GBDT笔记
GBDT笔记
GBDT是Boosting算法的一种,谈起提升算法我们熟悉的是Adaboost,它和AdaBoost算法不同;
区别如下: AdaBoost算法是利用前一轮的弱学习器的误差来更新样本权重值,然后一轮一轮的迭代;
GBDT也是迭代,但是GBDT要求弱学习器必须是CART模型,
而且GBDT在模型训练的时候,是要求模型预测的样本损失尽可能的小。
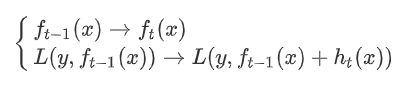
GBDT由三部分构成:
DT(Regression Decistion Tree)、GB(Gradient Boosting)和Shrinkage(衰减)
GBD是由多棵决策树组成,所有树的结果累加起来就是最终结果 迭代决策树和随机森林的区别: 随机森林使用抽取不同的样本构建不同的子树,也就是说第m棵树的构建和前m-1棵树的 结果是没有关系的 迭代决策树在构建子树的时候,使用之前子树构建结果后形成的残差作为输入数据构建下 一个子树;然后最终预测的时候按照子树构建的顺序进行预测(串行),并将预测结果相加.
训练过程
希望损失函数能够不断的减小,并且能够尽可能快的减小。 1.让损失函数沿着梯度方向的下降。这个就是gb。 2.利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。这个是dt。 3.这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
特征选择
gbdt选择特征的细节其实就是CART树生成的过程。 gbdt的弱分类器默认选择的是CART树。其实也可以选择其他弱分类器的(前提是低方差和高偏差。框架服从boosting 框架即可) CART树(是一种二叉树) 的生成:
CART树生成的过程其实就是一个选择特征的过程
假设我们目前总共有 M 个特征。
从中选择出一个特征 j,做为二叉树的第一个节点(选择量度为基尼系数)。
对特征 j 的值选择一个切分点 m.
一个样本的特征j的值如果小于m则分为一类,如果大于m则分为另外一类,如此便构建了CART 树的一个节点。
其他节点的生成过程和这个是一样的迭代生成。
对于每轮选择的时候,如何选择这个特征 j,以及如何选择特征 j 的切分点 m,原始的gbdt的做法非常的暴力,首先遍历每个特征,然后对每个特征遍历它所有可能的切分点,找到最优特征 m 的最优切分点 j。
算法原理
首先给定输入向量X和输出变量Y组成的若干训练样本(X1,Y1),(X2,Y2)......(Xn,Yn),目标是找到近似函数F(X),使得损失函数L(Y,F(X))的损失值最小。 L损失函数一般采用最小二乘损失函数或者绝对值损失函数:
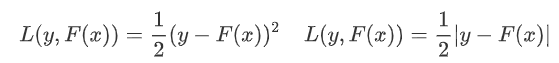
求最优解:

假定最终模型F(x) 是一组最优基函数f(x)的加权和:
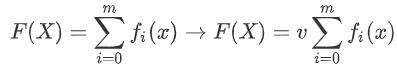
使用贪心算法的思想扩展得到Fm(X),求解最优f:
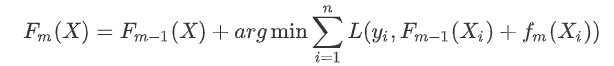
但是贪心法在每次选择最优基函数f时仍然困难,使用梯度下降的方法近似计算
给定常数函数F0(X):

根据梯度下降求解学习率:
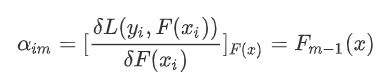
使用数据(x_i,α_im) (i=1……n )计算拟合残差找到一个CART回归树,得到第m棵树:
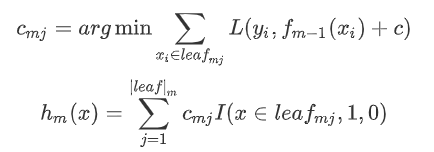
更新模型:

缺点:GBDT在sklearn中执行速度是最慢的
from sklearn.ensemble import GradientBoostingRegressor
# 使用AdaBoostRegressor; GBDT模型只支持CART模型
gbdt = GradientBoostingRegressor(n_estimators=100, learning_rate=0.01, random_state=14)
gbdt.fit(x_train, y_train)
print("训练集上R^2:%.5f" % gbdt.score(x_train, y_train))
print("测试集上R^2:%.5f" % gbdt.score(x_test, y_test))
GBDT笔记的更多相关文章
- 笔记︱决策树族——梯度提升树(GBDT)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记来源于CDA DSC,L2-R语言课程所 ...
- Boosting学习笔记(Adboost、GBDT、Xgboost)
转载请注明出处:http://www.cnblogs.com/willnote/p/6801496.html 前言 本文为学习boosting时整理的笔记,全文主要包括以下几个部分: 对集成学习进行了 ...
- [笔记]GBDT理论知识总结
一. GBDT的经典paper:<Greedy Function Approximation:A Gradient Boosting Machine> Abstract Function ...
- GBDT学习笔记
GBDT(Gradient Boosting Decision Tree,Friedman,1999)算法自提出以来,在各个领域广泛使用.从名字里可以看到,该算法主要涉及了三类知识,Gradient梯 ...
- scikit-learn 梯度提升树(GBDT)调参笔记
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- 【学习笔记】GBDT算法和XGBoost
前言 这一篇内容我学了足足有五个小时,不仅仅是因为内容难以理解, 更是因为前面CART和提升树的概念和算法本质没有深刻理解,基本功不够就总是导致自己的理解会相互在脑子里打架,现在再回过头来,打算好好总 ...
- Adaboost\GBDT\GBRT\组合算法
Adaboost\GBDT\GBRT\组合算法(龙心尘老师上课笔记) 一.Bagging (并行bootstrap)& Boosting(串行) 随机森林实际上是bagging的思路,而GBD ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
随机推荐
- 'internalField' 和'boundaryField'的区别?【翻译】
翻译自:CFD-online 帖子地址:http://www.cfd-online.com/Forums/openfoam/84322-difference-between-internalfield ...
- 代码检查p626
1 编译运行p626 图10-3代码,提交编译运行的截图 2 STDOUT_FILENO的值是多少?提交在Ubuntu中查找这个值的命令截图
- 我的公众号:WebHub
欢迎各位小可爱关注我的公众号WebHub(ID:myWebHub),公众号不定期更新软件行业的总结性文章,内容包括行业趋势和软件哲学,文章不谈技术只谈思想,满满干货! 此外,公众号文章同步CSDN博客 ...
- git submodule 如何push代码
某git项目关联了一个submodule 如何更新该项目下的submodule https://stackoverflow.com/questions/5814319/git-submodule-pu ...
- qt 设置程序控件样式
1. 以资源文件的形式设置控件样式 QFiledata(QString(":/style.qss")); QStringqssFile; if(data.open(QFile::R ...
- IIS配置问题:WCF服务打开svc文件报错:请求的内容似乎是脚本,因而将无法由静态文件处理程序来处理
在参考网上多个教程后,我用IIS配置的网站终于能正常打开了,但是很快就发现了新的问题,在打开WCF服务中的svc文件时报错: HTTP 错误 404.17 - Not Found请求的内容似乎是脚本, ...
- Linux | Vim使用
Linux vi/vim 所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在. 但是目前我们使用比较多的是 vim 编辑器. vim 具有程序编辑的能力,可以主 ...
- OpenJudge计算概论-整数的个数
/*========================================================== 整数的个数 总时间限制: 1000ms 内存限制: 65536kB 描述 给定 ...
- nginx里面的location 规则匹配
nginx location语法 ~ # 区分大小写的正则匹配 location ~ \.(gif|jpg|png|js|css)$ { #规则D } ~* # 不区分大小写的正则匹配(和~的功能相同 ...
- C# 多线程Thread.IsBackground=True的作用
C#中多线程的线程加.IsBackground = true与不加有什么区别? 按照MSDN上讲:“获取或设置一个值,该值指示某个线程是否为后台线程.” 其实这个解释并不到位,至少应该解释一下后台线程 ...