Kinect视频中运用全身运动和人体测量统计学的人物识别技术
 摘要:
摘要:
对于人物识别技术来说,动作和人体测量统计学对于光学差异并不敏感,甚至对于眼镜,头发,帽子的描述相当粗糙,现在的以步态为基础的识别技术都是基于对细节的精确描述和对步态周期的精确测量。这种方法需要运动主角在简单背景下反复的重复一个单一动作,并且需要昂贵的动作捕捉系统或者二维的视频系统,以便研究人员可以对运动物体进行分段和跟踪。现有的设备限制了人体测量统计学在实际场景中的运用,因为实际场景中的动作存在不同程度的复杂性。我们发展了一种新的人物识别方法,这种方法以动作和人体测量统计学为基础,并且所用的设备为廉价的kinect RGBD传感器。与之前的以步态为基础的方法不同,我们用Kinect SDK获得整个运动过程中全身的节点并进行分析,以获得运动模式和人物运动的统计学特征。我们演示的方法可以系别人物不同复杂程度的动作,例如同时识别走和跑,当与最先进的运用Kinect传感器获得深度图像的步态分析方法相比,本方法在人物识别方面的表现更好。
1.介绍
精确和高效的人物识别方法是计算机,计量生物学,监督部门,安全部门的主要研究方向。总的来说人物识别是通过测量和分析生物特征或者计量统计学,其中计量统计学是用于识别的特征。例如,高冲击研究被用于识别具有相似面部,相似指纹或者解剖统计学特征的人物。但是,这种识别都需要接触传感器或者配合传感器以得到数据,在实际的影像中,精确的识别和定位生物统计学特征可以敏感的识别光学差异和障碍物,这种方式会大大降低识别的表现。
为了克服这些限制,人物识别方法中运用较低的步态统计学来识别具有相似的较低的步态运动学,步幅,节奏,力学的人物。甚至这些方法仍然具有较少的限制,对障碍物的描述一样粗糙,并且需要精确探测运动区域,准确的分割特定时间序列的运动物体,以便孤立出单独的步态循环用来建立标准能量体积,独立的步态循环用于平衡这些动作,确定步态的个体特征。在真正的录像片段中,同时具有不同复杂度的运动,独立步态循环会导致计算的高成本和错误率的提高。如果步态循环不被合适的探测和孤立,步态平衡和标准化的错误就会被引入,有可能导致很差的识别表现。
我们呈现了一个新的方法,运用从Kinect 视频中得到的全身动作和生物统计学。Kinect传感器被用于识别,因为其廉价,易于使用,并且三维的动作传感器对于光学差异并不敏感。这种贡献是三倍的:1.我们引入了一个新的运动统计学,当一个人进行简单运动时,可以检测全身的协调运动,2.得到的运动统计学数据可以检测运动周期,在整个运动过程中追踪节点,使得步态循环的误差比那些以步态为基础的方法得到的误差要小3.我们引入了完整的人物识别系统来促进生物识别技术,在生物系别技术无法系别两个具有相似全身运动模式的人时。与现有的运用人体测量数据来增强物体追踪或者姿势估计得技术不同,人体测量统计学与预测动作相结合来形成统一的人物识别器。
在那些试验中,研究了十个不同人物的两种基本动作,我们一共收集100个短的Kinect视频,获得了平均等错误率的曲线和累积匹配曲线,分别为13%和90%。运用相同的Kinect数据集,将现有的方法与步态能量体积法相比较。第二部分详细描述了方法的细节,第三部分是试验部分,评估了人物是别的表现,第四部分是简要的结论。
2.提出方法
在这个部分,我们开发出新的用于识别Kinect视频中未知人物的基本运动。这种方法通过两步识别系统来完成,系别流程如图1所示。在第一阶段,包含未知的运动的测试Kinect视频被输入到动作识别器中,这个动作识别器可以识别两种最基本的运动,跑和走。为了完成这个过程,收集了不同性别,不同物体的最基本的两个动作的Kinect视频。对于每个训练视频的框架来说,标准化三维模型的20个骨骼节点,并且将其输入到高维空间中,通过支持向量机将两个动作分开并采集。赋予Kinect视频超平面可以使我们分析视频的每个框架,将未知动作通过多数决算法进行识别。
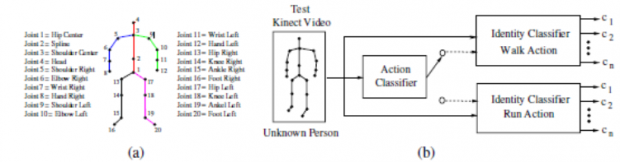
在第二段,测试Kinect视频被输入到识别器中,以便识别每个基本动作,我们准备了n个以动作模式和人物数据测量为准则的人物识别器。动作统计学数据是通过Kinect视频中描述的20个骨骼节点的半径,方位角和评估动作模式来得到的。同样,人体测量数据统计学的数据收集也是通过同样的Kinect视频,统计生物学是一个统计模型,描述了20个骨骼节点之间的比例。最后,n个数据被计算用于识别未知的动作,其中数值最小的就是未知的动作。
2.1动作识别
让Vw = {Vwi ; i = 1, 2, . . .,m}作为一个走路的集合,Vr = {Vri ; i =1, 2, . . .,m}作为跑步的集合,其中Vwi是图像帧的有序序列,图像捕捉了人物走路的不同姿态。每个框架用60×n的骨骼节点矩阵来描述,所有视频捕捉的数据构成一个60×2nm的矩阵,将矩阵用奇异值分解,得到的矩阵的元素值为0或者很小,只有10个最大的奇异值需要考虑,降维的矩阵用来训练多级的支持向量机,因为数据不是线性可分的,非线性的高斯径向基函数学习超函数。用所有出现的n个框架的多数决算法就可以识别未知的动作。
2.2 身份分类 赋予Kinect视频一个未知的人物X,识别动作需要消耗
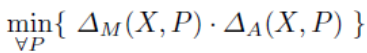
计算每个人P的训练数据集,其中ΔM(X, P)为运动差异,ΔA(X, P)为人体测量数据差异,人物X在其计算量最小时就会被识别出。
动作计量统计由如下过程获得,获得Kinect视频捕捉的人物的行走动作,构造每个动作的框架,定义第k个框架中的20个骨骼节点的半径,方位角和位置高度,,这种分法会形成3个不同的20×n的矩阵,半径矩阵,方位角矩阵,位置矩阵。对每个运动矩阵来说,运动的直方图由算法1来决定。

对于每个人的的训练数据来说,用6个动作直方图来计算,未知人物X不在训练的数据集中,已知人物P与X的训练数据的动作差异可以用下式计算。
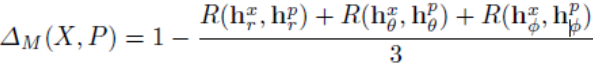
其中R是相关系数,h是X和P的运动直方图,运动差异的数值在0-1之间,当差异值为0时,两个人具有相同的运动模式。
人体测量统计学的测量过程如下:引入一个矩阵来描述个人的行走动作,对于每个视频框架来说,其矩阵为20×20的节点,这个矩阵由20个骨骼节点的位置组成,节点的比例由公式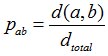 计算,其中d(a,b)是a与b之间的欧几里得距离。
计算,其中d(a,b)是a与b之间的欧几里得距离。
J是20*20n的矩阵,统计学模型N(p,D)是由J的比例构成的。P是一个描述20个节点的平均值比例的矩阵,D是描述20个节点协方差比例的矩阵。对于培训样本的每个人来说,其具有两个人体测量统计学模型。X是不在培训样本中的未知人物,P是培训样本中的已知人物,他们之间的差异可以用注明的KL距离计算公式。
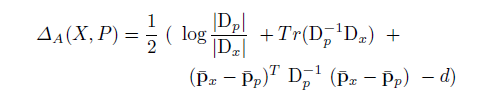
3试验
在本节进行实验,在这部分实验,评估拟议的系统的能力来正确地分类未知的人 和他们的行动在Kinect的视频能力。该方法的性能与步态能量体积(GEV)方法 相比较。一般来说,GEV是三维扩展的二维步态能量图像 。利用深度图像,把被跟踪的人的体轮廓分割,分割的结果是用来隔离每个步态周期的视频序列。对于每个孤立的步态周期的平衡和的平均形成了GEV。主成分分析(PCA)和多个判别分析(MDA)是用来发现一个降低维度特征向量,以及描述了GEV。这未知的特征向量相比已知使用基于特征向量的距离测量来识别人的身份在Kinect视频跟踪。在这些实验中,我们手动确定步态周期,然后使用推荐的设置进行PCA和MDA降维。
在3.1节中,我们描述了Kinect的数据集合用来训练动作和身份分类,并在3.2节中,我们描述了Kinect的数据集合用于测试系统的准确性和性能的比较。两个数据集收集使用Kinect传感器安装在一个可移动的车,面对着人做这个动作。数据收集过程中,装置和被摄物体之间的距离为大约1.5〜3米。最后,我们评估在3.3节中使用众所周知的接收机工作特征(ROC)曲线和曲线(CMC)的累积匹配的行动和个人身份分类的性能。ROC用于评估的灵敏度的方法:1.用于只有一个生物特征身份分类。2.频率的KF(见第2.2节)的数量用于构造相关(r,θ,φ)运动直方图变化的值的范围。(注:这是唯一提出人体识别系统的自由参数)。
3.1 训练数据
训练数据集包括10人,6男4女,其中每个人执行每2个基本动作2次。举例来说,每个人都有4 Kinect的视频:2行走和跑步。总体而言,训练数据集有40部影片。实施例的三维骨架Kinect传感器发现,示出的2个基本动作示于图中。活动分类培训,使用40个视频。对于每次步行身份分类运动和人体生物识别技术被训练使用两个集合的那个人。同样,用那个人身上获取的动作数据和人体数据测量统计学数据来训练跑步识别器。对于男性受试者的年龄范围为25至40岁之间,并高度范围大约是1.73米和1.8米之间。4女性受试者的年龄范围在25和37岁之间,高度范围大致在1.55米至1.6米。

图2.训练数据的例子。上面一排:例如一个人的骨骼进行正常的跑步动作。下面一排:例如一个人的骨骼进行正常行走动作。
3.2 测试数据
使用相同的10人的训练数据集,测试数据中的每个人设置执行2基本操作3次,即每个人都有6 Kinect的视频:3的步行和3个运行。总体而言,测试数据集有60部影片。为了使测试数据集具有挑战性的,每个人都被要求执行额外的操作:首次收集(至少是具有挑战性的)背一个载有20磅的书籍背包,最具挑战性的第二次收集(适度挑战性的)穿同样的20磅的背包,并在右手上携带一个对象,第三收集(是最具有挑战性的)如图片的指示缓慢的走出“S”型。在一般情况下,这些集合模拟真实场景,可能会发现在公众聚集区域,如机场,火车站,商场。

图3.例如第三收集测试数据。上面一排:例如一个人表演的“S”型的运行动作的骨骼。底下一排:例如一个人的骨骼进行“S”的行走动作。
3.3结果
两个动作,动作分类性能采用多数表决是100%这两个动作,每部影片的动作分类性能范围从50.30%到100%平均值为93.47%。在图片中的ROC曲线(1)我们的试验方法和GEV方法显示验证率(VR)及等错率(曾经)。这符图也显示了我们的方法和GEV的方法对于CMC等级1到6的性能。对于EER和CMC-1性能的行动能效比可以看出我们的方法是优于GEV的方法的。从步行和运行的操作中我们的方法在性能上显示提高了11%并且EER提高了4%。对于步行的动作我们的方法通过等级3,并达到了90%准确,而GEV仍徘徊在88%,属于等级6,1级的运行操作性能的方法是90%,而GEV方法的等级3却没有达到90%。在此ROC曲线在图中还显示运动生物识别是不是过于敏感,KF数量用于构造的运动直方图的频率。事实上,ROC曲线显示性能大致相同的,当FK为3倍或5倍并且大于10时。
这表明关节运动模式可以充分的描述幅度最大的前10个频率。
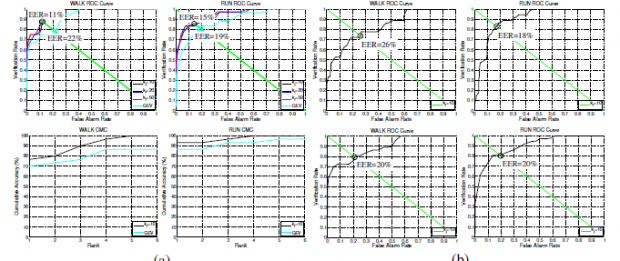
图4。对于这两种行为(一)顶行:VR和EER之间的比较和我们的方法(KF =10,30,50)和GEV的方法的比较。底排:CMC排名1至6和我们的方法(KF =10)和GEV的性能的对比。(二)顶行:VR能效比性能只使用运动生物识别(KF =10)。底排:VR和EER性能只使用人体测量的生物特征(KF= 10)。
图4(b)所示时,只有运动和VR的能效比性能可以用来人体测量的生物识别所使用的身份分类。这些ROC曲线中可以看出,运用这两个生物特征身份进行分类时,人识别时更为精确。对于步行动作来说,人体测量 的EER的表现明显优于动作统计,可以显示出人体侧量的统计对动作统计具有导向作用。然而,对于运行行动的辨别力的运动生物高,并且要求相对较低人体生物特征的帮助。因为计算复杂的奇异值分解和支持向量机算法O(pq2 + p2q + q3)[21]和O(q2),计算的复杂性, 空间复杂度的动作分类是O(q2),即右奇异值矩阵D的大小。分析的算法1显示出的身份的计算复杂性分类是O(nNlogN),身份分类和空间复杂度是O(n),即列的半径尺寸,方位,海拔矩阵。2.4GHz的英特尔酷睿2四核CPU,所需的总时间来训练的动作分类器是32分钟,并培养一个标识分类器所需要的时间是30毫秒。
4.结论
总之,这个方法是可行的。不同于传统的步态形成方法,在视频序列中的周期中,企图孤立和检查步态。我们的方法考虑了整个轨道的序列和检查的周期运动,上肢和下肢的关节由Kinect的SDK执行,并对的行动有很大的贡献。具有挑战性的测试数据集,构建了具有多种基本操作与不同层次的复杂性。实验结果表明,该方法有一个平均Roc能效比为13%,平均CMC-1识别率达到90%。性能的比较使用基于步态的方法进行使用Kinect感应器所产生的深度图像。结果表明我们的方法有更好的性能。实验也对个人的敏感性和两个生物测定进行了评估,结果表明两个生物识别技术需要人识别。我们还将显示运动生物用于构建的运动直方图的频率数进行识别是不是过于敏感。
Kinect视频中运用全身运动和人体测量统计学的人物识别技术的更多相关文章
- Dance GAN 迁移不同视频中人物动作的方法
该研究提出一种迁移不同视频中人物动作的方法.给出两个视频,一个视频中是研究者想要合成动作的目标人物,另一个是被迁移动作的源人物,研究者通过一种基于像素的端到端流程在人物之间进行动作迁移(motion ...
- 50行Python代码实现视频中物体颜色识别和跟踪(必须以红色为例)
目前计算机视觉(CV)与自然语言处理(NLP)及语音识别并列为人工智能三大热点方向,而计算机视觉中的对象检测(objectdetection)应用非常广泛,比如自动驾驶.视频监控.工业质检.医疗诊断等 ...
- 面部表情视频中进行远程心率测量:ICCV2019论文解析
面部表情视频中进行远程心率测量:ICCV2019论文解析 Remote Heart Rate Measurement from Highly Compressed Facial Videos: an ...
- 聊聊视频中的编解码器,你所不知道的h264、h265、vp8、vp9和av1编解码库
你知道FFmpeg吗?了解过h264/h265/vp8/vp9编解码库吗? 我们日常生活中使用最广泛的五种视频编码:H264(AVC).H265(HEVC).vp8.vp9.av1都分别是什么?由哪些 ...
- IOS从视频中获取截图
从视频中获取截图: NSString *movpath =[[NSBundle mainBundle] pathForResource:@”iosxcode4″ ofType:@”mov”]; mpv ...
- python 从视频中提取图片,并保存在硬盘上
使用python的moviepy库来提取视频中的图片,按照视频每帧一个图片的方式来保存. extract images from video, than save them to disk from ...
- 利用Effmpeg 提取视频中的音频(mp3)
在B站看到一个up发的病名为爱的钢琴曲,感觉很好听,然后当然是要加入歌单啊.然而不知道怎么转换成mp3,找来找去找到了EFFmpeg 这篇只是达到了我简单的需求,以后可能会有EFFmpeg更详细的使用 ...
- python+opencv选出视频中一帧再利用鼠标回调实现图像上画矩形框
最近因为要实现模板匹配,需要在视频中选中一个目标,然后框出(即作为模板),对其利用模板匹配的方法进行检测.于是需要首先选出视频中的一帧,但是在利用摄像头读视频的过程中我唯一能想到的方法就是: 1.在视 ...
- 机器学习进阶-图像基本处理-视频的读取与处理 1.cv2.VideoCapture(视频的载入) 2.vc.isOpened(载入的视频是否可以打开) 3.vc.read(视频中一张图片的读取) 4.cv2.cvtColor(将图片转换为灰度图)
1.vc = cv2.VideoCapture('test.mp4') #进行视频的载入 2.vc.isOpened() # 判断载入的视频是否可以打开 3.ret, frame = vc.read( ...
随机推荐
- webpack-dev-server 导致的 invalid host header
这几天做的一个项目,在这个项目的 js 方面,我将其分业务和功能的拆分成模块化,然后使用 webpack 来进行打包.(第一次在公司产品中使用 webpack) 然后使用了 webpack-dev-s ...
- 关于使用pietty或putty终端连接ubuntu虚拟机时报被拒绝连接问题
首先如果要使用终端进行远程连接的ubuntu虚拟机的话,必须保证其虚拟机ip能在window下ping的动.具体的ubuntu网络配置这里不再讲,我这里使用的是NAT连接. 然后检查ssh服务是否有安 ...
- Android Studio彻底删除Module
在"Project"视图中选择需要删除的module名,此处删除"app",点击右键,选择"Open Module Setting",然后选 ...
- java源码--HashMap
一.HashMap简介 1.1.HashMap概述 HashMap是基于哈希表的Map接口实现的,它存储的是内容是键值对<key,value>映射.此类不保证映射的顺序,假定哈希函数将元素 ...
- Ural 1250 Sea Burial 题解
目录 Ural 1250 Sea Burial 题解 题意 输入 题解 程序 Ural 1250 Sea Burial 题解 题意 给定一个\(n\times m\)的地图,\(.\)为水,\(\#\ ...
- Dijkstra算法——超~~详细!!
Dijkstra算法_ ** 时隔多月,我又回来了!**_ 今天下午久违的又学了会儿算法,又重新学习了一遍Dijkstra,这是第三次重新学习Dijkstra(*以前学的都忘完了>_<*) ...
- vue的基本语法
在学习vue之前,我们应了解一下什么是vue.js? 什么是Vue.js? Vue.js是目前最后一个前端框架,React是最流行的一个前端框架(react除了开发网站,还可以开发手机App,Vue语 ...
- 网络编程[第二篇]基于udp协议的套接字编程
udp协议下的套接字编程 一.udp是无链接的 不可靠的 而上篇的tcp协议是可靠的,会有反馈信息来确认信息交换的完成与否 基于udp协议写成的服务端与客户端,各司其职,不管对方是否接收到信息, ...
- k8s之dashboard认证、资源需求、资源限制及HeapSter
1.部署dashboard kubernetes-dashboard运行时需要有sa账号提供权限 Dashboard官方地址:https://github.com/kubernetes/dashboa ...
- Git FLS的使用
克隆git地址后,一些文件内容被隐藏. 显示如下: version https://git-lfs.github.com/spec/v1oid sha256:xxxxxxxxxxxxxxxxxxxxx ...