Postgres中tuple的组装与插入
1.相关的数据类型
我们先看相关的数据类型:
HeapTupleData(src/include/access/htup.h)
typedef struct HeapTupleData
{
uint32 t_len; /* length of *t_data */
ItemPointerData t_self; /* SelfItemPointer */
Oid t_tableOid; /* table the tuple came from */
HeapTupleHeader t_data; /* -> tuple header and data */
} HeapTupleData;
HeapTupleHeaderData(src/include/access/htup_details.h)
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
t_choice具有2个成员的联合类型:
1.t_heap 用于记录对元组执行插入/删除操作事物ID和命令ID,这些信息主要用于并发控制是检查元组对事物的可见性
2.t_datum一个新的元组在内存中形成的时候,我们不关心事物的可见性,因此在t_choice中需要用DatumTupleFields结构来记录元组的长度等信息,把内存的数据写入到表文件的时候,需要在元组中记录事物和命令ID,因此会把t_choice所占的内存转换成HeapTupleFields结构并且填充响应数据后再进行元组的插入。
t_ctid用于记录当前元组或者新元组的物理位置,块号和块内偏移量,例如(0,1)第一个块内的第一个linp,若tuple被跟新,那么就记录新版本的物理位置。
t_infomask2使用其低11位标识当前tuple的attribute的个数,其他位用于HOT以及tuple可见性的标志位
t_infomask用于标识tuple当前的状态,比如是否有OID,是否空的字段,t_infomask每一位代表一种状态,总共16种。
2.Tuple的构造
构造tuple的函数(src/backend/access/common/heaptuple.c)
HeapTuple
heap_form_tuple(TupleDesc tupleDescriptor,
Datum *values,
bool *isnull)
该函数使用给定的values数组和isnull数组来组装生成一个tuple。
该函数的主要流程是先计算整个tuple所需要的长度(这个长度是指tuple中除掉HeapTupleData结构以外的长度。事实上,该长度存储在HeapTupleData的t_len的属性中。)然后以此申请内存,最后根据values和isnull来填充tuple数据。
我们稍微说一下这个t_len的计算。
len = offsetof(HeapTupleHeaderData, t_bits);
首先计算heaptupleheaderdata的长度,这个offsetof计算了从HeapTupleHeaderData的首址到它的成员变量t_bit的偏移量。
所以为什么不直接sizeof(HeapTupleHeaderData)呢?
原因是t_bits描述了NULL的bitmap关系,它的实际长度与列(属性)个数有关,是一个可变的值,
因此,在计算完HeapTupleHeaderData长度的时候,我们便根据是否存在着null列,来计算相应的数据(如下)。
if (hasnull)
len += BITMAPLEN(numberOfAttributes);
以及是否有oid:
if (tupleDescriptor->tdhasoid)
len += sizeof(Oid);
再加上padding大小(涉及到C语言的数据对齐):
hoff = len = MAXALIGN(len); /* align user data safely */
最后再获取data的长度:
data_len = heap_compute_data_size(tupleDescriptor, values, isnull);
len += data_len;
获取了tuple的长度申请好内存后,向里面添加数据,就获得了如下的tuple(结构):
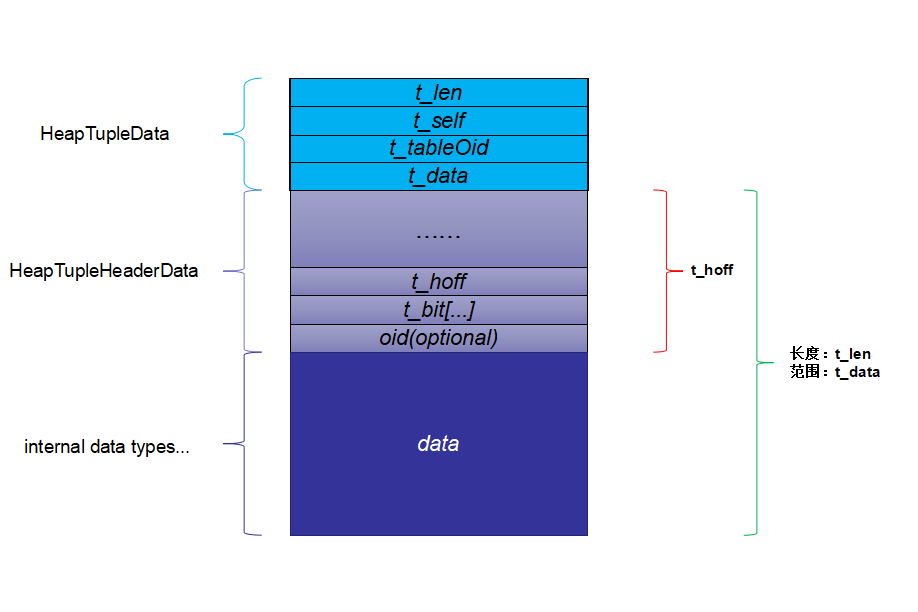
其中,hoff中包括了: 从TupleHeaderData起始位置到t_bits的位置;用户数据是从t_hoff开始,加上t_bits的偏移,以及oid的偏移,开始真正存储的。 这些由上图可以得知。
heap_fill_tuple 函数中依据tupledesc中atts所提供的信息来保存数据到相应的位置。att[i]->attlen == -1 当为此种情况时候,表明其是varlen数据,例如varchar之类的数量类型,att[i]->attlen == -2 当为此种情况时候,为cstring,即字符串形式的数据。never needs alignment 无需进行对齐操作。否则,为固定长度的类型。
如果是varlen类型数据时候。还需要使用VARATT_IS_EXTERNAL来判定是否是存储在外存上面。
做好了一条tuple之后,我们还要把它插入到数据库对应的表中才算完事。
3.Tuple的插入
插入tuple到heap的函数
Oid
heap_insert(Relation relation, HeapTuple tup, CommandId cid,
int options, BulkInsertState bistate)
这个函数还挺复杂的,涉及到了内存和disk的数据交换。内存主要涉及到了缓冲区buffer和lock,对于disk涉及到了FSM映射表和Page。
首先,预处理函数设置元组头部的字段,分配一个OID,并在必要时为元组提供Toast。请注意,在这里heaptup是传进来的tuple,而变量tup是作为一个临时变量存在的。
heaptup = heap_prepare_insert(relation, tup, xid, cid, options);
我们要将元组插入到page,涉及到内存和disk的数据交换,这就要用到buffer。我们知道insert的本质也是先"select"再"insert"。也就是说我们先要找到该表上合适的Page来装这个tuple。因此,我们为该Page申请一个buffer并加上执行锁,将该Page载入申请到的buffer中。注意,此时要插入的tuple并未写到buffer中。
buffer = RelationGetBufferForTuple(relation, heaptup->t_len,
InvalidBuffer, options, bistate,
&vmbuffer, NULL);
这样以后,所有的准备工作都做好了,就差临门一脚了。成与不成就在一举了。是不是听起来有点。。。?
是的,我们要进入临界区了,谁都不要打扰我:
START_CRIT_SECTION();
这个语句其实是设置了全局变量CritSectionCount,就相当于信号量了,这里不多说。
然后我们开始写数据吧:
RelationPutHeapTuple(relation, buffer, heaptup,
(options & HEAP_INSERT_SPECULATIVE) != 0);
但是话说,真的写了?并没有!你忘了我们postgresql有WAL么?你WAL log都还没写,数据怎么能先到磁盘?
那么这里我们有什么?我们buffer里面有Page,我们"手上"有tuple,好的,我们把tuple放到这个buffer装的Page里面对应的位置上。
就是说,我们的数据还在buffer里。
那么怎么通知Postgres我有脏数据要写啊?
MarkBufferDirty(buffer);
设置buffer为脏,这样Postgres在下次写磁盘(checkpointer)的时候就知道把这个buffer里的数据丢回disk了。
那么,我们也就知道了,接下来我们就要开始准备WAL和数据了。
这里大致用到了这几个函数:
XLogBeginInsert
XLogRegisterData
XLogRegisterBuffer
XLogRegisterBufData
PageSetLSN
好的,WAL也设置好了。(只等插入这条tuple的命令commit之后,WAL数据立即落盘,写到disk上,也就是pg_xlog目录下的WAL段里面。)此时退出临界区。
这个时候要放开buffer了。
最后我们再做一做清理工作,打完收工。
最最最后,实际的元组仍然在内存,不过没事,因为你的查询也是要先走buffer和cache的,所以你已经可以查询到这条数据了。等到系统调用了checkpointer进程,你的数据才真正落了盘,然而,这对你是透明的。
这里关于数据落盘的先后顺序和时机,我还是借网上的两张图吧:
WAL和data进入buffer的时机:
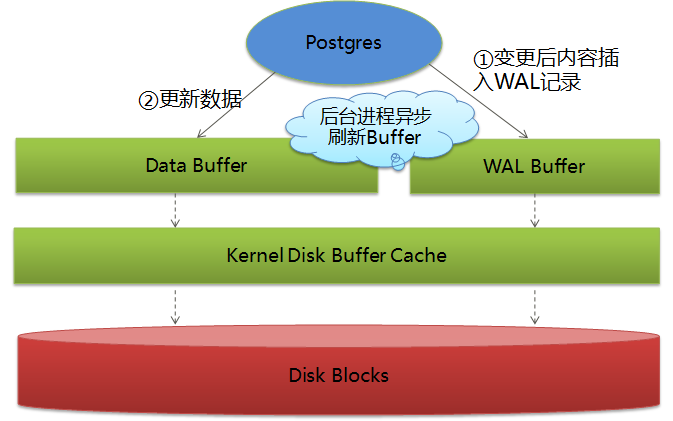
WAL和data写到disk的时机:
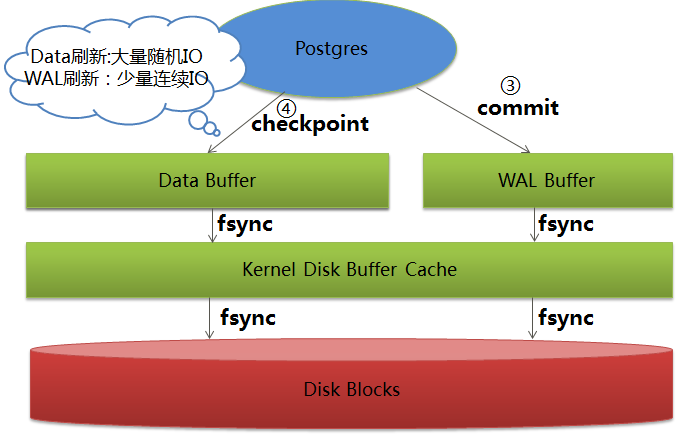
好的就是这样~
恩,这次对WAL的插入的分析比较简略,下次我弄清楚了再细说吧各位。
参考文章:
http://blog.jobbole.com/106585/
http://www.cnblogs.com/sangli/p/6404771.html
http://www.jianshu.com/p/a37ceed648a8
Postgres中tuple的组装与插入的更多相关文章
- Postgres的tuple的组装
1.相关的数据类型 我们先看相关的数据类型: HeapTupleData(src/include/access/htup.h) typedef struct HeapTupleData { uint3 ...
- 再说Postgres中的高速缓存(cache)
表的模式信息存放在系统表中,因此要访问表,就需要首先在系统表中取得表的模式信息.对于一个PostgreSQL系统来说,对于系统表和普通表模式的访问是非常频繁的.为了提高这些访问的效率,PostgreS ...
- PL/SQL客户端中执行insert语句,插入中文乱码
问题描述:在PL/SQL客户端中执行insert语句,插入中文乱码 解决方案: 1.执行脚本 select userenv('language') from dual; 结果为AMERICAN_ ...
- postgres中几个复杂的sql语句
postgres中几个复杂的sql语句 需求一 需要获取一个问题列表,这个问题列表的排序方式是分为两个部分,第一部分是一个已有的数组[0,579489,579482,579453,561983,561 ...
- postgres中的中文分词zhparser
postgres中的中文分词zhparser postgres中的中文分词方法 基本查了下网络,postgres的中文分词大概有两种方法: Bamboo zhparser 其中的Bamboo安装和使用 ...
- postgres中的视图和物化视图
视图和物化视图区别 postgres中的视图和mysql中的视图是一样的,在查询的时候进行扫描子表的操作,而物化视图则是实实在在地将数据存成一张表.说说版本,物化视图是在9.3 之后才有的逻辑. 比较 ...
- Postgres中postmaster代码解析(上)
之前我的一些文章都是在说Postgres的一些查询相关的代码.但是对于Postgres服务端是如何启动,后台进程是如何加载,服务端在哪里以及如何监听客户端的连接都没有一个清晰的逻辑.那么今天我来说说P ...
- Postgres中postmaster代码解析(中)
今天我们对postmaster的以下细节进行讨论: backend的启动和client的连接请求的认证 客户端取消查询时的处理 接受pg_ctl的shutdown请求进行shutdown处理 2.与前 ...
- 如何改变vim中的光标形状 : 在插入状态下显示为 beam?而在 其他 状态下 为 block?
分成两种情况来说明: 如果是在 shell 即: gnome-termial终端中, 来启动或 使用 vim的话, 你是 无法 实现这种需求的: 改变vim中的光标形状 : 在插入状态下显示为 bea ...
随机推荐
- jQuery树形控件zTree
初始化如下: function zTreeInit(){ parentCode = ""; setting = { view: { dblClickExpand: false, s ...
- 【BZOJ1951】古代猪文(CRT,卢卡斯定理)
[BZOJ1951]古代猪文(CRT,卢卡斯定理) 题面 BZOJ 洛谷 题解 要求什么很显然吧... \[Ans=G^{\sum_{k|N}{C_N^k}}\] 给定的模数是一个质数,要求解的东西相 ...
- 【UOJ#188】Sanrd(min_25筛)
[UOJ#188]Sanrd(min_25筛) 题面 UOJ 题解 今天菊开讲的题目.(千古神犇陈菊开,扑通扑通跪下来) 题目要求的就是所有数的次大质因子的和. 这个部分和\(min\_25\)筛中枚 ...
- BZOJ4033:[HAOI2015]树上染色——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=4033 有一棵点数为N的树,树边有边权.给你一个在0~N之内的正整数K,你要在这棵树中选择K个点,将 ...
- mysql互为主从复制配置笔记--未读,稍后学习
MySQL-master1:192.168.72.128 MySQL-master2:192.168.72.129 OS版本:CentOS 5.4MySQL版本:5.5.9(主从复制的master和s ...
- Linux 进程的 Uninterruptible sleep(D) 状态
首先,说一下产生D状态的原因. 上图阐释了一个进程运行的情况,首先,运行的时候,进程会向内核请求一些服务,内核就会将程序挂起进程,并将进程放到parked队列,通常这些进程只会在parked队列中停留 ...
- CollectionUtils.isEqualCollection的用法
在使用Java的集合时,有些时候会需要比较两个集合是否相等,自己写方法其实也简单,但是既然有了好的实现,就不要自己造轮子了,只要了解这个轮子是什么原理就好了. public static boolea ...
- TCP协议基础知识及wireshark抓包分析实战
TCP相关知识 应swoole长连接开发调研相关TCP知识并记录. 数据封包流程 如图,如果我需要发送一条数据给用户,实际的大小肯定是大于你发送的大小,在各个数据层都进行了数据的封包,以便你的数据能完 ...
- mongodb角色权限
角色说明:Read:允许用户读取指定数据库readWrite:允许用户读写指定数据库dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建.删除,查看统计或访问system.profileus ...
- HDU 3926 并查集 图同构简单判断 STL
给出两个图,问你是不是同构的... 直接通过并查集建图,暴力用SET判断下子节点个数就行了. /** @Date : 2017-09-22 16:13:42 * @FileName: HDU 3926 ...