Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1——第一个Spark程序:单词数统计
笔记摘抄自 [美] Holden Karau 等著的《Spark快速大数据分析》
添加依赖
通过 Maven 添加 Spark-core_2.10 的依赖
程序
找了一篇注释比较清楚的博客代码[1],一次运行通过
import scala.Tuple2;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import java.util.Arrays;import java.util.Iterator;import java.util.List;import java.util.regex.Pattern;public final class WordCount {private static final Pattern SPACE = Pattern.compile(" ");public static void main(String[] args) throws Exception {if (args.length < 1) {System.err.println("Usage: JavaWordCount <file>");System.exit(1);}/*** 对于所有的spark程序所言,要进行所有的操作,首先要创建一个spark上下文。* 在创建上下文的过程中,程序会向集群申请资源及构建相应的运行环境。* 设置spark应用程序名称* 创建的 sarpkContext 唯一需要的参数就是 sparkConf,它是一组 K-V 属性对。*/SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");JavaSparkContext ctx = new JavaSparkContext(sparkConf);/*** 利用textFile接口从文件系统中读入指定的文件,返回一个RDD实例对象。* RDD的初始创建都是由SparkContext来负责的,将内存中的集合或者外部文件系统作为输入源。* RDD:弹性分布式数据集,即一个 RDD 代表一个被分区的只读数据集。一个 RDD 的生成只有两种途径,* 一是来自于内存集合和外部存储系统,另一种是通过转换操作来自于其他 RDD,比如 Map、Filter、Join,等等。* textFile()方法可将本地文件或HDFS文件转换成RDD,读取本地文件需要各节点上都存在,或者通过网络共享该文件*读取一行*/JavaRDD<String> lines = ctx.textFile(args[0], 1);/**** new FlatMapFunction<String, String>两个string分别代表输入和输出类型* Override的call方法需要自己实现一个转换的方法,并返回一个Iterable的结构** flatmap属于一类非常常用的spark函数,简单的说作用就是将一条rdd数据使用你定义的函数给分解成多条rdd数据* 例如,当前状态下,lines这个rdd类型的变量中,每一条数据都是一行String,我们现在想把他拆分成1个个的词的话,* 可以这样写 :*///flatMap与map的区别是,对每个输入,flatMap会生成一个或多个的输出,而map只是生成单一的输出//用空格分割各个单词,输入一行,输出多个对象,所以用flatMapJavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String s) {return Arrays.asList(SPACE.split(s)).iterator();}});/*** map 键值对 ,类似于MR的map方法* pairFunction<T,K,V>: T:输入类型;K,V:输出键值对* 表示输入类型为T,生成的key-value对中的key类型为k,value类型为v,对本例,T=String, K=String, V=Integer(计数)* 需要重写call方法实现转换*/JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {//scala.Tuple2<K,V> call(T t)//Tuple2为scala中的一个对象,call方法的输入参数为T,即输入一个单词s,新的Tuple2对象的key为这个单词,计数为1@Overridepublic Tuple2<String, Integer> call(String s) {return new Tuple2<String, Integer>(s, 1);}});//A two-argument function that takes arguments// of type T1 and T2 and returns an R./*** 调用reduceByKey方法,按key值进行reduce* reduceByKey方法,类似于MR的reduce* 要求被操作的数据(即下面实例中的ones)是KV键值对形式,该方法会按照key相同的进行聚合,在两两运算* 若ones有<"one", 1>, <"one", 1>,会根据"one"将相同的pair单词个数进行统计,输入为Integer,输出也为Integer*输出<"one", 2>*/JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {//reduce阶段,key相同的value怎么处理的问题@Overridepublic Integer call(Integer i1, Integer i2) {return i1 + i2;}});//备注:spark也有reduce方法,输入数据是RDD类型就可以,不需要键值对,// reduce方法会对输入进来的所有数据进行两两运算/*** collect方法用于将spark的RDD类型转化为我们熟知的java常见类型*/List<Tuple2<String, Integer>> output = counts.collect();for (Tuple2<?,?> tuple : output) {System.out.println(tuple._1() + ": " + tuple._2());}ctx.stop();}}
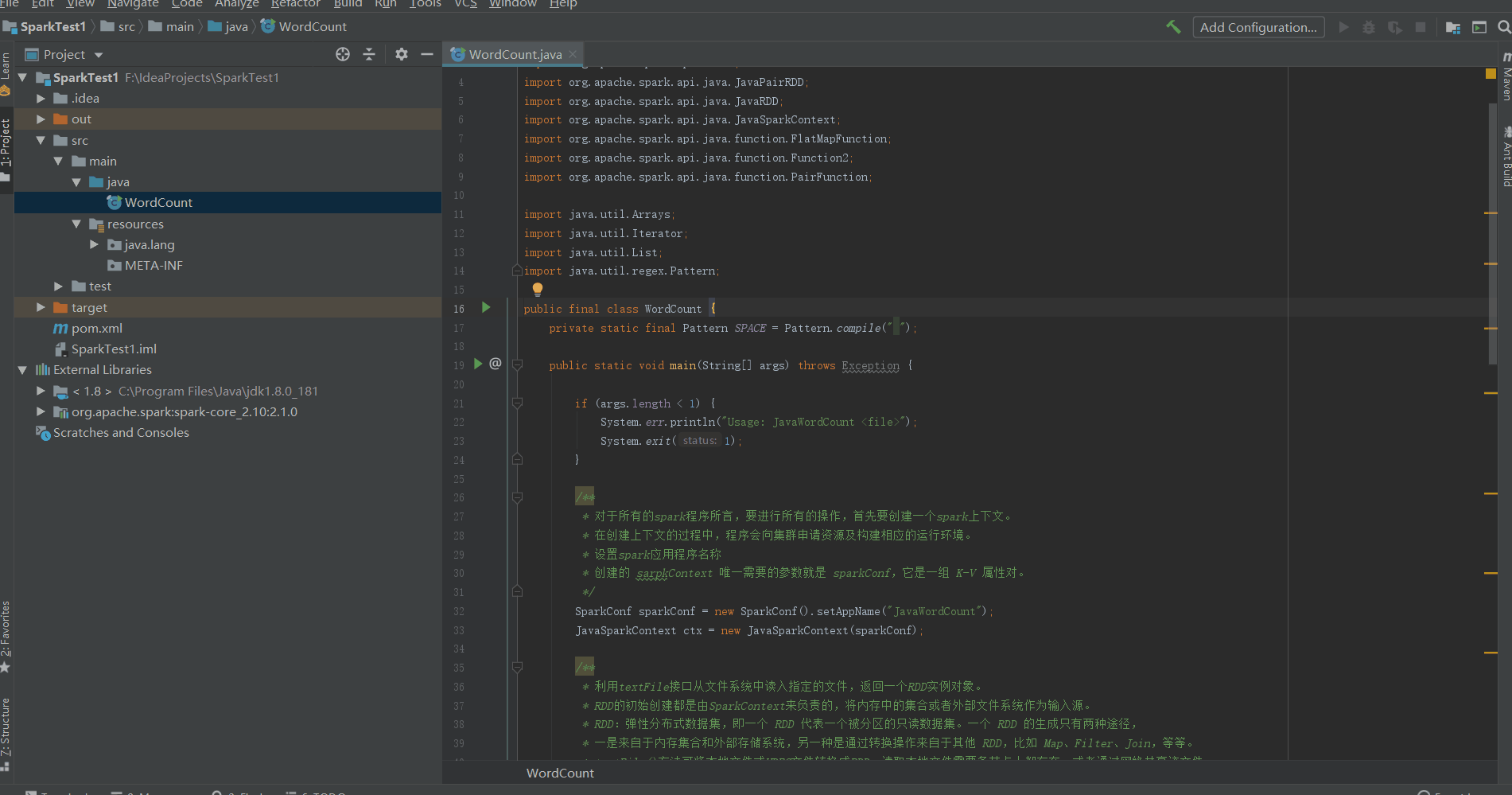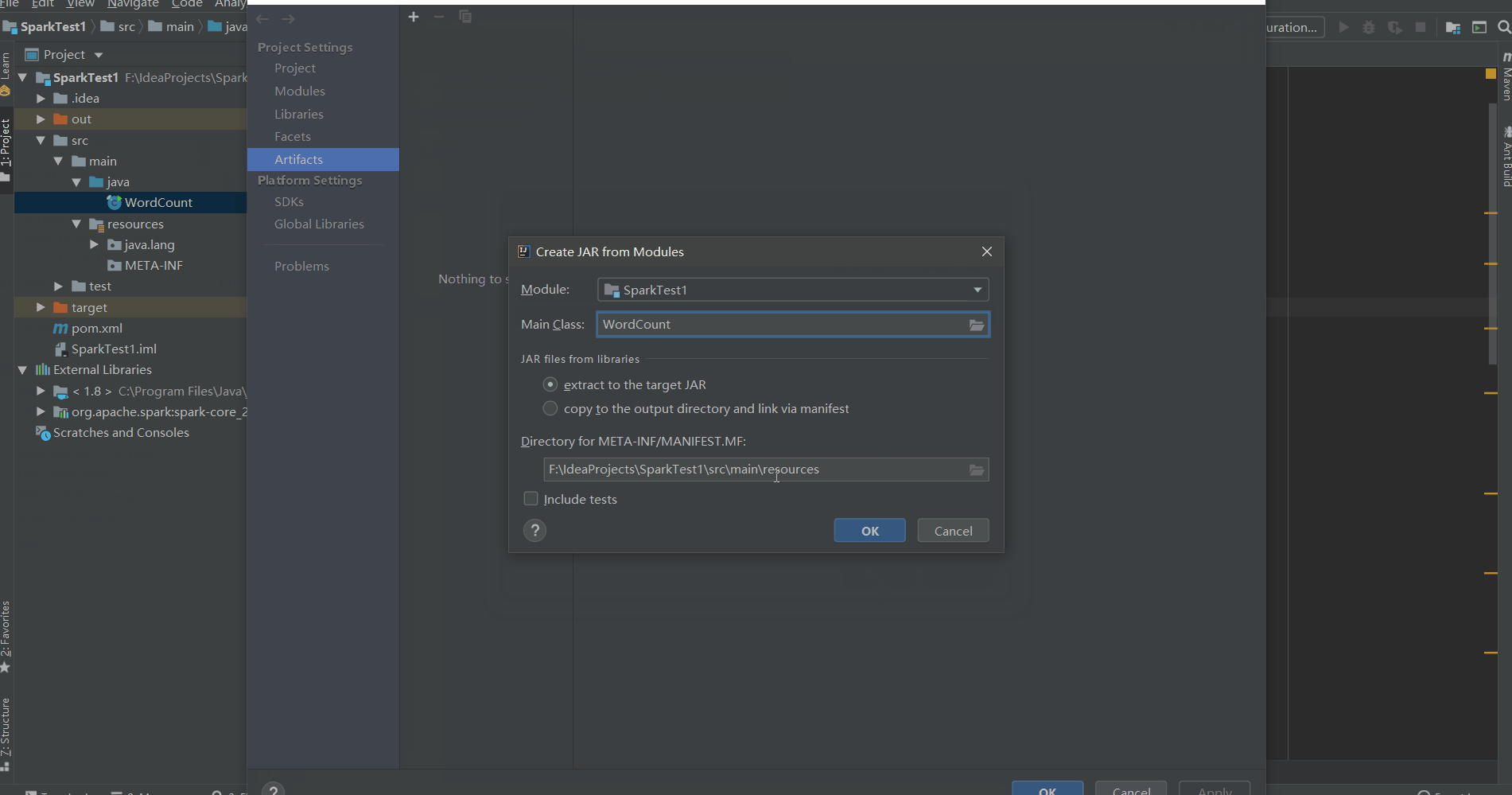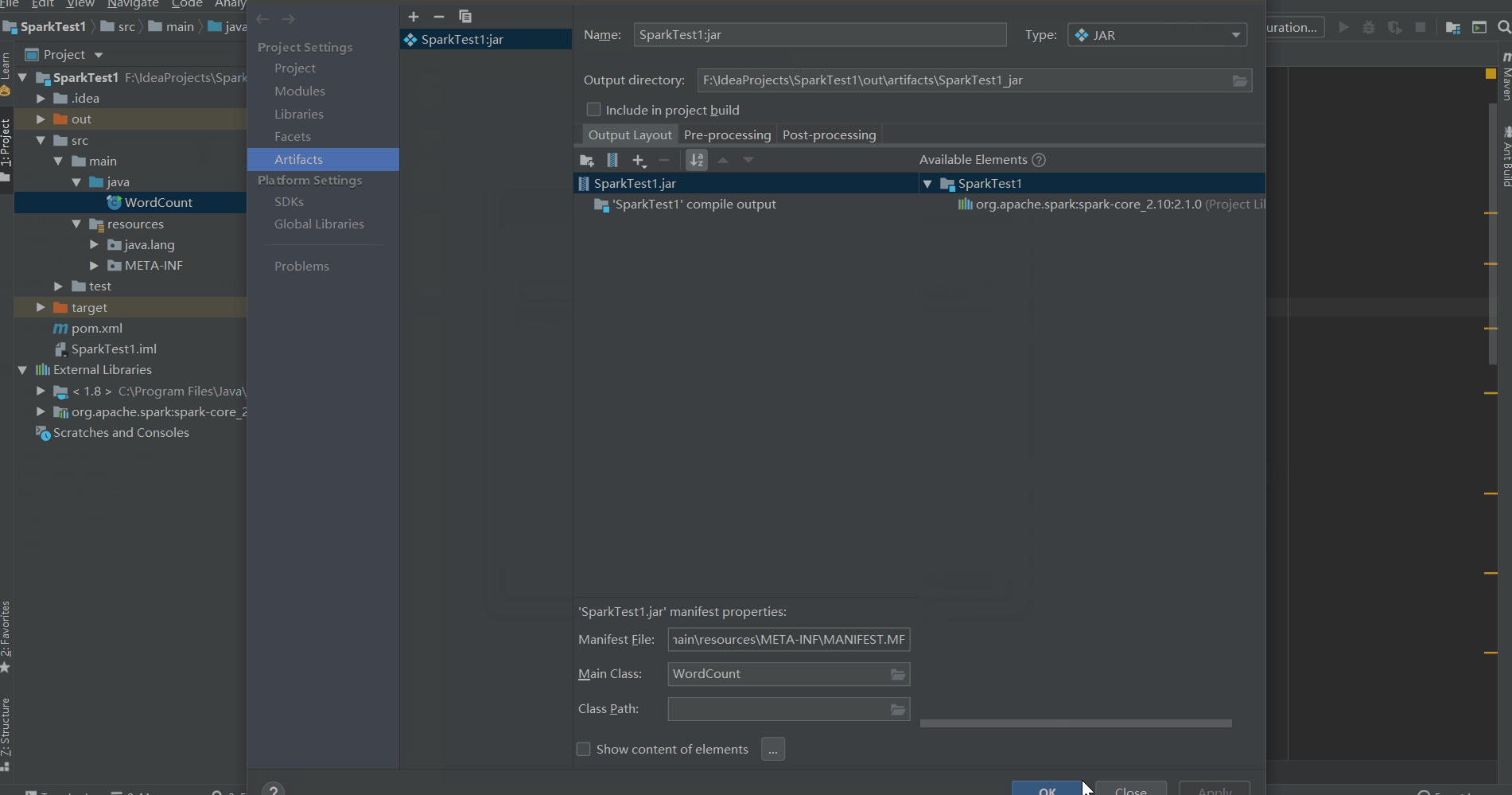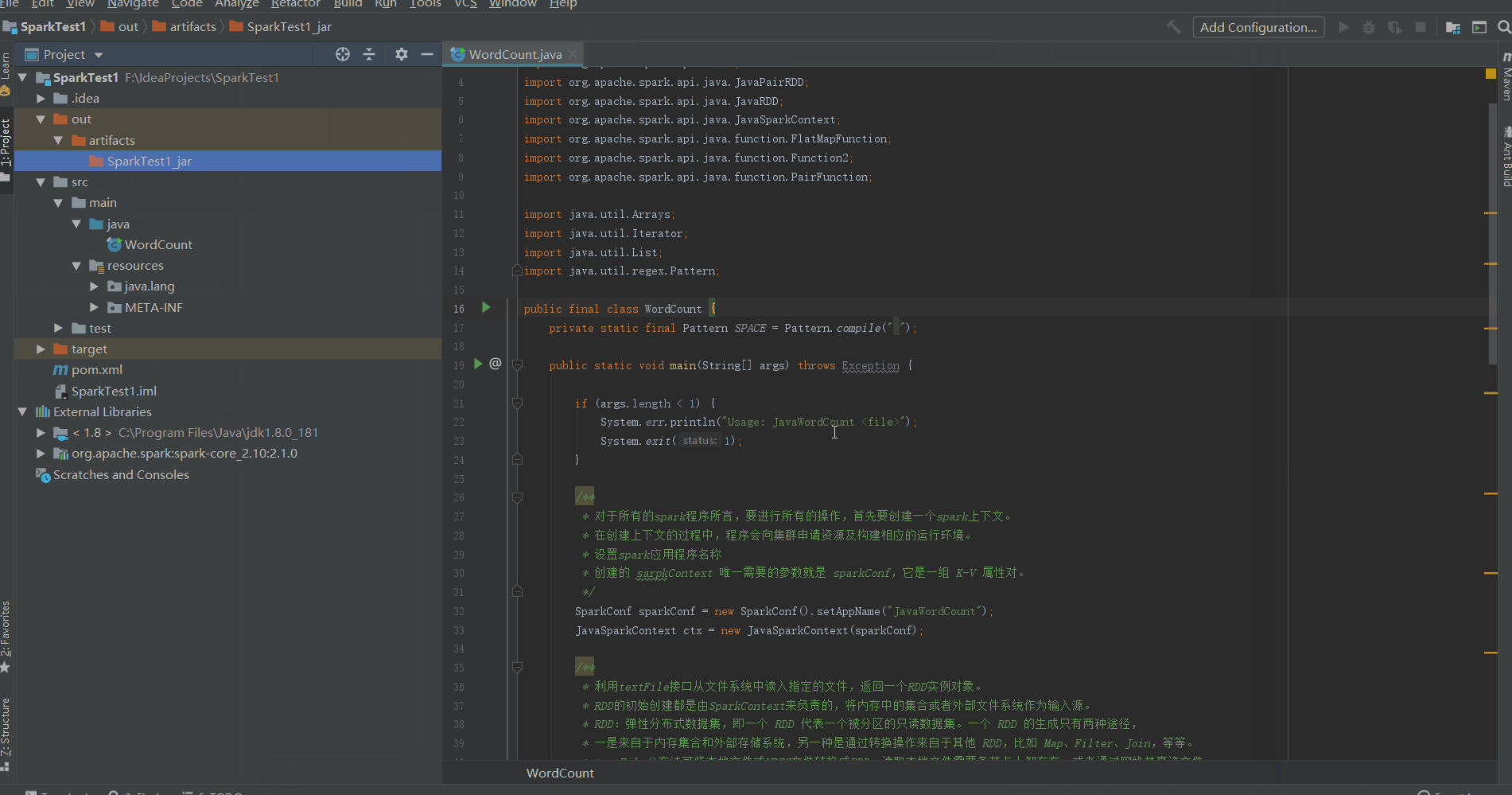
打包
将程序打包后上传到Linux
测试用例
[root@server1 ~]# vi test.txtaa ba b ca b c da b c d e
运行
[root@server1 spark-2.4.4-bin-hadoop2.7]# pwd/root/spark-2.4.4-bin-hadoop2.7[root@server1 spark-2.4.4-bin-hadoop2.7]# bin/spark-submit --class WordCount ~/SparkTest1.jar ~/test.txt19/09/09 17:04:56 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.properties...19/09/09 17:04:58 INFO DAGScheduler: ResultStage 1 (collect at WordCount.java:97) finished in 0.082 s19/09/09 17:04:58 INFO DAGScheduler: Job 0 finished: collect at WordCount.java:97, took 0.562887 sd: 2e: 1a: 5b: 4c: 3...
P.s. Spark 单机模式在官网下载压缩包解压进入 bin 目录下即可运行
Spark学习笔记1——第一个Spark程序:单词数统计的更多相关文章
- C#.NET学习笔记2---C#.第一个C#程序
C#.NET学习笔记2---C#.第一个C#程序 技术qq交流群:JavaDream:251572072 教程下载,在线交流:创梦IT社区:www.credream.com 6.第一个C#程序: ...
- 【opencv学习笔记五】一个简单程序:图像读取与显示
今天我们来学习一个最简单的程序,即从文件读取图像并且创建窗口显示该图像. 目录 [imread]图像读取 [namedWindow]创建window窗口 [imshow]图像显示 [imwrite]图 ...
- Spark学习笔记1(初始spark
1.什么是spark? spark是一个基于内存的,分布式的,大数据的计算框架,可以解决各种大数据领域的计算问题,提供了一站式的服务 Spark2009年诞生于伯克利大学的AMPLab实验室 2010 ...
- OD学习笔记10:一个VB程序的加密和解密思路
前边,我们的例子中既有VC++开发的程序,也有Delphi开发的程序,今天我们给大家分析一个VB程序的加密和解密思路. Virtual BASIC是由早期DOS时代的BASIC语言发展而来的可视化编程 ...
- c++学习笔记---04---从另一个小程序接着说
从另一个小程序接着说 文件I/O 前边我们已经给大家简单介绍和演示过C和C++在终端I/O处理上的异同点. 现在我们接着来研究文件I/O. 编程任务:编写一个文件复制程序,功能实现将一个文件复制到另一 ...
- Spark学习笔记(三)-Spark Streaming
Spark Streaming支持实时数据流的可扩展(scalable).高吞吐(high-throughput).容错(fault-tolerant)的流处理(stream processing). ...
- 学习笔记_第一个strut程序_之中文乱码,过滤器解决方案及过程总结
1. 第一次碰到加过滤器的过程,就是在学习struct1的时候,中文乱码 几个需要注意的关键字 2.什么叫package 所谓package就是打包的意思,就是说以下程序都是处于这个包内,所以一开始 ...
- OpenGL学习笔记:第一个OpenGL程序
OpenGL环境搭建参考博客:VS2015下OpenGL库的配置. #include<GL\glew.h> #include<GLTools.h> #include<GL ...
- 吴裕雄--天生自然JAVA SPRING框架开发学习笔记:第一个Spring程序
1. 创建项目 在 MyEclipse 中创建 Web 项目 springDemo01,将 Spring 框架所需的 JAR 包复制到项目的 lib 目录中,并将添加到类路径下,添加后的项目如图 2. ...
随机推荐
- ubuntu 16.04 修改网卡显示名称
~# sudo nano /etc/default/grub找到:GRUB_CMDLINE_LINUX=""改为:GRUB_CMDLINE_LINUX="net.ifna ...
- iOS的推送证书过期的处理
1.删除MAC上钥匙串访问中对应的推送证书.<根据过期日期看> 2.登录苹果开发者后台,revoke删除已过期推送证书(貌似会自己消失不用删除,具体记不清了...),然后为对应App ID ...
- python调用shell命令
1.subprocess介绍 官方推荐 subprocess模块,os.system(command) 这个废弃了 亲测 os.system 使用sed需要进行字符转义,非常麻烦 python3 su ...
- Spring Boot中mybatis insert 如何获得自增id
https://www.cnblogs.com/quan-coder/p/8728410.html 注意要显式设置主键,通过: @Options(useGeneratedKeys = true, ke ...
- scdbg分析shellcode
https://isc.sans.edu/forums/diary/Another+quickie+Using+scdbg+to+analyze+shellcode/24058/ scdbg -f s ...
- Exploit completed, but no session was created.
在kali上做metasploit实验,步骤如下: msf5 exploit(windows/mssql/mssql_payload) > show options Module options ...
- (IStool)64位软件安装在32位操作系统时给出提示
需求:64位的软件当在32位操作系统下安装时,需要提示用户不能在32位操作系统中进行安装 实现:打包时启用64位模式(打包工具用的是Inno Setup 5) 安装脚本段需要添加以下代码: [Setu ...
- springboot下html的js中使用shiro标签功能
在js中直接使用shiro标签是不行的 比如 下面有个小技巧
- 在搭建Hadoop集群环境时遇到的一些问题
最近在学习搭建hadoop集群环境,在搭建的过程中遇到很多问题,在这里做一些记录.1. SSH相关的问题 问题一: ssh: connect to host localhost port 22: Co ...
- Appium+unittest+python登录app
代码: # coding=utf-8 from appium import webdriver import time import unittest import os import HTMLTes ...