
b 3
c 6
d 10
e 15
dtype: int64
pandas模块的基本用法的更多相关文章
- Pandas模块
前言: 最近公司有数据分析的任务,如果使用Python做数据分析,那么对Pandas模块的学习是必不可少的: 本篇文章基于Pandas 0.20.0版本 话不多说社会你根哥!开干! pip insta ...
- 模块讲解---numpymo模块,matplotlib模块,pandas模块
目录 numpy模块 matplotlib模块 pandas模块 numpy模块 numpy模块:用来做数据分析,对numpy数组(既有行又有列)--矩阵进行科学运算 在使用的时候,使用方法与其他的模 ...
- python之pandas模块
一.pandas模块是基于Numpy模块的,pandas的主要数据结构是Series和DadaFrame,下面引入这样的约定: from pandas import Series,DataFrame ...
- Python 数据处理扩展包: numpy 和 pandas 模块介绍
一.numpy模块 NumPy(Numeric Python)模块是Python的一种开源的数值计算扩展.这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list str ...
- python中os模块和sys模块的常见用法
OS模块的常见用法 os.remove() 删除文件 os.rename() 重命名文件 os.walk() 生成目录树下的所有文件名 os.chdir() 改变目录 os.mkd ...
- 爬虫 requests模块的其他用法 抽屉网线程池回调爬取+保存实例,gihub登陆实例
requests模块的其他用法 #通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下 Host Referer #大型网站通常都会根据该参数判断请求的来源 ...
- 关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题 ...
- pandas模块实现小爬虫功能-转载
pandas模块实现小爬虫功能 安装 pip3 install pandas 爬虫代码 import pandas as pd df = pd.read_html("http://www.a ...
- Pandas模块:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
随机推荐
- 修复ubuntu 安装mysql后必须使用sudo问题
修改root用户 查看用户的权限,是否是mysql_native_password,如果不是,则将auth_sock改为mysql_native_password update user set pl ...
- 漏洞复现之Redis-rce
通过主从复制 GetShell Redis主从复制 Redis是一个使用ANSI C编写的开源.支持网络.基于内存.可选持久性的键值对存储数据库.但如果当把数据存储在单个Redis的实例中,当读写体量 ...
- LeetCode 199. 二叉树的右视图(Binary Tree Right Side View)
199. 二叉树的右视图 199. Binary Tree Right Side View 题目描述 给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值. Giv ...
- 关于Python编码这一篇文章就够了
概述 在使用Python或者其他的编程语言,都会多多少少遇到编码错误,处理起来非常痛苦.在Stack Overflow和其他的编程问答网站上,UnicodeDecodeError和UnicodeEnc ...
- C++ 根据两点式方法求直线并求两条直线的交点
Line.h #pragma once //Microsoft Visual Studio 2015 Enterprise //根据两点式方法求直线,并求两条直线的交点 #include"B ...
- C之指针加减运算
法则:1.指针减指针,语法正确,结果得一个整型值,表示两数值之间的对象类型的空间距离,而不是对象之间的字节数差值 2.指针加指针,语法错误, 3.指针加整形值,语法正确,表示后移N个空间单位 ...
- jquery中filter()和find()函数区别
通常把这两个函数,filter()函数和find()函数称为筛选器. 下面的例子分别使用filter函数和find函数对一组列表进行筛选操作. 一组列表: <li>1</li> ...
- 修改织梦DedeCMS投票漏洞
织梦/dedecms系统我们都知道是有很多漏洞的,我在调试投票功能的时候正好要用到投票功能,这不就出现了漏洞,下面我就给大家展示如何修复这个织梦投票漏洞 首先我们打开//dedevote.class. ...
- 十八、Nand Flash驱动和Nor Flash驱动
在读者学习本章之前,最好了解Nand Flash读写过程和操作,可以参考:Nand Flash裸机操作. 一开始想在本章写eMMC框架和设备驱动,但是没有找到关于eMMC设备驱动具体写法,所以本章仍继 ...
- 多线程面试题之【三线程按顺序交替打印ABC的方法】
建立三个线程,线程名字分别为:A.B.C,要求三个线程分别打印自己的线程名字,但是要求三个线程同时运行,并且实现交替打印,即按照ABCABCABC的顺序打印.打印10轮,打印完毕控制台输出字符串:&q ...