Attention is all you need 论文详解(转)
一、背景
自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型。传统的基于RNN的Seq2Seq模型难以处理长序列的句子,无法实现并行,并且面临对齐的问题。
所以之后这类模型的发展大多数从三个方面入手:
input的方向性:单向 -> 双向
深度:单层 -> 多层
类型:RNN -> LSTM GRU
但是依旧收到一些潜在问题的制约,神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量。这可能使得神经网络难以应付长时间的句子,特别是那些比训练语料库中的句子更长的句子;每个时间步的输出需要依赖于前面时间步的输出,这使得模型没有办法并行,效率低;仍然面临对齐问题。
再然后CNN由计算机视觉也被引入到deep NLP中,CNN不能直接用于处理变长的序列样本但可以实现并行计算。完全基于CNN的Seq2Seq模型虽然可以并行实现,但非常占内存,很多的trick,大数据量上参数调整并不容易。
本篇文章创新点在于抛弃了之前传统的encoder-decoder模型必须结合cnn或者rnn的固有模式,只用Attention。文章的主要目的在于减少计算量和提高并行效率的同时不损害最终的实验结果。
二、整体框架
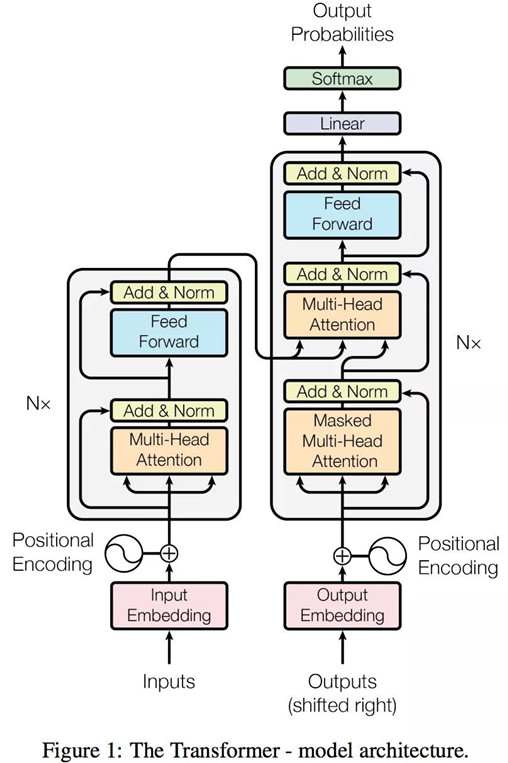
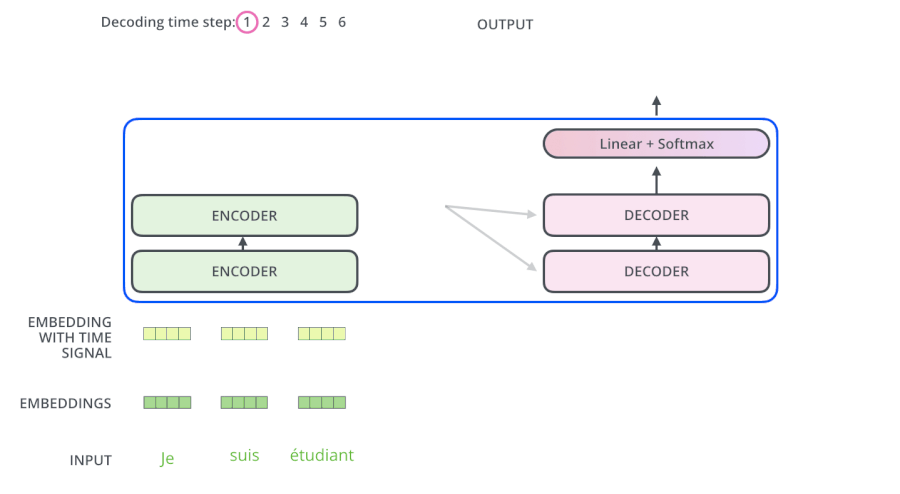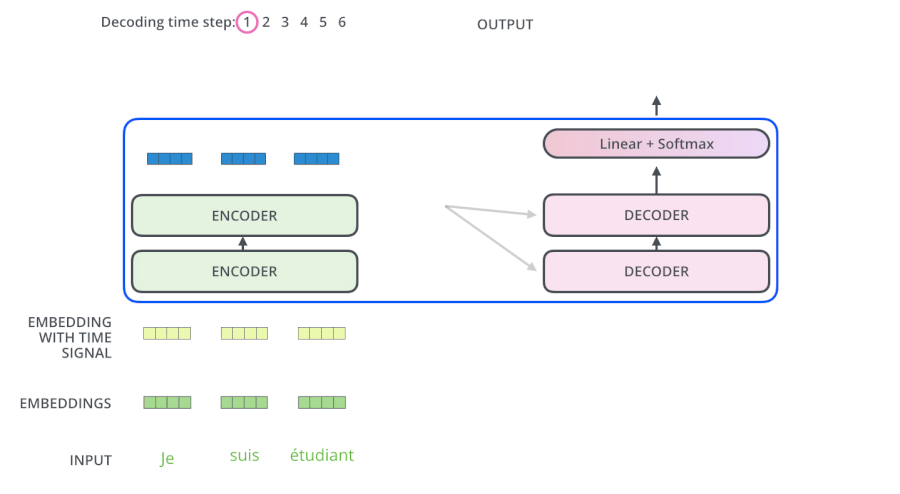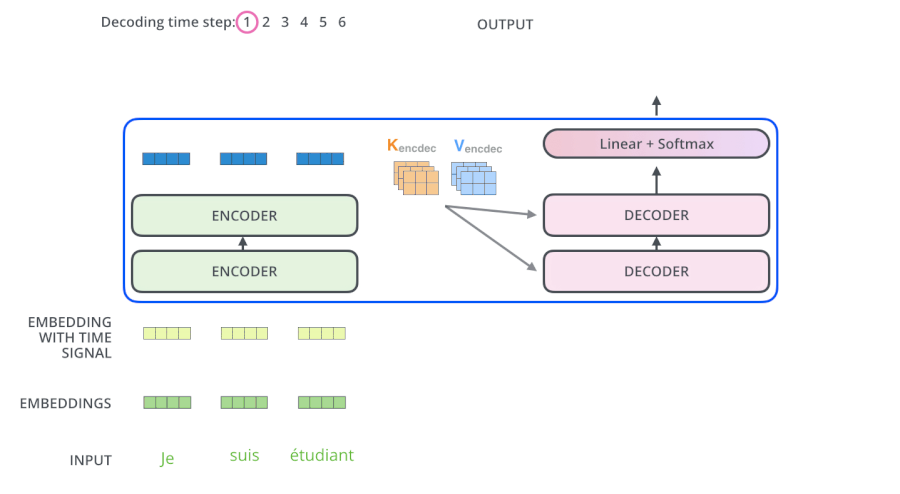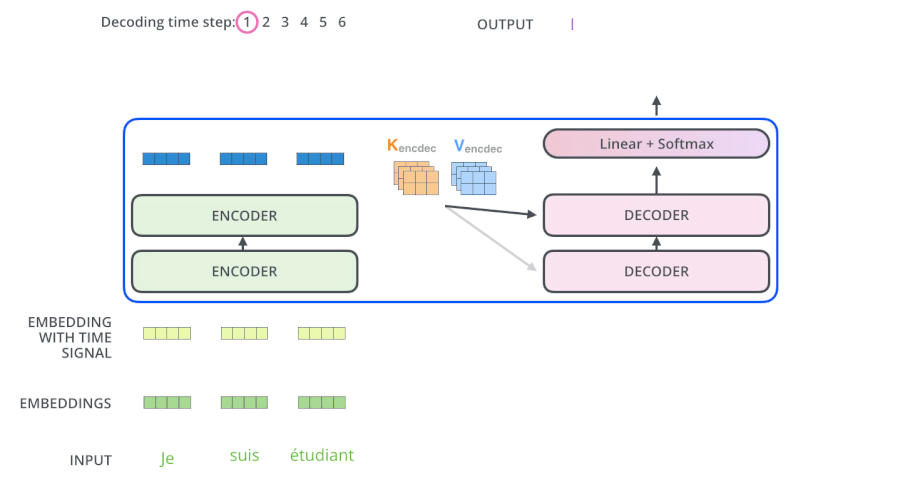
整体模型看上去看上去很复杂,其实这就是一个Seq2Seq模型,左边一个encoder把输入读进去,右边一个decoder得到输出:
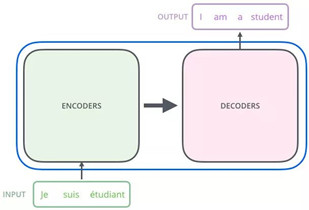
左边的encoders和右边的decoders都是由6层组成,内部左边encoder的输出是怎么和右边decoder结合的呢?再画张图直观的看就是这样:

三、分别展开
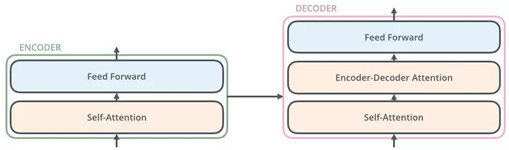
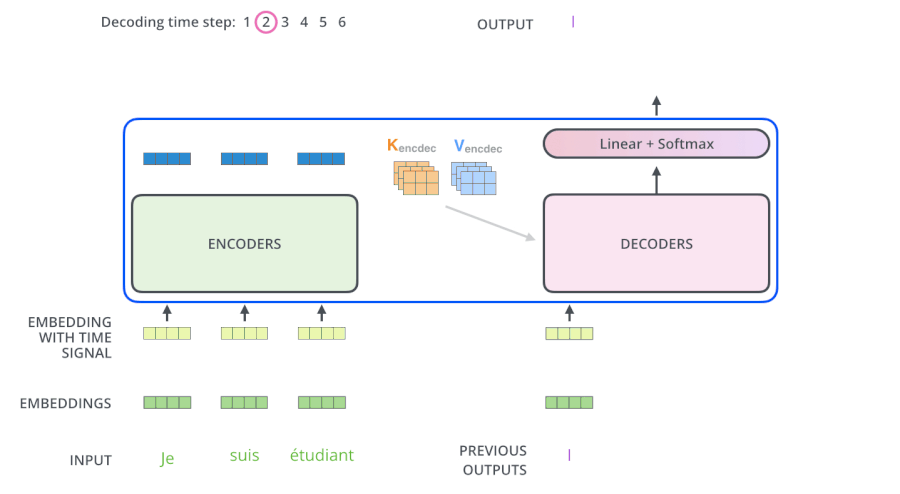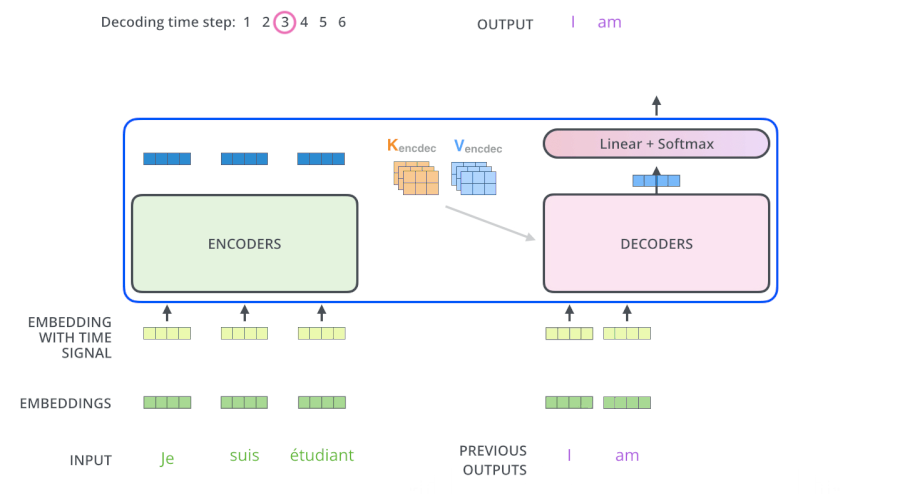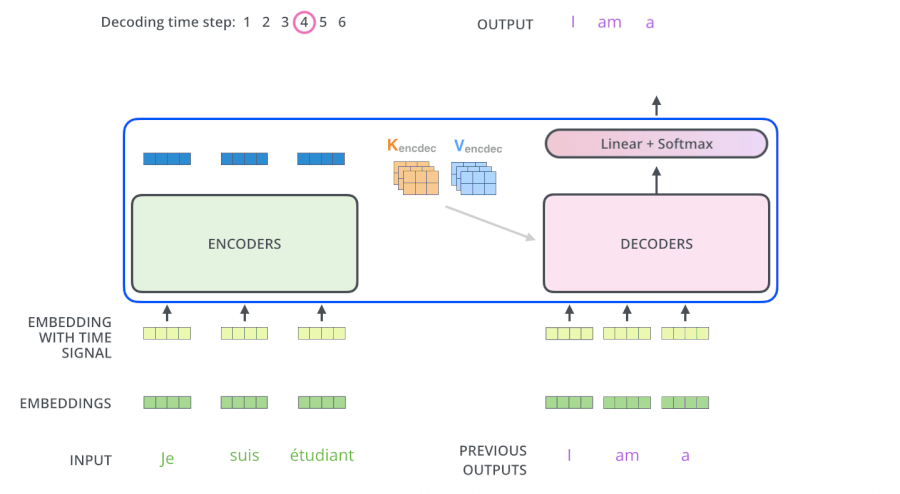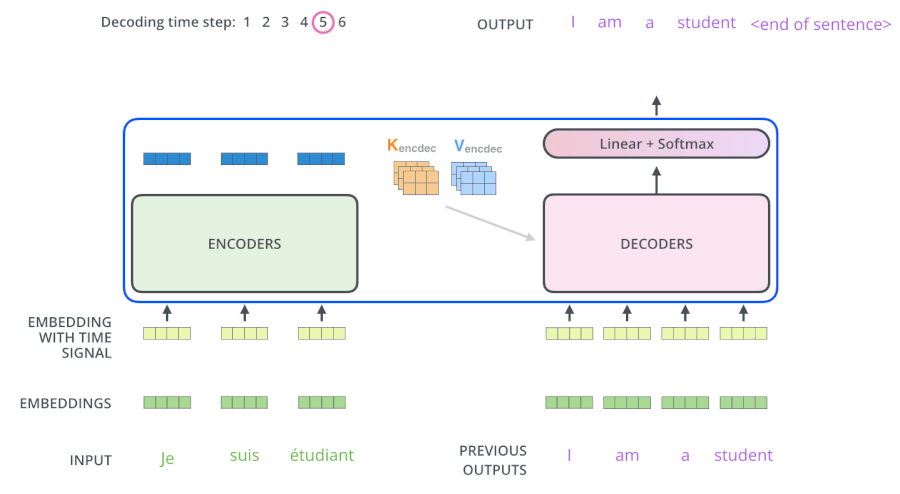
从上面可知,Encoder的输出,会和每一层的Decoder进行结合。我们取其中一层进行详细的展示:
整体框架细节展示:
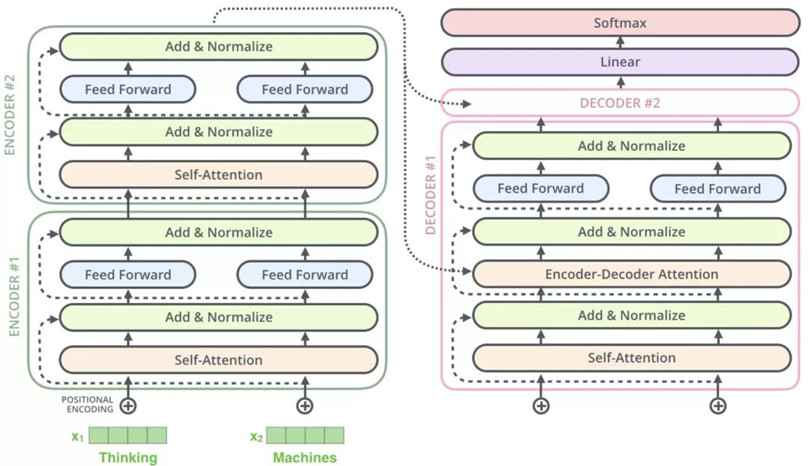
1)Encoder
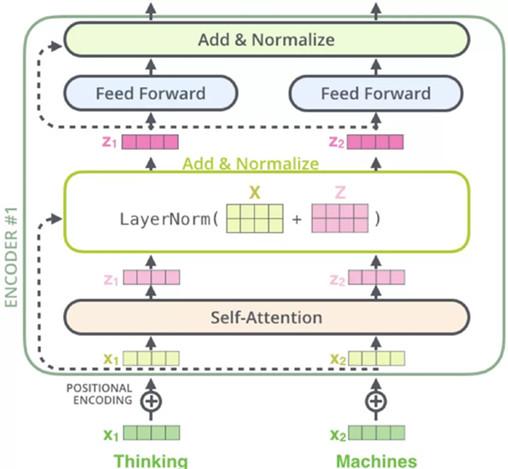
Encoder有N=6层,每层包括两个sub-layers:
第一个sub-layer是multi-head self-attention mechanism,用来计算输入的self-attention
第二个sub-layer是简单的全连接网络。
在每个sub-layer我们都模拟了残差网络,每个sub-layer的输出都是:

其中Sublayer(x) 表示Sub-layer对输入 x 做的映射,为了确保连接,所有的sub-layers和embedding layer输出的维数都相同。
2)Decoder
Decoder也是N=6层,每层包括3个sub-layers:
第一个是Masked multi-head self-attention,也是计算输入的self-attention,但是因为是生成过程,因此在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask
第二个sub-layer是全连接网络,与Encoder相同
第三个sub-layer是对encoder的输入进行attention计算。
同时Decoder中的self-attention层需要进行修改,因为只能获取到当前时刻之前的输入,因此只对时刻 t 之前的时刻输入进行attention计算,这也称为Mask操作。
图示参考上述总体框架细节图
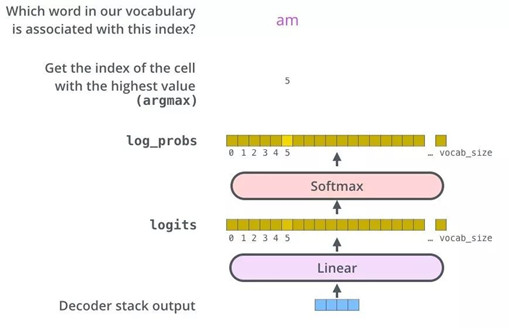
3)The Final Linear and Softmax Layer
4) Position-wise Feed-forward Networks
在进行了Attention操作之后,encoder和decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出:

其中每一层的参数都不同
四、Attention Mechanism详解
1)Attention定义


2)Self-Attention 具体计算步骤
以两个单词,Thinking, Machines 为例,通过词嵌入变换X1,X2两个向量,组成一个[2 x 4]的矩阵形式,如下:
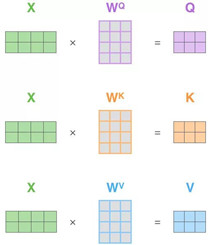
如上图所示,输入是一个[2x4]的矩阵(单词嵌入),权重矩阵是[4x3]的矩阵,分别与三个权重矩阵相乘,求得Q,K,V。
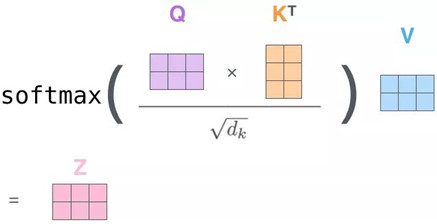
首先Q对K转制做点乘,除以dk的平方根(这个在论文中的解释是为了使得梯度更稳定)。再做一个softmax得到合为1的比例,最后对V做点乘得到输出Z。那么这个Z就是一个考虑过thinking周围单词(machine)的输出。
注意看这个公式,QKT 其实就会组成一个word2word的attention map!(加了softmax之后就是一个合为1的权重了)。比如说你的输入是一句话 "i have a dream" 总共4个单词,这里就会形成一张4x4的注意力机制的图:

这样一来,单词两两之间都有一个权重,注意encoder里面是叫self-attention,decoder里面是叫masked self-attention。
这里的masked就是要在做language modelling(或者像翻译)的时候,不给模型看到后面单词的信息。

mask就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息。
详细来说,i作为第一个单词,只能有和i自己的attention。have作为第二个单词,有和i, have 两个attention。 a 作为第三个单词,有和i,have,a 前面三个单词的attention。到了最后一个单词dream的时候,才有对整个句子4个单词的attention。
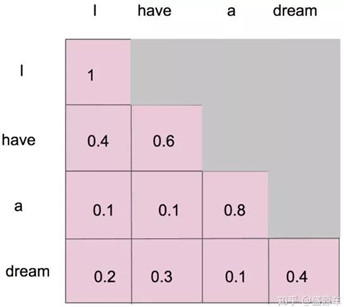
做完softmax后就像这样,横轴合为1
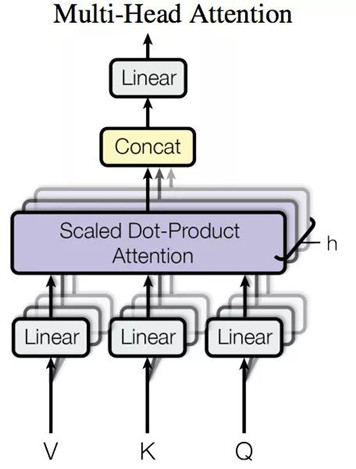
3) Multi-Head Attention
Multi-Head Attention就是把Scaled Dot-Product Attention的过程做H次,然后把输出Z合起来。论文中,它的结构图如下:
还是以上面的形式来解释:
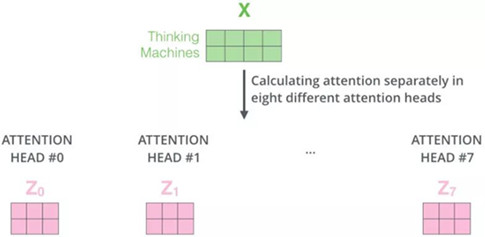
重复记性8次相似的操作,得到8个Zi矩阵

为了使得输出与输入结构对标 乘以一个线性W0 得到最终的Z。
4) 动态演示
五、Position Embedding
因为模型不包括Recurrence/Convolution,因此是无法捕捉到序列顺序信息的,例如将K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的分词相对或者绝对position信息利用起来。

这里每个分词的position embedding向量维度也是dmodel, 然后将原本的input embedding和position embedding加起来组成最终的embedding作为encoder/decoder的输入。其中position embedding计算公式如下:
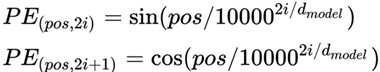
其中 pos 表示位置index, i 表示dimension index。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是,由于我们有:

这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
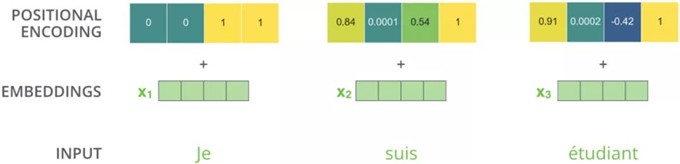
在其他NLP论文中,大家也都看过position embedding,通常是一个训练的向量,但是position embedding只是extra features,有该信息会更好,但是没有性能也不会产生极大下降,因为RNN、CNN本身就能够捕捉到位置信息,但是在Transformer模型中,Position Embedding是位置信息的唯一来源,因此是该模型的核心成分,并非是辅助性质的特征。
来源:https://mp.weixin.qq.com/s/7RgCIFxPGnREiBk8PcxOBg
来源:https://jalammar.github.io/illustrated-transformer/
参考:https://mp.weixin.qq.com/s/s2mvrF2pWBQ1M3fmwpf0Cg
Attention is all you need 论文详解(转)的更多相关文章
- Faster R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks ...
- R-CNN论文详解(转载)
这几天在看<Rich feature hierarchies for accurate object detection and semantic segmentation >,觉得作者的 ...
- The Google File System——论文详解(转)
“Google文件存储系统(GFS)是构建在廉价服务器之上的大型分布式系统.它将服务器故障视为正常现象,通过软件方式自动容错,在保证系统可用性和可靠性同时,大大降低系统成本. GFS是Google整个 ...
- Fast R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Fast R-CNN &创新点 规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取: 用RoI pooling层取代最后一层max ...
- R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Rich feature hierarchies for accurate object detection and semantic segmentatio ...
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 《The Tail At Scale》论文详解
简介 用户体验与软件的流畅程度是呈正相关的,所以对于软件服务提供方来说,保持服务耗时在用户能接受的范围内就是一件必要的事情.但是在大型分布式系统上保持一个稳定的耗时又是一个很大的挑战,这篇文章解析的是 ...
- 轻量化卷积神经网络MobileNet论文详解(V1&V2)
本文是 Google 团队在 MobileNet 基础上提出的 MobileNetV2,其同样是一个轻量化卷积神经网络.目标主要是在提升现有算法的精度的同时也提升速度,以便加速深度网络在移动端的应用.
- Residual Attention Network for Image Classification(CVPR 2017)详解
一.Residual Attention Network 简介 这是CVPR2017的一篇paper,是商汤.清华.香港中文和北邮合作的文章.它在图像分类问题上,首次成功将极深卷积神经网络与人类视觉注 ...
随机推荐
- java 父类的引用调用自己的属性 但是调用的方法必须是重写过的父类的方法 因为编译时候把他当作父类 运行时候才是他自己 所以必须重写父类得方法
- POJ P1185 炮兵阵地 【状压dp】
炮兵阵地 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 29502 Accepted: 11424 Description 司令 ...
- Linux内核设计第五周学习总结 分析system_call中断处理过程
陈巧然原创作品 转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 使用gdb跟踪分析一 ...
- POJ.3087 Shuffle'm Up (模拟)
POJ.3087 Shuffle'm Up (模拟) 题意分析 给定两个长度为len的字符串s1和s2, 接着给出一个长度为len*2的字符串s12. 将字符串s1和s2通过一定的变换变成s12,找到 ...
- bzoj3173: [Tjoi2013]最长上升子序列(fhqtreap)
这题用fhqtreap可以在线. fhqtreap上维护以i结尾的最长上升子序列,数字按从小到大加入, 因为前面的数与新加入的数无关, 后面的数比新加入的数小, 所以新加入的数对原序列其他数的值没有影 ...
- python基础----__setitem__,__getitem,__delitem__
class Foo: def __init__(self,name): self.name=name def __getitem__(self, item): print(self.__dict__[ ...
- 【DP】CF859C Pie Rules
https://www.luogu.org/problemnew/show/CF859C Description 有一个长度为\(n\)的序列,Alice和Bob在玩游戏.Bob先手掌握决策权. 他们 ...
- Codeforces Round #305 (Div. 2) D 维护单调栈
D. Mike and Feet time limit per test 1 second memory limit per test 256 megabytes input standard inp ...
- vim,删除所有
vim 删除所有内容:方法1: 按ggdG方法2: :%d
- 编写可移植C/C++程序的要点
1.分层设计,隔离平台相关的代码.就像可测试性一样,可移植性也要从设计抓起.一般来说,最上层和最下层都不具有良好的可移植性.最上层是GUI,大多数GUI都不是跨平台的,如Win32 SDK和MFC.最 ...