烧脑!CMU、北大等合著论文真的找到了神经网络的全局最优解
烧脑!CMU、北大等合著论文真的找到了神经网络的全局最优解

选自arXiv,作者:Simon S. Du、Jason D. Lee、Haochuan Li、Liwei Wang、Xiyu Zhai,机器之心编译,参与:思源、王淑婷、张倩。
一直以来,我们都不知道为什么深度神经网络的损失能降到零,降到零不代表着全局最优了么?这不是和一般 SGD 找到的都是局部极小点相矛盾么?最近 CMU、北大和 MIT 的研究者分析了深层全连接网络和残差网络,并表示使用梯度下降训练过参数化的深度神经网络真的能找到全局最优解。
用一阶方法训练的神经网络已经对很多应用产生了显著影响,但其理论特性却依然是个谜。一个经验观察是,即使优化目标函数是非凸和非平滑的,随机初始化的一阶方法(如随机梯度下降)仍然可以找到全局最小值(训练损失接近为零),这是训练中的第一个神秘现象。令人惊讶的是,这个特性与标签无关。在 Zhang 等人的论文 [2016] 中,作者用随机生成的标签取代了真正的标签,但仍发现随机初始化的一阶方法总能达到零训练损失。
人们普遍认为过参数化是导致该现象的主要原因,因为神经网络只有具备足够大的容量时才能拟合所有训练数据。实际上,很多神经网络架构都高度过参数化。例如,宽残差网络(Wide Residual Network)的参数量是训练数据的 100 倍。
训练深度神经网络的第二个神秘现象是「更深的网络更难训练。」为了解决这个问题,何恺明等人在 2006 年提出了深度残差网络(ResNet)架构,用随机梯度下降方法来训练显著具有更多层数的神经网络。理论上来说,Hardt 和 Ma [2016] 表明,线性网络中的残差连接可以阻止梯度消失为零,但使用非线性激活函数的神经网络还无法利用残差连接的优势。
在本文中,作者将揭开这两个神秘现象的面纱。具体而言,作者们从理论上分析了损失函数在梯度下降上的收敛情况,即采用全连接网络和残差网络架构下的损失函数收敛情况。作者关注根据欧式距离定义的损失函数,并假设激活函数是 Lipschitz 和平滑的。这种假设适用于很多激活函数,包括 soft-plus。本文贡献如下:
首先考虑全连接前馈网络。作者表明,如果层级的神经元数量
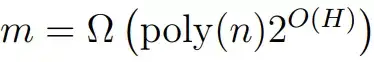
,则随机初始化的梯度下降会以线性速率收敛到零训练损失。
接下来考虑 ResNet 架构。作者表明,只要中间层的宽度 m = Ω (poly(n, H)),则随机初始化的梯度下降会以线性速率收敛到零训练损失。与第一个结果相比,ResNet 对网络层数的依赖呈指数级上升。该理论阐明了利用残差连接的优势。
最后,作者利用同样的技术来分析卷积 ResNet。作者表明,如果 m = poly(n, p, H),其中 p 是图像块数量,则随机初始化的梯度下降会达到零训练损失。
本文的证明是基于以前关于双层神经网络梯度下降研究中的两个重要概念。第一个是 Du 等人 [2018b] 提出的概念,本文作者分析了神经网络预测的动力学特征,即其收敛性由格拉姆矩阵(Gram matrix)的最小特征值决定。为了降低最小特征值的下界,从初始化开始限制每个权重矩阵的距离就足够了。其次,作者利用了 Li 和 Liang [2018] 的观察结果,即如果神经网络过参数化,则每个权重矩阵接近其初始化。与前两个研究不同,本文在分析深度神经网络时,需要构建更多深度神经网络的架构属性和新技术。在本文中,我们主要介绍了 ResNet 的分析结果,更详细的证明展示在原论文中的 29 页附录中。
论文:Gradient Descent Finds Global Minima of Deep Neural Networks

论文地址:https://arxiv.org/pdf/1811.03804.pdf
摘要:在训练深度神经网络时,即使目标函数是非凸的,梯度下降法也能找到全局最小值。本文证明了对于具有残差连接的深度超参数神经网络(ResNet),梯度下降可以在多项式时间内实现零训练损失。我们的分析依赖于神经网络架构引入的格拉姆矩阵的多项式结构。这种结构帮助我们证明格拉姆矩阵在训练过程中的稳定性,而且这种稳定性意味着梯度下降算法的全局最优性。我们的边界也揭示了使用 ResNet 优于全连接前馈架构的优点;对于前馈网络,我们的边界要求每层神经元的数量随深度进行指数缩放,而对于 ResNet,边界只要求每层神经元的数量随深度进行多项式缩放。我们还进一步将自己的分析扩展到深度残差卷积神经网络并得到了类似的收敛结果。
本文结构:第二节正式介绍了问题背景;第三节给出了在深度全连接神经网络上得到的主要结果;第四节给出了在 ResNet 上得到的主要结果;第五节给出了在卷积 ResNet 上得到的主要结果;第六节为以上三种架构提供了一个统一的证明策略。第 7 节为总结,证明见附录。
在论文的后面的章节中,大部分都在描述假设与推理。尤其在后面 29 页的附录中,作者给出了各推理的完整的证明。如果读者自信数学底子比较硬朗的话,可以查阅原论文了解详细推导过程,本文后面只简要介绍了 ResNet 的分析结果。
ResNet 的主要分析结果
在这一章节中,作者主要会考虑使用梯度下降训练 ResNet 的收敛性,并关注到底需要多大程度的过参数化才能确保梯度下降收敛到全局最优解。当然在这之前需要明确 ResNet 的形式化定义是什么样的。在这篇论文中,作者们主要分析了不同神经网络的经验风险最小化问题,其中损失函数由一般的欧式距离定义:
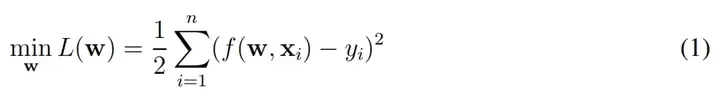
这个式子很容易理解,w 是神经网络所有的权重,x 为输入样本(如图像)、y 为样本的对应标注。在实践中,f(w, x_i) 表示的就是一个完整的残差网络(ResNet),我们希望利用梯度下降一步步调整 ResNet 中的权重 w,进而获得经过训练的 ResNet。从形式化上来说,ResNet 或 f(w, x_i) 函数可以表示为如下方程式:
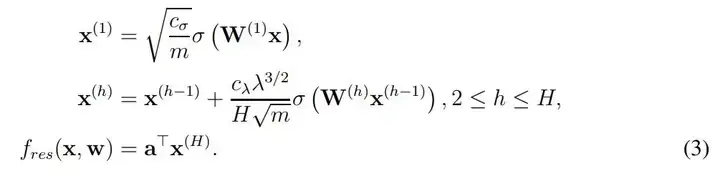
其中 x^(1) 表示输入图像 x 经第一个卷积层得出的特征图(feature map),c_σ为初始化阶段中归一化输入的缩放因子,这里并没有详细展示 c_σ的表达式,详情可查看原论文。此外,σ表示一般的激活函数,且作者假设算出来的中间层(x)都是方阵。在 x^(h) 中,作者形式化定义了残差第 h 个残差模块的输出,它会通过残差连接将 h-1 层的输出加上当前层的输出。x^(h) 后面σ左边比较复杂的表达式展示了这一层级的缩放因子,它们具体是什么可以查阅原论文。
最后的 f_res(x, w) 则表示了残差网络的最终表达式,即最后一个残差模块的输出做一个简单的反射变换。因此为了分析 ResNet 的收敛情况,作者定义了总体格莱姆矩阵,即对于所有 (i, j) ∈ [n] × [n],我们有:
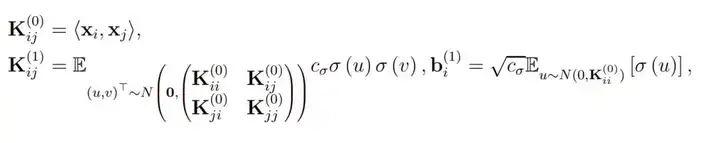
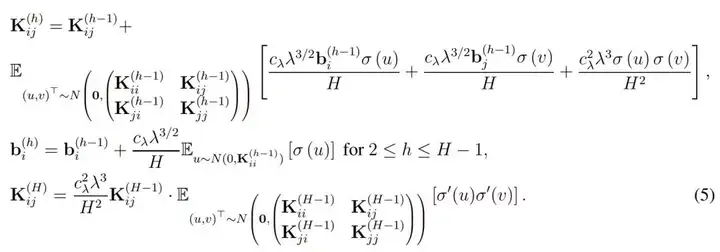
直观上而言,K^(h) 表示了在经过复合 h 次核函数后所得到的格莱姆矩阵(Gram matrix),其中核函数都是由激活函数σ所定义。此外,当权重矩阵的长和宽 m 趋向于无穷大时,它们会渐进格莱姆矩阵。因此作者做了以下假设以决定收敛率和过参数化总量:
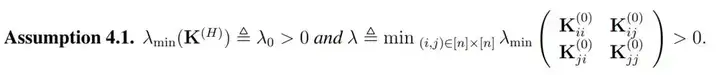
注意 λ 在这里仅依赖于 K^(0),因此它的定义与全连接网络中的不太一样。一般而言,除非两个数据点是平行的,否则λ通常都是正数。在有了这个假设以后,作者给出了他们对 ResNet 的主要定理:

与全连接网络中得出的定理不同,定理 4.1 完全是多项式形式的,因为神经元数量和收敛率都是关于 n 和 H 的多项式,所以作者根据分析结果表明经典多层全连接架构和 ResNet 架构是有显著差别的。作者在这里并没有使用任何指数因子,其主要原因是残差连接块使得整个架构在初始化阶段和训练阶段都更加稳定。
以上只是 ResNet 分析所获得的结果,更多分析和推导过程都在原论文中。作者最后表示过参数化网络上实现的梯度下降能获得零训练损失,且证明的关键技术是表明格莱姆矩阵在过参数化的情况下会越来越稳定,因此下降的每一步都会以几何速率减少损失,并最终收敛到全局最优解。
烧脑!CMU、北大等合著论文真的找到了神经网络的全局最优解的更多相关文章
- 【Machine Translation】CMU的NMT教程论文:最全面的神经机器翻译学习教程
这是一篇CMU发的神经机器翻译教程论文,很全很详细,适合新手阅读,即使没有什么MT.DNN.RNN的基础知识. 另外它还配套了CMU自己的一个框架DyNet的练习. 全文共9章,从统计语言模型到DNN ...
- paper 53 :深度学习(转载)
转载来源:http://blog.csdn.net/fengbingchun/article/details/50087005 这篇文章主要是为了对深度学习(DeepLearning)有个初步了解,算 ...
- 深度视觉盛宴——CVPR 2016
小编按: 计算机视觉和模式识别领域顶级会议CVPR 2016于六月末在拉斯维加斯举行.微软亚洲研究院在此次大会上共有多达15篇论文入选,这背后也少不了微软亚洲研究院的实习生的贡献.大会结束之后,小编第 ...
- 【课程学习】课程2:十行代码高效完成深度学习POC
本文用户记录黄埔学院学习的心得,并补充一些内容. 课程2:十行代码高效完成深度学习POC,主讲人为百度深度学习技术平台部:陈泽裕老师. 因为我是CV方向的,所以内容会往CV方向调整一下,有所筛检. 课 ...
- 2048-AI程序算法分析
转自:CodingLabs 针对目前火爆的2048游戏,有人实现了一个AI程序,可以以较大概率(高于90%)赢得游戏,并且作者在stackoverflow上简要介绍了AI的算法框架和实现思路.但是这个 ...
- 论文阅读笔记三十:One pixel attack for fooling deep neural networks(CVPR2017)
论文源址:https://arxiv.org/abs/1710.08864 tensorflow代码: https://github.com/Hyperparticle/one-pixel-attac ...
- 论文笔记:2018 PRCV 顶会顶刊墙展
Global Gated Mixture of Second-order Pooling for Imporving Deep Convolutional Neural Network(2018 NI ...
- 论文阅读之Joint cell segmentation and tracking using cell proposals
论文提出了一种联合细胞分割和跟踪方法,利用细胞segmentation proposals创建有向无环图,然后在该图中迭代地找到最短路径,为单个细胞提供分割,跟踪和事件. 3. PROPOSAL GE ...
- ACM TOMM 2017最佳论文:让AI接手繁杂专业的图文排版设计工作
编者按:你是否曾经为如何创作和编辑一篇图文并茂.排版精美的文章而烦恼?或是为缺乏艺术灵感和设计思路而痛苦?AI技术能否在艺术设计中帮助到我们?今天我们为大家介绍的这篇论文,“Automatic Gen ...
随机推荐
- pgpool 的配置文件详解
listen_addresses = 'localhost' # Host name or IP address to listen on: # '*' for all, '' for no TCP/ ...
- vue设置公共常量
Global.vue <template> </template> <script type="text/javascript"> const ...
- udf提权小结
00x1 首先判断mysql版本, mysql版本 < 5.2 , UDF导出到系统目录c:/windows/system32/ mysql版本 > 5.2 ,UDF导出到安装路径MySQ ...
- [Java复习] 分布式锁 Zookeeper Redis
一般实现分布式锁都有哪些方式? 使用 Redis 如何设计分布式锁?使用 Zookeeper 来设计分布式锁可以吗? 这两种分布式锁的实现方式哪种效率比较高? 1. Zookeeper 都有哪些使用场 ...
- vue+php接口
php: <?php header('Access-Control-Allow-Origin:*'); $date = $_POST['data'];$cars=array("Volv ...
- 解决一个 MySQL 服务器进程 CPU 占用 100%解决一个 MySQL 服务器进程 CPU 占用 100%的技术笔记》[转]
转载地址:http://bbs.chinaunix.net/archiver/tid-1823500.html 解决一个 MySQL 服务器进程 CPU 占用 100%解决一个 MySQL 服务器进程 ...
- (一)Rational Rose 2007 下载安装
因为有画UML图的需求,所以得在电脑上安装Rational Rose.开始准备安装Rational Rose 2003,但是破解过程过于繁琐而且似乎一直遇到各种问题,就决定安装Rational Ros ...
- (十二)会话跟踪技术之servlet通信(forward和include)
一.servlet通信方法 二.具体应用 scopeServlet.java protected void doPost(HttpServletRequest request, HttpServlet ...
- laravel输出HTML内容
blade模板引擎中的{{ $xxx }}表达式的返回值将被自动传递给 PHP 的 htmlentities 函数进行处理,以防止 XSS 攻击. 如果需要展示未转义的数据,可以使用{!! $xxx ...
- Win10使用mysqldump导出csv文件及期间遇到的问题
作为测试,我们这里使用了名为testdb的数据库中的名为test_table的表,首先我们使用如下SQL来查看其中有何数据: select * from testdb.test_table 数据如下: ...