Video Captioning 综述
1.Unsupervised learning of video representations using LSTMs
方法:从先前的帧编码预测未来帧序列
相似于Sequence to sequence learning with neural networks论文
方法:使用一个LSTM编码输入文本成固定表示,另一个LSTM解码成不同语言
2.Describing Videos by Exploiting Temporal Structure
该论文发表在iccv2015,是第一篇使用时间关注解决视频描述的文章。
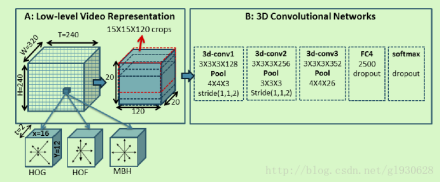
方法:①使用融合时空运动特征的3D回旋网络
②引入attention机制
3.Long-term recurrent convolutional networks for visual recognition and description
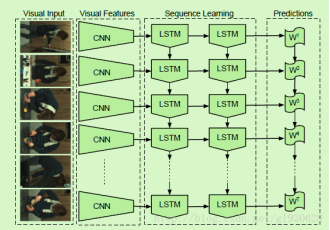
方法:①使用CRFs获得活动物体工具位置的语义元组
②使用一层LSTM将元组翻译成句子
缺点:仅用于有限域
4.Translating videos to natural language using deep recurrent neural networks
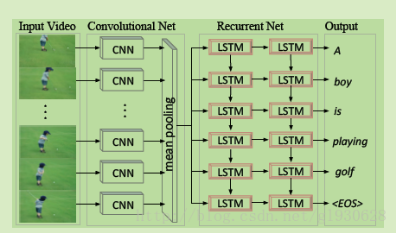
①CNN抽取视频帧特征
②平均池化产生单一特征向量代表整个视频
③使用LSTM作为序列编码器产生基于向量的描述
缺点:①完全忽略视频帧顺序
②未利用时间信息
5. Sequence to Sequence -Video to Text
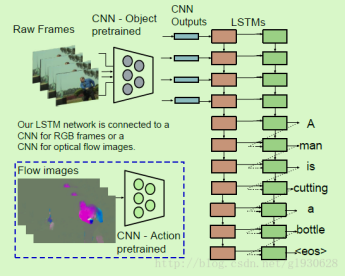
出现问题:1.现实世界视频复杂(物件场景行为属性多样化,并且难以确定主要内容正确用文本描述事件)
2.对视频描述需要对时间结构敏感以及允许可变长度的输入(视频帧)输出(文本)
方法:端到端序列到序列模型,使用LSTMs
模型:S2VT,学习直接将序列帧映射成序列句子。使用一层LSTM编码视频帧序列成分布式向量表示。这层单一的LSTM对输入编码并解码,允许在编码和解码时分享权重。
①LSTM对帧逐一编码,帧由CNN输出。为模拟时间活动方面,计算连续帧对之间的光流。流图像通过CNN输出给LSTM作为输出
②读取了所有帧,模型就逐句生成句子。
同时加入了另外的特征——光流图像提取的特征,因为可以更好的表示视频中的动作。
本篇详细方法:
1.LSTMs for sequence modeling
在编码阶段,给一个输入序列X(1,2,…n),LSTM计算一个隐藏状态序列(h1,h2,…hn)
解码阶段,给定输入序列X的输出序列Y定义分布为p(Y|X)
2.序列到序列视频到文本
其他方法:第一个LSTM将输入序列编码成一个固定长度向量,第二个LSTM将向量映射成序列输出。
本篇方法:一个单一的LSTM进行编码解码。
①在前几时间步里,首层LSTM获得序列帧,进行编码,二层LSTM获得隐藏表示ht联结成空的输入句子,然后编码
②当视频帧结束后,第二层LSTM会嵌入一个句子开始(BOS)标签,提示开始编码现有的隐藏表示为句子序列
3.视频和文本表示
(1)RGB frames:使用CNN输入图片提供输出为LSTMs的输入。输入视频帧为256256,裁剪为227227
本篇还移除了原始的最后一层全连接分类层,学习新的特征线性嵌入成一个500维空间。这个低维特征构成到第一层LSTM的输入
(2)Optical Flow:
①抽取经典变分光流特征
②创造流图像
③计算流强度并作为第三频道增加到流图像
④使用CNN初始化在UCF101视频集上的权重来将光流图像分类为101个活动类别。CNN的fc6层活性被嵌入到一个低于500维空间里并作为LSTM的输入。
在组合模型中,使用浅融合技术来组合流和RGB特征。
(3)文本输入
目标输出单词序列使用one-hot向量解码表示。
①通过应用线性变换嵌入单词成低于500的维空间成输入数据,然后通过反向传播学习参数。
②嵌入的单词向量连接第一层LSTM的输出ht来构成第二层LSTM的输入。
③对于LSTM输出应用softmax成完整的词汇
总结:对视频的特征提取也仅仅对每帧的图像使用CNN网络进行2D特征的提取,同时加入了另外的特征——光流图像提取的特征,因为可以更好的表示视频中的动作,整个视频encoder和decoder过程在一个LSTM模型上完成,考虑到了视频的时序特征,因此使用LSTM网络来顺序进行图像特征的输入,用隐含层来表示整个视频,再接着输入单词来逐个预测单词,之后是详细介绍。
6. Frame- and Segment-Level Features and Candidate Pool Evaluation for Video Caption Generation(2016)
这篇文章提出的方法就是用不同的模型在不同种类的特征上进行训练从而来生成视频的描述,再使用一个评估网络来评估生成句子和视频特征之间的关联性,选择关联性最好的为最终的视频描述。
选择的特征有三种:第一种是针对帧的特征,使用GoogleNet来提取特征;第二种是基于视频片段的特征,这里文章使用了两种特征,人工特征dense trajectories和使用C3D网络提取的特征;第二种是数据库给出的视频类别信息,一共20类。
在decoder上使用了LSTM的改进版,深层的LSTM,并且一个模型使用两种特征来进行训练,一种来init,另一种来persist。
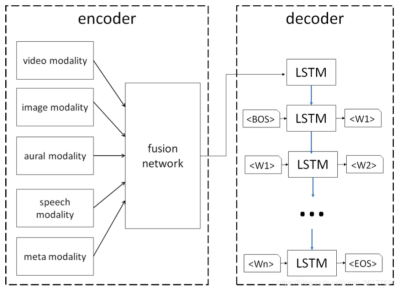
7.Describing Videos using Multi-modal Fusion(2016)
这篇文章使用了多种类型的特征,比如:图像特征、视频特征、环境音特征、语音特征和种类特征,将它们融合作为视频的表示。其中的的fusion network实际上是单层的FC网络,即对各类型的特征进行加权平均,在输入到decoder的LSTM模型来生成描述。
8.Multi-Task Video Captioning with Video and Entailment Generation 2017 ICCV
这篇文章的主要贡献是提出了使用多任务学习来优化视频描述任务,作者认为单独使用一个模型来训练视频描述任务不能很好的提取时序特征也就是动作序列,同时他把视频描述当成了一个推演过程,通过视频特征序列来推演出对应的描述,给出前提(视频特征)得出结果(描述),作者认为单任务单模型不能很好的拟合这种推演过程。因此他提出了用多任务来弥补视频描述中缺乏时序表示和逻辑推演这两方面。

这篇文章模型是没有创新的,还是2015年提出的attention加LSTM模型,每个任务的模型还有视频提取特征方法还有待提升。主要贡献是提出了多任务学习方法,其实个人认为还是加入更多的模型,更多的数据从而得到更好的特征来提升效果。
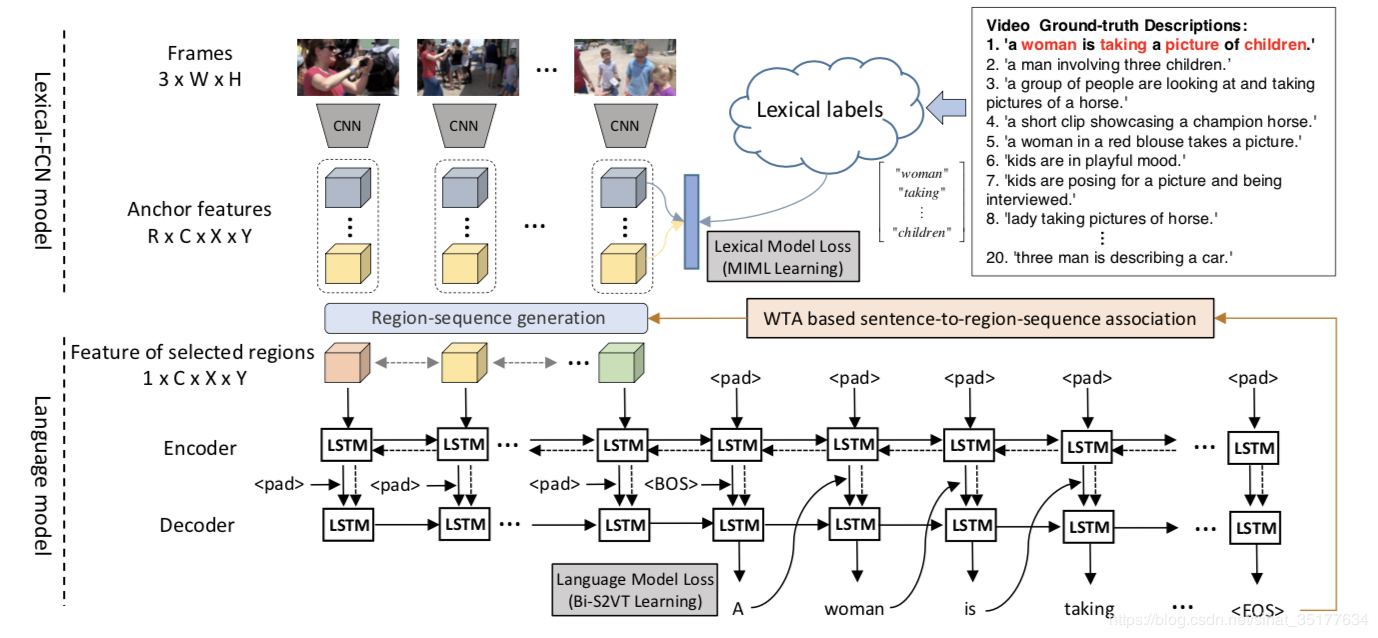
9.Weakly Supervised Dense Video Captioning 2017 CVPR
接下来这篇论文就比较厉害了(同时比较复杂),可以说开启了视频描述的新篇章,基于区域序列的多视频描述生成,因为作者觉得视频包含的信息很多,一句话是描述不清楚的,视频中也包含这各种对象,每个对象有着不同的动作,因此提出了基于区域序列的视频描述,同时这些描述要保证多样性,全方位的描述整个视频。如图,对同一个视频,先提取出不同的区域序列,对每个区域序列生成一句描述。至于为什么是弱监督学习,因为现在的视频描述数据库没有针对区域序列的描述数据,只有视频级的描述,要用视频级的描述来学习区域级的描述,因此是弱监督学习。
参考文献:
Video Captioning 综述的更多相关文章
- 视频描述(Video Captioning)调研
Video Analysis 相关领域介绍之Video Captioning(视频to文字描述)http://blog.csdn.net/wzmsltw/article/details/7119238 ...
- 视频描述(Video Captioning)近年重要论文总结
视频描述 顾名思义视频描述是计算机对视频生成一段描述,如图所示,这张图片选取了一段视频的两帧,针对它的描述是"A man is doing stunts on his bike", ...
- [ Continuously Update ] The Paper List of Image / Video Captioning
Papers Published in 2018 Convolutional Image Captioning - Jyoti Aneja et al., CVPR 2018 - [ Paper Re ...
- SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
题目:SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning 作者: Lo ...
- NLP(Natural Language Processing)
https://github.com/kjw0612/awesome-rnn#natural-language-processing 通常有: (1)Object Recognition (2)Vis ...
- Awesome Deep Vision
Awesome Deep Vision A curated list of deep learning resources for computer vision, inspired by awes ...
- RNN 与 LSTM 的应用
之前已经介绍过关于 Recurrent Neural Nnetwork 与 Long Short-Trem Memory 的网络结构与参数求解算法( 递归神经网络(Recurrent Neural N ...
- Deep Learning Papers
一.Image Classification(Recognition) lenet: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf alexn ...
- rnn应用
Weather Recognition plays an important role in our daily lives and many computer vision applications ...
随机推荐
- 微信小程序点击图片预览-wx.previewImage
<view class='imgList'> <view class='imgList-li' wx:for='{{imgArr}}'> <image class='im ...
- linux下Django Nginx+uwsgi 安装配置
原文链接 在前面的章节中我们使用 python manage.py runserver 来运行服务器.这只适用测试环境中使用. 正式发布的服务,我们需要一个可以稳定而持续的服务器,比如apache, ...
- Linux基础知识之文件的权限(一)
Linux基础知识之文件权限(一) Linux优点之一就是它拥有多用户多任务的环境,在提供文件共享的同时也能保证用户文件的安全性.所以,设置文件的权限管理变得尤为重要. 权限讲解 [der@Der ~ ...
- 洛谷P1462 通往奥格瑞玛的道路(SPFA+二分答案)
题目背景 在艾泽拉斯大陆上有一位名叫歪嘴哦的神奇术士,他是部落的中坚力量 有一天他醒来后发现自己居然到了联盟的主城暴风城 在被众多联盟的士兵攻击后,他决定逃回自己的家乡奥格瑞玛 题目描述 在艾泽拉斯, ...
- okhttp缓存策略源码分析:put&get方法
对于OkHttp的缓存策略其实就是在下一次请求的时候能节省更加的时间,从而可以更快的展示出数据,那在Okhttp如何使用缓存呢?其实很简单,如下: 配置一个Cache既可,其中接收两个参数:一个是缓存 ...
- mysql基础_操作文件中的内容
1.插入数据: insert into t1(id,name) values(1,'alex'); #向t1表中插入id为1,name为'alex'的一条数据 2.删除: delete from t1 ...
- retrying failed action with response code: 403 错误解决
[2019-06-10T06:52:51,610][INFO ][logstash.outputs.elasticsearch] retrying failed action with respons ...
- Jquery调用Ajax实现联动使用json
在很多时候我们都会使用到联动.jquery.js是一个不错的js框架.其ajax也挺不错.下面将实现一个js联动:选择公司出来受益人.根据公司不同受益人不同. 前提是:你用引入jquery.js &l ...
- keras使用AutoEncoder对mnist数据降维
import keras import matplotlib.pyplot as plt from keras.datasets import mnist (x_train, _), (x_test, ...
- not(expr|ele|fn)从匹配元素的集合中删除与指定表达式匹配的元素
not(expr|ele|fn) 概述 从匹配元素的集合中删除与指定表达式匹配的元素 参数 exprStringV1.0 一个选择器字符串.深圳dd马达 elementDOMElementV1.0 ...