CHD-5.3.6集群上hive安装
解压过后:
[hadoop@master CDH5.3.6]$ ls -rlt
total 8
drwxr-xr-x. 17 hadoop hadoop 4096 Jun 2 16:07 hadoop-2.5.0-cdh5.3.6
drwxr-xr-x. 11 hadoop hadoop 4096 Jun 2 16:28 hive-0.13.1-cdh5.3.6
1.配置hive-env.sh
export JAVA_HOME=/usr/local/jdk1.
export HADOOP_HOME=/home/hadoop/CDH5.3.6/hadoop-2.5.-cdh5.3.6
export HIVE_HOME=/home/hadoop/CDH5.3.6/hive-0.13.-cdh5.3.6
export HIVE_CONF_DIR=/home/hadoop/CDH5.3.6/hive-0.13.-cdh5.3.6/conf
2.配置hive-log4j.properties
hive.log.dir=/home/hadoop/CDH5.3.6/hive-0.13.-cdh5.3.6/log
3.配置hive-site.xml
这个寻找Apache-hadoop下的就可以,直接考过来就可以,在conf 目录下
4.配置环境变量
vi .bash_profile
export HADOOP_HOME=/home/hadoop/CDH5.3.6/hadoop-2.5.-cdh5.3.6
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HIVE_HOME=/home/hadoop/CDH5.3.6/hive-0.13.-cdh5.3.6
export HADOOP_INSTALL=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$MAVEN_HOME/bin:$HIVE_HOME/bin
5.拷贝MySQL包
cp /home/hadoop/hive/lib/mysql-connector-java-5.1..jar ./
6.hive命令报错:
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
解决方法:
格式化MySQL:
schematool -dbType mysql -initSchema
7.进入hive
hive (default)>
> CREATE TABLE dept(
> deptno int,
> dname string,
> loc string)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile;
OK
Time taken: 0.57 seconds
8.准备数据:
vi detp.txt
,ACCOUNTING,NEW YORK
,RESEARCH,DALLAS
,SALES,CHICAGO
,OPERATIONS,BOSTON
9.装数据:
load data local inpath '/home/hadoop/tmp/detp.txt' overwrite into table dept;
10.查询:
hive (default)> select count(1) from dept;
Total jobs =
Launching Job out of
Number of reduce tasks determined at compile time:
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1559517371869_0001, Tracking URL = http://master:8088/proxy/application_1559517371869_0001/
Kill Command = /home/hadoop/CDH5.3.6/hadoop-2.5.-cdh5.3.6/bin/hadoop job -kill job_1559517371869_0001
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 0.79 sec
-- ::, Stage- map = %, reduce = %, Cumulative CPU 1.7 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1559517371869_0001
MapReduce Jobs Launched:
Stage-Stage-: Map: Reduce: Cumulative CPU: 1.7 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
_c0 Time taken: 22.14 seconds, Fetched: row(s)
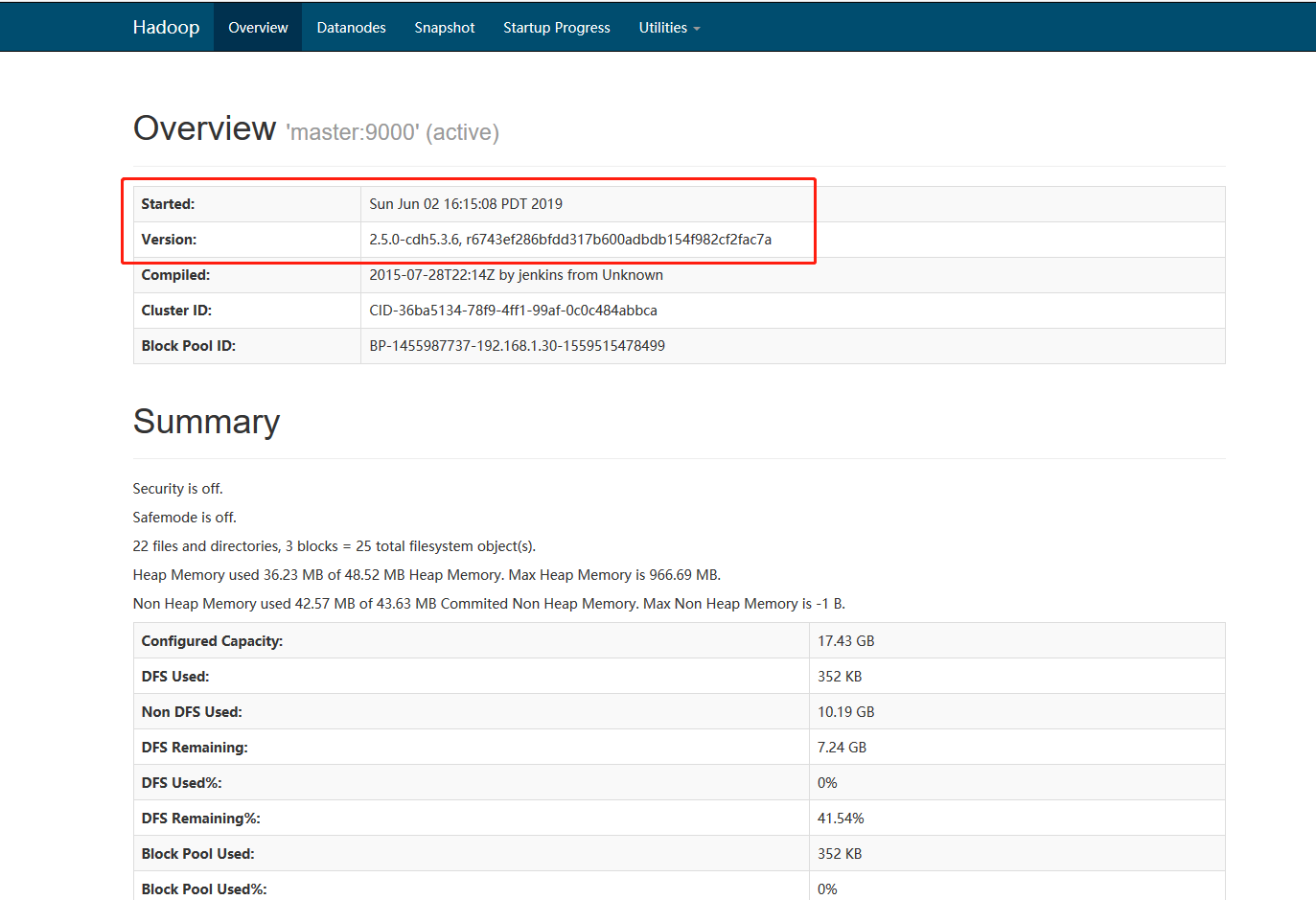
页面验证:
http://192.168.1.30:8088/cluster
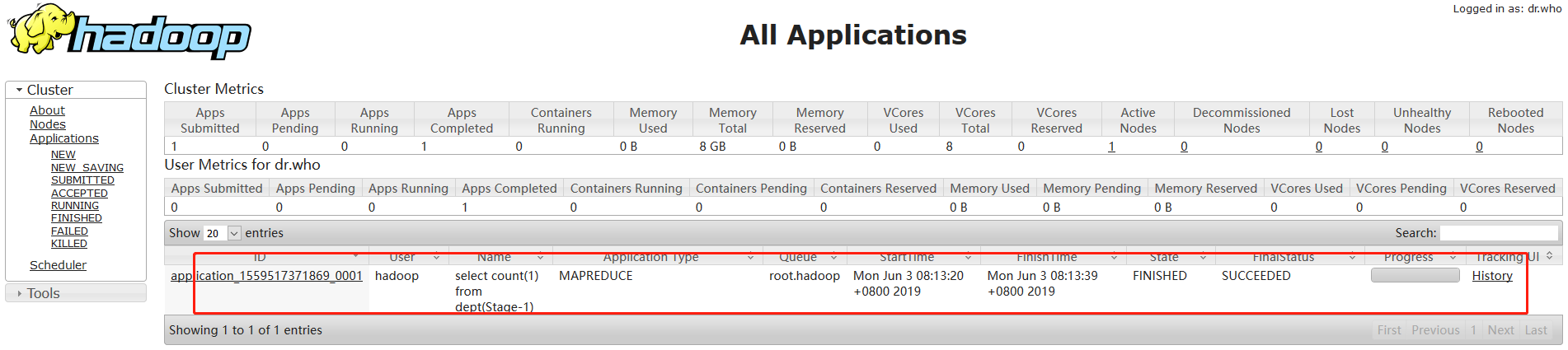
http://192.168.1.30:50070/dfshealth.html#tab-overview
CHD-5.3.6集群上hive安装的更多相关文章
- 基于Hadoop集群搭建Hive安装与配置(yum插件安装MySQL)---linux系统《小白篇》
用到的安装包有: apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.49.tar.gz 百度网盘链接: 链接:https://pan.baid ...
- CHD-5.3.6集群上Flume安装
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and ...
- CHD-5.3.6集群上sqoop安装
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ...
- CHD-5.3.6集群上oozie安装
参考文档:http://archive.cloudera.com/cdh5/cdh/5/oozie-4.0.0-cdh5.3.6/DG_QuickStart.html tar -zxvf oozie ...
- hive1.2.1安装步骤(在hadoop2.6.4集群上)
hive1.2.1在hadoop2.6.4集群上的安装 hive只需在一个节点上安装即可,这里再hadoop1上安装 1.上传hive安装包到/usr/local/目录下 2.解压 tar -zxvf ...
- 在Ubuntu16.04集群上手工部署Kubernetes
目前Kubernetes为Ubuntu提供的kube-up脚本,不支持15.10以及16.04这两个使用systemd作为init系统的版本. 这里详细介绍一下如何以非Docker方式在Ubuntu1 ...
- 在Hadoop集群上的HBase配置
之前,我们已经在hadoop集群上配置了Hive,今天我们来配置下Hbase. 一.准备工作 1.ZooKeeper下载地址:http://archive.apache.org/dist/zookee ...
- [转载] 把Nutch爬虫部署到Hadoop集群上
http://f.dataguru.cn/thread-240156-1-1.html 软件版本:Nutch 1.7, Hadoop 1.2.1, CentOS 6.5, JDK 1.7 前面的3篇文 ...
- 把Nutch爬虫部署到Hadoop集群上
原文地址:http://cn.soulmachine.me/blog/20140204/ 把Nutch爬虫部署到Hadoop集群上 Feb 4th, 2014 | Comments 软件版本:Nutc ...
随机推荐
- Java NIO 学习笔记 读写结合补充
小练习:nio读写文件,将fileread中的内容读取到filewrite中 try { //创建输入通道 FileInputStream fis = new FileInputStream(&quo ...
- JAVA 基础编程练习题31 【程序 31 数组逆序】
31 [程序 31 数组逆序] 题目:将一个数组逆序输出. 程序分析:用第一个与最后一个交换. package cskaoyan; public class cskaoyan31 { @org.jun ...
- RocketMQ采坑记
先来一篇解释比较多的实例 https://www.cnblogs.com/super-d2/p/4154541.html No route info of this topic, PushTopic ...
- Node.js使用Express实现Get和Post请求
var express = require('express'); var app = express(); // 主页输出 "Hello World" app.get('/', ...
- Linux学习笔记之系统中的分区和文件系统
转自 http://blog.csdn.net/hanxuehen/article/details/8229472
- .NET(C#):判断Type类的继承关系
//Type类的函数 class Type bool IsInstanceOfType(object); //判断对象是否是指定类型 //类型可以是父类,接口 //用法:父类.IsInstanceOf ...
- winform 更新文件上传(一)
using Common; using DevExpress.XtraEditors; using FileModel.UpLoad; using System; using System.Colle ...
- gx_dlms 的杂乱记录
DLMS_ERROR_CODE_FALSE W3Jehpnc543MuwUz6ZWDshy5kwbbE9Cw CGXDLMSClient::GetData(CGXByteBuffer& rep ...
- IOI 2005/bzoj 1812:riv 河流
Description 几乎整个Byteland王国都被森林和河流所覆盖.小点的河汇聚到一起,形成了稍大点的河.就这样,所有的河水都汇聚并流进了一条大河,最后这条大河流进了大海.这条大河的入海口处有一 ...
- vue操作数组时遇到的坑
用vue操作数组时,一般就那几个方法,而且是可以渲染的,但是有时候列表是渲染不了的先说下操作数组的几个方法吧 1 push ( ) 这个方法是在数组的最后面添加元素 用法: 括号里写需要加入的元素 ...