spark学习之Lambda架构日志分析流水线
单机运行
一、环境准备
Flume 1.6.0
Hadoop 2.6.0
Spark 1.6.0
Java version 1.8.0_73
Kafka 2.11-0.9.0.1
zookeeper 3.4.6
二、配置
spark和hadoop配置见()
kafka和zookeeper使用默认配置
1、kafka配置
启动
bin/kafka-server-start.sh config/server.properties
创建一个test的topic
bin/kafka-topics.sh --create --zookeeper vm: --replication-factor --partitions --topic test
2、flume配置文件,新建一个dh.conf文件,配置如下
其中发送的内容为apache-tomcat-8.0.32的访问日志
#define c1
agent1.channels.c1.type = memory
agent1.channels.c1.capacity =
agent1.channels.c1.transactionCapacity =
#define c1 end #define c2
agent1.channels.c2.type = memory
agent1.channels.c2.capacity =
agent1.channels.c2.transactionCapacity =
#define c2 end #define source monitor a file
agent1.sources.avro-s.type = exec
agent1.sources.avro-s.command = tail -f -n+ /usr/local/hong/apache-tomcat-8.0./logs/localhost_access_log.--.txt
agent1.sources.avro-s.channels = c1 c2
agent1.sources.avro-s.threads = # send to hadoop
agent1.sinks.log-hdfs.channel = c1
agent1.sinks.log-hdfs.type = hdfs
agent1.sinks.log-hdfs.hdfs.path = hdfs://vm:9000/flume
agent1.sinks.log-hdfs.hdfs.writeFormat = Text
agent1.sinks.log-hdfs.hdfs.fileType = DataStream
agent1.sinks.log-hdfs.hdfs.rollInterval =
agent1.sinks.log-hdfs.hdfs.rollSize =
agent1.sinks.log-hdfs.hdfs.rollCount =
agent1.sinks.log-hdfs.hdfs.batchSize =
agent1.sinks.log-hdfs.hdfs.txnEventMax =
agent1.sinks.log-hdfs.hdfs.callTimeout =
agent1.sinks.log-hdfs.hdfs.appendTimeout = #send to kafaka
agent1.sinks.log-sink2.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.log-sink2.topic = test
agent1.sinks.log-sink2.brokerList = vm:
agent1.sinks.log-sink2.requiredAcks =
agent1.sinks.log-sink2.batchSize =
agent1.sinks.log-sink2.channel = c2 # Finally, now that we've defined all of our components, tell
# agent1 which ones we want to activate.
agent1.channels = c1 c2
agent1.sources = avro-s
agent1.sinks = log-hdfs log-sink2
三、测试flume发送
1、启动hdfs
./start-dfs.sh
2、启动zookeeper
./zkServer.sh start
3、kafka的见上面
4、启动flume
flume-ng agent -c conf -f dh.conf -n agent1 -Dflume.root.logger=INFO,console
四、测试效果
运行kafka的consumer查看
bin/kafka-console-consumer.sh --zookeeper localhost: --topic test --from-beginning
可以看到如下内容说明kafka和flume的配置成功
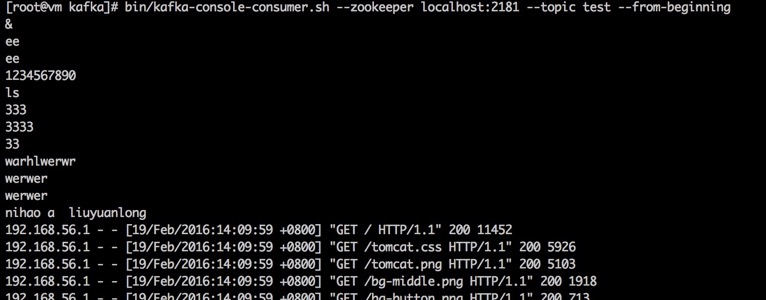
访问hdfs查看如果/flume可以下载文件进行查看验证hdfs发送是否成功
spark学习之Lambda架构日志分析流水线的更多相关文章
- spark SQL学习(综合案例-日志分析)
日志分析 scala> import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row scala&g ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- Hadoop学习笔记—20.网站日志分析项目案例
1.1 项目来源 本次要实践的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖.回帖,如图1所示. 图1 项目来源网站-技术学习论坛 本次实践的目的就在于 ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- 【Spark】通过Spark实现点击流日志分析
文章目录 数据大致内容及格式 统计PV(PageViews) 统计UV(Unique Visitor) 求取TopN 数据大致内容及格式 194.237.142.21 - - [18/Sep/2013 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- 架构之ELK日志分析系统
ELK多种架构及优劣 既然要谈ELK在大数据运维系统中的应用,那么ELK架构就不得不谈.本章节引出四种笔者曾经用过的ELK架构,并讨论各种架构所适合的场景和优劣供大家参考. 先大致介绍ELK组件.EL ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
随机推荐
- LeetCode 岛屿的最大面积(探索字节跳动)
题目描述 给定一个包含了一些 0 和 1的非空二维数组 grid , 一个 岛屿 是由四个方向 (水平或垂直) 的 1 (代表土地) 构成的组合.你可以假设二维矩阵的四个边缘都被水包围着. 找到给定的 ...
- 带你体验Android自定义圆形刻度罗盘 仪表盘 实现指针动态改变
带你体验Android自定义圆形刻度罗盘 仪表盘 实现指针动态改变 转 https://blog.csdn.net/qq_30993595/article/details/78915115 近期有 ...
- C语言处理CSV数据
以下代码为博客 <Python的并行求和例子>: http://www.cnblogs.com/instant7/p/4312786.html 中并行python代码的C语言重写版. 用C ...
- MySql锁和事务隔离级别
在讲mysql事物隔离级别之前,我们先简单说说mysql的锁和事务. 一:数据库锁 因为数据库要解决并发控制问题.在同一时刻,可能会有多个客户端对同一张表进行操作,比如有的在读取该行数据,其他的尝试去 ...
- 怎么用php实现短信验证码发送
我在在众多的第三方短信服务商里选择了云片网这个短信服务商,我也会尽可能利用最简单的方式去帮助广大开发者解决短信验证码功能模块的实现. 再次之前我也参考了大部分网上的博客等,大多数都是把云片网的demo ...
- KDE-解决.docx .xlsx .pptx文档默认由Ark打开的问题
安装KDE后,默认的压缩解压程序变成了Ark,并且原来默认用WPS Office打开的.docx .xlsx .pptx文档,从文件管理器双击打开时,也变成了用Ark打开. 查了下网上的资料,可通过如 ...
- jekins自动部署tomcat注意事项、连接tomcat报错
jekins自动部署tomcat注意事项 千万不要用下面插件推送,报错很多, 要用脚本,一篇博客说的:“我们都是用的脚本,插件报错太多,也不完善” Deploy to container Plugin ...
- centos7.2 mysql tar.gz 搭建 (亲测成功)
1.安装依赖:yum -y install libaioyum search libaio 2.卸载系统自带的Mariadb数据库:rpm -qa | grep mariadbrpm -e --nod ...
- mySQL的简单安装和配置
MySQL的安装和配置 1.去官网下载mysql-5.6.29-winx64.zip包.地址: http://dev.mysql.com/downloads/mysql/5.6.html 2,把安装包 ...
- 【Linux】部署NTP时间同步服务器
1. 查看机器的Linux版本 查看集群内所有服务器的linux版本,确保相同,不要跨大版本. [root@bigdata111 ~]# cat /etc/redhat-release CentOS ...