deep_learning_cross_entropy
交叉熵损失函数
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,以及其存在的不足。
- 二次代价函数的不足
ANN的设计目的之一是为了使机器可以像人一样学习知识。人在学习分析新事物时,当发现自己犯的错误越大时,改正的力度就越大。比如投篮:当运动员发现自己的投篮方向离正确方向越远,那么他调整的投篮角度就应该越大,篮球就更容易投进篮筐。同理,我们希望:ANN在训练时,如果预测值与实际值的误差越大,那么在反向传播训练的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。然而,如果使用二次代价函数训练ANN,看到的实际效果是,如果误差越大,参数调整的幅度可能更小,训练更缓慢。
以一个神经元的二类分类训练为例,进行两次实验(ANN常用的激活函数为sigmoid函数,该实验也采用该函数):输入一个相同的样本数据x=1.0(该样本对应的实际分类y=0);两次实验各自随机初始化参数,从而在各自的第一次前向传播后得到不同的输出值,形成不同的代价(误差):
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,以及其存在的不足。
- 二次代价函数的不足
ANN的设计目的之一是为了使机器可以像人一样学习知识。人在学习分析新事物时,当发现自己犯的错误越大时,改正的力度就越大。比如投篮:当运动员发现自己的投篮方向离正确方向越远,那么他调整的投篮角度就应该越大,篮球就更容易投进篮筐。同理,我们希望:ANN在训练时,如果预测值与实际值的误差越大,那么在反向传播训练的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。然而,如果使用二次代价函数训练ANN,看到的实际效果是,如果误差越大,参数调整的幅度可能更小,训练更缓慢。
以一个神经元的二类分类训练为例,进行两次实验(ANN常用的激活函数为sigmoid函数,该实验也采用该函数):输入一个相同的样本数据x=1.0(该样本对应的实际分类y=0);两次实验各自随机初始化参数,从而在各自的第一次前向传播后得到不同的输出值,形成不同的代价(误差):
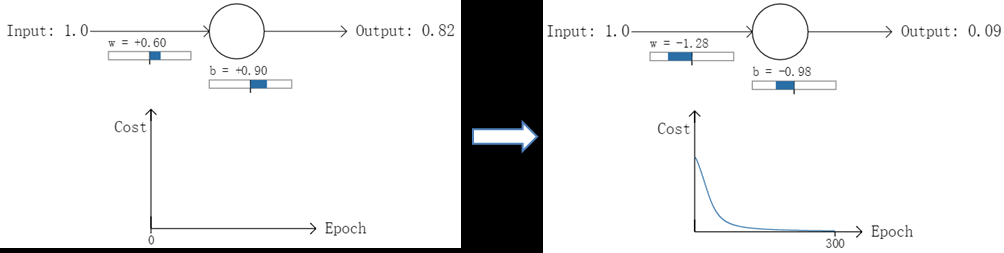
实验1:第一次输出值为0.82

实验2:第一次输出值为0.98
在实验1中,随机初始化参数,使得第一次输出值为0.82(该样本对应的实际值为0);经过300次迭代训练后,输出值由0.82降到0.09,逼近实际值。而在实验2中,第一次输出值为0.98,同样经过300迭代训练,输出值只降到了0.20。
从两次实验的代价曲线中可以看出:实验1的代价随着训练次数增加而快速降低,但实验2的代价在一开始下降得非常缓慢;直观上看,初始的误差越大,收敛得越缓慢。
其实,误差大导致训练缓慢的原因在于使用了二次代价函数。二次代价函数的公式如下:
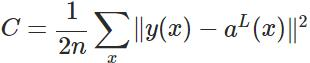

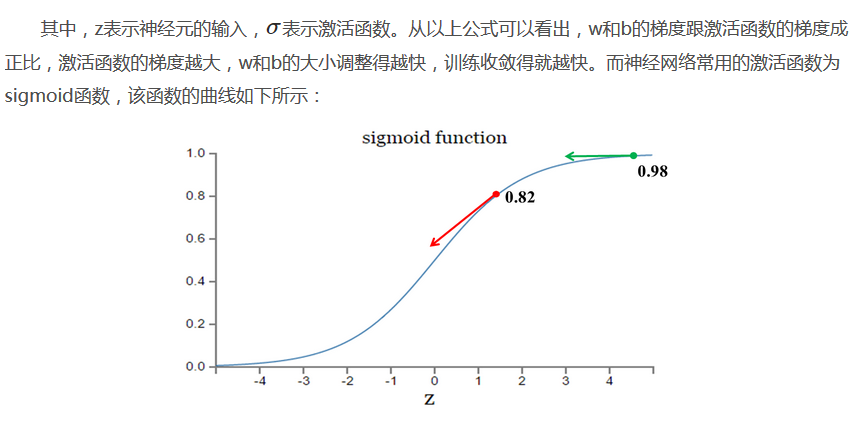
如图所示,实验2的初始输出值(0.98)对应的梯度明显小于实验1的输出值(0.82),因此实验2的参数梯度下降得比实验1慢。这就是初始的代价(误差)越大,导致训练越慢的原因。与我们的期望不符,即:不能像人一样,错误越大,改正的幅度越大,从而学习得越快。
可能有人会说,那就选择一个梯度不变化或变化不明显的激活函数不就解决问题了吗?图样图森破,那样虽然简单粗暴地解决了这个问题,但可能会引起其他更多更麻烦的问题。而且,类似sigmoid这样的函数(比如tanh函数)有很多优点,非常适合用来做激活函数,具体请自行google之


说起交叉熵损失函数「Cross Entropy Loss」,脑海中立马浮现出它的公式:
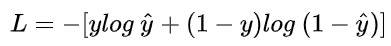
我们已经对这个交叉熵函数非常熟悉,大多数情况下都是直接拿来使用就好。但是它是怎么来的?为什么它能表征真实样本标签和预测概率之间的差值?上面的交叉熵函数是否有其它变种?也许很多朋友还不是很清楚!没关系,接下来我将尽可能以最通俗的语言回答上面这几个问题。
1. 交叉熵损失函数的数学原理
我们知道,在二分类问题模型:例如逻辑回归「Logistic Regression」、神经网络「Neural Network」等,真实样本的标签为 [0,1],分别表示负类和正类。模型的最后通常会经过一个 Sigmoid 函数,输出一个概率值,这个概率值反映了预测为正类的可能性:概率越大,可能性越大。
Sigmoid 函数的表达式和图形如下所示:
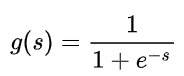

其中 s 是模型上一层的输出,Sigmoid 函数有这样的特点:s = 0 时,g(s) = 0.5;s >> 0 时, g ≈ 1,s << 0 时,g ≈ 0。显然,g(s) 将前一级的线性输出映射到 [0,1] 之间的数值概率上。这里的 g(s) 就是交叉熵公式中的模型预测输出 。
我们说了,预测输出即 Sigmoid 函数的输出表征了当前样本标签为 1 的概率:
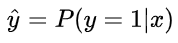
很明显,当前样本标签为 0 的概率就可以表达成:
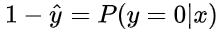
重点来了,如果我们从极大似然性的角度出发,把上面两种情况整合到一起:

也即,当真实样本标签 y = 0 时,上面式子第一项就为 1,概率等式转化为:
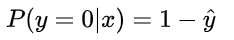
当真实样本标签 y = 1 时,上面式子第二项就为 1,概率等式转化为:
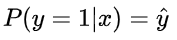
两种情况下概率表达式跟之前的完全一致,只不过我们把两种情况整合在一起了。重点看一下整合之后的概率表达式,我们希望的是概率 P(y|x) 越大越好。首先,我们对 P(y|x) 引入 log 函数,因为 log 运算并不会影响函数本身的单调性。则有:

我们希望 log P(y|x) 越大越好,反过来,只要 log P(y|x) 的负值 -log P(y|x) 越小就行了。那我们就可以引入损失函数,且令 Loss = -log P(y|x)即可。则得到损失函数为:
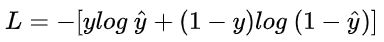
非常简单,我们已经推导出了单个样本的损失函数,是如果是计算 N 个样本的总的损失函数,只要将 N 个 Loss 叠加起来就可以了:
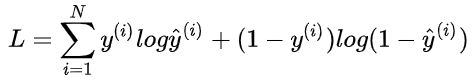
这样,我们已经完整地实现了交叉熵损失函数的推导过程。
2. 交叉熵损失函数的直观理解
可能会有读者说,我已经知道了交叉熵损失函数的推导过程。但是能不能从更直观的角度去理解这个表达式呢?而不是仅仅记住这个公式。好问题!接下来,我们从图形的角度,分析交叉熵函数,加深大家的理解。
首先,还是写出单个样本的交叉熵损失函数:

我们知道,当 y = 1 时:

这时候,L 与预测输出的关系如下图所示:
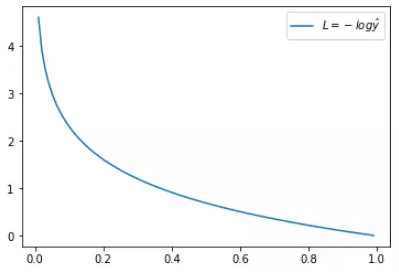
看了 L 的图形,简单明了!横坐标是预测输出,纵坐标是交叉熵损失函数 L。显然,预测输出越接近真实样本标签 1,损失函数 L 越小;预测输出越接近 0,L 越大。因此,函数的变化趋势完全符合实际需要的情况。当 y = 0 时:
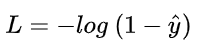
这时候,L 与预测输出的关系如下图所示:
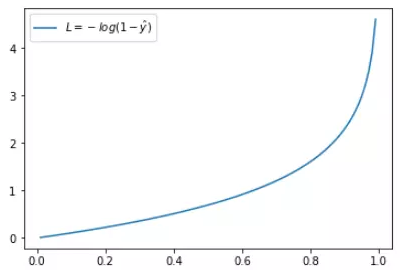
同样,预测输出越接近真实样本标签 0,损失函数 L 越小;预测函数越接近 1,L 越大。函数的变化趋势也完全符合实际需要的情况。
从上面两种图,可以帮助我们对交叉熵损失函数有更直观的理解。无论真实样本标签 y 是 0 还是 1,L 都表征了预测输出与 y 的差距。
另外,重点提一点的是,从图形中我们可以发现:预测输出与 y 差得越多,L 的值越大,也就是说对当前模型的 “ 惩罚 ” 越大,而且是非线性增大,是一种类似指数增长的级别。这是由 log 函数本身的特性所决定的。这样的好处是模型会倾向于让预测输出更接近真实样本标签 y。
3. 交叉熵损失函数的其它形式
什么?交叉熵损失函数还有其它形式?没错!我刚才介绍的是一个典型的形式。接下来我将从另一个角度推导新的交叉熵损失函数。
这种形式下假设真实样本的标签为 +1 和 -1,分别表示正类和负类。有个已知的知识点是Sigmoid 函数具有如下性质:
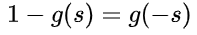
这个性质我们先放在这,待会有用。
好了,我们之前说了 y = +1 时,下列等式成立:
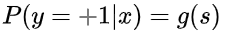
如果 y = -1 时,并引入 Sigmoid 函数的性质,下列等式成立:
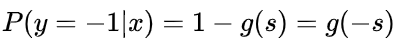
重点来了,因为 y 取值为 +1 或 -1,可以把 y 值带入,将上面两个式子整合到一起:
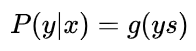
接下来,同样引入 log 函数,得到:
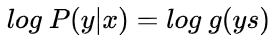
要让概率最大,反过来,只要其负数最小即可。那么就可以定义相应的损失函数为:
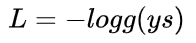
还记得 Sigmoid 函数的表达式吧?将 g(ys) 带入:

好咯,L 就是我要推导的交叉熵损失函数。如果是 N 个样本,其交叉熵损失函数为:
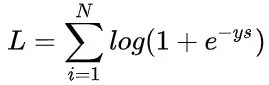
接下来,我们从图形化直观角度来看。当 y = +1 时:
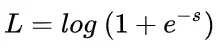
这时候,L 与上一层得分函数 s 的关系如下图所示:
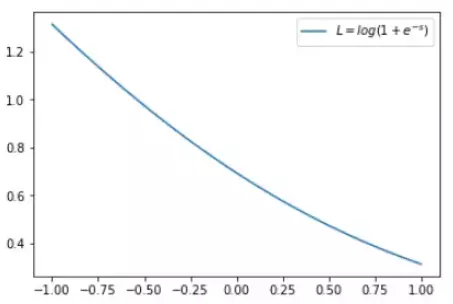
横坐标是 s,纵坐标是 L。显然,s 越接近真实样本标签 1,损失函数 L 越小;s 越接近 -1,L 越大。另一方面,当 y = -1 时:
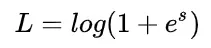
这时候,L 与上一层得分函数 s 的关系如下图所示:
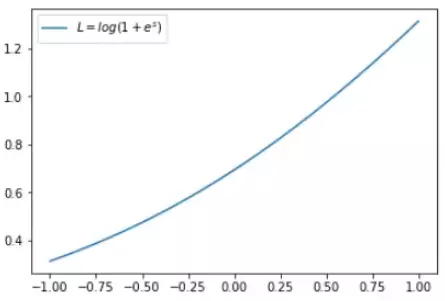
同样,s 越接近真实样本标签 -1,损失函数 L 越小;s 越接近 +1,L 越大。
4. 总结
本文主要介绍了交叉熵损失函数的数学原理和推导过程,也从不同角度介绍了交叉熵损失函数的两种形式。第一种形式在实际应用中更加常见,例如神经网络等复杂模型;第二种多用于简单的逻辑回归模型。
转自:https://www.jianshu.com/p/23623fe17f64
deep_learning_cross_entropy的更多相关文章
随机推荐
- Python之网络模型与图形绘制工具networkx
笔记 # https://www.jianshu.com/p/e543dc63454f import networkx as nx import matplotlib.pyplot as plt ## ...
- coreDNS一直处于创建中解决
https://blog.csdn.net/gsying1474/article/details/53256599 执行: [root@lab1 coredns]# kubectl delete -f ...
- 转:使用ActiveX插件时object显示问题,div被object标签遮挡的解决方案
起因设计要求视频控制面板显示在视频界面上,如下图红框内所示.但是因为object不在文档流之中,所以不论别的元素设置z-index多高,都只会被object元素遮住而无法看到.object元素代码如下 ...
- 学校或公司转ISP -boardband (上网公司)注意事项记录
如果学校或公司轉boardband , 1. 要更新 domain IP (亦可以轉移domain 去新ISP公司, 要HKDNR 登入名稱和密碼,可問舊ISP即boardband 公司或域名管理方要 ...
- Leetcode之动态规划(DP)专题-746. 使用最小花费爬楼梯(Min Cost Climbing Stairs)
Leetcode之动态规划(DP)专题-746. 使用最小花费爬楼梯(Min Cost Climbing Stairs) 数组的每个索引做为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost ...
- 【原创】asp.net webdiyer AspNetPager控件分页码改变时,序号列从新从1开始问题的解决
长话短说,首先看repeater 配合 webdiyer AspNetPager使用时webdiyer AspNetPager属性设置代码. <webdiyer:AspNetPager ID ...
- NDK学习笔记-C语言
本文简要回顾了C语言的一些注意事项和理解细节,不再赘述C语言的所有语法 头文件 头文件作为引入文件,在编译的时候,加载到源代码,参与编译 在VS2013中可以看到,当引入头文件时候,只能看到函数的声明 ...
- django中的Form和ModelForm中的问题
django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新 方法一:重写构造方法,在构造方法中重新去获取值 class UserForm(forms.Form): ...
- beautifulsoap爬虫
从html文件读 from bs4 import BeautifulSoup html_doc="文件地址" html_file=open(html_doc,"r&quo ...
- windows 安装jenkins
本文简单记录 windows 安装 jenkins. 1. 下载jenkins安装包,下载地址:https://jenkins.io/index.html 2. 选择下载windows版 3. 解压, ...