XV6操作系统代码阅读心得(四):虚拟内存
本文将会详细介绍Xv6操作系统中虚拟内存的初始化过程。
基本概念
32位X86体系结构采用二级页表来管理虚拟内存。之所以使用二级页表, 是为了节省页表所占用的内存,因为没有内存映射的二级页表可以不用分配地址来存储。在这个二级页表结构中,每个页的大小为4KB,每个页表的大小也为4KB,每个页表项的大小为4字节,一个页表包含1024个页表项。一级页表表项存储的是二级页表的地址,二级页表表项存储的是对应的物理地址。虚拟地址和物理地址的最后12位总是相同,因此页表表项中的这12位可以被用作标记其他信息。对于一个32位虚拟地址,可以通过前10位来找到其对应的一级页表表项的索引,读出二级页表表项的地址,并通过访问二级页表,得到对应的物理地址。显然,这样会使得一次虚拟内存的访问变成三次物理内存的访问,为了最小化其性能影响,CPU中额外有TLB缓存会缓存最近访问的虚拟地址所对应的页表项。虚拟地址到物理地址的转换图如下
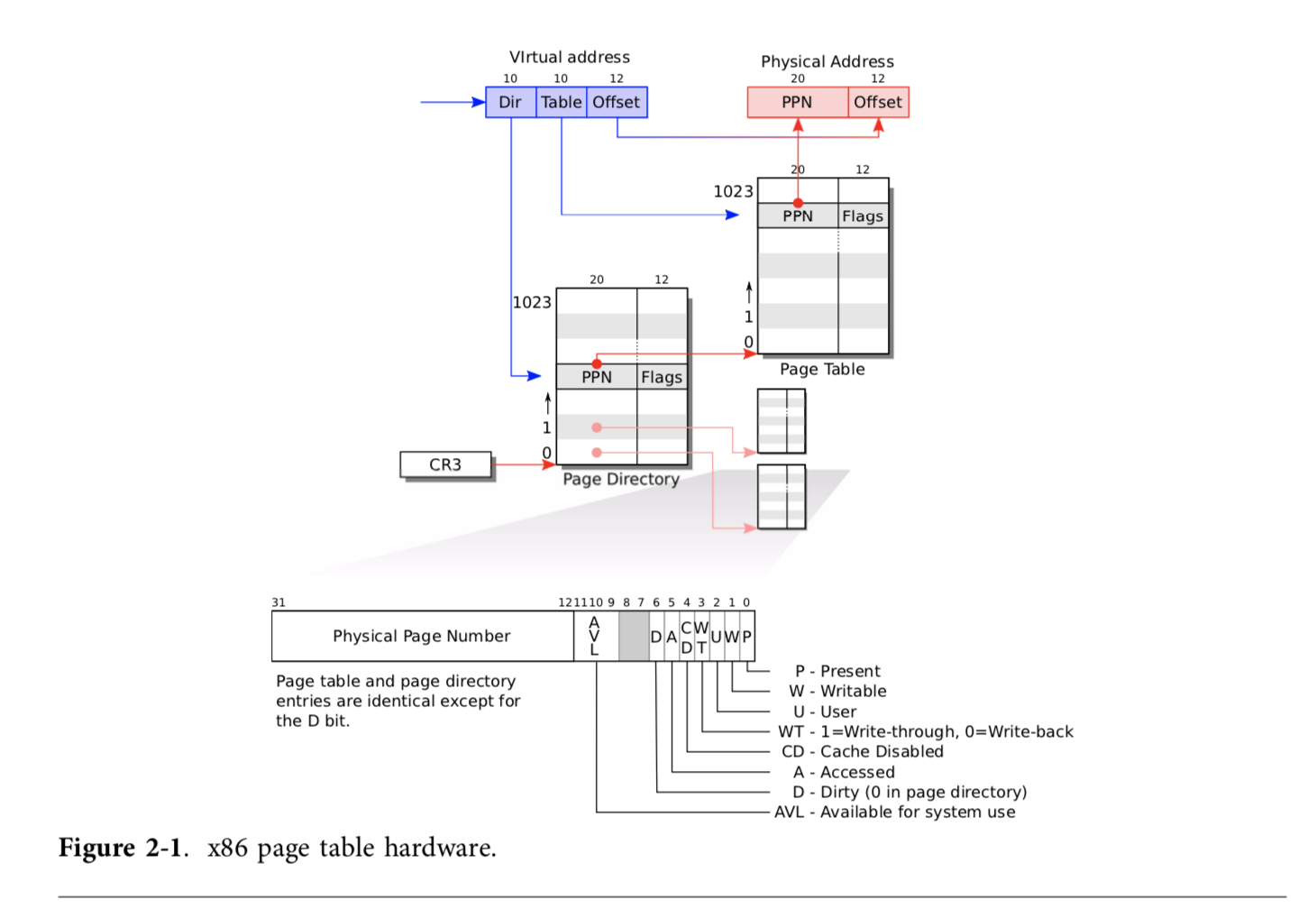
X86还额外支持4MB大页模式,让一个一级页表表项直接映射到4MB大小的页。有些情况下,这样分配会更加方便。后文会提到Xv6系统初始化时,会使用到4MB大页。
需要注意的是,虚拟地址到物理地址的映射过程是由硬件完成的,不是由某个函数完成的。硬件通过cr3控制寄存器中的一级页表地址取出对应的页表表项,自动完成虚拟地址的翻译,操作系统只负责初始化页表、设置控制寄存器和设置正确的页表表项的值。
main()函数执行前内存的情况
物理地址的内容
0x0000-0x7c00 引导程序的栈0x7c00-0x7d00 引导程序的代码(512字节)0x10000-0x11000 内核ELF文件头(4096字节)0xA0000-0x100000 设备区0x100000-0x400000 Xv6操作系统(未用满)
执行到main.c中的main()函数开头时,物理地址的具体内容如上。这里面引导程序是由BIOS负责载入内存,设备区是硬件规定占用的区域,而内核ELF文件头和Xv6操作系统是由引导程序(bootmain.c)加载进内存的。
全局描述符表的内容
| 索引 | 条目内容 | 条目含义 |
|---|---|---|
| [0] | 0 | 空条目 |
| [1] | SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) |
内核代码段 |
| [2] | SEG_ASM(STA_W, 0x0, 0xffffffff) |
内核数据段 |
| [3] | 尚未设置 | 用户代码段 |
| [4] | 尚未设置 | 用户数据段 |
| [5] | 尚未设置 | Task State Segment |
X86体系结构中,全局描述符表用于分段管理内存。为了可移植性,类Unix一般只会以最少的方式使用全局描述符表对内存进行分段。在main.c里的初始化函数执行前,全局描述符表的内容如上。IA32体系结构中使用cs、ds、ss、es寄存器存放段寄存器的索引。此时cs寄存器存的索引值是1,ds,ss,es存的索引值是2,对应内核数据段和内核代码段。除了权限不同外,两个条目的内容完全相同,都是将基地址设为0,最大偏移设为4GB,这样就和一般的32位直接寻址使用起来一样了。
在main.c中,操作系统还会调用seginit()函数重新设置全局描述符表,并补充未设置的内容。Task State Segment会在第一个用户进程被创建时设置(具体是在switchuvm()函数中)。
页表的内容
在进入entry.S之前,系统是运行在段寻址模式下的,entry.S中设置了初始的页表并进入基于页表的虚拟寻址模式,页大小为4MB,初始的一级页表声明如下
__attribute__((__aligned__(PGSIZE)))pde_t entrypgdir[NPDENTRIES] = {// Map VA's [0, 4MB) to PA's [0, 4MB)[0] = (0) | PTE_P | PTE_W | PTE_PS,// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS,};
注释中解释了初始的虚拟地址到物理地址的映射关系。KERNBASE为0x80000000。PTE_P表示这个页表项存在,PTE_W表示可写,PTE_PS表示这是4MB大页,没有设置PTE_U,表明这是内核页。注意其中用于内核区域的页只有一个,因此这就限制了内核代码段+数据段的总大小不能超过4MB(实际上是3MB,因为0x0-0x100000的物理地址在启动时被使用,且被设备区占用,实际的内核从物理地址0x100000开始)。
这只是一个初始的页表,在之后的main函数中会重新建立新的页表,并把这个页表丢弃。
Xv6对虚拟内存页的管理
管理虚拟内存页的代码在kalloc.c中。kalloc.c的内存管理思想是把所有可用的空闲内存页串在一起形成一个大链表。每当有内存页被释放时,就将这个内存页加入这个链表(kfree()函数);分配内存页时,就从链表头部取出一个内存页返回(kalloc()函数)。这个内存分配器必须知道它要负责管理的内存范围,并在初始化时将整个物理地址空间都纳入其管理范围。后文会提到,一开始,这个内存分配器管理的物理内存空间是[end, 0x400000],然后会扩展到[end, 0xE00000]。这就暗含了一个假设,就是物理地址0xE00000必须存在,这就要求Xv6锁运行的系统至少拥有240MB的内存。
用于内存页管理的数据结构定义如下
struct {struct spinlock lock;int use_lock;struct run *freelist;} kmem;
一开始,锁是没有启动的,直到main()函数调用了kvinit2()之后锁才会被使用,因为从这里之后可能会有多个进程和多个处理器并发地访问这个数据结构。 struct run *freelist就是空闲链表的声明。
对于每一个空内存页,因为这个内存页是空的,所以Xv6可以使用前4个字节来保存指向下一个空内存页的地址。因此,一个空内存页的定义如下
struct run {struct run *next;};
具体对应到添加和删除操作如下(注意其中的强制类型转换)
// In kfree()// Add virtual page v to freelistr = (struct run*)v;r->next = kmem.freelist;kmem.freelist = r;// In kalloc()// Return a free page r and remove r from listr = kmem.freelist;if(r) kmem.freelist = r->next;
kalloc()和kfree()函数的具体实现中还有一些关于锁和错误检查的细节,在此略去。
在使用这个内存分配器时,使用kfree()就可以向其中添加空闲的内存页,使用kalloc()就可以从中请求一个内存页。
main()函数中虚拟内存的初始化过程
Xv6系统使用end指针来标记Xv6的ELF文件所标记的结尾位置,这样,[PGROUNDUP(end), 0x400000]范围内的物理内存页是可以被用作内存页分配的。Xv6调用kinit1(end, P2V(0x400000))来首先将这部分内存纳入虚拟内存页管理。虽然这部分在之前的页表中已经被映射为4MB大页,但是我们的目标是建立一个新的页表,这个页表使用的页大小为4KB。由于这部分内存已经被分配为一个4MB内存大页,且硬件已经会自动执行虚拟内存地址翻译,故需要使用P2V()函数将物理地址转换为虚拟地址。之后的代码里还会存在很多这样的虚拟地址到物理地址的转换。
Xv6的内存分配器必须知道它要负责管理的内存范围。由于此时虚拟内存已经开启,且页表表项只有两条,因此Xv6必须利用已有的虚拟地址空间,在其中创建新的页表。这就是main()函数中kinit1()和kvmalloc()所做的事情。
kinit1()函数会调用freerange()函数,按照前文叙述的方式,建立从PGROUNDUP(end)地址开始直到0x400000为止的全部内存页的链表。这样,我们得到了第一组可以使用的虚拟内存页,然后内核就可以运行kvmalloc()使用这些内存页了。kvmalloc()函数获得一个虚拟内存页并将其初始化一级页表。这个一级页表的内容在vm.c中的kmap处被定义,具体内容如下
| 虚拟地址 | 映射到物理地址 | 内容 |
|---|---|---|
| [0x80000000, 0x80100000] | [0, 0x100000] | I/O设备 |
| [0x80100000, 0x80000000+data] | [0x100000, data] | 内核代码和只读数据 |
| [0x80000000+data, 0x80E00000] | [data, 0xE00000] | 内核数据+可用物理内存 |
| [0xFE000000, 0] | [0xFE000000, 0] | 其他通过内存映射的I/O设备 |
注意以上映射规则会被生成为x86所要求的对应一级页表和二级页表。需要的时候,kvmalloc()函数所调用的walkpgdir()函数会申请新的内存页用作二级页表。
之后,main()函数会调用seginit()函数重新设置GDT。新的GDT与之前的GDT的主要区别在于设置了用户数据段和用户代码段。虽然这些段依然是对32位偏移进行直接映射,但其执行权限与内核的段有所不同。GDT中的TSS表项直到第一个用户进程创立时才会被设置,并且其内容会随着当前用户进程的切换而改变。
最后,main()函数会调用kinit2()将[0x400000, 0xE00000]范围内的物理地址纳入到内存页管理之中。至此,Xv6的内存页管理系统和内核页表已经全部建立完毕。需要注意的是,这个内核页表(kpgdir变量)只会在调度器运行时被使用。对于每一个用户进程,都会拥有自己独自的完整页表,其中也包含了一份一模一样的内核页表。
下面我们来看看第一个用户进程的虚拟地址空间是如何初始化的。main()函数在kinit2()之后紧接着调用userinit()来初始化第一个用户进程。userinit()在完成有关进程数据结构管理的工作后,会初始化这个进程自己的页表(struct proc中的pgdir)。首先,userinit()会使用setupkvm()生成与前述一模一样的内核页表,然后使用inituvm()生成第一个用户内存页(映射到虚拟地址0x0),并将用户进程初始化代码移动至这个内存页中(这就要求初始化代码不能超过4KB,初始化代码参见initcode.S)。
initcode.S中包含了一个exec系统调用,通过这个系统调用来加载进一个真正的用户进程。exec系统调用的实现在exec.c中。exec会从磁盘里加载一个ELF文件。ELF文件中包含了所有代码段和数据段的信息,并且描述了这些段应该被加载到的虚拟地址(这是在编译时就已经确定好的,所以编译器必须遵循某些约定来分配这些虚拟地址)。
最后,exec会分配两个虚拟内存页,第一个页设置为不可访问,第二个页用作用户栈。由于栈是从上往下增长的,所以当栈的大小超过一个页(4KB)时,会触发错误,因此Xv6系统的用户进程最多只能使用4KB的栈。
最终的虚拟内存布局
这里我们列出init进程的页表中所记录的全部虚拟地址到物理地址的映射关系。每一个用户进程都有一个这样的页表。其中,有关内核的部分(也就是最后四项)对于所有用户进程都是一样的,而前面的映射会有所不同,表中的信息根据init的进程的ELF文件信息和exec调用的代码确定。
| 虚拟地址 | 映射到物理地址 | 内容 |
|---|---|---|
| [0x0, 0x1000] | 由分配器提供的地址 | 用户进程的代码和数据 |
| [0x1000, 0x2000] | 由分配器提供的地址 | 不可访问页,用于检测栈溢出 |
| [0x2000, 0x3000] | 由分配器提供的地址 | 用户进程的栈 |
| [0x80000000, 0x80100000] | [0, 0x100000] | I/O设备 |
| [0x80100000, 0x80000000+data] | [0x100000, data] | 内核代码和只读数据 |
| [0x80000000+data, 0x80E00000] | [data, 0xE00000] | 内核数据+可用物理内存 |
| [0xFE000000, 0] | [0xFE000000, 0] | 其他通过内存映射的I/O设备 |
中断、进程调度与虚拟内存
中断发生时,使用的的页表依然是对应用户进程的页表。由于每一个用户进程都有一份一模一样的内核页表条目,因此陷入的内核代码依然可以正常执行。只有当中断处理程序决定退出当前进程或者切换到其他进程时,当前页表才会被切换为调度器的页表(全局变量kpgdir),并在调度器中切换为新进程的页表。
XV6操作系统代码阅读心得(四):虚拟内存的更多相关文章
- XV6操作系统代码阅读心得(一):启动加载、中断与系统调用
XV6操作系统是MIT 6.828课程中使用的教学操作系统,是在现代硬件上对Unix V6系统的重写.XV6总共只有一万多行,非常适合初学者用于学习和实践操作系统相关知识. MIT 6.828的课程网 ...
- XV6操作系统代码阅读心得(二):进程
1. 进程的基本概念 从抽象的意义来说,进程是指一个正在运行的程序的实例,而线程是一个CPU指令执行流的最小单位.进程是操作系统资源分配的最小单位,线程是操作系统中调度的最小单位.从实现的角度上讲,X ...
- XV6操作系统代码阅读心得(三):锁
锁是操作系统中实现进程同步的重要机制. 基本概念 临界区(Critical Section)是指对共享数据进行访问与操作的代码区域.所谓共享数据,就是可能有多个代码执行流并发地执行,并在执行中可能会同 ...
- XV6操作系统代码阅读心得(五):文件系统
Unix文件系统 当今的Unix文件系统(Unix File System, UFS)起源于Berkeley Fast File System.和所有的文件系统一样,Unix文件系统是以块(Block ...
- VINS-Fusion代码阅读(四)
pts_i和pts_j:具体指什么含义?(分别为第l个路标点在第i, j个相机归一化相机坐标系中的观察到的坐标,P¯¯¯cil \bar{P}^{c_i}_l Pˉ lc i 和 P¯¯¯cjl ...
- 【原】AFNetworking源码阅读(四)
[原]AFNetworking源码阅读(四) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇还遗留了很多问题,包括AFURLSessionManagerTaskDe ...
- 【原】SDWebImage源码阅读(四)
[原]SDWebImage源码阅读(四) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 SDWebImage中主要实现了NSURLConnectionDataDelega ...
- 代码阅读分析工具Understand 2.0试用
Understand 2.0是一款源代码阅读分析软件,功能强大.试用过一段时间后,感觉相当不错,确实可以大大提高代码阅读效率.由于Understand功能十分强大,本文不可能详尽地介绍它的所有功能,所 ...
- Linux协议栈代码阅读笔记(二)网络接口的配置
Linux协议栈代码阅读笔记(二)网络接口的配置 (基于linux-2.6.11) (一)用户态通过C库函数ioctl进行网络接口的配置 例如,知名的ifconfig程序,就是通过C库函数sys_io ...
随机推荐
- bzoj 2375: 疯狂的涂色
2375: 疯狂的涂色 Time Limit: 5 Sec Memory Limit: 128 MB Description 小t非常喜爱画画,但是他还是一个初学者.他最近费尽千辛万苦才拜到已仙逝的 ...
- SSM框架使用-wrong
mybatis手册 1. mybatis 绑定错误 如果出现: org.apache.ibatis.binding.BindingException: Invalid bound statement ...
- dp ZOJ 3956
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3956 Course Selection System Time Limit ...
- asp.net DataTable导出 excel的方法记录(第三方)
官网:http://npoi.codeplex.com/ 简单应用,主要是可以实现我们想要的简单效果,呵呵 需要引入dll,可以在官网下载,也可在下面下载 protected void getExce ...
- 详解ASP.NET4 GridView的四种排序样式
与ASP.NET 的其他Web控件一能够,Gridview控件拥有很多不同的CSS样式属性设置,包括象CssClass,Font字体,ForeColor,BackColor,BackColor, Wi ...
- BestCoder Round #41 记。
大概整个过程都是很绝望的吧. 发现自己在七点之前是肯定搞不定网了..有冲动跑到机房去打 但是又不喜欢那样的气氛 这可是shi的场呢...好难过啊... 后来..好像是在和lyd讨论怎么把网络复原的过程 ...
- 【Atcoder】AGC 020 D - Min Max Repetition 二分+构造
[题意]定义f(A,B)为一个字符串,满足: 1.长度为A+B,含有A个‘A',B个'B'. 2.最长的相同字符子串最短. 3.在满足以上2条的情况下,字典序最小. 例如, f(2,3) = BABA ...
- python学习笔记(十)之格式化字符串
格式化字符串,可以使用format方法.format方法有两种形式参数,一种是位置参数,一种是关键字参数. >>> '{0} {1}'.format('Hello', 'Python ...
- bzoj 3522 tree-dp 暴力
首先我们知道,这个题可以N^2的做,我们先确定一个根,然后讨论下情况,合法的三个点只可能有三种情况,第一种是三个点有相同的lca,这种情况我们可以用tree-dp来解决,用dis[i][j]表示i为根 ...
- 「caffe编译bug」python/caffe/_caffe.cpp:10:31: fatal error: numpy/arrayobject.h: No such file or directory
在Makefile.config找到PYTHON_INCLUDE,发现有点不同: PYTHON_INCLUDE := /usr/include/python2.7 \ /usr/lib ...