【原创】大数据基础之ETL vs ELT or DataWarehouse vs DataLake
ETL
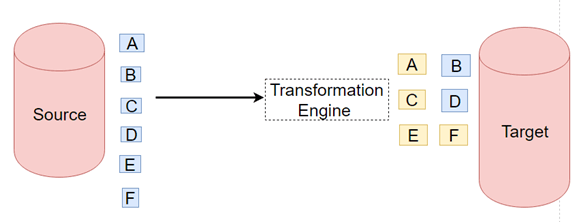
ETL is an abbreviation of Extract, Transform and Load. In this process, an ETL tool extracts the data from different RDBMS source systems then transforms the data like applying calculations, concatenations, etc. and then load the data into the Data Warehouse system.
In ETL data is flows from the source to the target. In ETL process transformation engine takes care of any data changes.
ELT
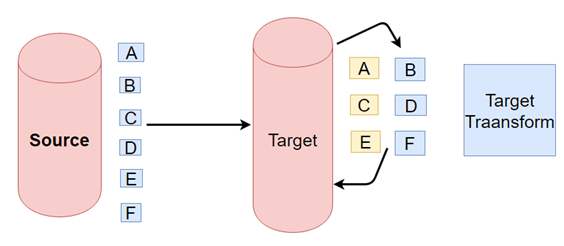
ELT is a different method of looking at the tool approach to data movement. Instead of transforming the data before it's written, ELT lets the target system to do the transformation. The data first copied to the target and then transformed in place.
ELT usually used with no-Sql databases like Hadoop cluster, data appliance or cloud installation.
Data Warehouse vs Data Lake
ETL对应的是Data Warehouse,而ELT对应Data Lake,那什么是Data Lake?
A data lake is a system or repository of data stored in its natural format, usually object blobs or files. A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video).
Pentaho CTO James Dixon has generally been credited with coining the term “data lake”. He describes a data mart (a subset of a data warehouse) as akin to a bottle of water…”cleansed, packaged and structured for easy consumption” while a data lake is more like a body of water in its natural state. Data flows from the streams (the source systems) to the lake. Users have access to the lake to examine, take samples or dive in.
参考:
https://www.guru99.com/etl-vs-elt.html
https://aws.amazon.com/cn/big-data/datalakes-and-analytics/what-is-a-data-lake/
https://www.blue-granite.com/blog/bid/402596/top-five-differences-between-data-lakes-and-data-warehouses
https://www.forbes.com/sites/bernardmarr/2018/08/27/what-is-a-data-lake-a-super-simple-explanation-for-anyone/#672125e776e0
https://blog.panoply.io/etl-vs-elt-the-difference-is-in-the-how
https://www.xplenty.com/blog/etl-vs-elt/
【原创】大数据基础之ETL vs ELT or DataWarehouse vs DataLake的更多相关文章
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- Kettle学习系列之数据仓库、数据整合、ETL、ELT和EII之间的区别?
不多说,直接上干货! 在数据仓库领域里,的一个重要概念就是数据整合(data intergration).数据整合它就是把不同数据库中的数据整合到一起,对外提供统一的数据视图. 数据整合最典型的案例就 ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
随机推荐
- Ubuntu安装Redis及使用
NoSQL简介NoSQL,全名为Not Only SQL,指的是非关系型的数据库随着访问量的上升,网站的数据库性能出现了问题,于是nosql被设计出来 优点/缺点优点:高可扩展性分布式计算低成本架构的 ...
- synchronized对象解析
package com.haiyisoft.hyoaPc; public class Test7 { public static void main(String[] args) throws Int ...
- ios-动态添加方法,交换方法,重定向方法
新建一个类Person,Person.h 不写代码,Person.m 有如下两个方法: - (void)eat { NSLog(@"xxx eat===="); } [动态添加方法 ...
- HttpURLConnection获取数据
使用步骤: 1.创建Url 2.用Url打开连接 3.设置请求参数 4. 获取响应状态码 2xxx 请求成功 3xxx重定向 4xxx资源错误 5xxx服务器错误 5.获取服务器返回的二进制输入流 6 ...
- NET全控件
NBSI WebSite Injection ReportSite Address: www.xmht.comInject URL: http://www.xmht.com/news.aspx?sty ...
- umask 介绍
umask码 是用户创建文件或目录的初始权限设置值 文件或目录的权限:读: r — 4写: w — 2执行: x — 1 输入umask 查看umask 码 设定umask码,umask 0033 1 ...
- php缓存加速优化--Xcache
1.安装软件:cd /usr/local/src/下载软件包wget http://xcache.lighttpd.net/pub/Releases/3.2.0/xcache- 3.2.0.tar.b ...
- JSTL优点
1. 在应用程序服务器之间提供了一致的接口,最大程序地提高了WEB应用在各应用服务器之间的移植. 2. 简化了JSP和WEB应用程序的开发.3. 以一种统一的方式减少了JSP中的scriptlet代码 ...
- 关于 /proc/sys/net/ipv4/下 文件的详细解释
关于 /proc/sys/net/ipv4/下 文件的详细解释: 1) /proc/sys/net/ipv4/ip_forward 该文件表示是否打开IP转发. 0,禁止 1,转 ...
- 二、windows下搭建vue开发环境+IIS部署
有时我们的服务器并不一定是node,也许是IIS,这样我们就需要把工程构建出来,与IIS集成. 构建该项目的命令如下 cnpm run build 将dist文件夹拷贝出来,放到IIS的发布目录,在浏 ...