Attention is all you need 详细解读
自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型。传统的基于RNN的Seq2Seq模型难以处理长序列的句子,无法实现并行,并且面临对齐的问题。
所以之后这类模型的发展大多数从三个方面入手:
· input的方向性:单向 -> 双向
· 深度:单层 -> 多层
· 类型:RNN -> LSTM GRU
但是依旧收到一些潜在问题的制约,神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量。这可能使得神经网络难以应付长时间的句子,特别是那些比训练语料库中的句子更长的句子;每个时间步的输出需要依赖于前面时间步的输出,这使得模型没有办法并行,效率低;仍然面临对齐问题。
再然后CNN由计算机视觉也被引入到deep NLP中,CNN不能直接用于处理变长的序列样本但可以实现并行计算。完全基于CNN的Seq2Seq模型虽然可以并行实现,但非常占内存,很多的trick,大数据量上参数调整并不容易。
本篇文章创新点在于抛弃了之前传统的encoder-decoder模型必须结合cnn或者rnn的固有模式,只用Attention。文章的主要目的在于减少计算量和提高并行效率的同时不损害最终的实验结果。
- 1.整体框架
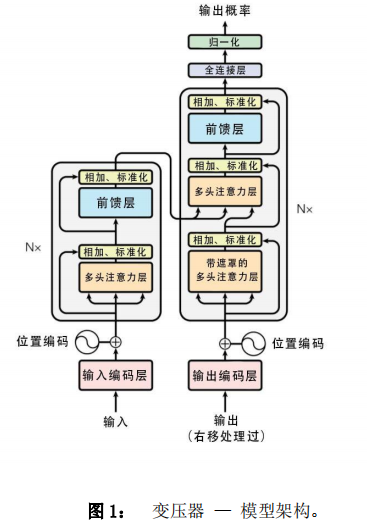
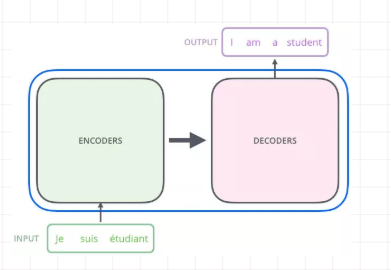
整体框架很容易理解,但是上图又很复杂,可以简化如下:

其实这就是一个Seq2Seq模型 左边一个encoder把输入读进去,右边一个decoder的单输出
第一眼看到论文中的框图,随之产生问题就是左边encoder的输出是怎么和右边decoder结合的。因为decoder里面是有N层的。再画张图直观的看就是这样:
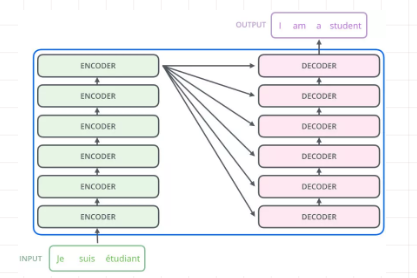
也就是说,Encoder的输出,回合每一层的Decoder进行结合。我们取其中一层进行详细的展示:
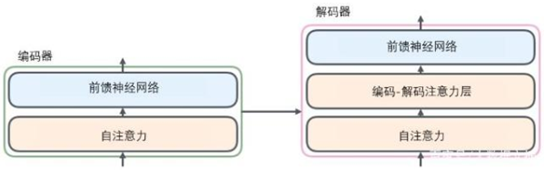
· 2 Attention Mechanism
o 2.1 Attention定义
Attention用于计算"相关程度",例如在翻译过程中,不同的英文对中文的依赖程度不同,Attention通常可以进行如下描述,表示为将query(Q)和key-value pairs映射到输出上,其中query、每个key、每个value都是向量,输出是V中所有values的加权,其中权重是由Query和每个key计算出来的,计算方法分为三步:
· 第一步:计算比较Q和K的相似度,用f来表示:
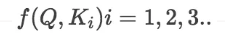
· 第二步:将得到的相似度进行Softmax操作,进行归一化:
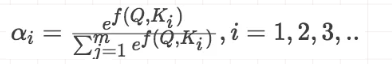
· 第三步:针对计算出来的权重,对V中所有的values进行加权求和计算,得到Attention向量:
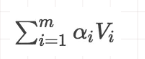
o 第一步中计算方法包括以下四种
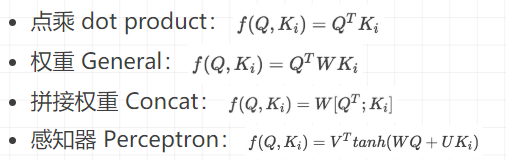
o 从微观视角看自注意力机制
首先我们了解一下如何使用向量来计算自注意力,然后来看它实怎样用矩阵来实现。
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
可以发现这些新向量在维度上比词嵌入向量更低。他们的维度是64,而词嵌入和编码器的输入/输出向量的维度是512. 但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multiheaded attention)的大部分计算保持不变。
X1与WQ权重矩阵相乘得到q1, 就是与这个单词相关的查询向量。最终使得输入序列的每个单词的创建一个查询向量、一个键向量和一个值向量。
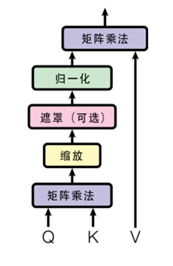
· 2.2 Scaled Dot-Product Attention
他的结构图如下:
像大部分NLP应用一样,我们首先将每个输入单词通过词嵌入算法转换为词向量。每个单词都被嵌入为512维的向量,我们用一些简单的方框来表示这些向量。
词嵌入过程只发生在最底层的编码器中。所有的编码器都有一个相同的特点,即它们接收一个向量列表,列表中的每个向量大小为512维。在底层(最开始)编码器中它就是词向量,
但是在其他编码器中,它就是下一层编码器的输出(也是一个向量列表)。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
将输入序列进行词嵌入之后,每个单词都会流经编码器中的两个子层。
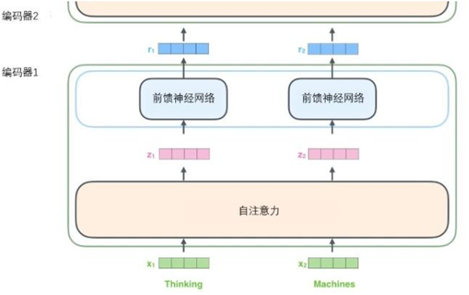
接下来我们看看Transformer的一个核心特性,在这里输入序列中每个位置的单词都有自己独 特的路径流入编码器。在自注意力层中,这些路径之间存在依赖关系。
而前馈(feed-forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
o first step
首先从输入开始理解,Scaled Dot-Product Attention里的Q, K, V从哪里来:按照我的理解就是给我一个输入X, 通过3个线性转换把X转换为Q,K,V。
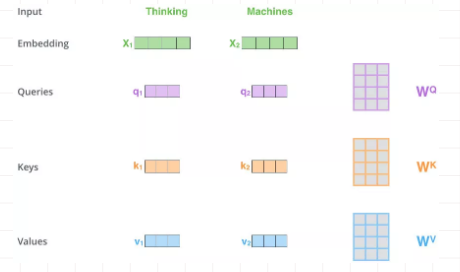
两个单词,Thinking, Machines. 通过嵌入变换会X1,X2两个向量[1 x 4]。分别与Wq,Wk,Wv三个矩阵[4x3]想做点乘得到,{q1,q2},{k1,k2},{v1,v2} 6个向量[1x3]。
o second step
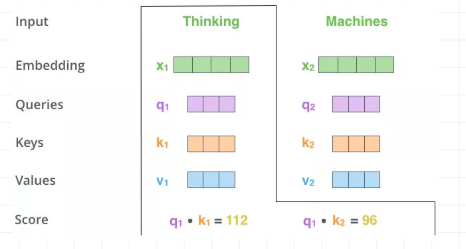
向量{q1,k1}做点乘得到得分(Score) 112, {q1,k2}做点乘得到得分96。
o third and forth steps
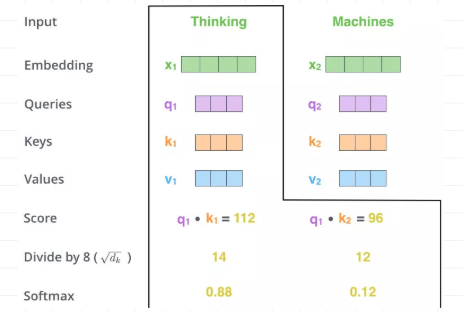
对该得分进行规范,除以8。这个在论文中的解释是为了使得梯度更稳定。之后对得分[14,12]做softmax得到比例 [0.88,0.12]。
o fifth step
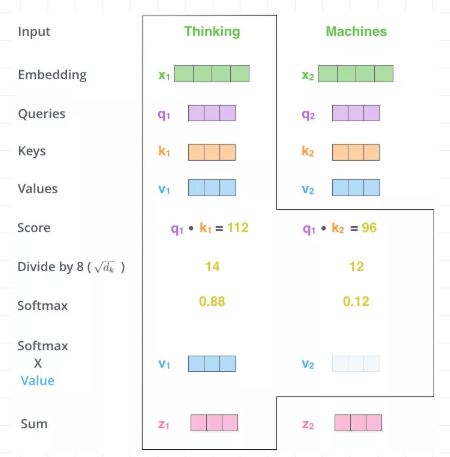
用得分比例[0.88,0.12] 乘以[v1,v2]值(Values)得到一个加权后的值。将这些值加起来得到z1。这就是这一层的输出。仔细感受一下,
用Q,K去计算一个thinking对与thinking, machine的权重,用权重乘以thinking,machine的V得到加权后的thinking,machine的V,最后求和得到针对各单词的输出Z
(译注:自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(值向量)进行加权求和,而权重是通过该词的表示(键向量)
与被编码词表示(查询向量)的点积并通过softmax得到。),然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)。
· 矩阵表示
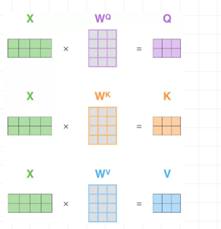
之前的例子是单个向量的运算例子。这张图展示的是矩阵运算的例子。输入是一个[2x4]的矩阵(单词嵌入),每个运算是[4x3]的矩阵,求得Q,K,V。
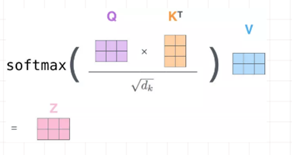
Q对K转制做点乘,除以dk的平方根。做一个softmax得到合为1的比例,对V做点乘得到输出Z。那么这个Z就是一个考虑过thinking周围单词(machine)的输出
注意看这个公式,QKT其实就会组成一个word2word的attention map!(加了softmax之后就是一个合为1的权重了)。
比如说你的输入是一句话 "i have a dream" 总共4个单词,这里就会形成一张4x4的注意力机制的图:

这样一来,每一个单词就对应每一个单词有一个权重
主要Encoder里面叫做self-attention decoder里面叫做masked self-attention
在这里的masked就是要在做language modelling(或者翻译)的时候,不给模型看到未来的信
息。

masked就是不给模型看到未来的信息,mask就是沿对角线把灰色的区域用0覆盖掉
详细的来说,i作为第一个单词,只能有和i自己的attention。have作为第二个单词,有和i, have 两个attention。
a 作为第三个单词,有和i,have,a 前面三个单词的attention。到了最后一个单词dream的时候,才有对整个句子4个单词的attention。

做完softmax后就像这样,横轴和为1
· 2.3 Multi-Head Attention
Multi-Head Attention就是把Scaled Dot-Product Attention的过程做H次,然后把输出Z合起来。论文中,它的结构图如下:
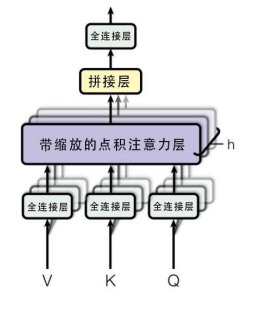
我们还是以上面的形式来解释:

论文中还增加一种称为 multi-headed 注意力机制,可以提升注意力层的性能
它使得模型可以关注不同位置
虽然在上面的例子中,z1 包含了一点其他位置的编码,但当前位置的单词还是占主要作用, 当我们想知道“The animal didn’t cross the street because it was too tired” 中 it 的含义时,这时就需要关注到其他位置
这个机制为注意层提供了多个“表示子空间”(representation subspaces)。下面我们将具体介绍,
o 经过 multi-headed , 我们会得到和 heads 数目一样多的 Query / Key / Value 权重矩阵组
论文中用了8个,那么每个encoder/decoder我们都会得到 8 个集合。
这些集合都是随机初始化的,经过训练之后,每个集合会将input embeddings (或者来自较低编码器/解码器的向量)投影到不同的表示子空间中
o 我们重读记性八次相似的操作,得到八个Zi矩阵
简单来说,就是定义8组权重矩阵,每个单词会做8次上面的self-attention的计算
这样每个单词就会得到8个不同的加权求和Z

o feed-forward处只能接受一个矩阵,所以需要将这八个矩阵压缩成一个矩阵
方法就是先将八个矩阵连接起来,然后乘以一个额外的权重矩阵W0
为了使得输出与输入结构对标 乘以一个线性W0 得到最终的Z
· 3 Transformer Architecture
绝大部分的序列处理模型都采用encoder-decoder结构,其中encoder将输入序列
(x1,x2,…,xn),然后decoder生成一个输出序列(y1,y2,…,yn),每个时刻输出一个结果。从框架中我们可以知道transformer模型延续了这个模型。
o 3.1 position embedding
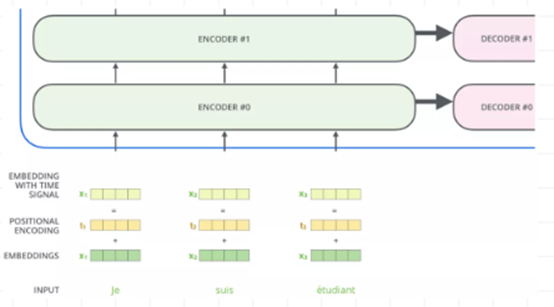
因为模型不包括Recurrence/Convolution,因此是无法捕捉到序列顺序信息的,例如将K、V按行进行打乱,那么Attention之后的结果是一样的。
但是序列信息非常重要,代表着全局的结构,因此必须将序列的分词相对或者绝对position信息利用起来。
这里每个分词的position embedding向量维度也是dmodel, 然后将原本的input embedding和position embedding加起来
组成最终的embedding作为encoder/decoder的输入。其中position embedding计算公式如下:
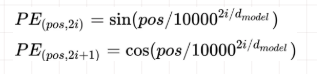
其中 pos 表示位置index, i 表示dimension index。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是,由于我们有:
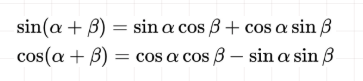
这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
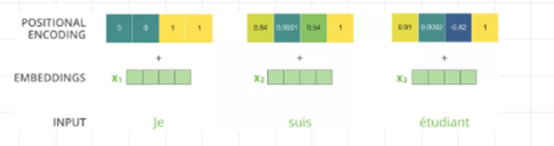
在其他NLP论文中,大家也都看过position embedding,通常是一个训练的向量,但是position embedding只是extra features,有该信息会更好,但是没有性能也不会产生极大下降,因为RNN、CNN本身就能够捕捉到位置信息,但是在Transformer模型中,Position Embedding是位置信息的唯一来源,因此是该模型的核心成分,并非是辅助性质的特征。
· 3.2 position-wise feed-forward networks
在进行了Attention操作之后,encoder和decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出:
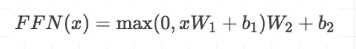
其中每一层的参数都不同。
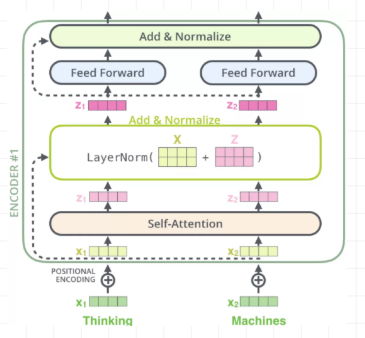
· 3.3 Encoder
Encoder有N=6层,每层包括两个sub-layers:
- 第一个sub-layer是multi-head self-attention mechanism,用来计算输入的self-attention
- 第二个sub-layer是简单的全连接网络。
在每个sub-layer我们都模拟了残差网络,每个sub-layer的输出都是:

其中Sublayer(x) 表示Sub-layer对输入 x 做的映射,为了确保连接,所有的sub-layers和embedding layer输出的维数都相同dmodel
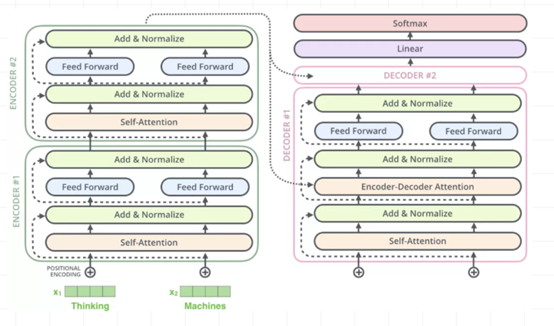
· 3.4 Decoder
Decoder也是N=6层,每层包括3个sub-layers:
o 第一个是Masked multi-head self-attention,也是计算输入的self-attention,但是因为是生成过程,因此在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask
o 第二个sub-layer是全连接网络,与Encoder相同
o 第三个sub-layer是对encoder的输入进行attention计算。
同时Decoder中的self-attention层需要进行修改,因为只能获取到当前时刻之前的输入,因此只对时刻 t 之前的时刻输入进行attention计算,这也称为Mask操作。
·
3.5 the final linear and softmax
layer
解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
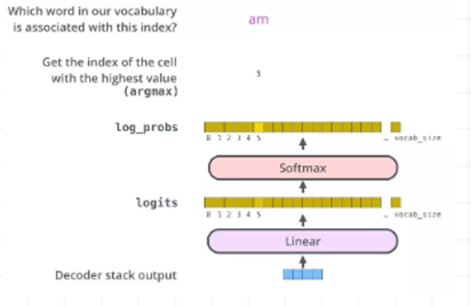
将Decoder的堆栈输出作为输入,从底部开始,最终进行word预测。
·
3.6 the decoder side
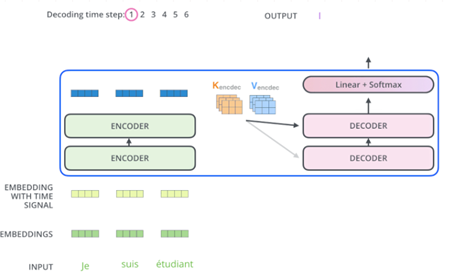
继续进行:
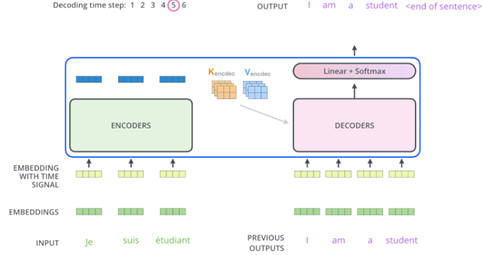
·
4.Experiment
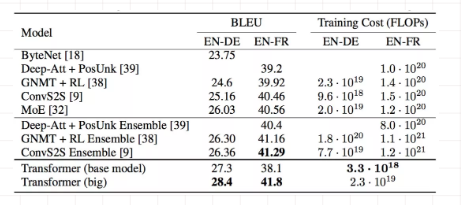
可以看出,transformer 用了最少的资源得到了state-of-art的输出回报。
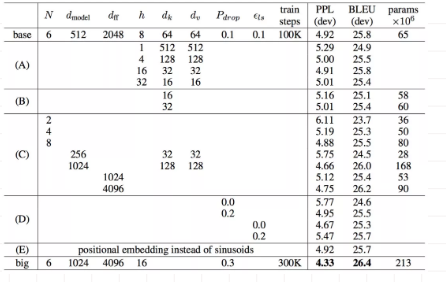
对模型自身的一些参数做了改变自变量的测试,看一下哪些参数对模型的影响比较大。
参考:https://mp.weixin.qq.com/s/RLxWevVWHXgX-UcoxDS70w
https://github.com/tensorflow/tensor2tensor
https://baijiahao.baidu.com/s?id=1622064575970777188&wfr=spider&for=pc
https://www.jianshu.com/p/e7d8caa13b21
https://www.jianshu.com/p/6b2e586f9256
对你有帮助就支付宝请我喝可乐叭~~~

Attention is all you need 详细解读的更多相关文章
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- MemCache超详细解读
MemCache是什么 MemCache是一个自由.源码开放.高性能.分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高 ...
- MemCache超详细解读 图
http://www.cnblogs.com/xrq730/p/4948707.html MemCache是什么 MemCache是一个自由.源码开放.高性能.分布式的分布式内存对象缓存系统,用于 ...
- rpm软件包管理的详细解读
CentOS系统上使用rpm命令管理程序包:安装.卸载.升级.查询.校验.数据库维护 1.基本安装 rpm -ivh PackageFile 2.rpm选项 rpm -ivh --test Packa ...
- MemCache详细解读
MemCache是什么 MemCache是一个自由.源码开放.高性能.分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高 ...
- Android BLE蓝牙详细解读
代码地址如下:http://www.demodashi.com/demo/15062.html 随着物联网时代的到来,越来越多的智能硬件设备开始流行起来,比如智能手环.心率检测仪.以及各式各样的智能家 ...
- 为你详细解读HTTP请求头的具体含意
当我们打开一个网页时,浏览器要向网站服务器发送一个HTTP请求头,然后网站服务器根据HTTP请求头的内容生成当次请求的内容发送给浏览器.你明白HTTP请求头的具体含意吗?下面一条条的为你详细解读,先看 ...
- 详细解读Volley(三)—— ImageLoader & NetworkImageView
ImageLoader是一个加载网络图片的封装类,其内部还是由ImageRequest来实现的.但因为源码中没有提供磁盘缓存的设置,所以咱们还需要去源码中进行修改,让我们可以更加自如的设定是否进行磁盘 ...
- 【Python】【Web.py】详细解读Python的web.py框架下的application.py模块
详细解读Python的web.py框架下的application.py模块 这篇文章主要介绍了Python的web.py框架下的application.py模块,作者深入分析了web.py的源码, ...
随机推荐
- TC做题笔记
SRM593 Div1Medium--May The Best Pet Win(bitset优化) Description 给出n个元素取值的max.min,把这n个元素分割成两个集合,求如何分割使两 ...
- HDU5514——容斥原理&&gcd
题目 链接 有n只青蛙,有m块石头,编号为0-m-1,第i只青蛙每次可以跳$a_i$, 刚开始都在0,问,青蛙总共可以跳到的石头之和为多少.其中$t≤20$,$1≤n≤10^4$,$1≤m≤10^9$ ...
- 05 django组件:contenttype
1.django组件:contenttype 组件的作用:可以通过两个字段让表和N张表创建FK关系 1.专题课,学位课 如何关联 过期时间?? 方法1:分别创建 专题课--过期时间表 .学位课--过期 ...
- P5057 [CQOI2006]简单题 前缀异或差分/树状数组
好思路,好思路... 思路:前缀异或差分 提交:1次 题解:区间修改,单点查询,树状数组,如思路$qwq$ #include<cstdio> #include<iostream> ...
- codeforces700B
CF700B Connecting Universities 题意翻译 树之王国是一个由n-1条双向路连接着n个城镇的国家,任意两个城镇间都是联通的. 在树之王国共有2k所大学坐落于不同的城镇之中. ...
- Python实用黑科技——解包元素(2)
需求: 前面的文章讲的是使用变量的个数需要和迭代器数据变量的元素个数相同的方法,但更多的时候确实不想根据元素个数n来定义相应多的变量,而是希望用较少的变量( def drop_first_last(g ...
- CF892D—Gluttony(思维,好题)
http://codeforces.com/contest/892/problem/D D. Gluttony You are given an array a with n distinct int ...
- HDU 2176 取(m堆)石子游戏 —— (Nim博弈)
如果yes的话要输出所有情况,一开始觉得挺难,想了一下也没什么. 每堆的个数^一下,答案不是0就是先取者必胜,那么对必胜态显然至少存在一种可能性使得当前局势变成必败的.只要任意选取一堆,把这堆的数目变 ...
- selenium知识点
1. 导包 from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from se ...
- Mac 下python3 [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed 解决方法
原文:http://blog.yuccn.net/archives/625.html python3.6下使用urllib 的request进行url 请求时候,如果请求的是https,请求可以会出现 ...