MP3格式音频文件结构解析
MP3的全称是MPEG Audio Layer3,它是一种高效的计算机音频编码方案,它以较大的压缩比将音频文件转换成较小的扩展名为.MP3的文件,基本保持原文件的音质。MP3是ISO/MPEG标准的一部分,ISO/MPEG标准描述了使用高性能感知编码方案的音频压缩,此标准一直在不断更新以满足“质高量小”的追求,现已形成MPEGLayer1、Layer2、Layer3三个音频编码解码方案。MPEGLayer3压缩率可达1:10至1:12,1M的MP3文件可播放1分钟,而1分钟CD音质的WAV文件(44100Hz,16bit,双声道,60秒)要占用10M空间,这样算来,一张650M的MP3光盘播放时间应在10小时以上,而同样容量的一张CD盘播放时间在70分钟左右。MP3的优势是CD难以比拟的。
MPEG Audio 标准
MPEG(MovingPictureExpertsGroup)是ISO下的一个动态图 像专家组,它制定的MPEG标准广泛应用于各种多媒体中。 MPEG标准包括视频和音频标准,其中音频标准已制定出MPEG-1、MPEG-2、MPEG-2AAC和MPEG-4。
MPEG-1和MPEG-2标准使用同一个音频编码解码族—Layer1、2、3。MPEG-2一个新特点是采用低采样率扩展降低数据流量,另一特点是多通道扩展,将主声道增加为5个。MPEG-2AAC(MPEG-2AdvancedAudioCoding)标准是FraunhoferIIS 同AT&T公司于1997年推出的,旨在显著减少数据流量,MPEG22AAC采用的修正的离散余弦变换(MDCT,ModifiedDiscreteCo2sineTransform)算法,采样率可在8KHz到96KHz之间,声道数可在1-48之间。
MPEG Audio Layer1、2、3三个层使用相同的滤波器组、位流结构和头信息,采样频率为32KHz、4411KHz或48KHz。Layer1是为数字压缩磁带DCC(DigitalCompactCassette)设计的,数据流量为384kbps,Layer2在复杂性和性能间作了权衡,数据流量下降到256kbps-192kbps。Layer3一开始就为低数据流量而设计,数据流量在128kbps-112kbps,Layer3增加了MDCT变换,使其频率分辨能力是Layer2的18倍,Layer3还使用了与MPEGVid2eo类似的平均信息量编码(EntropyCoding),减少了冗余信息。MP3绝大部分使用的是MPEG21标准。
音频压缩
MP3格式始于80年代中期,德国Erlangen的Fraunhofer研究 所致力于高质量、低数据率的声音编码。
MP3音频压缩包含编码和解码两个部分。编码是将WAV文件中的数据转换成高压缩率的位流形式,解码是接受位流并将其重建到WAV文件中。
MP3采用了感知音频编码(PerceptualAudioCoding)这一失真算法。人耳感受声音的频率范围是20Hz-220kHz,MP3截掉了大量的冗余信号和无关的信号,编码器通过混合滤波器组将原始声音变换到频率域,利用心理声学模型,估算刚好能被察觉到的噪声水平,再经过量化,转换成Huffman编码,形成MP3位流。解码器要简单得多,它的任务是从编码后的谱线成分中,经过反 量化和逆变换,提取出声音信号。
在压缩音频数据时,先将原始声音数据分成固定的分块,然后作顺向MDCT变换,MDCT本身并不进行数据压缩,只是将一组时域数据转换成频域数据,以得知时域变化情况,顺向MDCT将每块的值转换为512个MDCT系数。量化使数据得到压缩,在对量化后的变换样值进行比特分配时要考虑使整个量化块最小,这就成为有损压缩了。解压时,经反向MDCT将512个系数还原成原始声音数据,前后的原始声音数据是不一致的,因为在压缩过程中,去掉了冗余和不相关数据。
MP3文件结构
MP3 文件大体分为三部分:TAG_V2(ID3V2),Frame, TAG_V1(ID3V1)
| ID3V2 | 包含了作者,作曲,专辑等信息,长度不固定,扩展了ID3V1的信息量 |
|
Frame |
一系列的帧,个数有文件大小和帧长决定 每个FRAM的长度可能不固定,也可能固定,由位率bitrate决定 每个FRAME由分为帧头和数据实体两部分 帧头记录了mp3的位率,采样率,版本等信息,每个帧之间相互独立 |
| ID3V1 | 包含了作者,作曲,专辑等信息,长度为128BYTE |
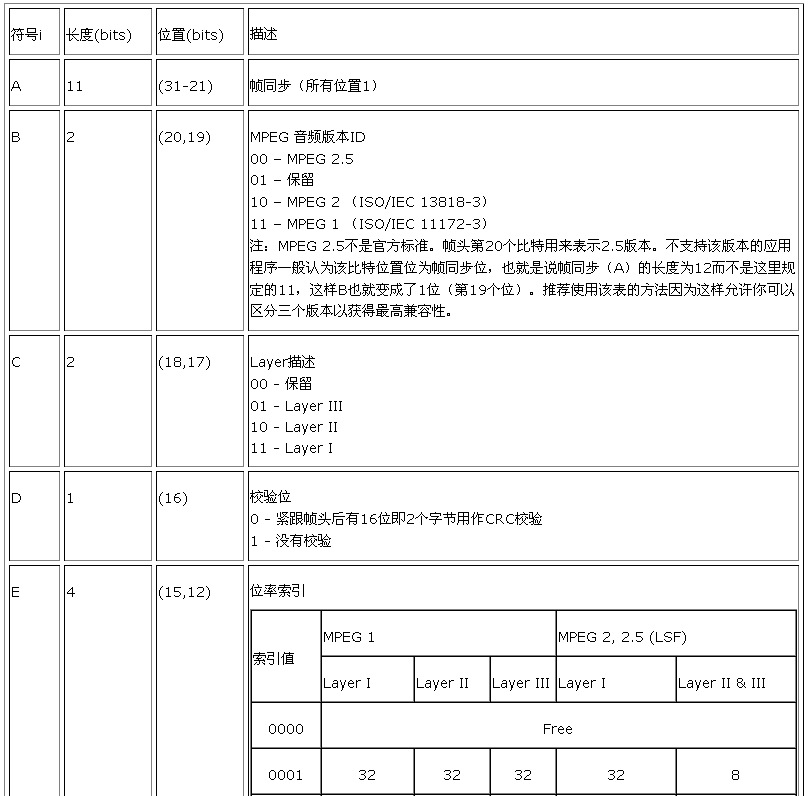
1. 帧头格式
下面是一个头内容图示,使用字符 A 到 M 表示不同的区域。在表格中你可以看到每一区域
的详细内容。
AAAAAAAA AAABBCCD EEEEFFGH IIJJKLMM




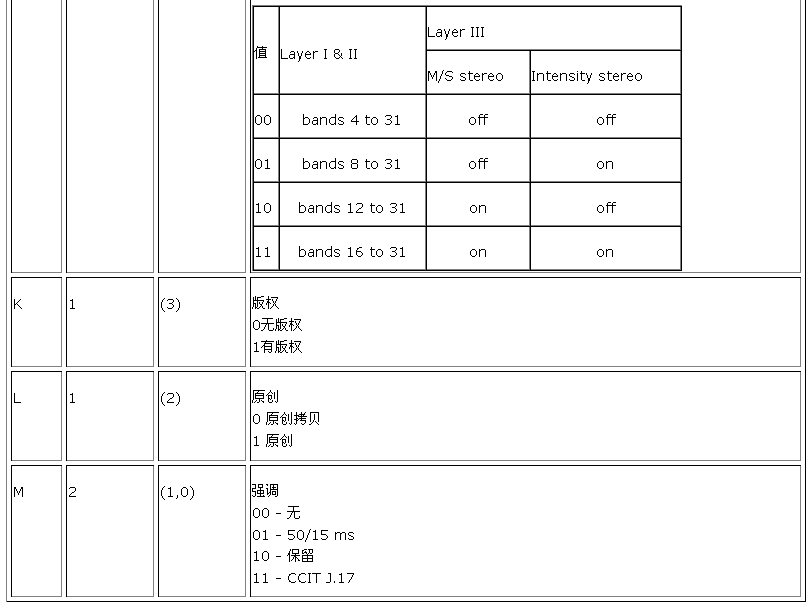
关于读取帧头我使用了下面的方法
定义一个结构体
typedef struct frameHeader
{
unsigned int sync1:8; //同步信息 1
unsigned int error_protection:1; //CRC 校验
unsigned int layer:2; //层
unsigned int version:2; //版本
unsigned int sync2:3; //同步信息 2
unsigned int extension:1; //版权
unsigned int padding:1; //填充空白字
unsigned int sample_rate_index:2; //采样率索引
unsigned int bit_rate_index:4; //位率索引
unsigned int emphasis:2; //强调方式
unsigned int original:1; //原始媒体
unsigned int copyright:1; //版权标志
unsigned int mode_extension:2; //扩展模式,仅用于联合立体声
unsigned int channel_mode:2; //声道模式
}FHEADER, *pFHEADER;请注意我的同步信息分成了两个部分,而且其他的位的顺序也和上表列出的有所差别,这个
主要是因为 c 语言在存取数据时总是从低位开始,而这个帧头是需要从高位来读取的。
读取方式如下
FHEADER header;
fread( &header, sizeof( FHEADER ), 1, streams );//这里假设文件已打开,读取位置已经指向帧
头所在的位置
这样一次就可以读入帧头的所有信息了。
2、如何计算帧长度
我们首先区分两个术语:帧大小和帧长度。帧大小即每帧采样数表示一帧中采样的个数,这是恒定值。其值入下表所示

帧长度是压缩时每一帧的长度,包括帧头。它将填充的空位也计算在内。LayerI 的一个空位长 4 字节,LayerII 和 LayerIII 的空位是 1 字节。当读取 MPEG 文件时必须计算该值以便找到相邻的帧。
注意:因为有填充和比特率变换,帧长度可能变化。
从头中读取比特率,采样频率和填充,
LyaerI 使用公式:
帧长度(字节) = (( 每帧采样数 / 8 * 比特率 ) / 采样频率 ) + 填充 * 4
LyerII 和 LyaerIII 使用公式:
帧长度(字节)= (( 每帧采样数 / 8 * 比特率 ) / 采样频率 ) + 填充
例:
LayerIII 比特率 128000,采样频率 44100,填充 0
=〉帧大小 417 字节
3、每帧的持续时间
之前看了一些文章都说 mp3 的一帧的持续时间是 26ms,结果在实际程序的编写中发现无法正确按时间定位到帧,然后又查了一些文章才知道,所谓 26ms 一帧只是针对 MPEG1 Layer III 而且采样率为 44.1KHz 来说是对的,但 mp3 文件并不都是如此,其实这个时间也是可以通过计算来获得,下面给出计算公式
每帧持续时间(毫秒) = 每帧采样数 / 采样频率 * 1000
这样通过计算可知 MPEG1 Layer III 采样率为 44.1KHz 的一帧持续时间为 26.12...不是整数,不过我们权且认为它就是 26 毫秒吧。
如果是 MPEG2 Layer III 采样率为 16KHz 的话那一帧要持续 36 毫秒,这个相差还是蛮大的,所以还是应该通过计算来获的,当然可以按 MPEG 版本,层数和采样率来建一个表,这样直接查表就可以知道时间了。
5、帧数据
在帧头后边是 Side Info(姑且称之为通道信息)。对标准的立体声 MP3 文件来说其长度为 32字节。通道信息后面是 Scale factor(增益因子)信息。当解码器在读到上述信息后,就可以进行解码了。当 MP3 文件被打开后,播放器首先试图对帧进行同步,然后分别读取通道信息及增益因子等数据,再进行霍夫曼解码,至此我们已经获得解压后的数据。但这些数据仍然不能进行播放,它们还处于频域,要想听到歌曲还要将它由频域通过特定的手段转换到时域。接下来的处理分别为立体化处理;抗锯齿处理;IMDCT 变换;IDCT 变换及窗口化滑动处理。
我们知道,对于 mp3 来说现在有两种编码方式,一种是 CBR,也就是固定位率,固定位率的帧的大小在整个文件中都是是固定的(公式如上所述),只要知道文件总长度,和从第一帧帧头读出的信息,就都可以通过计算得出这个 mp3 文件的信息,比如总的帧数,总的播放时间等等,要定位到某一帧或某个时间点也很方便,这种编码方式不需要文件头,第一帧开始就是音频数据。另一种是 VBR,就是可变位率,VBR 是 XING 公司推出的算法,所以在 MP3 的 FRAME 里会有“Xing"这个关键字(也有用"Info"来标识的,现在很多流行的小软件也可以进行 VBR 压缩,它们是否遵守这个约定,那就不得而知了),它存放在 MP3文件中的第一个有效帧的数据区里,它标识了这个 MP3 文件是 VBR 的。同时第一个帧里存放了 MP3 文件的帧的总个数,这就很容易获得了播放总时间,同时还有 100 个字节存放了播放总时间的 100 个时间分段的帧索引,假设 4 分钟的 MP3 歌曲,240S,分成 100 段,每两个相邻 INDEX 的时间差就是 2.4S,所以通过这个 INDEX,只要前后处理少数的FRAME,就能快速找出我们需要快进的帧头。其实这第一帧就相当于文件头了。不过现在有些编码器在编码 CBR 文件时也像 VBR 那样将信息记入第一帧,比如著名的 lame,它使用"Info"来做 CBR 的标记。
6、VBR 头
这里列出 VBR 的第一帧存储文件信息的头的格式。有两种格式,一种是常见的 XING Header
(头部包含字符‘Xing’)
,另一种是 VBRI Header (头部包含字符‘VBRI’)鉴于 VBRI Header
不 常 见 , 下 面 只 说 XING Header , 关 于 VBRI Header 请 看
http://www.codeproject.com/audio/MPEGAudioInfo.asp。
XING Header 的起始位置,相对于第一帧帧头的位置,单位是字节
36-39 "Xing"
21-24 "Xing"
21-24 "Xing"
13-16 "Xing"
文件为 MPEG1 并且不是单声道(大多数 VBR 的 mp3 文件都是如此)
文件为 MPEG1 并且是单声道
文件为 MPEG2 并且不是单声道
文件为 MPEG2 并且是单声道
XING Header 格式
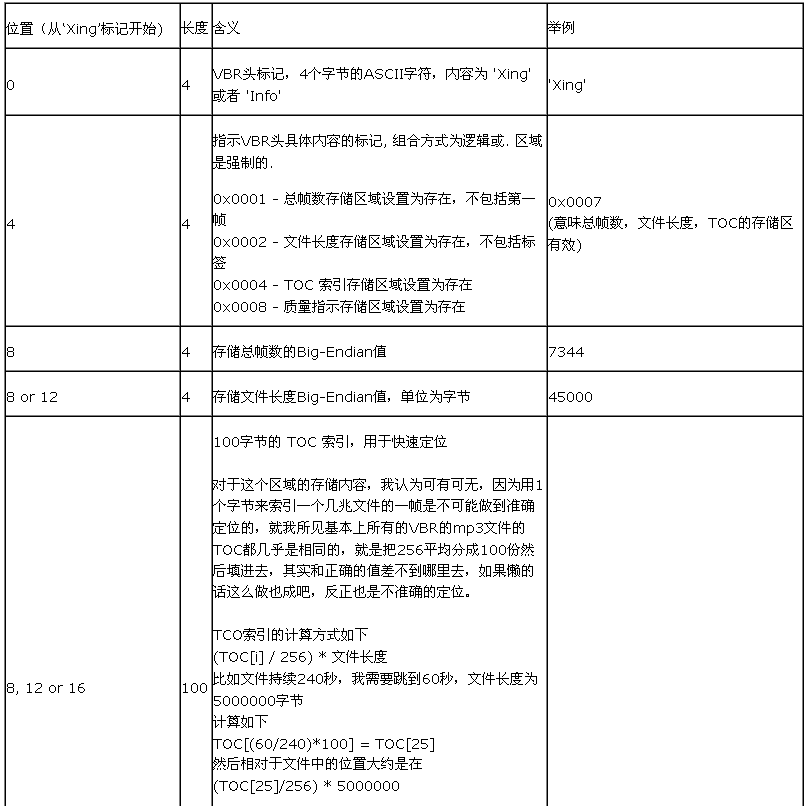

这样算来,XING Header 包括帧头一共最多只需要 156 个字节就够了。当然也可以在 XING
Header 后面存储编码器的信息,比如 lame 在其后就是存储其版本,这需要给第一帧留足够
的空间才行。
至于 mp3 的信息用从 XING Header 读出的信息就可以计算
比如
总持续时间 = 总帧数 * 每帧采样数 / 采样率 (结果为秒)
平均位率 = 文件长度 / 总持续时间 * 8
MPEG 音频标签
MPEG 音频标签分为两种,一种是 ID3v1,存在文件尾部,长度 128 字节,另一种是 ID3v2,
是对 ID3v1 的扩展,存在文件头部,长度不定。
1、ID3v1
ID3v1 标签用来描述 MPEG 音频文件。包含艺术家,标题,唱片集,发布年代和流派。另
外还有额外的注释空间。位于音频文件的最后固定为 128 字节。可以读取该文件的最后这
128 字节获得标签。
结构如下
AAABBBBB BBBBBBBB BBBBBBBB BBBBBBBB
BCCCCCCC CCCCCCCC CCCCCCCC CCCCCCCD
DDDDDDDD DDDDDDDD DDDDDDDD DDDDDEEE
EFFFFFFF FFFFFFFF FFFFFFFF FFFFFFFG
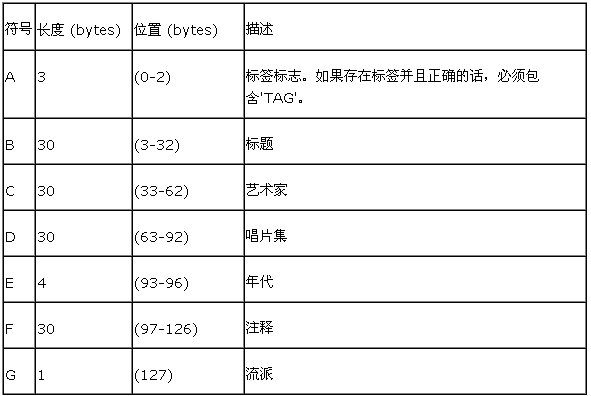
该规格要求所有的空间必须以空字符(ASCII 0)填充。但是并不是所有的应用程序遵循该规
则,比如 winamp 就用空格(ASCII 32)代替之。
在 ID3v1.1 结构中有些改变。注释部分的最后一个字节用来定义唱片集中的轨道号。如果不
知道该信息时可以用空字符(ASCII 0)代替。
流派使用原码表示,为下列数字之一:
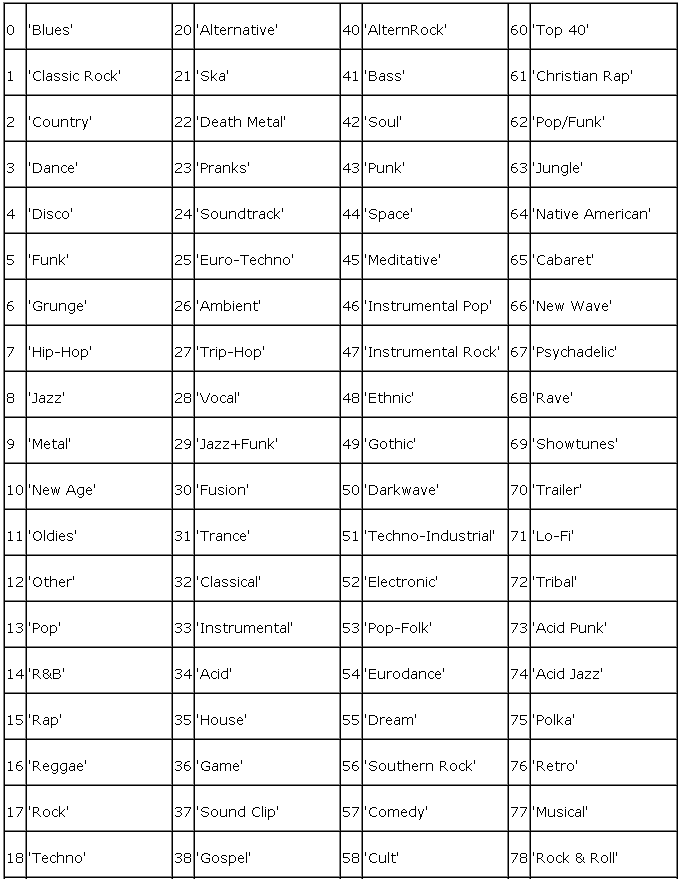

Winamp 扩充了这个表
其他任何的数值都认为是“unknown”
2、ID3V2
ID3V2 到现在一共有 4 个版本,但流行的播放软件一般只支持第 3 版,既 ID3v2.3。由于
ID3V1 记录在 MP3 文件的末尾,ID3V2 就只好记录在 MP3 文件的首部了(如果有一天发
布 ID3V3,真不知道该记录在哪里)。也正是由于这个原因,对 ID3V2 的操作比 ID3V1 要
慢。而且 ID3V2 结构比 ID3V1 的结构要复杂得多,但比前者全面且可以伸缩和扩展。
下面就介绍一下 ID3V2.3。
每个 ID3V2.3 的标签都一个标签头和若干个标签帧或一个扩展标签头组成。关于曲目的信息如标题、作者等都存放在不同的标签帧中,扩展标签头和标签帧并不是必要的,但每个标
签至少要有一个标签帧。标签头和标签帧一起顺序存放在 MP3 文件的首部。
(一)、标签头
在文件的首部顺序记录 10 个字节的 ID3V2.3 的头部。数据结构如下:
char Header[3]; /*必须为"ID3"否则认为标签不存在*/
char Ver; /*版本号 ID3V2.3 就记录 3*/
char Revision; /*副版本号此版本记录为 0*/
char Flag; /*存放标志的字节,这个版本只定义了三位,稍后详细解说*/
char Size[4]; /*标签大小,包括标签头的 10 个字节和所有的标签帧的大小*/
注:对这里我有疑惑,因为在实际寻找首帧的过程中,我发现有的 mp3 文件的标签大小是不
包含标签头的,但有的又是包含的,可能是某些 mp3 编码器写标签的 BUG,所以为了兼容
只好认为其是包含的,如果按大小找不到,再向后搜索,直到找到首帧为止。
(1).标志字节
标志字节一般为 0,定义如下:
abc00000
a -- 表示是否使用 Unsynchronisation(这个单词不知道是什么意思,字典里也没有找到,一般
不设置)
b -- 表示是否有扩展头部,一般没有(至少 Winamp 没有记录),所以一般也不设置
c -- 表示是否为测试标签(99.99%的标签都不是测试用的啦,所以一般也不设置)
(2).标签大小
一共四个字节,但每个字节只用 7 位,最高位不使用恒为 0。所以格式如下
0xxxxxxx 0xxxxxxx 0xxxxxxx 0xxxxxxx
计算大小时要将 0 去掉,得到一个 28 位的二进制数,就是标签大小(不懂为什么要这样做),
计算公式如
下:
int total_size;
total_size = (Size[0]&0x7F)*0x200000
+(Size[1]&0x7F)*0x4000
+(Size[2]&0x7F)*0x80
+(Size[3]&0x7F)
(二)、标签帧
每个标签帧都有一个 10 个字节的帧头和至少一个字节的不固定长度的内容组成。它们也是
顺序存放在文件
中,和标签头和其他的标签帧也没有特殊的字符分隔。得到一个完整的帧的内容只有从帧头
中的到内容大
小后才能读出,读取时要注意大小,不要将其他帧的内容或帧头读入。
帧头的定义如下:
char FrameID[4]; /*用四个字符标识一个帧,说明其内容,稍后有常用的标识对照表*/char Size[4]; /*帧内容的大小,不包括帧头,不得小于 1*/
char Flags[2]; /*存放标志,只定义了 6 位,稍后详细解说*/
(1).帧标识
用四个字符标识一个帧,说明一个帧的内容含义,常用的对照如下:
TIT2=标题 表示内容为这首歌的标题,下同
TPE1=作者
TALB=专集
TRCK=音轨 格式:N/M 其中 N 为专集中的第 N 首,M 为专集中共 M 首,N 和 M 为
ASCII 码表示的数字
TYER=年代 是用 ASCII 码表示的数字
TCON=类型 直接用字符串表示
COMM=备注 格式:"eng\0 备注内容",其中 eng 表示备注所使用的自然语言
(2).大小
这个可没有标签头的算法那么麻烦,每个字节的 8 位全用,格式如下
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx
算法如下:
int FSize;
FSize = Size[0]*0x1000000
+Size[1]*0x10000
+Size[2]*0x100
+Size[3];
(3).标志
只定义了 6 位,另外的 10 位为 0,但大部分的情况下 16 位都为 0 就可以了。格式如下:
abc00000 ijk00000
a -- 标签保护标志,设置时认为此帧作废
b -- 文件保护标志,设置时认为此帧作废
c -- 只读标志,设置时认为此帧不能修改(但我没有找到一个软件理会这个标志)
i -- 压缩标志,设置时一个字节存放两个 BCD 码表示数字
j -- 加密标志(没有见过哪个 MP3 文件的标签用了加密)
k -- 组标志,设置时说明此帧和其他的某帧是一组
值得一提的是 winamp 在保存和读取帧内容的时候会在内容前面加个'\0',并把这个字节计
算在帧内容的
大小中。
附:帧标识的含义
(4). Declared ID3v2 frames
The following frames are declared in this draft.AENC Audio encryption
APIC Attached picture
COMM Comments
COMR Commercial frame
ENCR Encryption method registration
EQUA Equalization
ETCO Event timing codes
GEOB General encapsulated object
GRID Group identification registration
IPLS Involved people list
LINK Linked information
MCDI Music CD identifier
MLLT MPEG location lookup table
OWNE Ownership frame
PRIV Private frame
PCNT Play counter
POPM Popularimeter
POSS Position synchronisation frame
RBUF Recommended buffer size
RVAD Relative volume adjustment
RVRB Reverb
SYLT Synchronized lyric/text
SYTC Synchronized tempo codes
TALB Album/Movie/Show title
TBPM BPM (beats per minute)
TCOM Composer
TCON Content type
TCOP Copyright message
TDAT Date
TDLY Playlist delay
TENC Encoded by
TEXT Lyricist/Text writer
TFLT File type
TIME Time
TIT1 Content group description
TIT2 Title/songname/content description
TIT3 Subtitle/Description refinement
TKEY Initial key
TLAN Language(s)
TLEN Length
TMED Media type
TOAL Original album/movie/show title
TOFN Original filename
TOLY Original lyricist(s)/text writer(s)TOPE Original artist(s)/performer(s)
TORY Original release year
TOWN File owner/licensee
TPE1 Lead performer(s)/Soloist(s)
TPE2 Band/orchestra/accompaniment
TPE3 Conductor/performer refinement
TPE4 Interpreted, remixed, or otherwise modified by
TPOS Part of a set
TPUB Publisher
TRCK Track number/Position in set
TRDA Recording dates
TRSN Internet radio station name
TRSO Internet radio station owner
TSIZ Size
TSRC ISRC (international standard recording code)
TSSE Software/Hardware and settings used for encoding
TYER Year
TXXX User defined text information frame
UFID Unique file identifier
USER Terms of use
USLT Unsychronized lyric/text transcription
WCOM Commercial information
WCOP Copyright/Legal information
WOAF Official audio file webpage
WOAR Official artist/performer webpage
WOAS Official audio source webpage
WORS Official internet radio station homepage
WPAY Payment
WPUB Publishers official webpage
WXXX User defined URL link frame
MP3 文件实例剖析
在 VC++中打开一个名为 test.mp3 文件,其内容如下:
000000 FF FB 52 8C 00 00 01 49 09 C5 05 24 60 00 2A C1
000010 19 40 A6 00 00 05 96 41 34 18 20 80 08 26 48 29
000020 83 04 00 01 61 41 40 50 10 04 00 C1 21 41 50 64
......
0000D0 FE FF FB 52 8C 11 80 01 EE 90 65 6E 08 20 02 30
0000E0 32 0C CD C0 04 00 46 16 41 89 B8 01 00 08 36 48
0000F033 B7 00 00 01 02 FF FF FF F4 E1 2F FF FF FF FF
......
0001A0 DF FF FF FB 52 8C 12 00 01 FE 90 58 6E 09 A0 02
0001B0 33 B0 CA 85 E1 50 01 45 F6 19 61 BC 26 80 28 7C
0001C0 05 AC B4 20 28 94 FF FF FF FF FF FF FF FF FF FF......
001390 7F FF FF FF FD 4E 00 54 41 47 54 45 53 54 00 00
0013A0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
......
0013F000 00 00 00 04 19 14 03 00 00 00 00 00 00 00 00
001400 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
001410 00 00 00 00 00 00 4E
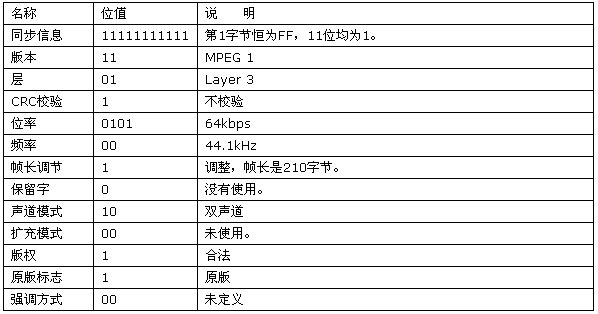
该文件长度 1416H(5.142K),帧头为:FF FB 52 8C,转换成二进制为:
11111111 11111011
01010010 10001100
对照表 1 可知,test.mp3 帧头信息见表 5。
表 5 test.mp3 文件帧头信息
第 1397H 开始的三个字节是 54 41 47,存放的是字符“TAG”,表示此文件有 ID3 V1.0 信息。
139AH 开始的 30 个字节存放歌名,前 4 个非 00 字节是 54 45 53 54,表示“TEST”;
13F4H 开始的 4 个字节是 04 19 14 03,存放年份“04/25/2003”;
最后 1 个字节是 4E,表示音乐类别,代号为 78,即“Rock&Roll”;
其它字节均为 00,未存储信息。
原文链接: https://wenku.baidu.com/view/d4877350ad02de80d4d840cb.html
原文链接: https://wenku.baidu.com/view/a071bf4e852458fb770b56a0.html
MP3格式音频文件结构解析的更多相关文章
- mp3格式音频 不能立即播放
原因是mp3的meta信息在mp3文件后面,所以要都加载完才能播放 而m4a 格式的 可以立即播放
- 微信录音文件上传到服务器以及amr转化成MP3格式
微信公众号音频接口开发 根据业务需求,我们可能需要将微信录音保存到服务器,而通过微信上传语音接口上传到微信服务器的语音文件的有效期只有3天,所以需要将文件下载到我们自己的服务器. 上传语音接口 wx. ...
- 微信录音文件上传到服务器以及amr转化成MP3格式,linux上转换简单方法
微信公众号音频接口开发 根据业务需求,我们可能需要将微信录音保存到服务器,而通过微信上传语音接口上传到微信服务器的语音文件的有效期只有3天,所以需要将文件下载到我们自己的服务器. 上传语音接口 wx. ...
- MP3文件结构解析(超详细)
转自:http://blog.csdn.net/u010650845/article/details/53520426 MP3文件结构解析(超详细) 1. MP3文件结构解析 1.1. 概述 1.1. ...
- 如何将AAC音频转换成MP3格式
我们应该怎样将AAC音频转换成MP3格式呢?AAC是一种专为声音数据设计的文件压缩格式,相对于MP3音频来说更加高效,性价比跟高.但是因为MP3音频格式的通用性,我们还是时常需要将AAC音频转换成MP ...
- PHP 将amr音频文件转换为mp3格式
说下整体思路 1.服务器安装ffmpeg 2.使用ffmpeg -i 指令来转换amr为mp3格式(这个到时候写在PHP代码中,使用exec函数执行即可) 3.在网页端使用HTML5的audio标签来 ...
- 怎样将flac音频格式转换成MP3格式
Flac音频格式怎样转换成MP3格式呢?随着现在音频格式的不断多样性,生活中很多时候我们都会遇到音频格式转换的问题,如flac音频转MP3的问题,那么我们应该如何去解决这个问题呢?下面我们就一起去来一 ...
- 怎样将M4A音频格式转换成MP3格式
因为MP3音频格式应用的广泛性,所以很多时候我们都需要将不同的音频格式转换成MP3格式的,那么如果我们需要将M4A音频格式转换成MP3格式,我们应该怎样进行实现呢?下面我们就一起来看一下吧. 操作步骤 ...
- CEF3 HTML5 audio标签为什么不能播放mp3格式的音频文件
CEF3 HTML5 audio标签 为什么不能播放mp3格式的音频文件 原因略. 解决方法: 找一个最新版的chrome ,我用的是24版本.路径 C:\Documents and Sett ...
随机推荐
- Eclipse安装Activiti插件(流程设计器)
Eclipse安装Activiti插件(流程设计器) 一.安装步骤: 1,打开Eclipse的 Help -> Install New Software,填上插件地址: Name:Activit ...
- react-refetch的使用小例子
出处:<react设计模式和最佳实践> 作者:米凯莱·贝尔托利 出版时间:2018年8月第1版(还算新) 使用react-refetch来简化api获取数据的代码 const List = ...
- jenkins邮箱配置以及结合ansible进行批量构建
tomcat8.5以上版本,jenkins2.7以上版本 首先填写你的系统管理员邮件地址,否则会使用jenkins系统本身的邮箱 填写的163邮箱,通过smtp认证填写正确的账号和密码(注意这里的密码 ...
- 地址之间的复制,memcpy函数
#include <stdio.h> #include <stdlib.h> int main(int argc, char *argv[]) { char a[3 ...
- 解读:Hadoop序列化类
序列化(serialization)是指将结构化的对象转化字节流,以便在进程间通信或写入硬盘永久存储. 反序列化(deserialization)是指将字节流转回到结构化对象的过程. 需要注意的是,能 ...
- vSphere SDK for Java 示例
示例代码: package com.vmware.event.connect; import java.net.MalformedURLException; import java.net.URL; ...
- LeetCode——merge-two-sorted-lists
Question Merge two sorted linked lists and return it as a new list. The new list should be made by s ...
- 第四篇:Spark SQL Catalyst源码分析之TreeNode Library
/** Spark SQL源码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,但是发现 ...
- [Network Architecture]ResNext论文笔记(转)
文章地址: https://blog.csdn.net/u014380165/article/details/71667916 论文:Aggregated Residual Transformatio ...
- 【cs231n】反向传播笔记
前言 首先声明,以下内容绝大部分转自知乎智能单元,他们将官方学习笔记进行了很专业的翻译,在此我会直接copy他们翻译的笔记,有些地方会用红字写自己的笔记,本文只是作为自己的学习笔记.本文内容官网链接: ...