spark[源码]-Pool分析
概述
这篇文章主要是分析一下Pool这个任务调度的队列。整体代码量也不是很大,正好可以详细的分析一下,前面在TaskSchedulerImpl提到大体的功能,这个点在丰富一下吧。
DAGScheduler负责构建具有依赖关系的任务集,TaskSetManger负责在具体的任务集内部调度任务,而TaskScheduler负责将资源提供给TaskSetManger供其作为调度任务的依据,但是每个sparkContext可能同时存在多个可运行的任务集,因此需要调度池pool来进行协调管理。
初始化源码解析
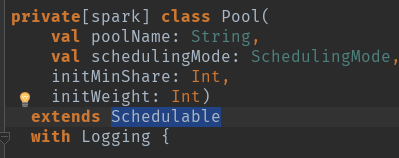
poolname:名字
schedulingMode:调度模式,FAIR(公平调度),FIFO,默认是FIFO的方式。
initWeight:调度池权重
initMinShare:计算资源中的cpu核数
先看一下扩展类Schedulable,Scheduler是一个特征类,pool是其具体的实现.
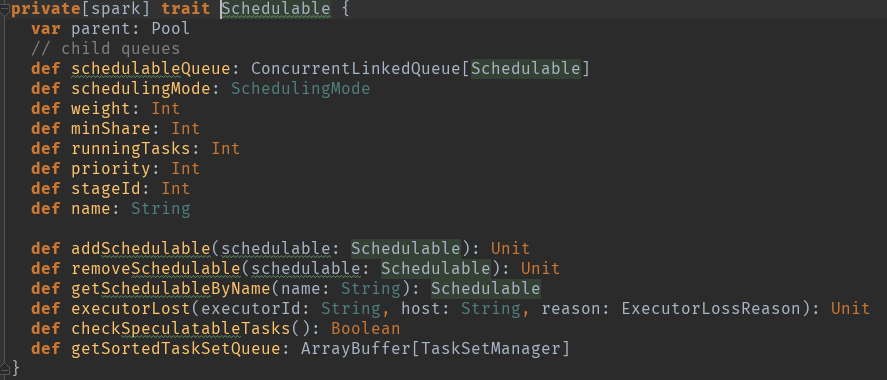
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable] 调度队列
val schedulableNameToSchedulable = new ConcurrentHashMap[String, Schedulable] 调度对应关系
var weight = initWeight 调度池权重
var minShare = initMinShare 计算资源中的cpu核数
var runningTasks = 0 正在运行的task数量
var priority = 0 优先级
var stageId = -1 池的阶段id用于在调度中中断绑定
var name = poolName 调度池名字
var parent: Pool = null
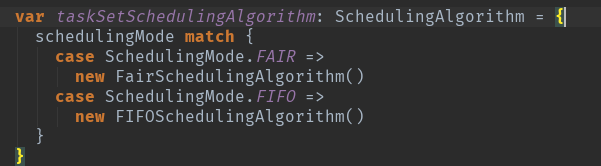
调度算法,根据调度模式初始化算法。org.apache.spark.scheduler.SchedulingAlgorithm。
调度池则用于调度每个sparkContext运行时并存的多个互相独立无依赖关系的任务集。
调度池负责管理下一级的调度池和TaskSetManager对象。
用户可以通过配置文件定义调度池和TaskSetManager对象。
1.调度的模式Scheduling mode:用户可以设置FIFO或者FAIR调度方式。
2.weight,调度的权重,在获取集群资源上权重高的可以获取多个资源。
3.miniShare:代表计算资源中的cpu核数。
配置conf/faurscheduler.xml配置调度池的属性,同时要在sparkConf对象中配置属性。
方法解析
TaskSchedulerImpl在初始化过程中会根据用户设定的SchedulingMode(默认是FIFO)创建一个rootPool根调度池,之后根据具体的调度模式再进一步创建ScheduleBuilder对象,具体的ScheduleBuilder对象的BuildPools方法将在rootPool的基础上完成整个Pool的构建工作,之后就有通过addSchedulable将taskSetManger和pool关联起来了。
Schedulable有两个类,一个是pool,一个是TaskSetManager。
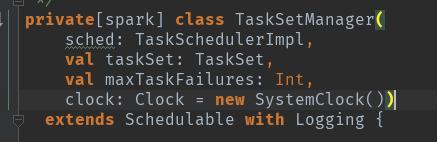
Pool直接管理的是TaskSetManager,每个TaskSetManager创建时都存储了其对应的StageID.
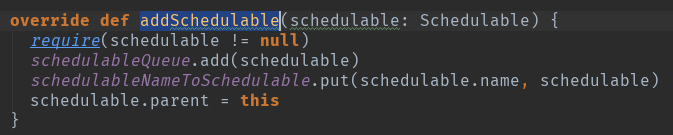
具体的调度算法,等以后的文章在做详细分析吧。
spark[源码]-Pool分析的更多相关文章
- Spark源码分析(一)-Standalone启动过程
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3858065.html 为了更深入的了解spark,现开始对spark源码进行分析,本系列文章以spark ...
- Spark源码分析 -- TaskScheduler
Spark在设计上将DAGScheduler和TaskScheduler完全解耦合, 所以在资源管理和task调度上可以有更多的方案 现在支持, LocalSheduler, ClusterSched ...
- Spark源码分析之九:内存管理模型
Spark是现在很流行的一个基于内存的分布式计算框架,既然是基于内存,那么自然而然的,内存的管理就是Spark存储管理的重中之重了.那么,Spark究竟采用什么样的内存管理模型呢?本文就为大家揭开Sp ...
- Spark源码分析之六:Task调度(二)
话说在<Spark源码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这个方法针对接收到的ReviveOffer ...
- Spark源码分析之五:Task调度(一)
在前四篇博文中,我们分析了Job提交运行总流程的第一阶段Stage划分与提交,它又被细化为三个分阶段: 1.Job的调度模型与运行反馈: 2.Stage划分: 3.Stage提交:对应TaskSet的 ...
- Spark源码分析之四:Stage提交
各位看官,上一篇<Spark源码分析之Stage划分>详细讲述了Spark中Stage的划分,下面,我们进入第三个阶段--Stage提交. Stage提交阶段的主要目的就一个,就是将每个S ...
- Spark源码分析之二:Job的调度模型与运行反馈
在<Spark源码分析之Job提交运行总流程概述>一文中,我们提到了,Job提交与运行的第一阶段Stage划分与提交,可以分为三个阶段: 1.Job的调度模型与运行反馈: 2.Stage划 ...
- spark 源码分析之四 -- TaskScheduler的创建和启动过程
在 spark 源码分析之二 -- SparkContext 的初始化过程 中,第 14 步 和 16 步分别描述了 TaskScheduler的 初始化 和 启动过程. 话分两头,先说 TaskSc ...
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
随机推荐
- 关于 AfxSocketInit()
一般来说 WASAtarup() 是应用程序调用的Windows Sockets dll的第一个函数,在调用任何Winsock Api之前,必须调用WSAStartup()进行初始化,最后调用WSAC ...
- sizeof 数组与指针
在学习指针的时候,得到指针的定义和数组的定义一样,但是这时候就很好奇,指针只是一个地址,那数组和指针一样的话,sizeof时怎么得知其长度呢. 于是百度了下面的回复: 千万不要把数组名看成指针,尽管有 ...
- ubuntu安装mysql-python
1.首先你要确定ubuntu更新源能用.以下的源适合13.X和14.X,低版本号的ubuntu没试过.毕竟劳资不是測试人员. 为了安全起见 cp /etc/apt/source.list /etc/a ...
- MySQL------代码1024,can't get hostname for your address解决方法
1.hosts文件问题 进入C:\Windows\System32\drivers\etc\hosts 查看里面是否包含: # 127.0.0.1 localhost 没有则添加,再重启MySQL服务 ...
- 剑指 offer set 18 数组中只出现一次的数字
题目描述: 一个整型数组里除了两个数字之外,其他的数字都出现了两次.请写程序找出这两个只出现一次的数字 思路 1. 思路是先将数组分成两个部分, 两个单个数字分别分到两部分中, 并且数组中其他数字都成 ...
- ios 开发之 -- 极光推送,发送自定义消息,进入制定页面
在进行极光推送时候,发现版本有所更新,以前截取didfinish入口方法里面的launchOptions,获取一个本地的通知内容,进行本地展示不可用了,通过查询官方文档和网上的资料才发现,方法改变了, ...
- Linux命令之乐--expr
计算字符长度 [root@Director ~]# echo $var hello world [root@Director test]# expr length "$var" 数 ...
- 从WebView跳到普通View
本文转载至 http://pingguohe.net/2011/06/25/webview_to_nativeview/ 做网络ios应用难免要用到UIWebViewController,直接嵌入一个 ...
- POI读写大数据量EXCEL
另一篇文章http://www.cnblogs.com/tootwo2/p/8120053.html里面有xml的一些解释. 大数据量的excel一般都是.xlsx格式的,网上使用POI读写的例子比较 ...
- Microsoft License Keys – Volume
VLK Product Group Product KeyOffice XP Applications P3HBK-F86Y2-374PQ-KW92R-B36VTOffice 2003 Suites ...