爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:


二:爬虫过程分析
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
下图是大V的主要信息:
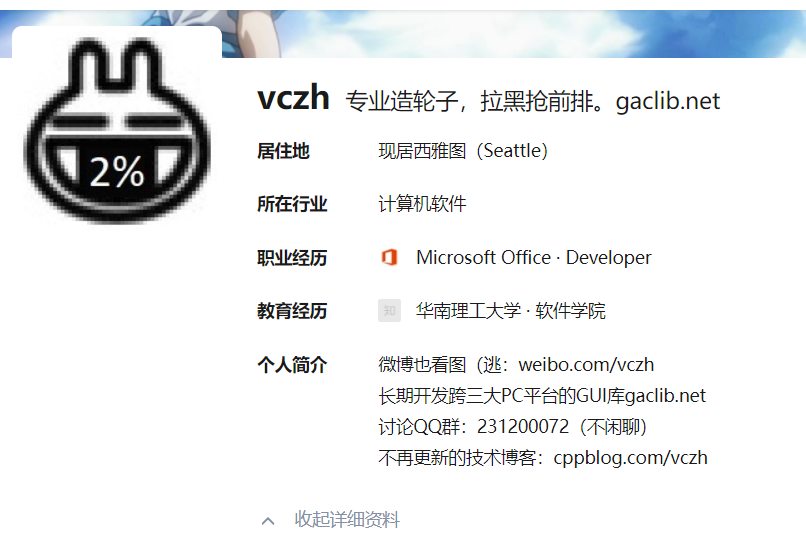
然后我们获取他关注的人和关注他的人的信息:
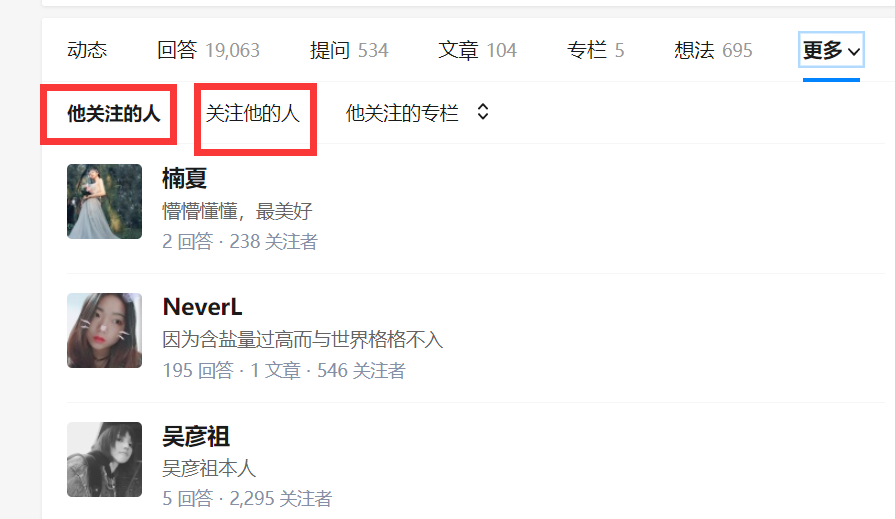
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
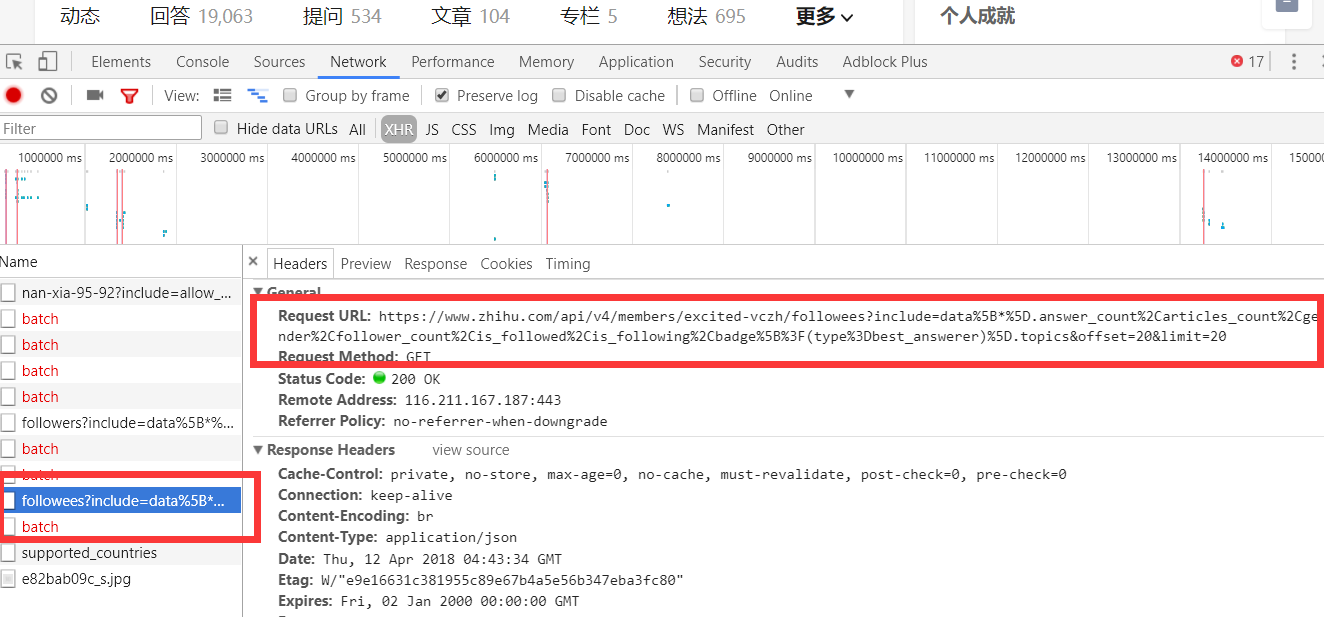
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个json数据,而这里就存着一页关乎的用户信息。
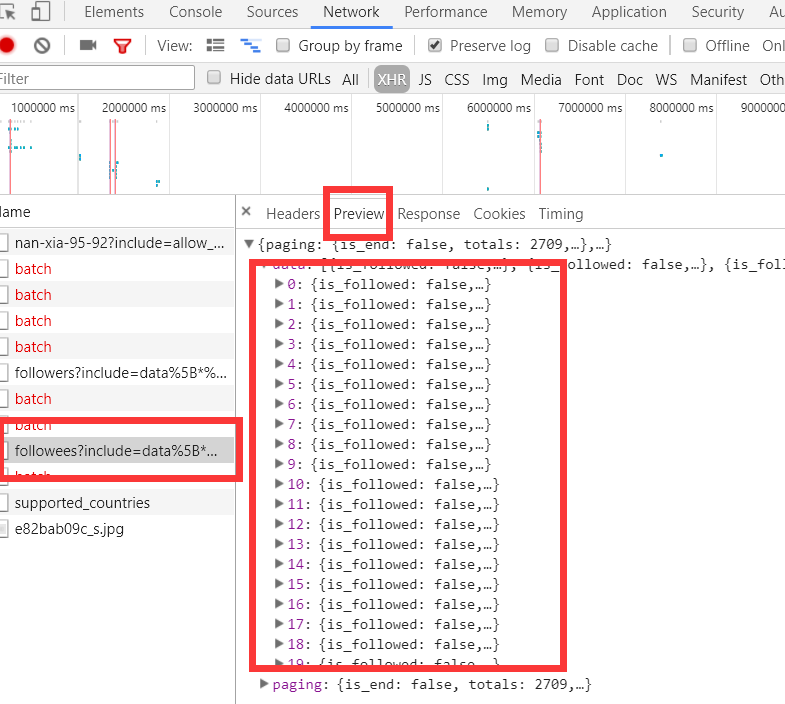
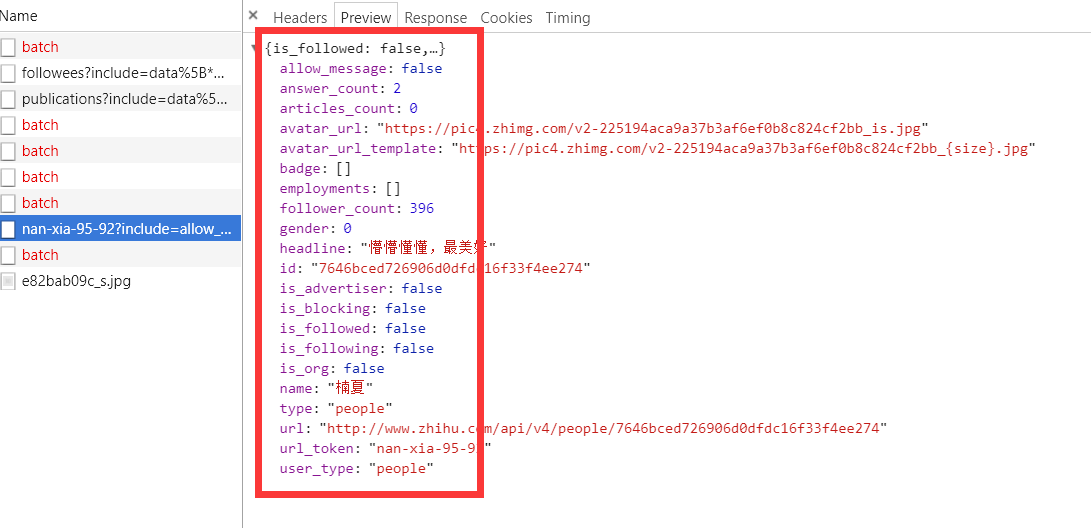
上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:

我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:
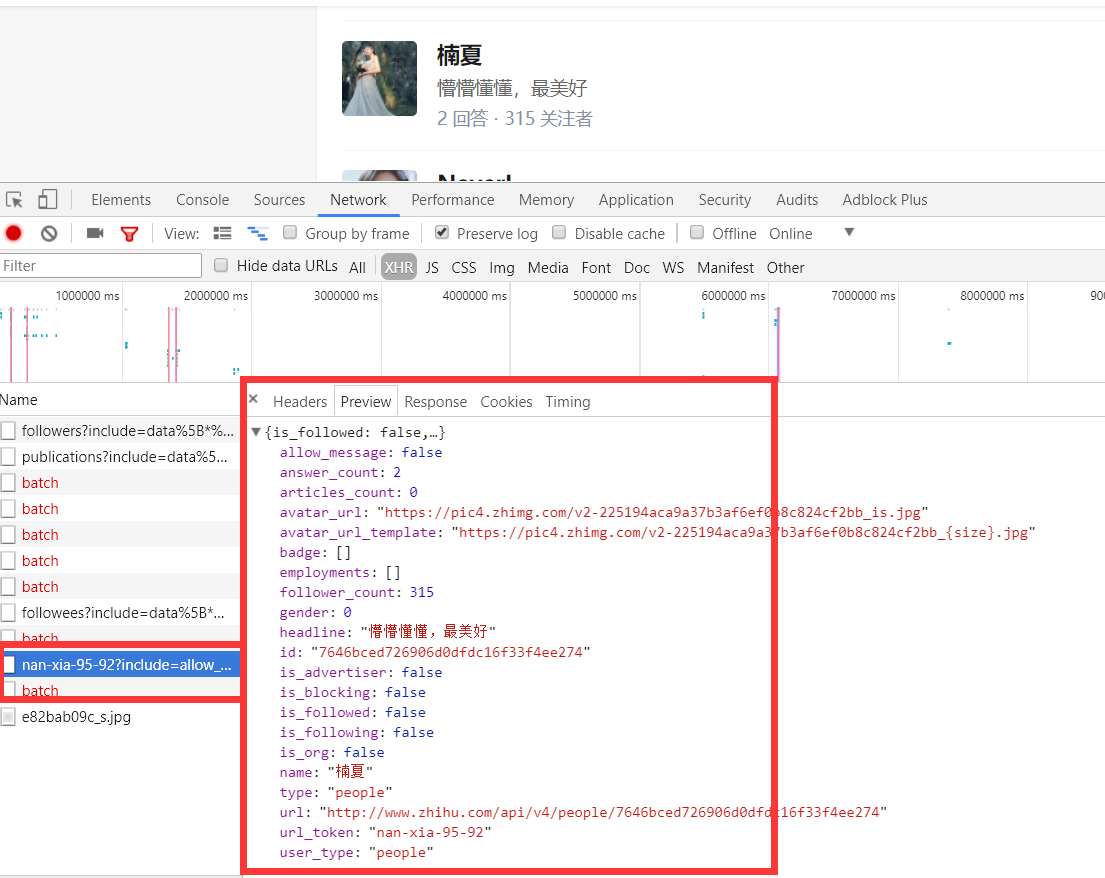
通过上面的分析我们知道了以下两个地址:
1关注列表:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
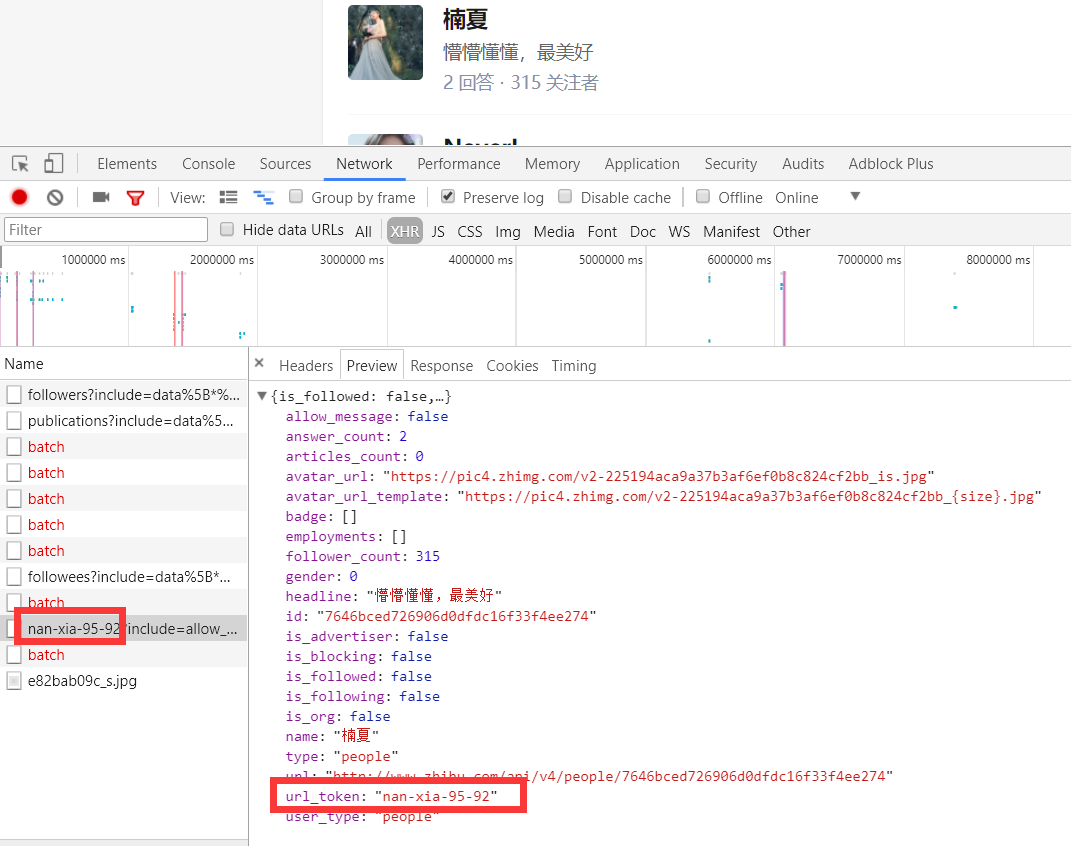
2、详情信息:https://www.zhihu.com/api/v4/members/nan-xia-95-92?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的url_token其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个url_token。
三:创建项目实战
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu zhihu.com
创建好后用pycharm打开:
更改settings文件:
# 是否遵循爬取规则,我们改成False
ROBOTSTXT_OBEY = False
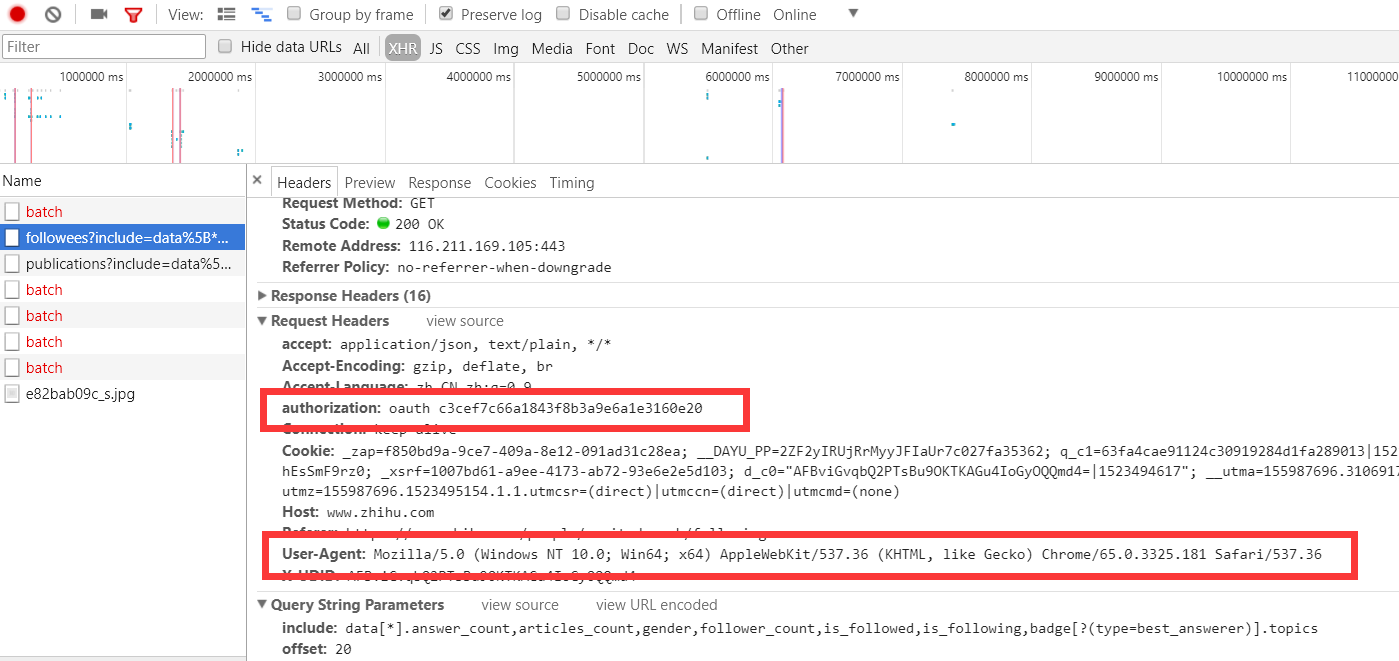
# 添加请求头信息,因为知乎默认检测请求头的 DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20',
}
四:代码实现
(1):items中的代码主要是我们要爬取的字段的定义
import scrapy class UserItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
name = scrapy.Field()
allow_message = scrapy.Field()
answer_count = scrapy.Field()
articles_count = scrapy.Field()
avatar_url = scrapy.Field()
avatar_url_template = scrapy.Field()
badge = scrapy.Field()
employments = scrapy.Field()
follower_count = scrapy.Field()
gender = scrapy.Field()
headline = scrapy.Field()
is_advertiser = scrapy.Field()
is_blocking = scrapy.Field()
is_followed = scrapy.Field()
is_following = scrapy.Field()
is_org = scrapy.Field()
type = scrapy.Field()
url = scrapy.Field()
url_token = scrapy.Field()
user_type = scrapy.Field()
(2):spiders中的主要代码
# -*- coding: utf-8 -*-
import json import scrapy from scrapy_zhihuuser.items import UserItem class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['zhihu.com']
start_urls = ['http://zhihu.com/'] # 起始的大V账号
start_user = 'excited-vczh' # 这里把查询的参数单独存储为user_query,user_url存储的为查询用户信息的url地址
user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics' # #follows_url存储的为关注列表的url地址,fllows_query存储的为查询参数。这里涉及到offset和limit是关于翻页的参数,0,20表示第一页
follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}'
follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' # #followers_url是获取粉丝列表信息的url地址,followers_query存储的为查询参数。
followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' # 第一次访问的方法重写
def start_requests(self):
"""
这里重写了start_requests方法,分别请求了用户查询的url和关注列表的查询以及粉丝列表信息查询
:return:
"""
yield scrapy.Request(self.user_url.format(user=self.start_user, include=self.user_query),
callback=self.parse_user)
yield scrapy.Request(
self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20),
callback=self.parse_follows)
yield scrapy.Request(
self.follows_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20),
callback=self.parse_followers) def parse_user(self, response):
"""
因为返回的是json格式的数据,所以这里直接通过json.loads获取结果
:param response:
:return:
"""
result = json.loads(response.text)
item = UserItem()
# 这里循环判断获取的字段是否在自己定义的字段中,然后进行赋值
for field in item.fields:
if field in result.keys():
item[field] = result.get(field)
# 这里在返回item的同时返回Request请求,继续递归拿关注用户信息的用户获取他们的关注列表
yield item
yield scrapy.Request(
self.follows_url.format(user=result.get("url_token"), include=self.follows_query, offset=0, limit=20),
callback=self.parse_follows)
yield scrapy.Request(
self.followers_url.format(user=result.get("url_token"), include=self.followers_query, offset=0, limit=20),
callback=self.parse_followers) def parse_follows(self, response):
# 用户关注列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息
results = json.loads(response.text)
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query),
self.parse_user)
# 这里判断page是否存在并且判断page里的参数is_end判断是否为False,如果为False表示不是最后一页,否则则是最后一页
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
# 获取下一页的地址然后通过yield继续返回Request请求,继续请求自己再次获取下页中的信息
yield scrapy.Request(next_page, self.parse_follows) def parse_followers(self, response):
"""
这里其实和关乎列表的处理方法是一样的
用户粉丝列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息
:param response:
:return:
""" results = json.loads(response.text)
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query),
self.parse_user)
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, self.parse_followers)
关于上面爬虫的简单描述:
1. 当重写start_requests,一会有三个yield,分别的回调函数调用了parse_user,parse_follows,parse_followers,这是第一次会分别获取我们所选取的大V的信息以及关注列表信息和粉丝列表信息
2. 而parse分别会再次回调parse_follows和parse_followers信息,分别递归获取每个用户的关注列表信息和分析列表信息
3. parse_follows获取关注列表里的每个用户的信息回调了parse_user,并进行翻页获取回调了自己parse_follows
4. parse_followers获取粉丝列表里的每个用户的信息回调了parse_user,并进行翻页获取回调了自己parse_followers
(3):关于数据存储到mongodb
更改pipeline代码:
import pymongo class MongoPipeline(object):
collection_name = 'scrapy_items' def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler):
return cls(
# 在settings中定义数据库相关的操作
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
) def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def close_spider(self, spider):
self.client.close() def process_item(self, item, spider):
self.db['user'].update({'url_token': item['url_token']}, {'$set': item}, True) # 更新去重
# self.db[self.collection_name].insert_one(dict(item))
return item
项目代码--》GitHub地址
爬虫(十六):scrapy爬取知乎用户信息的更多相关文章
- 爬虫实战--利用Scrapy爬取知乎用户信息
思路: 主要逻辑图:
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- Srapy 爬取知乎用户信息
今天用scrapy框架爬取一下所有知乎用户的信息.道理很简单,找一个知乎大V(就是粉丝和关注量都很多的那种),找到他的粉丝和他关注的人的信息,然后分别再找这些人的粉丝和关注的人的信息,层层递进,这样下 ...
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
随机推荐
- 使用Docker发布Asp.Net Core程序到Linux
CentOS安装Docker 按照docker官方文档来,如果有之前安装过旧版,先卸载旧版,没有的话,可跳过. sudo yum remove docker \ docker-client \ doc ...
- 数据多的时候为什么要使用redis而不用mysql?
2018-06-28 136465569... 转自 庆亮trj21bc... 修改 微信 分享: Redis和MySQL的应用场景是不同的. 通常来说,没有说用Redis就不用MySQL的这 ...
- rem em min-width: 30em 的意思
30em=30rem=30x16px=480px @media only screen and (min-width:30 em){ }
- Chrome安装crx文件的插件时出现“程序包无效”
有趣的事,Python永远不会缺席! 如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/11043453.html 链接:https: ...
- 开始Swift学习之路
Swift出来好几个月了,除了同事分享点知识外,对swift还真没有去关心过.GitHub上整理的学习Swift资料还是很不错的,目前也推出了电子书和PDF格式. Swift的语法和我们平常开发的语言 ...
- 善用#waring,#pragma mark 标记
在项目开发中,我们不可能对着需求一口气将代码都写好.开发过程中肯定遇到诸如需求变动,业务逻辑沟通,运行环境的切换等这些问题.当项目大的时候,如果木有形成统一的代码规范,在项目交接和开发人员沟通上将会带 ...
- cell上的按钮点击和左滑冲突
cell上的某个按钮的点击事件,当cell左滑的时候,只要活动的区域也在按钮上,那么按钮的点击事件也会调用. fix: 给按钮添加一个手势(TapGesture)那么当点击的时候就会响应点击手势的方法 ...
- SDL图解
1.什么是SDL 2.为什么要用SDL 3.SDL由哪几个阶段组成 用于规范公司web应用开发流程:安全需求分析.代码检查.安全测试... 4.微软的SDL实施流程
- windows和linux下的spice客户端使用方法
1.Linux客户端 安装spice yum install virt-viewer 连接远程虚拟机 #remote-viewer spice://IP:PORTremote-viewer spice ...
- Linux用ctrl + r 查找以前(历史)输入的命令
在Linux系统下一直用上下键查找以前输入的命令,这个找刚输入不久的命令还是很方便的,但是比较久远的命令,用上下键效率就不高了.那个history命令也是个花架子,虽然功能多,但不好用,网上找了下,发 ...