读《分布式一致性原理》CURATOR客户端
创建会话
使用curator客户端创建会话和其它客户端产品有很大不同
1.使用CuratorFrameworkFactory这个工厂类的两个静态方法来创建一个客户端:
public static CuratorFramework newClient(String connectString, RetryPolicy retryPolicy) public static CuratorFramework newClient(String connectString, int sessionTimeoutMs,
int connectionTimeoutMs, RetryPolicy retryPolicy)
2.通过调用CuratorFramework的start()方法来启动会话
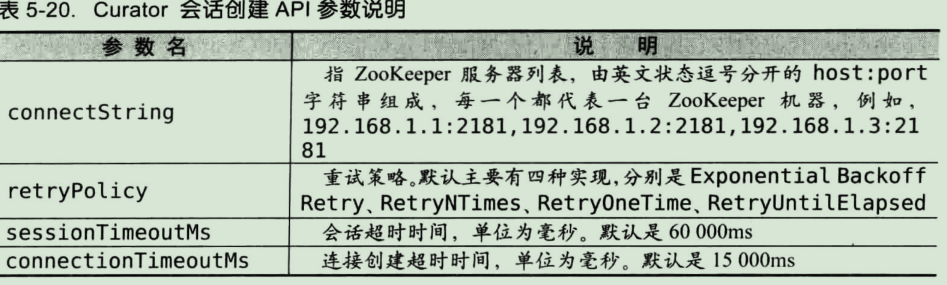
在重试策略上,Curator通过一个接口来让用户实现自定义的重试策略。在RetryPolicy接口中之定义了一个方法:
public boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper);

使用Curator创建会话
package session; import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry; public class CreateSession { public static void main(String[] args) throws InterruptedException {
ExponentialBackoffRetry retry = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.64.60:2181", retry);
client.start();
Thread.sleep(Integer.MAX_VALUE);
}
}
我们创建了一个名为ExponentialBackoffRetry的重试策略,该重试策略是Curator默认提供的几种重试策略之一,其构造方法如下:
public ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries)
public ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries, int maxSleepMs)


使用Fluent风格的API接口来创建会话
Curator提供的API接口在设计上最大的亮点就是其遵守了Fluent设计风格。
package session; import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry; public class FluentSession { public static void main(String[] args) {
ExponentialBackoffRetry retry = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("192.168.64.60:2181").
sessionTimeoutMs(3000).retryPolicy(retry).build();
client.start();
}
}
使用Curator创建含隔离命名空间的会话
为了实现不同的zookeeper业务之间的隔离,往往会为每个业务分配一个独立的命名空间,即指定一个zookeeper根路径。下面
所示的独立命名空间为/base,那么该客户端对zookeeper上数据节点的任何操作,都是基于对该相对目录进行的:

创建节点
Curator中提供了一系列的Fluent风格的接口,开发人员可以通过对其进行自由组合来完成各种类型节点的创建。
创建一个节点,初始内容为空
client.create().forPath(path)
创建一个节点附带初始内容
client.create().forPath(path,"init".getBytes())
如果没有设置节点属性,那么Curator默认创建的是持久节点,内容默认是空
client.create().withMode(CreateMode.EPHEMERAL).forPath(path)
如果需要递归创建
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path)
删除节点
client.delete().forPath(path);
client.delete().deletingChildrenIfNeeded().forPath(path);
client.delete().withVersion(1).forPath(path)
client.delete().guaranteed().forPath(path)
guaranteed接口是一个保障措施,只要客户端会话有效,那么Curator会在后台持续进行删除操作
直到节点删除成功。
读取数据
client.getData().forPath(path);
client.getData().storingStatIn(stat).forPath(path);
通过传入一个旧的stat来获取旧的节点信息。
更新数据
client.setData().forPath(path);
//调用该接口后,会返回一个stat对象。
client.setData().withVersion(version).forPath(path)
version是用来实现CAS的,version信息通常事重一个旧的stat对象中获取到
异步接口
curator中引入了BackGroudCallBack接口,用来处理异步接口调用接口调用之后服务端返回的结果信息。

BackgroundCallback接口中只有一个processResult方法。从注释中可以看出来方法会在操作完成后异步调用

CuratorEvent这个参数定义了zookeeper服务端发送到客户端的一系列事件参数。其中比较重要的有事件类型和响应码来两个参数。
事件类型(curatorEventType)

响应码(int)


在这些API接口中,我们重点看一下executor参数。在zookeeper中,所有的异步通知事件处理都是由
EventThread这个线程来处理的——EventThread线程用于串行化处理所有的事件通知。EventThread的“串行化处理机制”
在绝大部分情况下能保证事件处理的顺序性,这个特性也有一个弊端,就是一旦碰上复杂的处理单元,会消耗长时间处理
,所以允许用户传入一个Executor实例,这样一来就可以把哪些比较复杂的事件处理放到一个专门的线程池中去
package async; import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.api.BackgroundCallback;
import org.apache.curator.framework.api.CuratorEvent;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode; public class AsyncCuStor { static String path ="/zk-book"; static CuratorFramework client = CuratorFrameworkFactory.builder().
connectString("192.168.64.60:2181").sessionTimeoutMs(5000).
retryPolicy(new ExponentialBackoffRetry(1000, 3)).build(); static ExecutorService tp = Executors.newFixedThreadPool(2); public static void main(String[] args) throws Exception {
client.start();
System.out.println("main thread"+Thread.currentThread().getName()); client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).
inBackground(new BackgroundCallback() { public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
// TODO Auto-generated method stub
System.out.println(event.getResultCode()+"---"+event.getType()); System.out.println(Thread.currentThread().getName());
}
}, "", tp).forPath(path); Thread.sleep(Integer.MAX_VALUE); } }
典型使用场景
1.事件监听
zookeeper原生支持通过Watcher来进行事件监听,但是其使用并不是特别方便,需要开发人员自己反复注册watcher。curator
引入了Cache来实现对zookeeper服务端事件的监听。curator是对zookeeper中事件监听的包装,其对事件监听可以看做是一个本地缓存视图和服务器视图的一个比对。
同事curator能够解决反复注册监听的繁琐。
Cache分为两类监听:一种是节点监听,一种是子节点监听。
NodeCache
NodeCache用于监听指定zookeeper数据节点本身的变化
NodeCache(CuratorFramework client, String path)
public NodeCache(CuratorFramework client, String path, boolean dataIsCompressed)
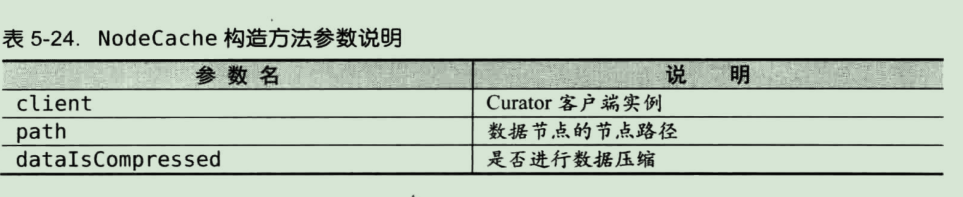
同时,NodeCache定义了事件处理的回调接口NodeCacheListener。

当数据节点的内容发生变化的时候,就会回调该方法。
package cache; import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.cache.NodeCache;
import org.apache.curator.framework.recipes.cache.NodeCacheListener;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode; public class NodeCache_Sample { static String path ="/zk-book/nodecache";
static CuratorFramework client = CuratorFrameworkFactory.
builder().connectString("192.168.64.60:2181").connectionTimeoutMs(5000).
retryPolicy(new ExponentialBackoffRetry(3000, 3)).build(); public static void main(String[] args) throws Exception { client.start();
client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.forPath(path,"init".getBytes());
final NodeCache cache = new NodeCache(client, path,false);
cache.start(true);
cache.getListenable().addListener(new NodeCacheListener() { public void nodeChanged() throws Exception {
System.out.println("node data update, new data"+
new String(cache.getCurrentData().getData())); }
});
client.setData().forPath(path,"u".getBytes());
Thread.sleep(5000);
client.delete().deletingChildrenIfNeeded().forPath(path);
Thread.sleep(Integer.MAX_VALUE); }
//调用cache的start的方法,方法有个boolean类型的参数,默认为false
//如果设置为true,那么第一次启动就会从zookeeper上读取对应节点的数据
//内容,并保存在Cache中。
//NodeCache不仅可以监听数据节点内容的变更,也可以监听指定节点是否存在
//如果指定节点不存在那么就会触发NodeCacheListener,如果该节点被删除
//那么curator将无法触发NodeCacheListener。
}
PathChildrenCache
pathChildrenCache用于监听指定zookeeper数据节点的子节点变化情况。


PathChildrenCache定义了事件处理的回调接口PathChildrenCacheListener,其定义如下。

当指定节点的子节点发生变化时,就会回调该方法。
package cache; import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.cache.PathChildrenCache;
import org.apache.curator.framework.recipes.cache.PathChildrenCacheEvent;
import org.apache.curator.framework.recipes.cache.PathChildrenCacheListener;
import org.apache.curator.framework.recipes.cache.PathChildrenCache.StartMode;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode; public class PathChildrenCache_sample { static String path ="/zk-book/nodecache";
static CuratorFramework client = CuratorFrameworkFactory.
builder().connectString("192.168.64.60:2181").connectionTimeoutMs(5000).
retryPolicy(new ExponentialBackoffRetry(3000, 3)).build(); public static void main(String[] args) throws Exception { client.start();
PathChildrenCache cache = new PathChildrenCache(client, path, true);
cache.start(StartMode.POST_INITIALIZED_EVENT);
cache.getListenable().addListener(new PathChildrenCacheListener() { public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
// TODO Auto-generated method stub
switch (event.getType()) {
case CHILD_ADDED:
System.out.println("child add"+event.getData().getPath());
break;
case CHILD_UPDATED:
System.out.println("child update"+event.getData().getPath());
case CHILD_REMOVED:
System.out.println("child remove"+event.getData().getPath());
default:
break;
} }
});
client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.forPath(path,"init".getBytes());
client.setData().forPath(path,"u".getBytes());
Thread.sleep(5000);
client.delete().deletingChildrenIfNeeded().forPath(path);
Thread.sleep(Integer.MAX_VALUE); } }
Master
对于一个复杂的任务,仅需要从集群中选举一台进行处理即可。诸如此分类的分布式问题,我们统称“Master”选举。借助zookeeper,
我们可以很方便的实现选举功能。
大体思路:
选择一个根节点,例如/master_select,多台机器同时像该节点创建一个子节点/master_select/lock,利用zookeeper的特性,最终只有一台
机器能够创建成功,成功的那台机器就作为Master。
Curator也是基于这个思路,但是它将节点创建,事件监听和自动选举进行了封装。开发人员只需要调用简单的API即可实现
Master选举。
package master; import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.leader.LeaderSelector;
import org.apache.curator.framework.recipes.leader.LeaderSelectorListenerAdapter;
import org.apache.curator.retry.ExponentialBackoffRetry; public class PullMaster { static String master_path = "/master_path"; static CuratorFramework client = CuratorFrameworkFactory.builder().
connectString("192.168.64.60:2181")
.connectionTimeoutMs(5000).
retryPolicy(new ExponentialBackoffRetry(3000, 3))
.build(); public static void main(String[] args) throws InterruptedException {
client.start();
LeaderSelector leaderSelector = new LeaderSelector(client, master_path, new LeaderSelectorListenerAdapter() { public void takeLeadership(CuratorFramework client) throws Exception {
// TODO Auto-generated method stub
System.out.println("成为Master角色");
Thread.sleep(3000);
System.out.println("完成Master操作,释放Master权利");
}
});
leaderSelector.autoRequeue();
leaderSelector.start();
Thread.sleep(Integer.MAX_VALUE);
}
}
可以看到主要是创建了一个LeaderSelector实例,该实例负责封装所有和Master选举相关的逻辑,
包含和zookeeper服务器交互的过程。其中master_path代表了一个Master选举的根节点,表明本次Master选举都是在
该节点下进行的。
在创建LeaderSelector实例的时候,还会传入一个监听器:leaderSelectorListenerAdapter。这需要开发人员自行去实现。
curator会在成功获取Master权利的时候回调该监听器。
一旦执行完takeLeadership方法,curator就会立即释放Master权利,然后重新开始新一轮的Master选举。

读《分布式一致性原理》CURATOR客户端的更多相关文章
- 读<分布式一致性原理>初识zookeeper
zookeeper是什么 zookeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如:数据发布/订阅,负载均衡,命名服务,分布式协调/通知 ,集群管理,Master选举 ...
- 《从Paxos到Zookeeper:分布式一致性原理与实践》【PDF】下载
内容简介 Paxos到Zookeeper分布式一致性原理与实践从分布式一致性的理论出发,向读者简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了Paxos和ZAB协议. ...
- 从Paxos到Zookeeper 分布式一致性原理与实践读书心得
一 本书作者介绍 此书名为从Paxos到ZooKeeper分布式一致性原理与实践,作者倪超,阿里巴巴集团高级研发工程师,国家认证系统分析师,毕业于杭州电子科技大学计算机系.2010年加入阿里巴巴中间件 ...
- 我读《从Paxos到zookeeper分布式一致性原理与实践》
从年后拿到这本书开始阅读,到准备系统分析师考试之前,终于读完了一遍,对Zookeeper有了一个全面的认识,整本书从理论到应用再到细节的阐述,内容安排从逻辑性和实用性上都是很优秀的,对全面认识Zook ...
- 《从Paxos到ZooKeeper分布式一致性原理与实践》学习笔记
第一章 分布式架构 1.1 从集中式到分布式 集中式的特点: 部署结构简单(因为基于底层性能卓越的大型主机,不需考虑对服务多个节点的部署,也就不用考虑多个节点之间分布式协调问题) 分布式系统是一个硬件 ...
- 《从Paxos到ZooKeeper 分布式一致性原理与实践》读书笔记
一.分布式架构 1.分布式特点 分布性 对等性.分布式系统中的所有计算机节点都是对等的 并发性.多个节点并发的操作一些共享的资源 缺乏全局时钟.节点之间通过消息传递进行通信和协调,因为缺乏全局时钟,很 ...
- 2月22日 《从Paxos到Zookeeper 分布式一致性原理与实践》读后感
zk的特点: 分布式一致性的解决方案,包括:顺序一致性,原子性,单一视图,可靠性,实时性 zk的基本概念: 集群角色:not Master/Slave,is Leader/Follower/Obser ...
- [从Paxos到ZooKeeper][分布式一致性原理与实践]<二>一致性协议[Paxos算法]
Overview 在<一>有介绍到,一个分布式系统的架构设计,往往会在系统的可用性和数据一致性之间进行反复的权衡,于是产生了一系列的一致性协议. 为解决分布式一致性问题,在长期的探索过程中 ...
- 读《分布式一致性原理》CURATOR客户端3
分布式锁 在分布式环境中,为了保证数据的一致性,经常在程序运行的某个运行点.需要进行同步控制. package master; import java.text.SimpleDateFormat; i ...
随机推荐
- 重温CLR(十四) 可空类型
我们知道,一个值类型的变量永远不可能为null.它总是包含值类型本身.遗憾的是,这在某些情况下会成为问题.例如,设计一个数据库时,可将一个列定义成为一个32位的整数,并映射到FCL的Int32数据类型 ...
- python正则的使用
python的正则是通过re模块的支持 匹配的3个函数 match :只从字符串的开始与正则表达式匹配,匹配成功返回matchobject,否则返回none: re.match(pattern, st ...
- drill 数据源配置
1. mongodb { "type":"mongo", "connection":"mongodb://user:passwor ...
- python+anaconda+pycharm工具包安装
更新额外包 $ conda update conda 更新pip python -m pip install --upgrade pip 更新所有 conda update --all 安装ffmpe ...
- win7 QT +opencv环境搭建
1.Win7 Qt4.8.5+QtCreator2.8.0+mingw环境参考前博文先搭建 2.下载Cmake2.8.11.2版本,安装.运行 [项目]那编译器选择:MinGW4.4.另外,重新编译O ...
- bzoj 3157 && bzoj 3516 国王奇遇记——推式子
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3157 https://www.lydsy.com/JudgeOnline/problem.p ...
- Markdown语法简单介绍
Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式. 一.标题 # 这是标题一 ## 这是标题二 ### 这是标题三 #### 这是标题 ...
- yii2自定义500错误
由于项目想加预警监控,有一块儿是涉及到程序内部错误的500,这样的错误级别比较高,所以就需要捕获这样的错误,顺便自定义了一把视图样式 看了这篇博客,知道了如何去自定义自己错误页面 : http://t ...
- xunsearch安装及环境检测(一)
1.运行执行下载解压安装包wget http://www.xunsearch.com/download/xunsearch-full-latest.tar.bz2解压到指定目录 tar -xjf xu ...
- cowboy的路由方式
直接贴代码 route_helper.erl -module(route_helper). -export([get_routes/]). get_routes() -> [ {'_', [ % ...