十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式
urllib库中使用xpath表达式
etree.HTML()将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式

#!/usr/bin/env python
# -*- coding:utf8 -*-
import urllib.request
from lxml import etree #导入html树形结构转换模块 wye = urllib.request.urlopen('http://sh.qihoo.com/pc/home').read().decode("utf-8",'ignore')
zhuanh = etree.HTML(wye) #将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
print(zhuanh)
hqq = zhuanh.xpath('/html/head/title/text()') #通过xpath表达式获取标题 #注意,xpath表达式获取到数据,有时候是列表,有时候不是列表所以要做如下处理
if str(type(hqq)) == "<class 'list'>": #判断获取到的是否是列表
print(hqq)
else:
xh_hqq = [i for i in hqq] #如果不是列表,循环数据组合成列表
print(xh_hqq) #返回 :['【今日爆点】你的专属资讯平台']
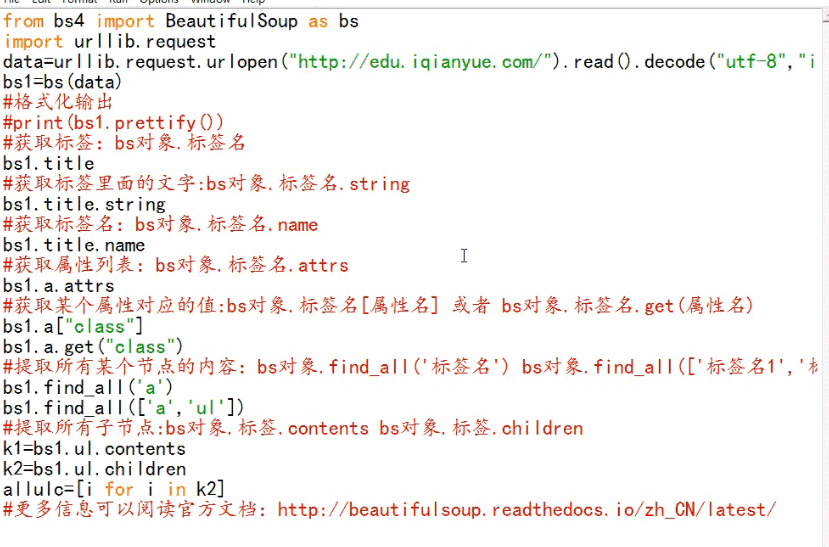
BeautifulSoup基础
BeautifulSoup是获取thml元素的模块
BeautifulSoup-3.2.1版本
十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础的更多相关文章
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- 六 web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 ...
- 九 web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块 #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib from urllib import request import j ...
- 八 web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener()初始化IPinstall_opener()将代理IP设置成全 ...
- 七 web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执行下去 1.常见状态吗 301:重定向到新的URL,永久性302:重定向到临时URL,非永久性304: ...
随机推荐
- 关联规则之Apriori
1.关联规则原理 1.关联规则概述 关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,如果两个或多个事物之间存在一定的关联关系,那么,其中一个事物就能通过 ...
- 264. Ugly Number II(丑数 剑指offer 34)
Write a program to find the n-th ugly number. Ugly numbers are positive numbers whose prime factors ...
- hdu6194 string string string
地址:http://acm.split.hdu.edu.cn/showproblem.php?pid=6194 题目: string string string Time Limit: 2000/10 ...
- rmp-st算法
struct RMQ { ]; void init(int n) { ; i <= n; i ++)log2[i] = (i == ? - : log2[i >> ] + ); ; ...
- 2016-2017 National Taiwan University World Final Team Selection Contest J - Zero Game
题目: You are given one string S consisting of only '0' and '1'. You are bored, so you start to play w ...
- I.MX6中PC连接开发板问题
修改板端的文件 添加登录密码: passwd vi /etc/network/interrfaces 在auto eth0下增加auto eth1 如果采用固定ip方式可以在后面增加一段固定ip设置 ...
- Kafka学习之(一)了解一下Kafka及关键概念和处理机制
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模小打的网站中所有动作流数据.优势 高吞吐量:非常普通的硬件Kafka也可以支持每秒100W的消息,即使在非常廉价的商用机器上也能做 ...
- WCF的异步调用
1.服务契约 namespace Contracts { [ServiceContract] public interface ICalculator { [OperationContract] do ...
- flume从log4j收集日志输出到kafka
1. flume安装 (1)下载:wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.1.tar.gz (2)解压:ta ...
- 为什么Eureka Client获取服务实例这么慢
1. Eureka Client注册延迟 Eureka Client启动后不会立即向Eureka Server注册,而是有一个延迟时间,默认为40s 2. Eureka Server更新响应缓存 Eu ...