SOLR企业搜索平台 三 (schema.xml配置和solrj的使用)
前面讲到如何搭建solr运行环境以及对中文查询语句进行分词处理,这篇文章主要讲解对schema.xml的相关配置和如何使用solrj
对于搜索程序来说,最重要的是理解他的总体架构.solr也是基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面.但是他的执行过程却无异于lucene
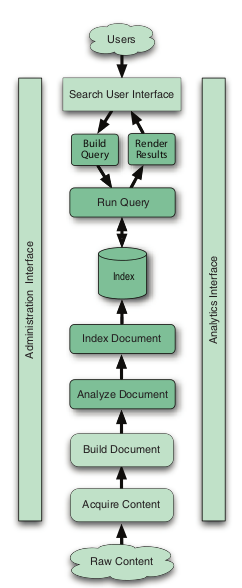
搜索程序的典型组件,其中阴影部分由lucene完成
我们首先来说说这个schema.xml。
schema.xml,这个相当于数据表配置文件,它定义了加入索引的数据的数据类型。主要包括types、fields和其他的一些缺省设置。
1)首先需要在types结点内定义一个FieldType子结点,包括name,class,positionIncrementGap等等一些参数,name就是这个FieldType的名称,class指向org.apache.solr.analysis包里面对应的class名称,用来定义这个类型的行为。在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤。在第二篇文章中详细讲了怎样添加中文分词器,详情请参见http://3961409.blog.51cto.com/3951409/833417
2)接下来的工作就是在fields结点内定义具体的字段(类似数据库中的字段),就是filed,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否有多个值)等等。
例:
- <field name="id" type="string" indexed="true" stored="true" required="true" />
- <field name="ant_title" type="textComplex" indexed="true" stored="true" />
- <field name="ant_content" type="textComplex" indexed="true" stored="true" />
- <field name="all" type="textComplex" indexed="true" stored="false" multiValued="true"/>
field的定义相当重要,有几个技巧需注意一下,对可能存在多值得字段尽量设置multiValued属性为true,避免建索引抛出错误;如果不需要存储相应字段值,尽量将stored属性设为false。
3)建议建立了一个拷贝字段,将所有的全文字段复制到一个字段中,以便进行统一的检索: (此时进行查询使用all:jason就相当于使用ant_title:jason or ant_content:jason)
- <field name="all" type="textComplex" indexed="true" stored="false" multiValued="true"/>
并在拷贝字段结点处完成拷贝设置:
- <copyField source="ant_title" dest="all"/>
- <copyField source="ant_content" dest="all"/>
4)除此之外,还可以定义动态字段,所谓动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
schema.xml配置文件大体上就是这样,更多细节请参见solr wiki http://wiki.apache.org/solr/SchemaXml。
下面将使用solrj对索引进行操作
1)新建工程,并加入以下jar包(参考http://wiki.apache.org/solr/Solrj)
From /dist:
- apache-solr-solrj-*.jar
From /dist/solrj-lib
- commons-codec-1.3.jar
- commons-httpclient-3.1.jar
- commons-io-1.4.jar
- jcl-over-slf4j-1.5.5.jar
- slf4j-api-1.5.5.jar
也就是solr/dist/solrj-lib/中commons-codec-x.xjar , commons-httpclient-x.x.jar , commons-io-x.x.jar , jcl-over-slf4j-x.x.jar , slf4j-api-x.x.jar还有solr/dist/中apache-solr-solrj-x.x.x.jar , apache-solr-core-x.x.x.jar
2)新建一个测试类
- package cn.edu.ccut.blackant;
- import java.io.IOException;
- import java.net.MalformedURLException;
- import org.apache.solr.client.solrj.SolrServerException;
- import org.apache.solr.client.solrj.impl.CommonsHttpSolrServer;
- import org.apache.solr.common.SolrInputDocument;
- import org.junit.Test;
- public class SolrTest {
- @Test
- public void test(){
- final String URL="http://localhost:8080/solr";
- //创建solrserver对象(CommonsHttpSolrServer)
- try {
- CommonsHttpSolrServer server=new CommonsHttpSolrServer(URL);
- SolrInputDocument doc = new SolrInputDocument();
- doc.addField("id", "2");//id必须有,value的值类型要根据schema.xml中规定的id类型而定
- doc.addField("ant_title", "atitle");
- doc.addField("ant_content", "jason");
- server.add(doc);
- server.commit();
- } catch (MalformedURLException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } catch (SolrServerException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
项目中添加junit,具体做法是右键项目-->add library-->选择junit-->junit4-->finish
3)运行测试类(运行相关信息需要查看控制台或者tomcat的日志文件)
运行结果可以使用luke来查看,使用前一定要根据solr的版本来选择luke,这里是用的是solr3.5,所以luke也要用3.5版本
下载地址http://code.google.com/p/luke/downloads/detail?name=lukeall-3.5.0.jar
使用方法:
3.1)进入文件所在路径
3.2)在命令行java -jar ./lukeall-3.5.0.jar打开软件
运行界面如图:
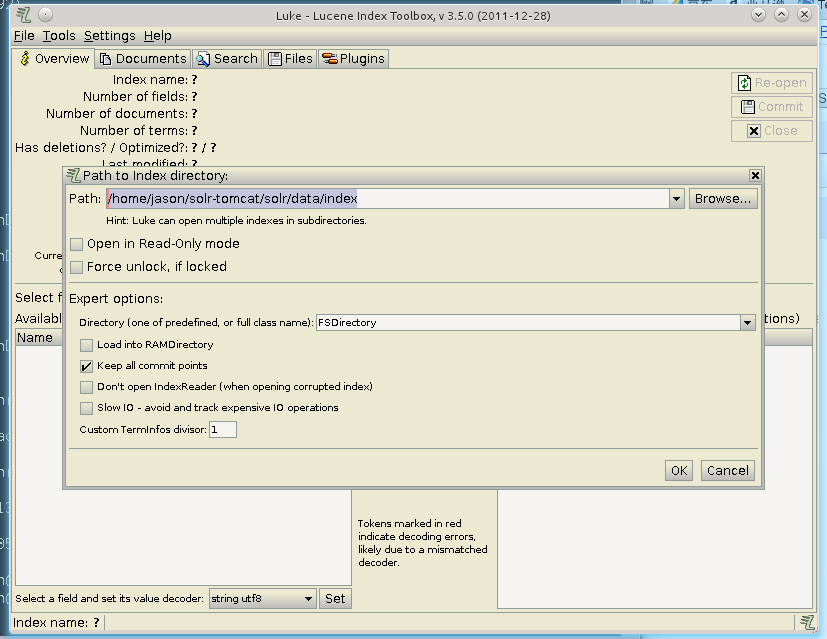
需要说明的是要指定solr的索引文件路径.此处为/home/jason/solr-tomcat/solr/data/index,指定好路径以后
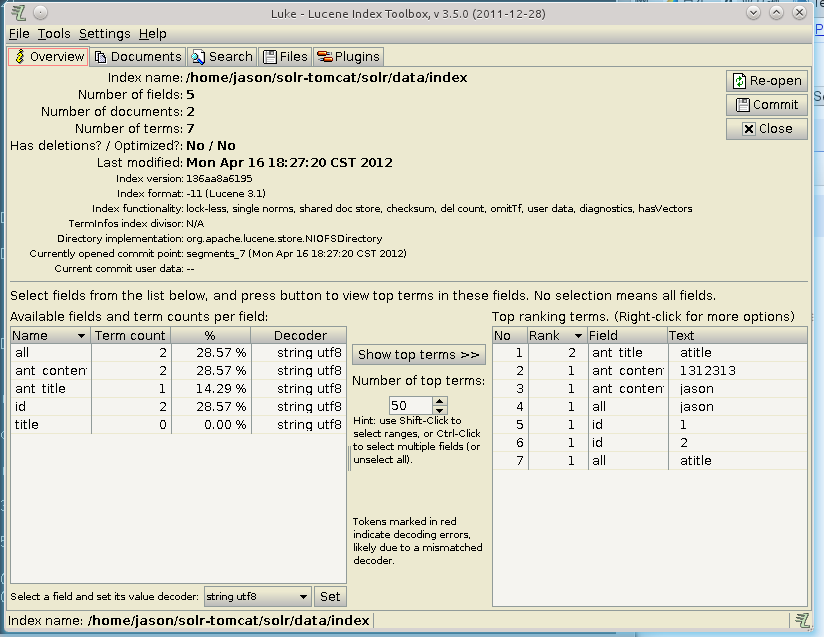
运行成功的话将会生成新的索引,如图右下角所示.如果程序中id值不变,那么每次将会覆盖id为2的索引值,这样可以完成更新索引的操作
4)访问http://127.0.0.1:8080/solr/admin/
查询*:*(查询全部),如果结果包含程序中的信息,那么恭喜配置成功!
本文出自 “李明泽” 博客,请务必保留此出处http://3961409.blog.51cto.com/3951409/836027
SOLR企业搜索平台 三 (schema.xml配置和solrj的使用)的更多相关文章
- solr官方文档翻译系列之schema.xml配置介绍
常见的元素 <field name="weight" type="float" indexed="true" stored=" ...
- SOLR企业搜索平台 二 (分词安装)
标签:linux lucene 分词 solr 全文检索 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://3961409.blog ...
- SOLR企业搜索平台 一 (搭建SOLR)
前提是已经安装了java的环境,环境变量的配置不做为讲解,网上也有大量资料.下面以linux为例来说明如何搭建好一个solr 1)首先下载solr,下载地址:http://mirror.bit.edu ...
- SOLR搭建企业搜索平台
一. SOLR搭建企业搜索平台 运行环境: 运行容器:Tomcat6.0.20 Solr版本:apache-solr-1.4.0 分词器:mmseg4j-1.6.2 词库:sogou-dic ...
- 利用SOLR搭建企业搜索平台 之——MultiCore
Solr Multicore 是 solr 1.3 的新特性.其目是一个solr实例,可以有多个搜索应用. 下面着手来将solr给出的一个example跑出来.这篇文章是基于<利用SOLR搭建企 ...
- 利用SOLR搭建企业搜索平台 之——配置文件
运行solr是个很简单的事,如何让solr高效运行你的项目,这个就不容易了.要考虑的因素太多.这里很重要一个就是对solr的配置要了解.懂得配置文件每个配置项的含义,这样操作起来就会如鱼得水! 在so ...
- 利用SOLR搭建企业搜索平台 之——运行solr
来源:http://blog.csdn.net/zx13525079024/article/details/24806131 本节主要介绍Solr的安装,其实Solr不需要安装.直接下载就可以了 ...
- 利用SOLR搭建企业搜索平台 之——模式配置Schema.xml
来源:http://blog.csdn.net/awj3584/article/details/16963525 schema.xml这个配置文件可以在你下载solr包的安装解压目录的\solr\ex ...
- solr的schema.xml配置属性解释
schema.xml做什么? SOLR加载数据,创建索引和数据时,核心数据结构的配置文件是schema.xml,该配置文件主要用于配置数据源,字段类型定义,搜索类型定义等.schema.xml的配置直 ...
随机推荐
- C#中的四舍五入有多坑
原文:C#中Math.Round()实现中国式四舍五入 C#中的Math.Round()并不是使用的"四舍五入"法.其实在VB.VBScript.C#.J#.T-SQL中Round ...
- SpringMVC配置过程中出现的问题!
<c:set var="ctx" value="${pageContext.request.contextPath}" />不起作用,原因是web. ...
- bootstrap 自定义
在ror工程内 /app/assets/stylesheets/bootstrap_and_overrides.css.less 内覆盖内容 具体参数如下 https://github.com/twb ...
- U3D 代码自动化生成定制预置体的旋转问题
//定制预置体 //要求:1,模型面向U3D的Z轴正向(由MAX导出时是面向U3D的X负向的) //2,增加一些常用挂点,3增加一个圆形阴影片,4,添加包围盒 //根据这些要求制作预置休 static ...
- Keepalived 资源监控
简介: 作为一个高可用集群软件,Keepalived 没有 Heartbeat .RHCS 等专业的高可用集群软件功能强大,它不能够实现集群资源的托管,也不能实现对集群中运行服务的监控,好在 Keep ...
- 使用zTree展开节点后,覆盖了下一个节点
如图所示,结果是zTree与<fieldset>标签不兼容....我去!!! 也就是说Ztree不能放在<fieldset>标签中..
- Oracle和Mysql的区别 转载
一.并发性 并发性是oltp数据库最重要的特性,但并发涉及到资源的获取.共享与锁定. mysql:mysql以表级锁为主,对资源锁定的粒度很大,如果一个session对一个表加锁时间过长,会让其他se ...
- chrome crx下载路径
chrome crx下载后会被删除,可在检查时粘贴出来,下载路径在: %localappdata%\Google\Chrome\User Data\Webstore Downloads 参考:http ...
- 在linux下使用CMake构建应用程序
本文介绍了一个跨平台的自动化构建系统 CMake 在 linux 上的使用方法. CMake 是一个比 automake 更加容易使用的工具,能够使程序员从复杂的编译连接过程中解脱出来.文中通过一些例 ...
- Part2_lesson4---ARM寻址方式
所谓寻址方式就是处理器根据指令中给出的信息来找到指令所需操作数的方式. 1.立即数寻址 ADD R0,R0,#0x3f; R0<-R0+0x3f 在以上指令中,第二个源操作数即为立即数,要求以“ ...