05_Hive分区总结
2.1.创建分区表并将本地文件的数据加载到分区表:
使用下面的命令来创建一个带分区的表

通过partitioned by(country string)关键字声明该表是分区表,且分区字段不能为create table时存在的字段。此
时只能说指定了这个表会分区,但是具体数据有哪些分区则会在导入数据时产生
使用下面的命令来指定具体导入到哪个分区:

查询该分区表:select * from t_part;
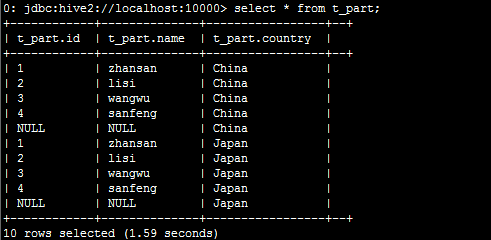
此时分区字段已经变成一个伪字段了。如果要分区查询,可以使用Where或者Group by来进行限定;
2.2.Hive中上传数据:
之前我们直接将数据文件上传到了Hive表所在的数据目录,其实Hive还提供了一个Load命令供我们将数据进行上传
语法结构:Load
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
参数说明:
Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,列如:hdfs://namenode:9000/user/hive/project/data1
LOCAL关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath
如果没有指定 LOCAL关键字,则根据inpath中的uri查找文件
OVERWRITE 关键字
若使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
2.3.Hive修改表_增加/删除分区:
语法结构
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ]
partition_spec [ LOCATION 'location2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...) ALTER TABLE table_name DROP partition_spec, partition_spec,...
增加分区:alter table t_part add partition (country='American');
删除分区:alter table t_part drop partition (country='American');
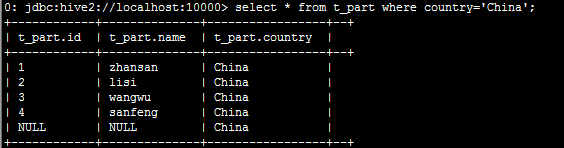
查看分区数据:
查看分区:show partitions t_part;

总结:分区的目的就是提高查询效率,查询分区数据的方式就是指定分区名,指定分区名之后就不再全表扫描,直接从指
定分区(如name=jack的分区)中查询,从hdfs的角度看就是从相应的文件系统中(如country=‘China’文件夹下)去查找
特定的数据
05_Hive分区总结的更多相关文章
- SQL Server表分区
什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在 ...
- win7安装时,避免产生100m系统保留分区的办法
在通过光盘或者U盘安装Win7操作系统时,在对新硬盘进行分区时,会自动产生100m的系统保留分区.对于有洁癖的人来说,这个不可见又删不掉的分区是个苦恼.下面介绍通过diskpart消灭保留分区的办法: ...
- Partition:增加分区
在关系型 DB中,分区表经常使用DateKey(int 数据类型)作为Partition Column,每个月的数据填充到同一个Partition中,由于在Fore-End呈现的报表大多数是基于Mon ...
- Partition2:对表分区
在SQL Server中,普通表可以转化为分区表,而分区表不能转化为普通表,普通表转化成分区表的过程是不可逆的,将普通表转化为分区表的方法是: 在分区架构(Partition Scheme)上创建聚集 ...
- Partition:分区切换(Switch)
在SQL Server中,对超级大表做数据归档,使用select和delete命令是十分耗费CPU时间和Disk空间的,SQL Server必须记录相应数量的事务日志,而使用switch操作归档分区表 ...
- WebGIS项目中利用mysql控制点库进行千万条数据坐标转换时的分表分区优化方案
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 项目中有1000万条历史案卷,为某地方坐标系数据,我们的真实 ...
- VMware下对虚拟机Ubuntu14系统所在分区sda1进行磁盘扩容
VMware下对虚拟机Ubuntu14系统所在分区sda1进行磁盘扩容 一般来说,在对虚拟机里的Ubuntu下的磁盘进行扩容时,都是添加新的分区,而并不是对其系统所在分区进行扩容,如在此链接中http ...
- SQL Server 批量主分区备份(Multiple Jobs)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 方案一(Solution One) 方案二(Solution Two) ...
- SQL Server 批量主分区备份(One Job)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 实现代码(SQL Codes) 主分区完整.差异还原(Primary B ...
随机推荐
- 学习UML图和时序图,以及IDEA种查看类之间关系
1.类之间的关系:(6种) 关系 表示 图示 解释 表明的结构和语义 泛化关系 带空心箭头的直线 A继承自B(B指代非抽象类) 继承结构 实现关系 带空心箭头的虚线 小汽车继承车(B指代抽象类) 继承 ...
- 【log4j】的学习和理解 + 打印所有 SQL
log4j 1.2 学习和理解 + 打印所有 SQL 一.基本资料 官方文档:http://logging.apache.org/log4j/1.2/manual.html(理解基本概念和其他) lo ...
- [学习笔记] 在Eclipse中导出可以直接运行的jar,依赖的jar中的类解压后放在运行jar中
前文: [学习笔记] 在Eclipse中导出可以直接运行的jar,依赖的jar打在jar包中 使用7z打开压缩包,查看所有依赖的jar都被解压以包名及class的方式存储在了运行jar中,此时jar的 ...
- docker入门2--生命周期
容器的概念: 一句话概括容器:容器就是将软件打包成标准化单元,以用于开发.交付和部署. 容器镜像是轻量的.可执行的独立软件包 ,包含软件运行所需的所有内容:代码.运行时环境.系统工具.系统库和设置 ...
- Kettle无法打开文件资源库
问题: Kettle无法打开文件资源库. 问题描述: 新建文件资源库之后,资源库路径中有中文路径.退出kettle之后,再次进去发现没有了右上角的connect按钮了. 原因: kettle的repo ...
- 【AtCoder】ARC067
ARC067 C - Factors of Factorial 这个直接套公式就是,先求出来每个质因数的指数幂,然后约数个数就是 \((1 + e_{1})(1 + e_{2})(1 + e_{3}) ...
- 剑指offer37:统计一个数字在排序数组中出现的次数
1 题目描述 统计一个数字在排序数组中出现的次数. 2 思路和方法 (1)查找有序数组,首先考虑使用二分查找,使时间复杂度为O(log n).更改二分查找的条件,不断缩小区间,直到区间头和区间尾均为k ...
- global和nonlocal的区别
global可以在任何地方修饰变量,而且被global修饰的变量直接被标识为全局变量,对该变量修改会影响全局变量的值,但不影响函数中未被global修饰的同名变量(依然是局部变量),nonlocal只 ...
- 移动端APP测试概要
APP测试点总结(全面) 一.功能性测试: ——根据产品需求文档编写测试用例. ——软件设计文档编写用例. 注意:就是根据产品需求文档编写测试用例而进行测试. 二.兼容性测试: ——android版本 ...
- Java 抽象类详解
在<Java中的抽象方法和接口>中,介绍了抽象方法与接口,以及做了简单的比较. 这里我想详细探讨下抽象类. 一.抽象类的定义 被关键字“abstract”修饰的类,为抽象类.(而且,abx ...