tensorflow卷积神经网络与手写字识别
1、知识点
"""
基础知识:
1、神经网络(neural networks)的基本组成包括输入层、隐藏层、输出层。而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)
2、卷积层:通过在原始图像上平移来提取特征,每一个特征就是一个特征映射
a)提取特征:定义一个过滤器(也称观察窗口,奇数大小,值为权重)大小,步长
b)移动越过图片:
1、VALID:不越过,直接停止观察(一般不用)
2、SAME:直接越过,则对图像零填充(padding过程)
影响因素:窗口大小,步长,零填充,窗口数目 矩阵大小公式计算:
输入体积大小:H1*W1*D1
四个超参数:Filter数量K、Filter大小F、步长S、零填充大小P
输出体积大小 H2*W2*D2
H2=(H1-F+2P)/S+1 #如果有小数,要注意
W2=(W1-F+2P)/S+1
D2=K 卷积API:tf.nn.conv2d(input, filter, strides=, padding=, name=None)计算给定4-D input和filter张量的2维卷积
input:给定的输入张量,具有[batch,heigth,width,channel],类型为float32,64 ,channel为图片的通道数,batch为图片的数量
filter:指定过滤器的大小,[filter_height, filter_width, in_channels, out_channels] ,其中,in_channels=channel ,out_channels为过滤器的数量
strides:strides = [1, stride, stride, 1],步长
padding:“SAME”, “VALID”,使用的填充算法的类型,使用“SAME”。其中”VALID”表示滑动超出部分舍弃,“SAME”表示填充,使得变化后height,width一样大 3、激活函数(Relu),增加激活函数相当于增加了网络的非线性分割能力
1、机器学习使用:sigmoid ,公式:f(x) = 1/1+e^(-x)
2、深度学习使用:Relu ,公式为:f(x) = max(0,x)
3、API:tf.nn.relu(features, name=None)
features:卷积后加上偏置的结果
return:结果 4、池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂度,(最大池化和平均池化)
1、池化计算矩阵大小公式和卷积一样
2、API:tf.nn.max_pool(value, ksize=, strides=, padding=,name=None)输入上执行最大池数
value:4-D Tensor形状[batch, height, width, channels]
ksize:池化窗口大小,[1, ksize, ksize, 1]
strides:步长大小,[1,strides,strides,1]
padding:“SAME”, “VALID”,使用的填充算法的类型,使用“SAME” 5、dropout:防止过拟合,直接使一些数据失效,小型网络用不到 6、不采用sigmoid函数作为激活函数的原因?
第一、采用sigmoid等函数,反向传播求取误差梯度时,计算量相对大,而采用Relu激活函数,震哥哥过程的计算节省很多
第二、对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失等情况
7、tf.one_hot(indices,depth)
indices:数据集标签
depth:类别数 卷积神经网络实现流程:
1、准备数据
2、建立模型
a)准备数据占位符
b)卷积、激活、池化操作
c)全连接层,建立矩阵表达式
3、计算交叉熵损失
4、梯度下降求出损失
5、计算准确率
6、初始化变量
7、开始训练 手写字网络结构设计:
输入数据:[None,784] [None.10]
一卷积层:
卷积:32个filer,5*5 ,strides=1,padding="SAME" ,输入:[None,28,28,1] 输出:[None,28,28,32]
激活:输出 [None,28,28,32]
池化:2*2,strides=2,padding="SAME" 输出 [None,14,14,32]
二卷积层:
卷积:64个filer,5*5 ,strides=1,padding="SAME" ,输入:[None,14,14,32] 输出:[None,14,14,64]
激活:输出 [None,14,14,64]
池化: 2*2,strides=2 ,输出:[None,7,7,64]
全连接层:
形状改变:[None,7,7,64] -->[None,7*7*64]
权重:[7*7*10]
偏置:[10]
输出:[None,10]
输出:[3,5,7] -->softmax转为概率[0.04,0.16,0.8] ---> 交叉熵计算损失值 (目标值和预测值的对数)
"""
2、代码
# coding = utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #定义一个初始化权重的函数
def weight_variables(shape):
w = tf.Variable(tf.random_normal(shape=shape,mean=0.0,stddev=1.0))
return w #定义一个初始化偏置的函数
def bais_variables(shape):
b = tf.Variable(tf.constant(0.0,shape=shape))
return b def model():
"""
自定义卷积模型
:return:
"""
#1、准备数据的占位符 x[None,784] y_true[None,10]
with tf.variable_scope("data"):
x = tf.placeholder(tf.float32,[None,784])
y_true = tf.placeholder(tf.int32,[None,10]) #2、一卷积层 卷积: 5*5*1,32个,strides=1 激活: tf.nn.relu 池化
with tf.variable_scope("conv1"):
#随机初始化权重,[5,5,1,32]--->5,5为过滤器大小,1为输入的图像通道数,32为过滤器的数量
w_conv1 = weight_variables([5,5,1,32])
b_conv1 =bais_variables([32])
#对x进行形状的改变[None,784] --->[None,28,28,1]
# 改变形状,不知道的参数填写-1
x_reshape= tf.reshape(x,[-1,28,28,1]) #strides=[1,1,1,1],表示上下左右移动步长都为1 [None, 28, 28, 1]-----> [None, 28, 28, 32]
x_relu1 = tf.nn.relu(tf.nn.conv2d(x_reshape,w_conv1,strides=[1,1,1,1],padding="SAME")+b_conv1) #池化 2*2 ,strides2 [None, 28, 28, 32]---->[None, 14, 14, 32]
x_pool1 = tf.nn.max_pool(x_relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME") #3、二卷积层
with tf.variable_scope("conv2"):
# 随机初始化权重, 权重:[5, 5, 32, 64] 偏置[64]
w_conv2 = weight_variables([5, 5, 32, 64])
b_conv2 = bais_variables([64]) # 卷积,激活,池化计算
# [None, 14, 14, 32]-----> [None, 14, 14, 64]
x_relu2 = tf.nn.relu(tf.nn.conv2d(x_pool1,w_conv2,strides=[1,1,1,1],padding="SAME")+b_conv2) # 池化 2*2, strides 2, [None, 14, 14, 64]---->[None, 7, 7, 64]
x_pool2 =tf.nn.max_pool(x_relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME") #4、全连接层 [None, 7, 7, 64]--->[None, 7*7*64]*[7*7*64, 10]+ [10] =[None, 10]
with tf.variable_scope("conv2"):
# 随机初始化权重,
w_fc = weight_variables([7*7*64, 10])
b_fc = bais_variables([10]) #修改形状[None, 7, 7, 64] --->None, 7*7*64]
x_fc_reshape = tf.reshape(x_pool2,[-1,7*7*64])
#进行矩阵运算,得出每个样本的10个结果
y_predict = tf.matmul(x_fc_reshape,w_fc)+b_fc ######收集和合并变量####
tf.summary.histogram("w1",w_conv1)
tf.summary.histogram("b1",b_conv1)
tf.summary.histogram("w2",w_conv2)
tf.summary.histogram("b2",b_conv2)
tf.summary.histogram("wfc",w_conv1)
tf.summary.histogram("bfc",b_conv1) merged =tf.summary.merge_all() return x,y_true,y_predict,merged def conv_fc():
# 获取数据
minist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True)
x,y_true,y_predict,merged = model() # 3、计算交叉熵损失
with tf.variable_scope("cross_entropy"):
# 求取平均交叉熵损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict)) # 4、梯度下降求出损失
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(0.0001).minimize(loss) # 5、计算准确率
with tf.variable_scope("accuracy"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
# equal_list None个样本 [1,0,1,1,0,0,0......]
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 7、初始化变量
init_op = tf.global_variables_initializer() ##########收集变量#############
tf.summary.scalar("losses",loss)
tf.summary.scalar("accuracy",accuracy)
merged1 = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(init_op)
fileWriter = tf.summary.FileWriter("./event/",graph=sess.graph)
for i in range(1000):
# 取出数据的特征自和目标值
mnist_x, mnist_y = minist.train.next_batch(50)
# 训练
sess.run(train_op, feed_dict={x: mnist_x, y_true: mnist_y}) summary = sess.run(merged,feed_dict={x: mnist_x, y_true:mnist_y})
summary1 = sess.run(merged1, feed_dict={x: mnist_x, y_true: mnist_y})
fileWriter.add_summary(summary,i)
fileWriter.add_summary(summary1, i) print("训练第%d步,准确率为:%f" % (i, sess.run(accuracy, feed_dict={x: mnist_x, y_true: mnist_y}))) return None if __name__ == "__main__":
conv_fc()
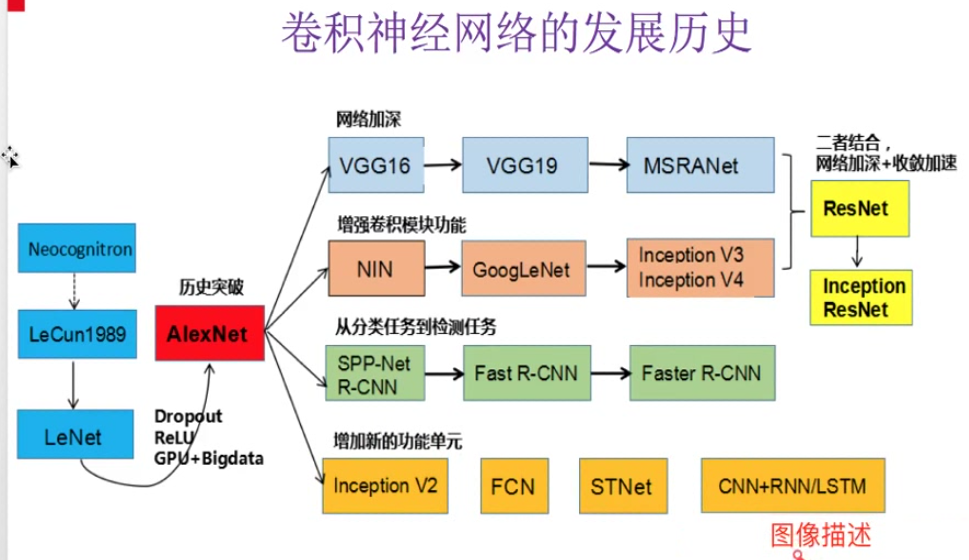
3、发展历程
4、卷积与池化输出矩阵维度计算公式

5、损失计算-交叉熵损失公式
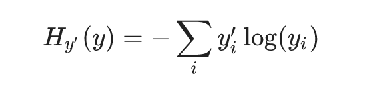

6、SoftMax回归计算公式
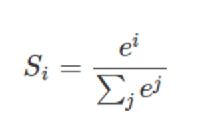
7、激活函数-Relu

tensorflow卷积神经网络与手写字识别的更多相关文章
- TensorFlow卷积神经网络实现手写数字识别以及可视化
边学习边笔记 https://www.cnblogs.com/felixwang2/p/9190602.html # https://www.cnblogs.com/felixwang2/p/9190 ...
- 吴裕雄--天生自然 Tensorflow卷积神经网络:花朵图片识别
import os import numpy as np import matplotlib.pyplot as plt from PIL import Image, ImageChops from ...
- 用TensorFlow教你手写字识别
博主原文链接:用TensorFlow教你做手写字识别(准确率94.09%) 如需转载,请备注出处及链接,谢谢. 2012 年,Alex Krizhevsky, Geoff Hinton, and Il ...
- Tensorflow卷积神经网络[转]
Tensorflow卷积神经网络 卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络, 在计算机视觉等领域被广泛应用. 本文将简单介绍其原理并分析Te ...
- 10分钟搞懂Tensorflow 逻辑回归实现手写识别
1. Tensorflow 逻辑回归实现手写识别 1.1. 逻辑回归原理 1.1.1. 逻辑回归 1.1.2. 损失函数 1.2. 实例:手写识别系统 1.1. 逻辑回归原理 1.1.1. 逻辑回归 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-cifar10图片分类(代码) 1.tf.nn.lrn(局部响应归一化操作) 2.random.sample(在列表中随机选值) 3.tf.one_hot(对标签进行one_hot编码)
1.tf.nn.lrn(pool_h1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75) # 局部响应归一化,使用相同位置的前后的filter进行响应归一化操作 参数 ...
- 基于MTCNN多任务级联卷积神经网络进行的人脸识别 世纪晟人脸检测
神经网络和深度学习目前为处理图像识别的许多问题提供了最佳解决方案,而基于MTCNN(多任务级联卷积神经网络)的人脸检测算法也解决了传统算法对环境要求高.人脸要求高.检测耗时高的弊端. 基于MTCNN多 ...
- knn算法手写字识别案例
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os from sklearn.neighb ...
- TensorFlow 卷积神经网络实用指南 | iBooker·ApacheCN
原文:Hands-On Convolutional Neural Networks with TensorFlow 协议:CC BY-NC-SA 4.0 自豪地采用谷歌翻译 不要担心自己的形象,只关心 ...
随机推荐
- 目标检测之车辆行人(darknet版yolov3)
序言 自动驾驶是目前非常有前景的行业,而视觉感知作为自动驾驶中的“眼睛”,有着非常重要的地位和作用.为了能有效地识别到行驶在路上的动态目标,如汽车.行人等,我们需要提前对这些目标的进行训练, ...
- cpp编码规范要求
1.所有头文件使用#ifndef #define #endif来防止文件被多重包含,命名格式当是: <PROJECT>_<PATH>_<FILE>_H_ 2.只有当 ...
- 2019-2020-1 20199319《Linux内核原理与分析》第一周作业
一.Linux系统简介 通过实验一了解了Linux 的历史,Linux与windows之间的区别以及学习Linux的方法.因为一直用的都是windows系统,习惯了图形界面,而Linux是通过输入命令 ...
- windows控制台,cmd,命令提示符下的基础操作
打开dos命令窗口1.win+r-->运行-->cmd 2.摁住shift+鼠标右击 选择 在此处打开命令窗口3.在磁盘某文件夹下,选择标题栏中输入框,输入cmd 回车 windows下常 ...
- OJ问题集合
1.找出给定数组之中的3个和为0的数. 2.给出一个字符串,给出需要去除的字符串,返回去除需要去除的字符串后的值. 3.一个数组之中的第二最大值三个数的组合.
- c# 获取api 数据
private string GetDataFromServerApi(string url, string body) { string str = ""; try { Http ...
- (六) Java数据库
一.概述 程序开发没有数据库的参与,可以说几乎是不可能的.数据库和Java都已经有了简单的了解,现在的关键是对两者进行连接,起到这一作用的正是JDBC——Java Database Connectiv ...
- 如何用eclipse进行jar文件打包?
直接导出runnable jar,如下图所示: 然后选择导出runnable jar: 关于library handling部分的解释如下: (1)Extract required libraries ...
- POJ-2752-Seek the Name(KMP, 循环节)
链接: https://vjudge.net/problem/POJ-2752#author=0 题意: 给定若干只含小写字母的字符串(这些字符串总长≤400000),在每个字符串中求出所有既是前缀又 ...
- [Functional Programming] propSatisfies with implies
// implies :: ((a -> Boolean), (a -> Boolean)) -> a -> Boolean const implies = (p, q) =& ...