Spring Data JPA 大纲归纳
第一天:
springdatajpa
day1:orm思想和hibernate以及jpa的概述和jpa的基本操作
day2:springdatajpa的运行原理以及基本操作
day3:多表操作,复杂查询 第一 orm思想
主要目的:操作实体类就相当于操作数据库表
建立两个映射关系:
实体类和表的映射关系
实体类中属性和表中字段的映射关系
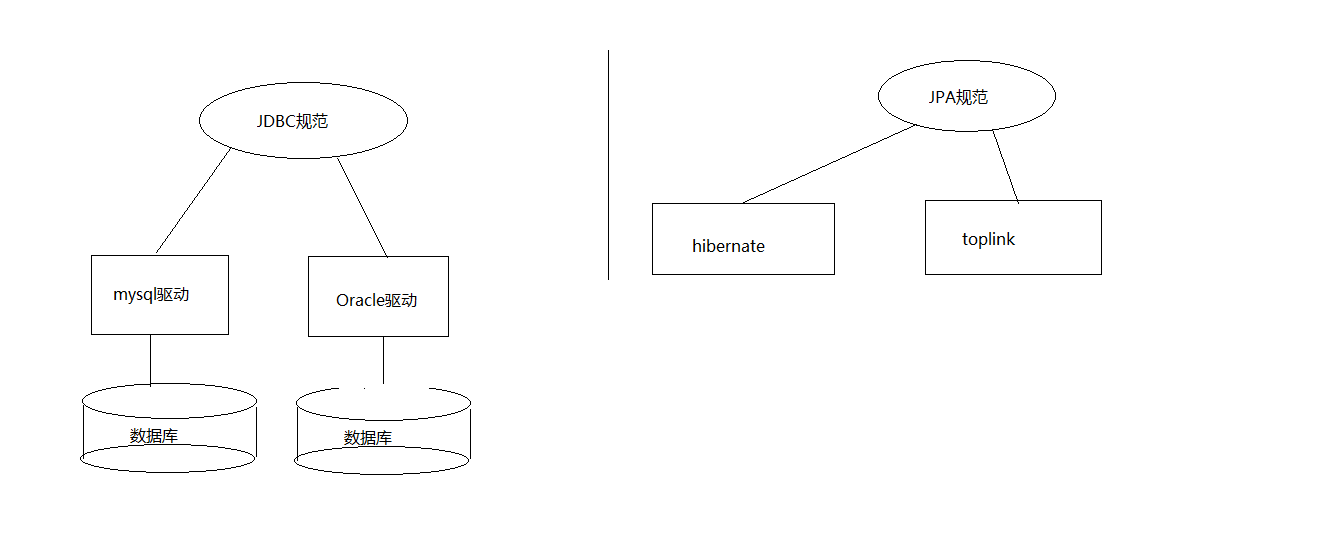
不再重点关注:sql语句 实现了ORM思想的框架:mybatis,hibernate 第二 hibernate框架介绍
Hibernate是一个开放源代码的对象关系映射框架,
它对JDBC进行了非常轻量级的对象封装,
它将POJO与数据库表建立映射关系,是一个全自动的orm框架 第三 JPA规范
jpa规范,实现jpa规范,内部是由接口和抽象类组成 第四 jpa的基本操作
案例:是客户的相关操作(增删改查)
客户:就是一家公司
客户表: jpa操作的操作步骤
1.加载配置文件创建实体管理器工厂
Persisitence:静态方法(根据持久化单元名称创建实体管理器工厂)
createEntityMnagerFactory(持久化单元名称)
作用:创建实体管理器工厂 2.根据实体管理器工厂,创建实体管理器
EntityManagerFactory :获取EntityManager对象
方法:createEntityManager
* 内部维护的很多的内容
内部维护了数据库信息,
维护了缓存信息
维护了所有的实体管理器对象
再创建EntityManagerFactory的过程中会根据配置创建数据库表
* EntityManagerFactory的创建过程比较浪费资源
特点:线程安全的对象
多个线程访问同一个EntityManagerFactory不会有线程安全问题
* 如何解决EntityManagerFactory的创建过程浪费资源(耗时)的问题?
思路:创建一个公共的EntityManagerFactory的对象
* 静态代码块的形式创建EntityManagerFactory 3.创建事务对象,开启事务
EntityManager对象:实体类管理器
beginTransaction : 创建事务对象
presist : 保存
merge : 更新
remove : 删除
find/getRefrence : 根据id查询 Transaction 对象 : 事务
begin:开启事务
commit:提交事务
rollback:回滚
4.增删改查操作
5.提交事务
6.释放资源 i.搭建环境的过程
1.创建maven工程导入坐标
2.需要配置jpa的核心配置文件
*位置:配置到类路径下的一个叫做 META-INF 的文件夹下
*命名:persistence.xml
3.编写客户的实体类
4.配置实体类和表,类中属性和表中字段的映射关系
5.保存客户到数据库中
ii.完成基本CRUD案例
persist : 保存
merge : 更新
remove : 删除
find/getRefrence : 根据id查询 iii.jpql查询
sql:查询的是表和表中的字段
jpql:查询的是实体类和类中的属性
* jpql和sql语句的语法相似 1.查询全部
2.分页查询
3.统计查询
4.条件查询
5.排序
回顾jdbc操作以及引入orm
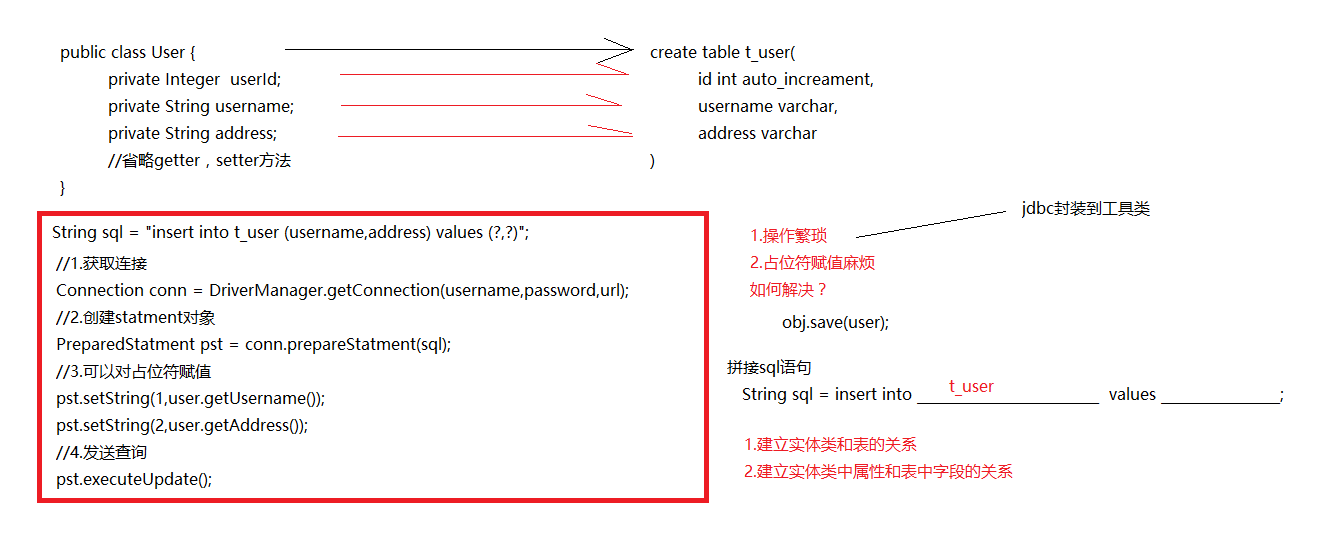
jpa
第二天
orm思想,hibernate,JPA的相关操作 * SpringDataJpa 第一 springDataJpa的概述 第二 springDataJpa的入门操作
案例:客户的基本CRUD
i.搭建环境
创建工程导入坐标
配置spring的配置文件(配置spring Data jpa的整合)
编写实体类(Customer),使用jpa注解配置映射关系
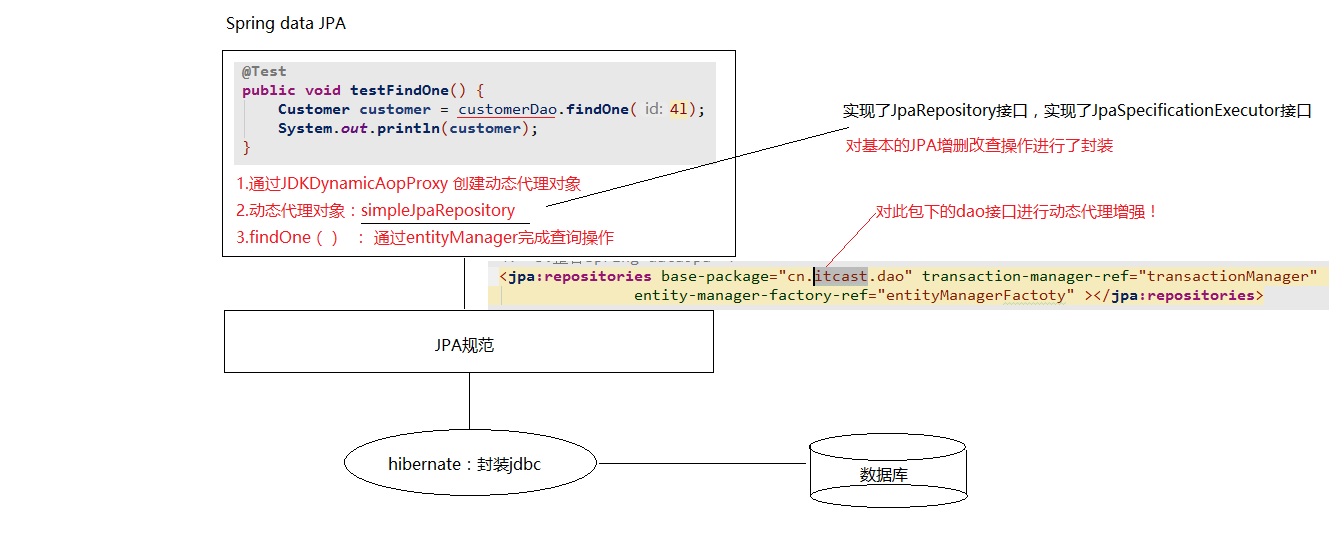
ii.编写一个符合springDataJpa的dao层接口
* 只需要编写dao层接口,不需要编写dao层接口的实现类
* dao层接口规范
1.需要继承两个接口(JpaRepository,JpaSpecificationExecutor)
2.需要提供响应的泛型 *
findOne(id) :根据id查询
save(customer):保存或者更新(依据:传递的实体类对象中,是否包含id属性)
delete(id) :根据id删除
findAll() : 查询全部 第三 springDataJpa的运行过程和原理剖析
1.通过JdkDynamicAopProxy的invoke方法创建了一个动态代理对象
2.SimpleJpaRepository当中封装了JPA的操作(借助JPA的api完成数据库的CRUD)
3.通过hibernate完成数据库操作(封装了jdbc) 第四 复杂查询
i.借助接口中的定义好的方法完成查询
findOne(id):根据id查询
ii.jpql的查询方式
jpql : jpa query language (jpq查询语言)
特点:语法或关键字和sql语句类似
查询的是类和类中的属性 * 需要将JPQL语句配置到接口方法上
1.特有的查询:需要在dao接口上配置方法
2.在新添加的方法上,使用注解的形式配置jpql查询语句
3.注解 : @Query iii.sql语句的查询
1.特有的查询:需要在dao接口上配置方法
2.在新添加的方法上,使用注解的形式配置sql查询语句
3.注解 : @Query
value :jpql语句 | sql语句
nativeQuery :false(使用jpql查询) | true(使用本地查询:sql查询)
是否使用本地查询 iiii.方法名称规则查询
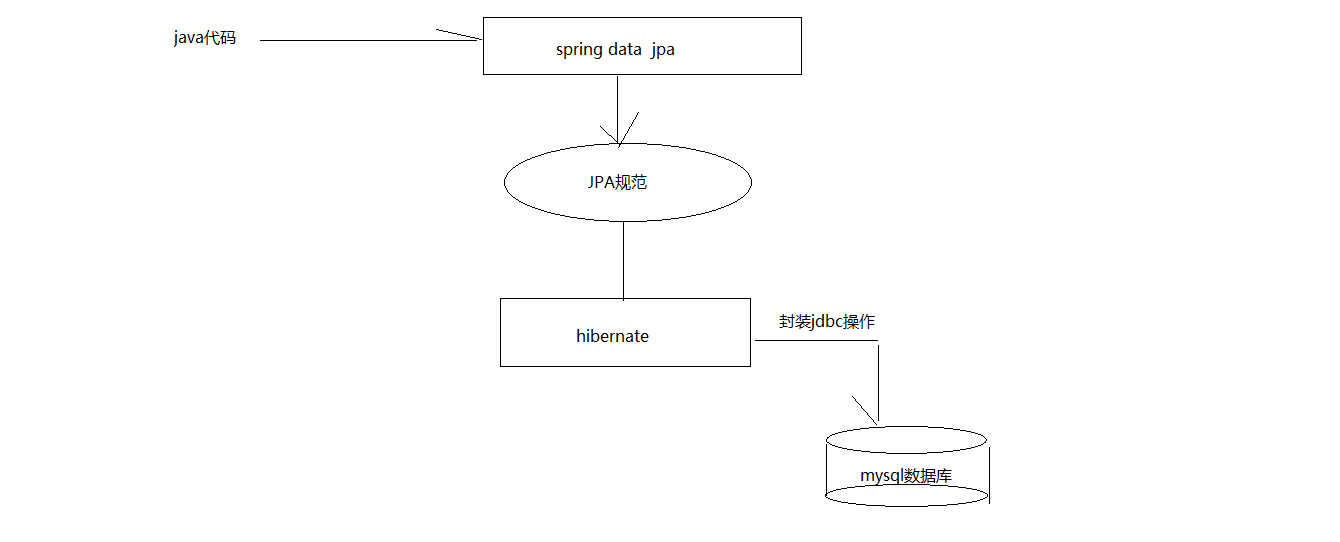
springDataJpa,jpa,hibernate关系
动态分析

springdatajpa的运行过程
第三天
1 回顾
2 i.springDatajpa,jpa规范,hibernate三者之间的关系
3 code -- > springDatajpa --> jpa规范的API --> hibernate
4 ii.符合springDataJpa规范的dao层接口的编写规则
5 1.需要实现两个接口(JpaRepository,JapSpecificationExecutor)
6 2.提供响应的泛型
7 iii.运行过程
8 * 动态代理的方式:动态代理对象
9 iiii.查询
10
11 第一 Specifications动态查询
12
13 JpaSpecificationExecutor 方法列表
14
15 T findOne(Specification<T> spec); //查询单个对象
16
17 List<T> findAll(Specification<T> spec); //查询列表
18
19 //查询全部,分页
20 //pageable:分页参数
21 //返回值:分页pageBean(page:是springdatajpa提供的)
22 Page<T> findAll(Specification<T> spec, Pageable pageable);
23
24 //查询列表
25 //Sort:排序参数
26 List<T> findAll(Specification<T> spec, Sort sort);
27
28 long count(Specification<T> spec);//统计查询
29
30 * Specification :查询条件
31 自定义我们自己的Specification实现类
32 实现
33 //root:查询的根对象(查询的任何属性都可以从根对象中获取)
34 //CriteriaQuery:顶层查询对象,自定义查询方式(了解:一般不用)
35 //CriteriaBuilder:查询的构造器,封装了很多的查询条件
36 Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb); //封装查询条件
37
38 第二 多表之间的关系和操作多表的操作步骤
39
40 表关系
41 一对一
42 一对多:
43 一的一方:主表
44 多的一方:从表
45 外键:需要再从表上新建一列作为外键,他的取值来源于主表的主键
46 多对多:
47 中间表:中间表中最少应该由两个字段组成,这两个字段做为外键指向两张表的主键,又组成了联合主键
48
49 讲师对学员:一对多关系
50
51 实体类中的关系
52 包含关系:可以通过实体类中的包含关系描述表关系
53 继承关系
54
55 分析步骤
56 1.明确表关系
57 2.确定表关系(描述 外键|中间表)
58 3.编写实体类,再实体类中描述表关系(包含关系)
59 4.配置映射关系
60
61 第三 完成多表操作
62
63 i.一对多操作
64 案例:客户和联系人的案例(一对多关系)
65 客户:一家公司
66 联系人:这家公司的员工
67
68 一个客户可以具有多个联系人
69 一个联系人从属于一家公司
70
71 分析步骤
72 1.明确表关系
73 一对多关系
74 2.确定表关系(描述 外键|中间表)
75 主表:客户表
76 从表:联系人表
77 * 再从表上添加外键
78 3.编写实体类,再实体类中描述表关系(包含关系)
79 客户:再客户的实体类中包含一个联系人的集合
80 联系人:在联系人的实体类中包含一个客户的对象
81 4.配置映射关系
82 * 使用jpa注解配置一对多映射关系
83
84 级联:
85 操作一个对象的同时操作他的关联对象
86
87 级联操作:
88 1.需要区分操作主体
89 2.需要在操作主体的实体类上,添加级联属性(需要添加到多表映射关系的注解上)
90 3.cascade(配置级联)
91
92 级联添加,
93 案例:当我保存一个客户的同时保存联系人
94 级联删除
95 案例:当我删除一个客户的同时删除此客户的所有联系人
96
97 ii.多对多操作
98 案例:用户和角色(多对多关系)
99 用户:
100 角色:
101
102 分析步骤
103 1.明确表关系
104 多对多关系
105 2.确定表关系(描述 外键|中间表)
106 中间间表
107 3.编写实体类,再实体类中描述表关系(包含关系)
108 用户:包含角色的集合
109 角色:包含用户的集合
110 4.配置映射关系
111
112 iii.多表的查询
113 1.对象导航查询
114 查询一个对象的同时,通过此对象查询他的关联对象
115
116 案例:客户和联系人
117
118 从一方查询多方
119 * 默认:使用延迟加载(****)
120
121 从多方查询一方
122 * 默认:使用立即加载
Spring Data JPA 大纲归纳的更多相关文章
- Spring Boot2 系列教程(二十三)理解 Spring Data Jpa
有很多读者留言希望松哥能好好聊聊 Spring Data Jpa! 其实这个话题松哥以前零零散散的介绍过,在我的书里也有介绍过,但是在公众号中还没和大伙聊过,因此本文就和大家来仔细聊聊 Spring ...
- 快速搭建springmvc+spring data jpa工程
一.前言 这里简单讲述一下如何快速使用springmvc和spring data jpa搭建后台开发工程,并提供了一个简单的demo作为参考. 二.创建maven工程 http://www.cnblo ...
- spring boot(五):spring data jpa的使用
在上篇文章springboot(二):web综合开发中简单介绍了一下spring data jpa的基础性使用,这篇文章将更加全面的介绍spring data jpa 常见用法以及注意事项 使用spr ...
- 转:使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- 深入浅出学Spring Data JPA
第一章:Spring Data JPA入门 Spring Data是什么 Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map ...
- spring data jpa 调用存储过程
网上这方面的例子不是很多,研究了一下,列出几个调用的方法. 假如我们有一个mysql的存储过程 CREATE DEFINER=`root`@`localhost` PROCEDURE `plus1in ...
- Spring Data JPA 学习记录1 -- 单向1:N关联的一些问题
开新坑 开新坑了(笑)....公司项目使用的是Spring Data JPA做持久化框架....学习了一段时间以后发现了一点值得注意的小问题.....与大家分享 主要是针对1:N单向关联产生的一系列问 ...
- Spring Boot with Spring Data JPA (1) - Concept
What's Spring Data JPA? According to Pivotal, Spring Data JPA, part of the larger Spring Data family ...
- 了解 Spring Data JPA
前言 自 JPA 伴随 Java EE 5 发布以来,受到了各大厂商及开源社区的追捧,各种商用的和开源的 JPA 框架如雨后春笋般出现,为开发者提供了丰富的选择.它一改之前 EJB 2.x 中实体 B ...
随机推荐
- kubernetes监控(12)
一.Weave Scope 1. weave scope 容器地图 创建 Kubernetes 集群并部署容器化应用只是第一步.一旦集群运行起来,我们需要确保一起正常,所有必要组件就位并各司其职,有足 ...
- Python基础-day04
函数基础 目标 函数的快速体验 函数的基本使用 函数的参数 函数的返回值 函数的嵌套调用 在模块中定义函数 01. 函数的快速体验 1.1 快速体验 所谓函数,就是把 具有独立功能的代码块 组织为一个 ...
- iOS知识点总结
1.监测网络状态: - (void)checkNetwork { __block NSString *tips; _reachiabilityManager = [AFNetworkReachabil ...
- InfluxDB入门教程
前言InfluxDB是一个时序性数据库,详细资料如下http://liubin.org/blog/2016/02/18/tsdb-intro/ 下载和安装LZ从官网下载的是influxdb-1.2.4 ...
- Hyperledger Fabric 常用命令
Peer常用命令: #peer chaincode --help #peer channel list --help --logging-level <string> #<strin ...
- 「JOISC 2019 Day3」穿越时空 Bitaro
「JOISC 2019 Day3」穿越时空 Bitaro 题解: 不会处理时间流逝,我去看了一眼题解的图,最重要的转换就是把(X,Y)改成(X,Y-X)这样就不会斜着走了. 问题变成二维平面上 ...
- 深入剖析Java虚拟机内存结构
深入剖析Java虚拟机内存模型 JVM整体架构 JVM整体架构如下: 通过编写代码来分析整个内存区域 public class Math { public static final Integer C ...
- python 创建目录文件夹
主要涉及到三个函数 1.os.path.exists(path) 判断一个目录是否存在 2.os.makedirs(path) 多层创建目录 3.os.mkdir(path) 创建目录 DEMO 直接 ...
- request方法
获取请求行方法: getMethod()获取请求的方法 getContextPath()回去虚拟路径 getServletPath()获取路径(只有在servert中使用) getQueryStrin ...
- java中讲讲DataInputStream的用法,举例?
[学习笔记] 2.4 DataInputStream的用法 马 克-to-win:DataInputStream顾名思义:就是专门用来读各种各样的数据的,比如(int,char,long等),一定要注 ...