Hadoop I/O
Hadoop自带一套原子操作用于数据I/O。当中一些技术,如数据完整性保持和压缩,对于处理多达数个TB的数据时。特别值得关注。另外一些Hadoop工具或API。所形成的构建模块可用于开发分布式系统。比方序列化操作和on-disk数据结构。
本篇的内容主要有以下几点:
(1)通过检验和保证数据完整性
(2)Hadoop压缩
(3)Hadoop序列化-Writable
(4)Hadoop顺序文件-即文件序列化
数据完整性
(1)在数据的流转过中,HDFS通过“校验和”。来检验数据完整性,假设发现损坏,则新建一个replica,删除损坏的部分,是数据块的复本保持在期望的水平。
(2)datanode节点本身也会在一个后台线程中运行一个DataBlockScanner。从而定期验证本节点的全部数据块。
(3)Hadoop的LocalFileSystem运行client的校验和验证。在写入数据时。会新建一个名为.filename.crc的文件,用于校验
(4)假设底层文件系统本身已经有了校验机制,则能够使用一个不须要检验的文件系统RawLocalFileSystem:
Configuration conf = ...
FileSystem fs = new RawLocalFileSystem();
fs.initialize(null,conf);
(5)LocalFileSystem通过CheckSumFileSystem完毕校验操作,一般使用方法例如以下:
FileSystem rawFs = ...
FileSystem checksummedFs = new ChecksumFileSystem(rawFs);
Hadoop怎样使用压缩
压缩格式总结

gzip是比較通用的压缩格式,比較通用。bzip2比gzip更高效,但压缩速度慢一点。
bzip2解压比压缩快,但与其它压缩格式比,还是慢一点。LZO优化压缩速度,但效率略低。
DEFLATE是一个标准压缩算法。该算法的标准实现是zlib。没有可用于生产DEFLATE文件的经常使用命令行工具。由于通常都用gzip格式。
gzip格式仅仅是在DEFLATE格式添加了文件头和文件尾。
全部压缩算法都须要权衡时间和空间:一般来说-1为优化速度,-9为优化压缩空间,比如:gzip -1 file,代表最快压缩创建一个file.gz。
是否可切分。代表压缩算法是否支持切分(splitable)。即能否够搜索数据流任务位置并进一步往下读取数据。
可切分压缩尤其适合MapReduce。
codec
codec实现了一种压缩-解压算法。在Hadoop中,对接口CompressionCodec的实现代表一个codec,Hadoop实现的codec列表例如以下:

当中LZO代码库拥有GPL许可,不在Apache的发行版中。能够在http://github.com/kevinweil/hadoop-lzo下载。
(例程1)从标准输入读取数据,然后写入标准输出:
import java.io.FileInputStream;
import java.io.InputStream; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils; public class StreamCompressor {
public static void main(String[] args) throws Exception { String codeClassname = "org.apache.hadoop.io.compress.GzipCodec";
Class<?> codecClass = Class.forName(codeClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec) ReflectionUtils
.newInstance(codecClass, conf);
CompressionOutputStream out = codec.createOutputStream(System.out);
//InputStream in = new FileInputStream("/test/input/wc/file01.txt");
InputStream in = System.in;
IOUtils.copyBytes(in, out, 4096, false);
out.finish(); //这里仅仅是完毕到这个数据流的写操作。并没有关闭。所以能够接着往下流
}
}
hadoop集群运行命令:echo "Text" | hadoop jar test.jar StreamCompressor | gunzip 。能够看到正确的输出。
(例程2)依据文件扩展名,利用工厂推断产生codec对文件进行解压缩:
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory; public class FileDecompressor {
public static void main(String[] args) throws Exception {
String uri = "/test/input/t/1901.gz";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path inputPath = new Path(uri);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
String outputUri = CompressionCodecFactory.removeSuffix(uri,
codec.getDefaultExtension());
InputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(inputPath));
out = fs.create(new Path(outputUri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}
hadoop集群运行命令:
hadoop jar test.jar FileDecompressor。
hadoop fs -ls /test/input/t ,能够看到 /test/input/t/file01.gz 文件已经被解压了。
hadoop fs -cat /test/input/t/file01,能够查看文件内容。
(例程3)使用压缩池对标准输入的数据进行压缩,然后写入标准输出:
假设使用的是原生代码库。而且须要在应用中运行大量压缩和解压缩操作。能够考虑使用CodecPool,它同意你重复使用压缩和解压缩,以分摊创建这些对象所涉及的开销。
关于原生类库:
为了性能。最好使用原生(native)类库进行压缩和解压缩,比如。使用原生gzip类库能够降低大约一半的解压缩时间和10%的压缩时间(和内置的Java实现相比)。
并不是每种格式都有原生实现。例如以下表:

默认情况下。Hadoop会依据自身运行的平台搜索原生代码库,假设找到对应代码库就会自己主动载入。当然,特殊情况下,也能够禁用原生代码库,设置hadoop.native.lib为false(这确保使用内置的Java代码库,假设有的话)。
代码演示样例:
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CodecPool;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.io.compress.Compressor;
import org.apache.hadoop.util.ReflectionUtils; public class PooledStreamCompressor {
public static void main(String[] args) throws Exception { String codeClassname = "org.apache.hadoop.io.compress.GzipCodec";
Class<?> codecClass = Class.forName(codeClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec) ReflectionUtils
.newInstance(codecClass, conf);
Compressor compressor = null;
try {
compressor = CodecPool.getCompressor(codec);
CompressionOutputStream out = codec.createOutputStream(System.out,
compressor);
// InputStream in = new
// FileInputStream("/test/input/wc/file01.txt");
InputStream in = System.in;
IOUtils.copyBytes(in, out, 4096, false);
out.finish(); // 这里仅仅是完毕到这个数据流的写操作,并没有关闭,所以能够接着往下流
} finally {
CodecPool.returnCompressor(compressor);// 返回池子
}
}
}
(例程4)对查找最高气温的输出进行压缩:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter; public class MaxTemperatureWithCompression { public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(MaxTemperatureWithCompression.class);
conf.setJobName("Max Temperature With Compression"); // FileInputFormat.addInputPaths(conf, new Path(args[0]));
// FileOutputFormat.setOutputPath(conf, new Path(args[1])); FileInputFormat.setInputPaths(conf, new Path("/test/input/t"));
FileOutputFormat.setOutputPath(conf, new Path("/test/output/t")); // 设置压缩(输出gz压缩文件)
conf.setBoolean("mapred.output.compress", true);
conf.setClass("mapred.output.compression.codec", GzipCodec.class,
CompressionCodec.class); conf.setMapperClass(MaxTemperatureWithCompressionMapper.class);
conf.setCombinerClass(MaxTemperatureWithCompressionReduce.class);
conf.setReducerClass(MaxTemperatureWithCompressionReduce.class); conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class); JobClient.runJob(conf);
}
} class MaxTemperatureWithCompressionMapper extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999; public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
output.collect(new Text(year), new IntWritable(airTemperature));
}
}
} class MaxTemperatureWithCompressionReduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int maxValue = Integer.MIN_VALUE;
while (values.hasNext()) {
maxValue = Math.max(maxValue, values.next().get());
}
output.collect(key, new IntWritable(maxValue));
}
}
查理结果:
hadoop fs -copyToLocal /test/output/t/part-00000.gz
gunzip -c part-00000.gz
应该使用哪种压缩格式
使用哪种压缩格式与详细应用相关。
是希望运行速度最快。还是更关注降低存储开销?通常,须要为应用尝试不同的策略,而且为应用构建一套測试标准,从而找到最理想的压缩格式。
对于巨大、没有存储边界的文件,如日志文件,能够考虑例如以下选项:
(1)存储未经压缩的文件
(2)使用支持切分的存储格式,如bzip2
(3)在应用中切分文件成块,然后压缩。这样的情况,须要合理选择数据库的大小,以确保压缩后数据近似HDFS块的大小
(4)使用顺序文件(Sequence File)。它支持压缩和切分
(5)使用一个Avro数据文件。改文件支持压缩和切分,就像顺序文件一样,但添加了很多编程语言都可读写的优势
对于大文件来说,不应该使用不支持切分整个文件的压缩格式,否则将失去数据的本地特性。进而造成MapReduce应用效率低下。
序列化(serialization)
序列化,是将结构化对象转换为字节流。以便传输或存储。反序列化。是指字节流转回结构化对象的逆过程。
序列化在分布式数据处理的两大领域经常出现:进程间通信和永久存储。
Hadoop使用自己的序列化格式Writable,它格式紧凑,速度快,但很难用Java以外的语言进行扩展或使用。由于Writable是Hadoop的核心,大多数MapReduce程序的键和值都会使用它。
Writable接口
Writable接口定义了两个方法:一个将其状态写到DataOutput二进制流,还有一个从DataInput二进制流读取状态,代码例如以下:
package org.apache.hadoop.io; import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException; public interface Writable {
void write(DataOutput output) throws IOException;
void readFields(DataInput in) throws IOException;
}
Writable类
Hadoop自带的org.apache.hadoop.io包中有广泛的Writable类可供选择。
Writable类的层次结构例如以下图:
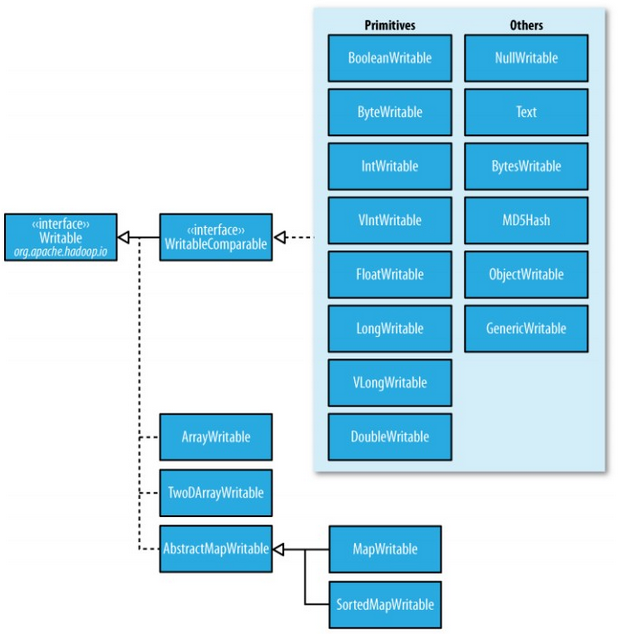
Java基本类型的Writable类:

实现定制的Writable类型
Hadoop本身已经有如上的Writable实现能够满足大部分要求,但有些时候。我们可能还是须要依据自己的需求构造一个新的实现。由于Writable是MapReduce数据IO的核心,所以调整成二进制表示能对性能产生显著效果。
例如以下演示存储一对Text对象的Writable类型:
import java.io.*;
import org.apache.hadoop.io.*; public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second; public TextPair() {
set(new Text(), new Text());
} public TextPair(Text first, Text second) {
set(first, second);
} public void set(Text first, Text second) {
this.first = first;
this.second = second;
} public Text getFirst() {
return first;
} public Text getSecond() {
return second;
} // @Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
} // @Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
} @Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
} @Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
} @Override
public String toString() {
return first + "\t" + second;
} // @Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}
例如以下演示在TextPair类的基础上,为了速度,实现一个RawComparator(上面的 TextPair是在对象的基础上比較,我们以下在序列化的字节流的基础上进行比較):
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.io.WritableUtils; public class Comparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator(); public Comparator() {
super(TextPair.class);
} @Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1])
+ readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2])
+ readVInt(b2, s2);
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
if (cmp != 0) {
return cmp;
}
return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1, b2,
s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
} static {
WritableComparator.define(TextPair.class, new Comparator());
}
}
以上能够看出,编写原生的comparator,须要处理字节级别的细节。
为什么不用Java Object Serialization
Doug Cutting这样解释:“为什么開始设计Hadoop的时候我不用Java Serialization?由于它看起来太复杂,而我觉得须要有一个很精简的机制。能够用于精确控制对象的读和写。由于这个机制是Hadoop的核心。使用Java Serialization后,尽管能够获得一些控制权,但用起来很纠结。不用RMI也处于相似的考虑。高效、高性能的进程间通信是Hadoop的关键。
我觉得我们须要精确控制连接、延迟和缓冲的处理方式,然而RMI对此无能为力。
”
Doug觉得Java序列化不满足序列化的标准:精简、高速、可扩展、互操作。
精简:Writable不把类名写到数据流,它假设client知道会收到什么类型,结果是这个格式比Java序列化更加精简,同一时候支持 随机存取和訪问。由于流中的每一条记录均独立于其它记录。
高效:Writable对象能够(而且通常)重用。对于MapRe作业(主要对仅仅有几个类型的大量对象进行序列化和反序列化)。不须要为新建对象分配空间而得到的存储节省是很可观的。
Avro
Apache Avro是一个独立于编程语言的数据序列化框架。该项目是由Doug Cutting创建的。旨在解决Hadoop中Writable类型的不足:缺乏语言的可移植性。
本篇不介绍这个框架,能够參阅官方网址:http://avro.apache.org 。
顺序文件
顺序文件,即流式文件。二进制文件。Hadoop开发了一组对象,来处理顺序文件。
SequenceFile
(1)写入SequenceFile对象
import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*; public class SequenceFileWriteDemo {
private static final String[] DATA = { "One,two", "Threw,four", "Five,six",
"Seven,eitht", "Nine,ten" }; public static void main(String[] args) throws IOException {
String uri = "/test/numbers.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(),
value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key,
value);
writer.append(key, value);
} } finally {
IOUtils.closeStream(writer);
}
}
}
writer.getLength()实际取出的是流式文件的偏移量,是记录的边界。
(2)读取SequenceFile
import java.io.*;
import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.ReflectionUtils; public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = "/test/numbers.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable) ReflectionUtils.newInstance(
reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(
reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";// 同步点
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key,
value);
position = reader.getPosition();// beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
在顺序文件里能够搜索给定位置,有两种方法:第一种是reader.seek(359),假设359不是记录的边界的话。则reader.next(key,value)时,会报IOException;另外一种是reader.sync(360)。代表从360之后找第一个同步点。
同步点是指当数据读取的实例出错后,能够再一次与记录边界同步的数据流中的一个位置。
同步点是SequenceFile.Writer记录的,在顺序文件写入过程中,每隔一定记录便插入一个特殊项标记同步标注。
同步点始终位于记录的边界处。
(3)通过命令行接口显示及排序SequenceFile
hadoop fs -text 能够识别gzip压缩文件及顺序文件,其它格式,则觉得是文本文件。
hadoop fs -text /test/numbers.seq
MapFile
(1)写入MapFile
MapFile是已经排序的SequenceFile,而且已经添加用于搜索键的索引。
写入MapFile代码例如以下:
import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*; public class MapFileWriteDemo {
private static final String[] DATA = { "One,two", "Threw,four", "Five,six",
"Seven,eitht", "Nine,ten" }; public static void main(String[] args) throws IOException {
String uri = "/test/numbers.map";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
IntWritable key = new IntWritable();
Text value = new Text();
MapFile.Writer writer = null;
try {
writer = new MapFile.Writer(conf, fs, uri, key.getClass(), value.getClass());
for (int i = 0; i < 1024; i++) {
key.set(i+1);
value.set(DATA[i % DATA.length]);
writer.append(key, value);
} } finally {
IOUtils.closeStream(writer);
}
}
}
能够通过hadoop命令查看,发现生成了numbers.map目录。里面有data和index文件:
hadoop fs -text /test/numbers.map/data | head
hadoop fs -text /test/numbers.map/index | head
关于index文件。默认情况下。是每隔128个键才有一个,能够通过MapFile.Writer实例中的setIndexInterval()方法设置io.map.index.interval属性。添加间隔数量能够有效降低用于存储索引的内存,减小间隔数量。能够提高随机訪问的时间。
Hadoop I/O的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- Hadoop的安装与设置(1)
在Ubuntu下安装与设置Hadoop的主要过程. 1. 创建Hadoop用户 创建一个用户,用户名为hadoop,在home下创建该用户的主目录,就不详细介绍了. 2. 安装Java环境 下载Lin ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
随机推荐
- Coding.net简单使用指南
注意:大家创建项目时一定要选择创建公开仓库!不然别人看不到! Coding.net是一个代码托管平台,简单来说这东西就是一个你在线存放代码的地方. 至于为什么要把代码存到这东西上呢?很多好处,比如防丢 ...
- 基于NMAP日志文件的暴力破解工具BruteSpray
基于NMAP日志文件的暴力破解工具BruteSpray 使用NMAP的-sV选项进行扫描,可以识别目标主机的端口对应的服务.用户可以针对这些服务进行认证爆破.为了方便渗透测试人员使用,Kali L ...
- 【BZOJ 2916】 2916: [Poi1997]Monochromatic Triangles (容斥)
2916: [Poi1997]Monochromatic Triangles Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 310 Solved: 1 ...
- 【BZOJ 2595】2595: [Wc2008]游览计划 (状压DP+spfa,斯坦纳树?)
2595: [Wc2008]游览计划 Time Limit: 10 Sec Memory Limit: 256 MBSec Special JudgeSubmit: 1572 Solved: 7 ...
- PHP 笔记——Web页面交互
一.客户端数据提交方法 客户端浏览器的数据通常使用 GET.POST 方式提交到服务器. 1.GET方式 GET方式指直接在URL中提供上传数据或者通过表单采用GET方式上传. http://url? ...
- NOI2005 维护数列(splay)
学了半天平衡树,选择了一道题来写一写,发现题目是裸的splay模板,但是还是写不好,这个的精髓之处在于在数列的某一个位置加入一个数列,类似于treap里面的merge,然后还学到了题解里面的的回收空间 ...
- POJ 3904 JZYZOJ 1202 Sky Code 莫比乌斯反演 组合数
http://poj.org/problem?id=3904 题意:给一些数,求在这些数中找出四个数互质的方案数. 莫比乌斯反演的式子有两种形式http://blog.csdn.net/out ...
- Codeforces Round #346 (Div. 2) D. Bicycle Race 叉积
D. Bicycle Race 题目连接: http://www.codeforces.com/contest/659/problem/D Description Maria participates ...
- hibernate 开发步骤
1 创建Customer表 CREATE TABLE CUSTOMER ( CID int NOT NULL PRIMARY KEY , USERNAME varchar(20) , PASSWORD ...
- Ubuntu下deb包的安装方法 - kevinhg的博客 - 博客频道 - CSDN.NET
Ubuntu下deb包的安装方法 - kevinhg的博客 - 博客频道 - CSDN.NET dpkg -i