《浏览器工作原理与实践》<05>渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?
在上一篇文章中我们介绍了导航相关的流程,那导航被提交后又会怎么样呢?就进入了渲染阶段。这个阶段很重要,了解其相关流程能让你“看透”页面是如何工作的,有了这些知识,你可以解决一系列相关的问题,比如能熟练使用开发者工具,因为能够理解开发者工具里面大部分项目的含义,能优化页面卡顿问题,使用 JavaScript 优化动画流程,通过优化样式表来防止强制同步布局,等等。
既然它的功能这么强大,那么今天,我们就来好好聊聊渲染流程。
为了能更好地理解下文,你可以先结合下图快速抓住 HTML、CSS 和 JavaScript 的含义:
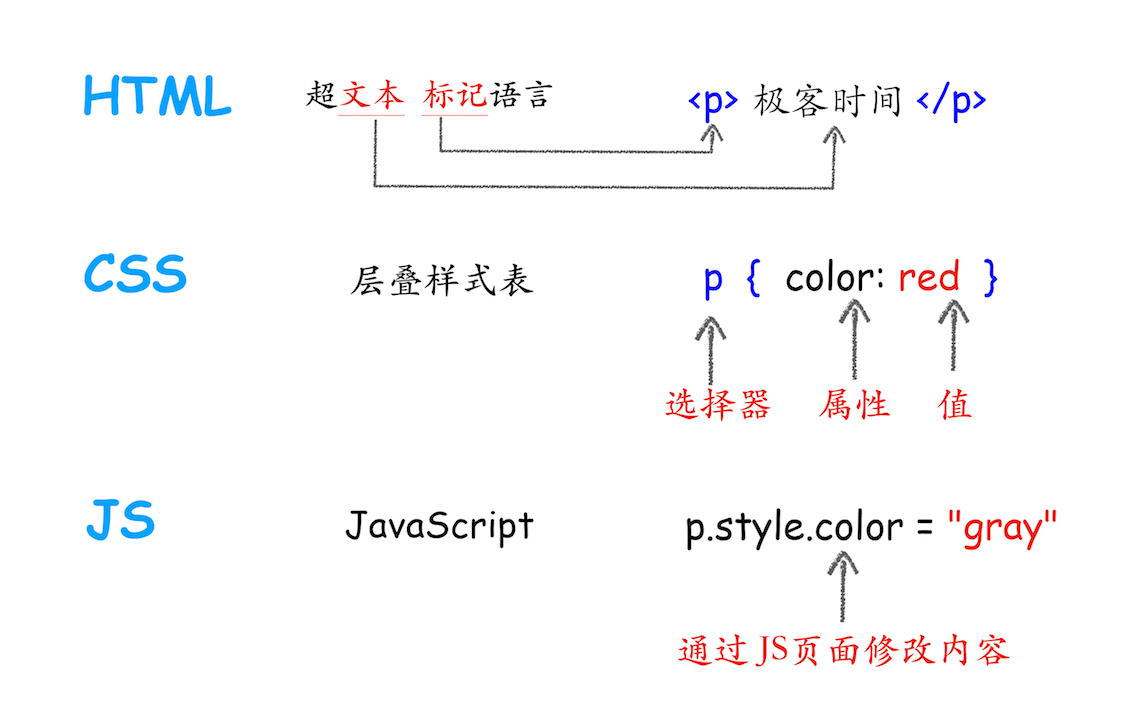
从上图可以看出,HTML 的内容是由标记和文本组成。标记也称为标签,每个标签都有它自己的语意,浏览器会根据标签的语意来正确展示 HTML 内容。比如上面的标签是告诉浏览器在这里的内容需要创建一个新段落,中间的文本就是段落中需要显示的内容。
如果需要改变 HTML 的字体颜色、大小等信息,就需要用到 CSS。CSS 又称为层叠样式表,是由选择器和属性组成,比如图中的 p 选择器,它会把 HTML 里面标签的内容选择出来,然后再把选择器的属性值应用到标签内容上。选择器里面有个 color 属性,它的值是 red,这是告诉渲染引擎把标签的内容显示为红色。
至于 JavaScript(简称为 JS),使用它可以使网页的内容“动”起来,比如上图中,可以通过 JavaScript 来修改 CSS 样式值,从而达到修改文本颜色的目的。
搞清楚 HTML、CSS 和 JavaScript 的含义后,那么接下来我们就正式开始分析渲染模块了。由于渲染机制过于复杂,所以渲染模块在执行过程中会被划分为很多子阶段,输入的 HTML 经过这些子阶段,最后输出像素。我们把这样的一个处理流程叫做渲染流水线,其大致流程如下图所示:
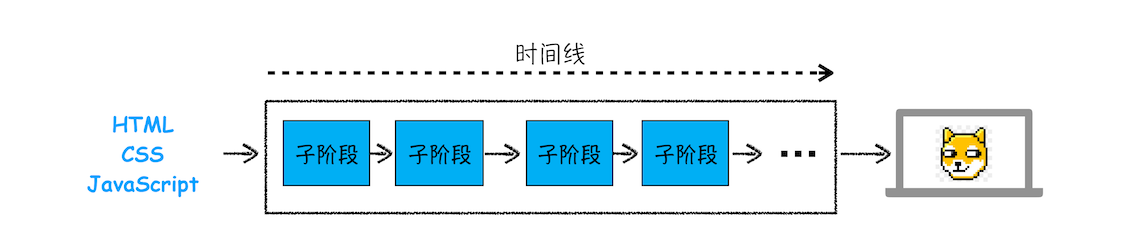
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、绘制、分块、光栅化和合成。内容比较多,接下来会详细讲解这各个子阶段。在介绍每个阶段的过程中,你应该重点关注以下三点内容:
1.开始每个子阶段都有其输入的内容;
2.然后每个子阶段有其处理过程;
3.最终每个子阶段会生成输出内容。
构建 DOM树
为什么要构建 DOM 树呢?这是因为浏览器无法直接理解和使用 HTML,所以需要将 HTML 转换为浏览器能够理解的结构——DOM 树。
这里我们还需要简单介绍下什么是树结构,为了更直观地理解,你可以参考下面我画的几个树结构:

从图中可以看出,树这种结构非常像我们现实生活中的“树”,其中每个点我们称为节点,相连的节点称为父子节点。树结构在浏览器中的应用还是比较多的,比如下面我们要介绍的渲染流程,就在频繁地使用树结构。接下来咱们还是言归正传,来看看 DOM 树的构建过程,你可以参考下图:
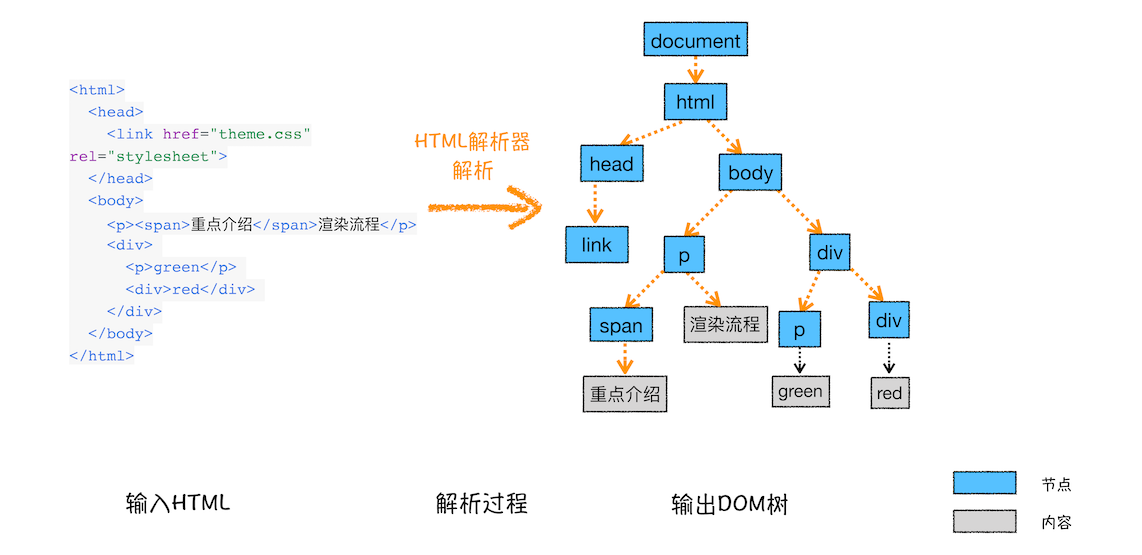
从图中可以看出,构建 DOM 树的输入内容是一个非常简单的 HTML 文件,然后经由 HTML 解析器解析,最终输出树状结构的 DOM。
为了更加直观地理解 DOM 树,你可以打开 Chrome 的“开发者工具”,选择“Console”标签来打开控制台,然后在控制台里面输入“document”后回车,这样你就能看到一个完整的 DOM 树结构,如下图所示:
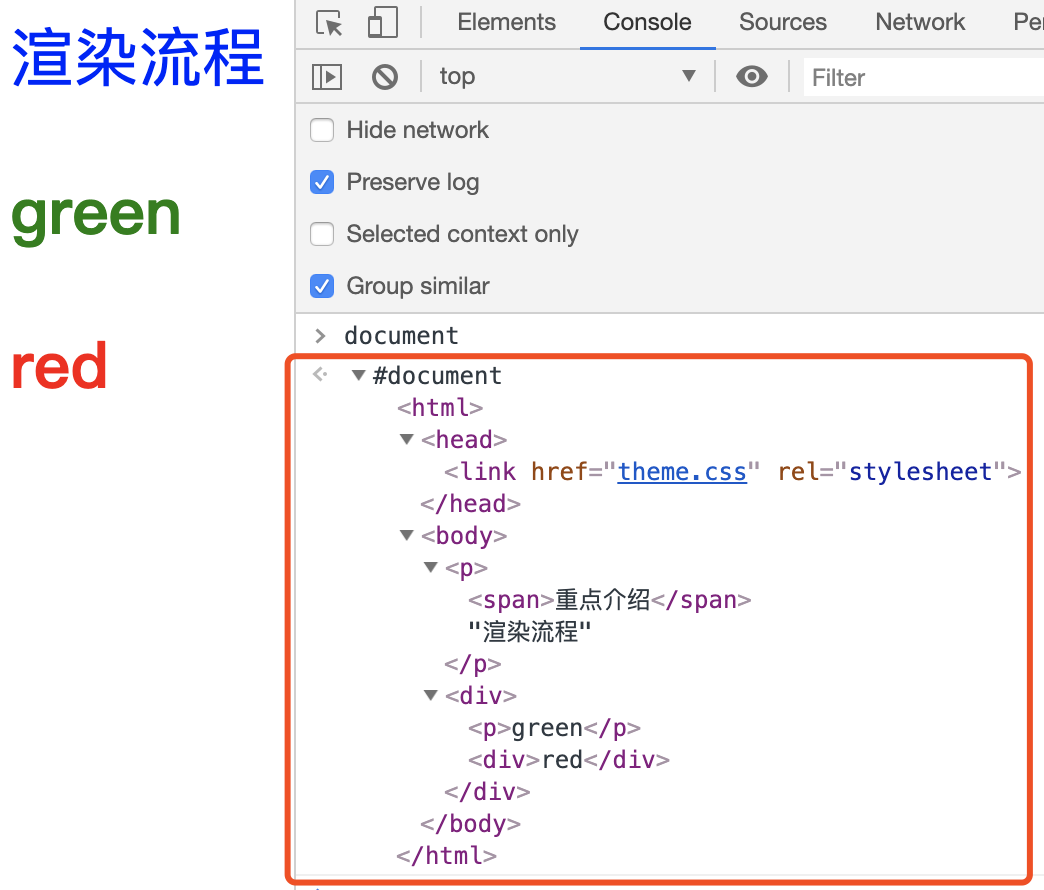
现在我们已经看到 DOM 树了,但是 DOM 节点的样式我们依然不知道,要让 DOM 节点拥有正确的样式,这就需要样式计算了。
样式计算(Recalculate Style)
样式计算的目的是为了计算出 DOM 节点中每个元素的具体样式,这个阶段大体可分为三步来完成。
1. 把 CSS 转换为浏览器能够理解的结构
那 CSS 样式的来源主要有哪些呢?你可以先参考下图:
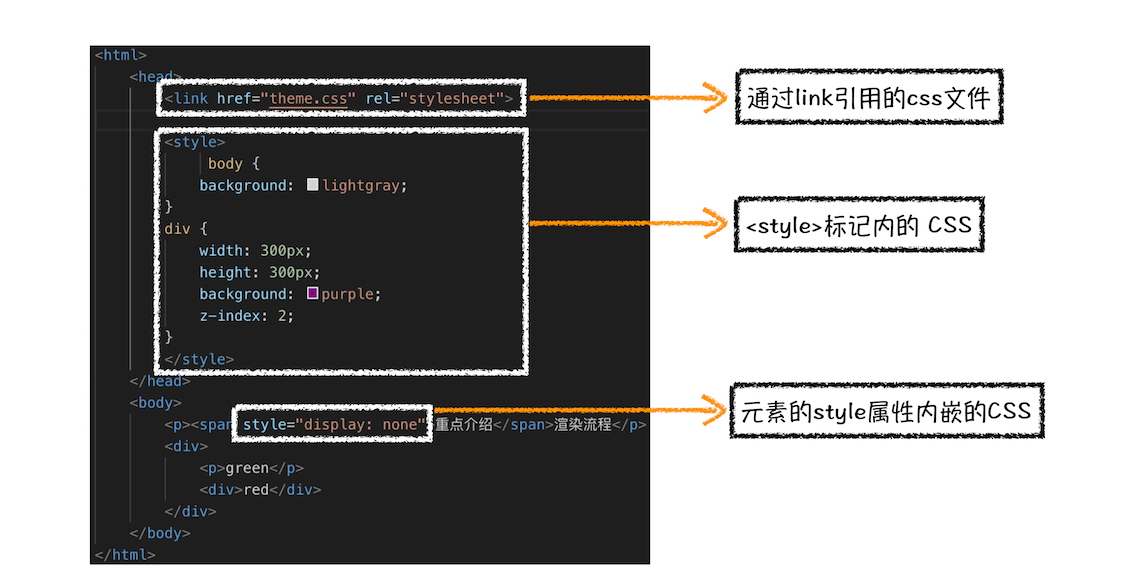
从图中可以看出,CSS 样式来源主要有三种:
1. 通过 link 引用的外部 CSS 文件
2. <style>标记内的css
3. 元素的 style 属性内嵌的 CSS
和 HTML 文件一样,浏览器也是无法直接理解这些纯文本的 CSS 样式,所以当渲染引擎接收到 CSS 文本时,会执行一个转换操作,将 CSS 文本转换为浏览器可以理解的结构——styleSheets。
为了加深理解,你可以在 Chrome 控制台中查看其结构,只需要在控制台中输入 document.styleSheets,然后就看到如下图所示的结构:

从图中可以看出,这个样式表包含了很多种样式,已经把那三种来源的样式都包含进去了。当然样式表的具体结构不是我们今天讨论的重点,你只需要知道渲染引擎会把获取到的 CSS 文本全部转换为 styleSheets 结构中的数据,并且该结构同时具备了查询和修改功能,这会为后面的样式操作提供基础。
2. 转换样式表中的属性值,使其标准化
现在我们已经把现有的 CSS 文本转化为浏览器可以理解的结构了,那么接下来就要对其进行属性值的标准化操作。要理解什么是属性值标准化,你可以看下面这样一段 CSS 文本:
body { font-size: 2em }
p {color:blue;}
span {display: none}
div {font-weight: bold}
div p {color:green;}
div {color:red; }
可以看到上面的 CSS 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。
那标准化后的属性值是什么样子的?
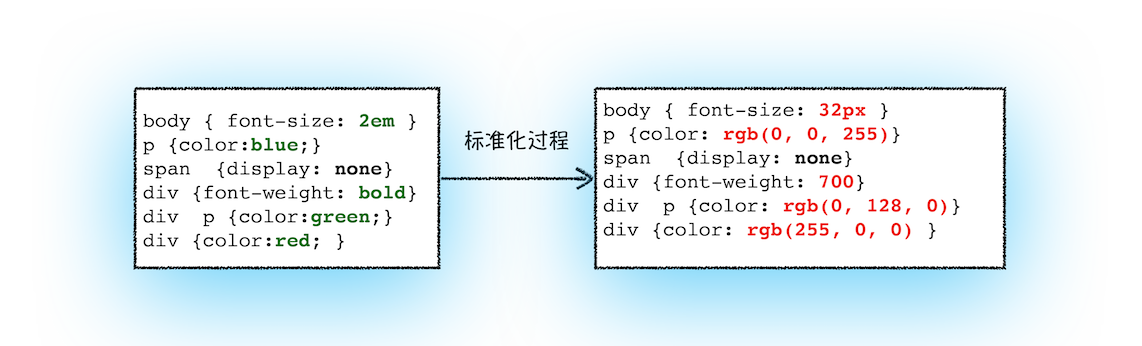
从图中可以看到,2em 被解析成了 32px,red 被解析成了 rgb(255,0,0),bold 被解析成了 700。
3. 计算出 DOM 树中每个节点的具体样式
现在样式的属性已被标准化了,接下来就需要计算 DOM 树中每个节点的样式属性了,如何计算呢?
这就涉及到 CSS 的继承规则和层叠规则了。
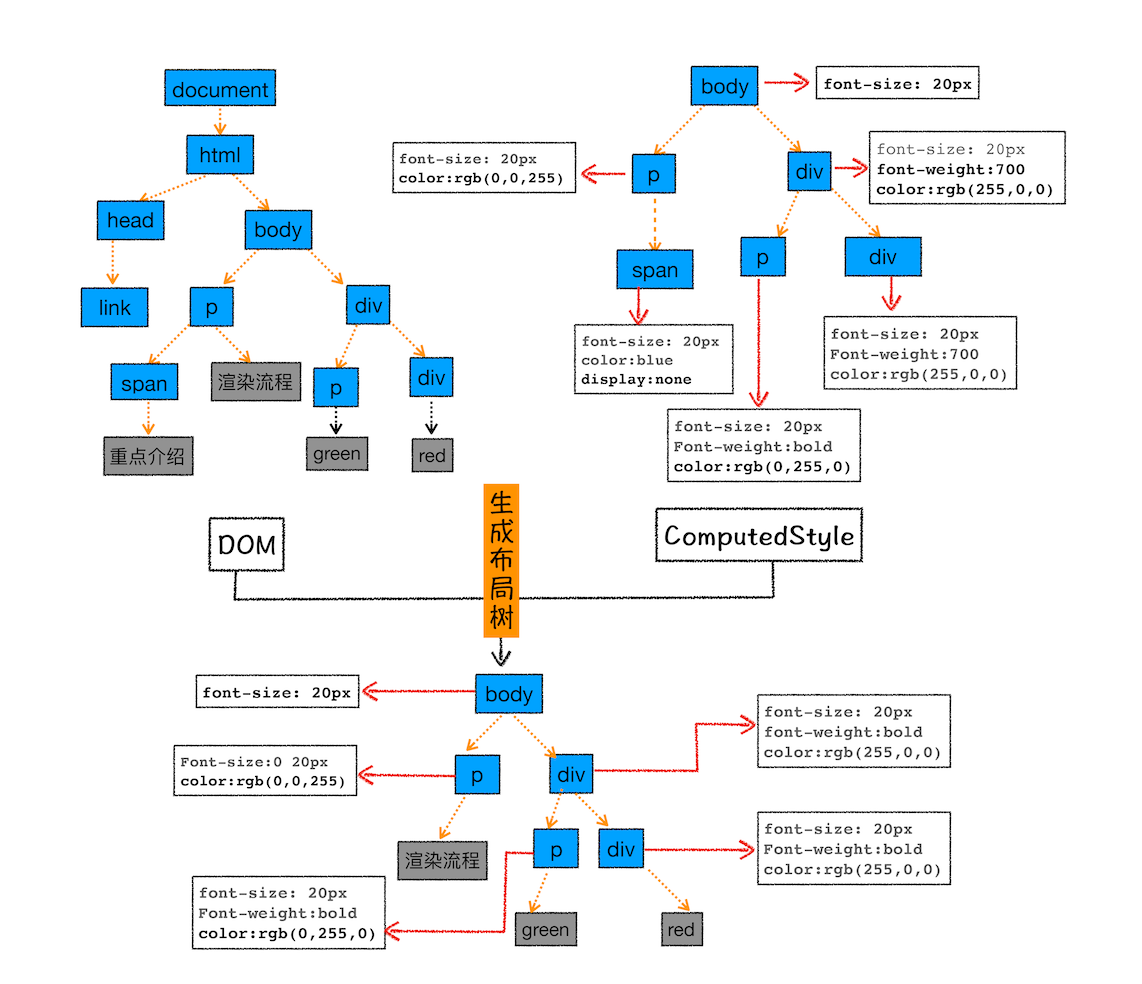
首先是 CSS 继承。CSS 继承就是每个 DOM 节点都包含有父节点的样式。这么说可能有点抽象,我们可以结合具体例子,看下面这样一张样式表是如何应用到 DOM 节点上的。
body { font-size: 20px }
p {color:blue;}
span {display: none}
div {font-weight: bold;color:red}
div p {color:green;}
这张样式表最终应用到 DOM 节点的效果如下图所示:
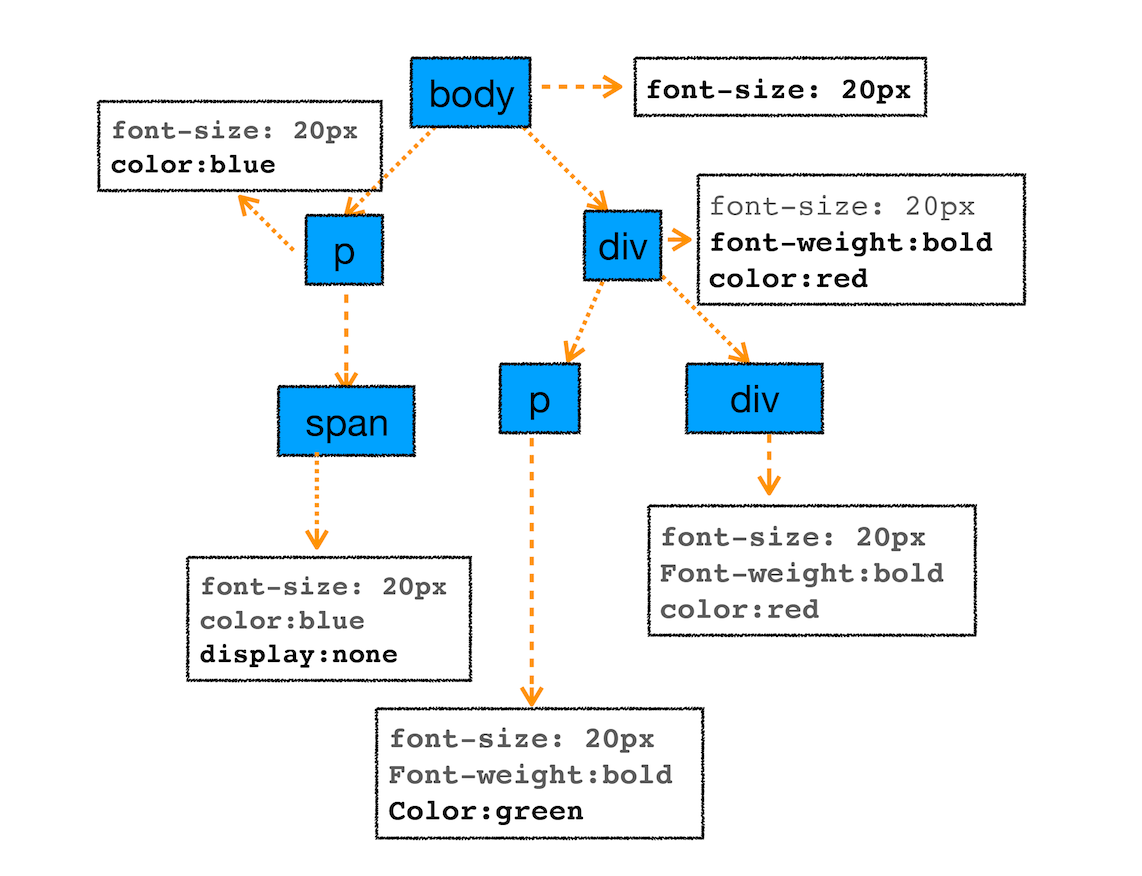
从图中可以看出,所有子节点都继承了父节点样式。比如 body 节点的 font-size 属性是 20,那 body 节点下面的所有节点的 font-size 都等于 20。
为了加深你对 CSS 继承的理解,你可以打开 Chrome 的“开发者工具”,选择第一个“element”标签,再选择“style”子标签,你会看到如下界面:
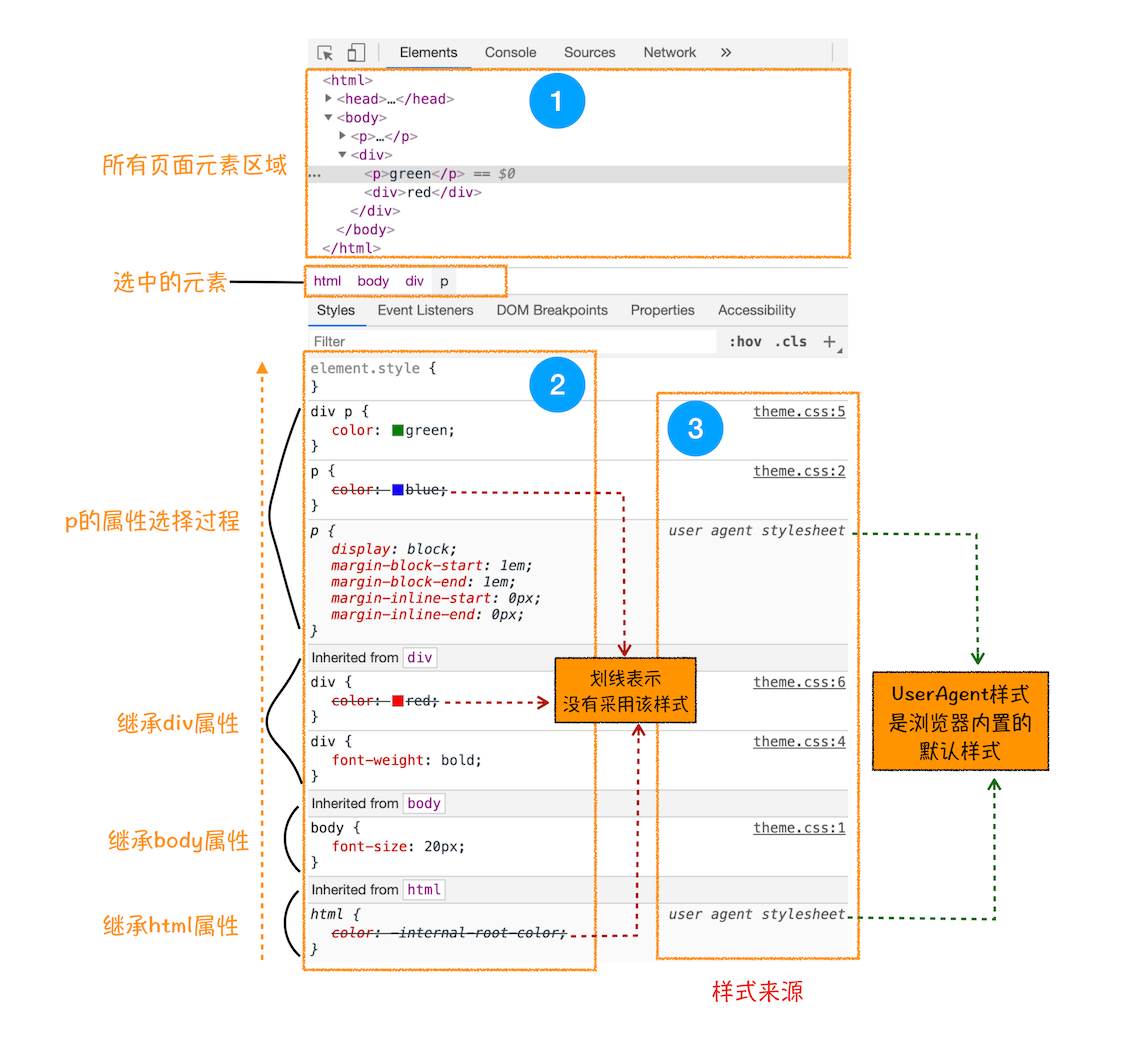
这个界面展示的信息很丰富,大致可描述为如下。
1.首先,可以选择要查看的元素的样式(位于图中的区域 2 中),在图中的第 1 个区域中点击对应的元素元素,就可以了下面的区域查看该元素的样式了。比如这里我们选择的元素是
标签,位于 html.body.div. 这个路径下面。
2.其次,可以从样式来源(位于图中的区域 3 中)中查看样式的具体来源信息,看看是来源于样式文件,还是来源于 UserAgent 样式表。这里需要特别提下 UserAgent 样式,它是浏览器提供的一组默认样式,如果你不提供任何样式,默认使用的就是 UserAgent 样式。
3.最后,可以通过区域 2 和区域 3 来查看样式继承的具体过程。
以上就是 CSS 继承的一些特性,样式计算过程中,会根据 DOM 节点的继承关系来合理计算节点样式。
样式计算过程中的第二个规则是样式层叠。层叠是 CSS 的一个基本特征,它是一个定义了如何合并来自多个源的属性值的算法。它在 CSS 处于核心地位,CSS 的全称“层叠样式表”正是强调了这一点。
总之,样式计算阶段的目的是为了计算出 DOM 节点中每个元素的具体样式,在计算过程中需要遵守 CSS 的继承和层叠两个规则。
这个阶段最终输出的内容是每个 DOM 节点的样式,并被保存在 ComputedStyle 的结构内。如果你想了解每个 DOM 元素最终的计算样式,可以打开 Chrome 的“开发者工具”,选择第一个“element”标签,然后再选择“Computed”子标签,如下图所示:
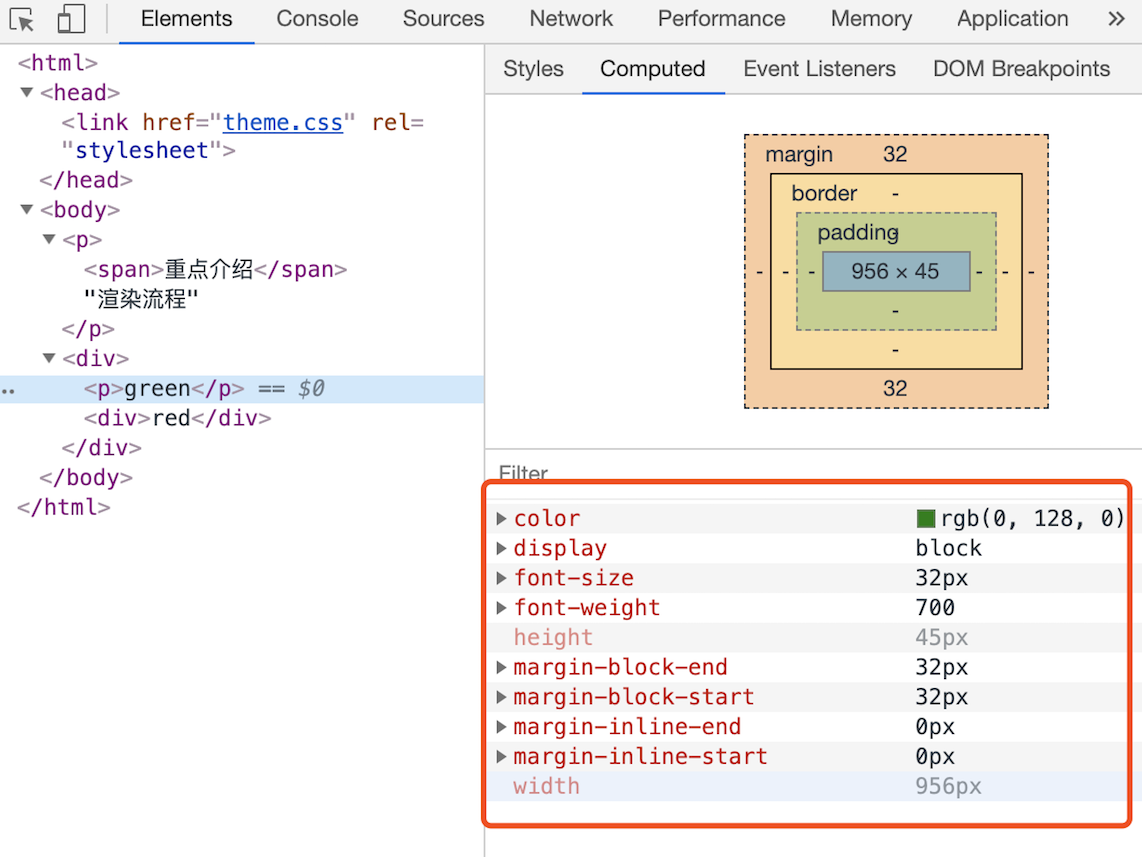
上图红色方框中显示了 html.body.div.p 标签的 ComputedStyle 的值。你想要查看哪个元素,点击左边对应的标签就可以了。
布局阶段
现在,我们有 DOM 树和 DOM 树中元素的样式,但这还不足以显示页面,因为我们还不知道 DOM 元素的几何位置信息。那么接下来就需要计算出 DOM 树中可见元素的几何位置,我们把这个计算过程叫做布局。Chrome 在布局阶段需要完成两个任务:创建布局树和布局计算。
1. 创建布局树
你可能注意到了 DOM 树还含有很多不可见的元素,比如 head 标签,还有使用了 display:none 属性的元素。所以在显示之前,我们还要额外地构建一棵只包含可见元素布局树。我们结合下图来看看布局树的构造过程:
我们结合下图来看看布局树的构造过程:
从上图可以看出,DOM 树中所有不可见的节点都没有包含到布局树中。为了构建布局树,浏览器大体上完成了下面这些工作:
遍历 DOM 树中的所有可见节点,并把这些节点加到布局中;
而不可见的节点会被布局树忽略掉,如 head 标签下面的全部内容,再比如 body.p.span 这个元素,因为它的属性包含 dispaly:none,所以这个元素也没有被包进布局树。
2. 布局计算
现在我们有了一棵完整的布局树。那么接下来,就要计算布局树节点的坐标位置了。布局的计算过程非常复杂,我们这里先跳过不讲,等到后面章节中我再做详细的介绍。
在执行布局操作的时候,会把布局运算的结果重新写回布局树中,所以布局树既是输入内容也是输出内容,这是布局阶段一个不合理的地方,因为在布局阶段并没有清晰地将输入内容和输出内容区分开来。针对这个问题,Chrome 团队正在重构布局代码,下一代布局系统叫 LayoutNG,试图更清晰地分离输入和输出,从而让新设计的布局算法更加简单。
总结
好了,今天正文就到这里,我画了下面这张比较完整的渲染流水线,你可以结合这张图来回顾下今天的内容。
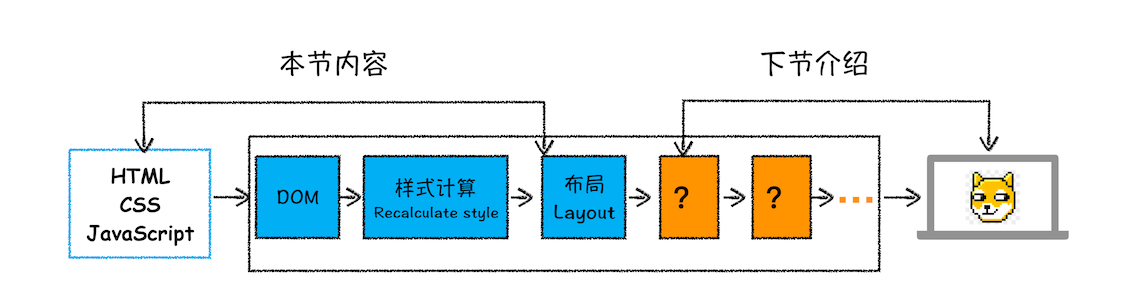
从图中可以看出,本节内容我们介绍了渲染流程的前三个阶段:DOM 生成、样式计算和布局。
要点可大致总结为如下:
1. 浏览器不能直接理解 HTML 数据,所以第一步需要将其转换为浏览器能够理解的 DOM 树结构;
2. 生成 DOM 树后,还需要根据 CSS 样式表,来计算出 DOM 树所有节点的样式;
3. 最后计算 DOM 元素的布局信息,使其都保存在布局树中。
到这里我们的每个节点都拥有了自己的样式和布局信息,那么后面几个阶段就要利用这些信息去展示页面了,由于篇幅限制,剩下的这些阶段我会在下一篇文章中介绍。
注: 本文出自极客时间(浏览器工作原理与实践),请大家多多支持李兵老师。如有侵权,请及时告知。
《浏览器工作原理与实践》<05>渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?的更多相关文章
- 《浏览器工作原理与实践》<06>渲染流程(下):HTML、CSS和JavaScript,是如何变成页面的?
在上篇文章中,我们介绍了渲染流水线中的 DOM 生成.样式计算和布局三个阶段,那今天我们接着讲解渲染流水线后面的阶段. 这里还是先简单回顾下上节前三个阶段的主要内容:在 HTML 页面内容被提交给渲染 ...
- 《浏览器工作原理与实践》<03>HTTP请求流程:为什么很多站点第二次打开速度会很快?
一个 TCP 连接过程包括了建立连接.传输数据和断开连接三个阶段. 而 HTTP 协议,正是建立在 TCP 连接基础之上的.HTTP 是一种允许浏览器向服务器获取资源的协议,是 Web 的基础,通常由 ...
- 《浏览器工作原理与实践》<04>从输入URL到页面展示,这中间发生了什么?
“在浏览器里,从输入 URL 到页面展示,这中间发生了什么? ”这是一道经典的面试题,能比较全面地考察应聘者知识的掌握程度,其中涉及到了网络.操作系统.Web 等一系列的知识. 在面试应聘者时也必问这 ...
- 《浏览器工作原理与实践》<01>Chrome架构:仅仅打开了1个页面,为什么有4个进程?
无论你是想要设计高性能 Web 应用,还是要优化现有的 Web 应用,你都需要了解浏览器中的网络流程.页面渲染过程,JavaScript 执行流程,以及 Web 安全理论,而这些功能是分散在浏览器的各 ...
- 《浏览器工作原理与实践》 <12>栈空间和堆空间:数据是如何存储的?
对于前端开发者来说,JavaScript 的内存机制是一个不被经常提及的概念 ,因此很容易被忽视.特别是一些非计算机专业的同学,对内存机制可能没有非常清晰的认识,甚至有些同学根本就不知道 JavaSc ...
- 《浏览器工作原理与实践》<11>this:从JavaScript执行上下文的视角讲清楚this
在上篇文章中,我们讲了词法作用域.作用域链以及闭包,接下来我们分析一下这段代码: var bar = { myName:"time.geekbang.com", printName ...
- 《浏览器工作原理与实践》<10>作用域链和闭包 :代码中出现相同的变量,JavaScript引擎是如何选择的?
在上一篇文章中我们讲到了什么是作用域,以及 ES6 是如何通过变量环境和词法环境来同时支持变量提升和块级作用域,在最后我们也提到了如何通过词法环境和变量环境来查找变量,这其中就涉及到作用域链的概念. ...
- 《浏览器工作原理与实践》<09>块级作用域:var缺陷以及为什么要引入let和const?
在前面我们已经讲解了 JavaScript 中变量提升的相关内容,正是由于 JavaScript 存在变量提升这种特性,从而导致了很多与直觉不符的代码,这也是 JavaScript 的一个重要设计缺陷 ...
- 《浏览器工作原理与实践》<08>调用栈:为什么JavaScript代码会出现栈溢出?
在上篇文章中,我们讲到了,当一段代码被执行时,JavaScript 引擎先会对其进行编译,并创建执行上下文.但是并没有明确说明到底什么样的代码才算符合规范. 那么接下来我们就来明确下,哪些情况下代码才 ...
随机推荐
- BSD process name correspondlng to current thread: knernel_task Mac OS version Not yet set
网上查了一大堆,没有一个靠谱的, 百度,以说黑苹果装系统最容易出现这个,这个让我开始怀疑公司给我们的所谓外观的iMac是黑苹果了,因为一直很卡,比上家公司的真黑苹果还卡. 谷歌,有说重置BIOS电池的 ...
- Android 中View的工作原理
Android中的View在Android的知识体系中扮演着重要的角色.简单来说,View就是Android在视觉的体现.我们所展现的页面就是Android提供的GUI库中控件的组合.但是当要求不能满 ...
- SpringBoot: 17.热部署配置(转)
spring为开发者提供了一个名为spring-boot-devtools的模块来使Spring Boot应用支持热部署,提高开发者的开发效率,无需手动重启Spring Boot应用. devtool ...
- python基础----redis模块
数据库 关系型数据 例如mysql,有表还有约束条件等 非关系型 k-v形式 memcache 存在内存中 redis 存在内存 mongodb 数据存在磁盘 import redis #string ...
- 《剑指offer》Q01-12 (牛客10.11)
目录 T1 二维部分有序数组查找 ☆ T2 字符串字符不等长替换 - 从后往前 T3 返回链表的反序 vector T4 重建二叉树 T5 两个栈模拟队列 T6 旋转数组中的最小元素 - 二分或暴力 ...
- POJ 1734:Sightseeing trip
Sightseeing trip Time Limit: 1000MS Memory Limit: 65536K Total Submissions: Accepted: Special Judge ...
- DS博客大作业--树(李天明组)
DS博客大作业--树 大作业博客要求 (10分) 1.树的存储结构说明 .树采用的是链式存储结构. .这段代码中定义了两个结构体.第一个是自定义为Name类型的结构体,里面的成员有字符串str和类型为 ...
- 《MIT 6.828 Homework 2: Shell》解题报告
Homework 2的网站链接:MIT 6.828 Homework 2: shell 题目 下载sh.c文件,在文件中添加相应代码,以支持以下关于shell的功能: 实现简单shell命令,比如ca ...
- [转载]ASP.NET Core文件上传与下载(多种上传方式)
ASP.NET Core文件上传与下载(多种上传方式) 前言 前段时间项目上线,实在太忙,最近终于开始可以研究研究ASP.NET Core了. 打算写个系列,但是还没想好目录,今天先来一篇,后面在 ...
- 19牛客暑期多校 round2 H 01矩阵内第二大矩形
题目传送门//res tp nowcoder 目的 给定n*m 01矩阵,求矩阵内第二大矩形 分析 O(nm)预处理01矩阵为n个直方图,问题转换为求n个直方图中的第二大矩形.单调栈计算,同时维护前二 ...