模块 - logging/re
logging 模块
很多程序都有记录日志的需求
logging的日志可以分为 debug(), info(), warning(), error() and critical()5个级别
1.最简单用法:
import logging
logging.warning("user [alex] attempted wrong password more than 3 times")
logging.critical("server is down")
看一下这几个日志级别分别代表什么意思
Level When it’s used
DEBUG Detailed information, typically of interest only when diagnosing problems.
INFO Confirmation that things are working as expected.
WARNING An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected.
ERROR Due to a more serious problem, the software has not been able to perform some function.
CRITICAL A serious error, indicating that the program itself may be unable to continue running.
2.如果想把日志写到文件里,也很简单
import logging
logging.basicConfig(filename='example.log',level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
3.自定义日志格式
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.basicConfig(format='%(asctime)s %(message)s',datefmt='%Y-%m-%d %H:%M:%S %p')
logging.warning('is when this event was logged.')
#输出
12/12/2010 11:46:36 AM is when this event was logged.
除了加时间,还可以自定义一大堆格式,下表就是所有支持的格式
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 会乱码
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s 用户输出的消息
4.日志同时输出到屏幕和文件
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
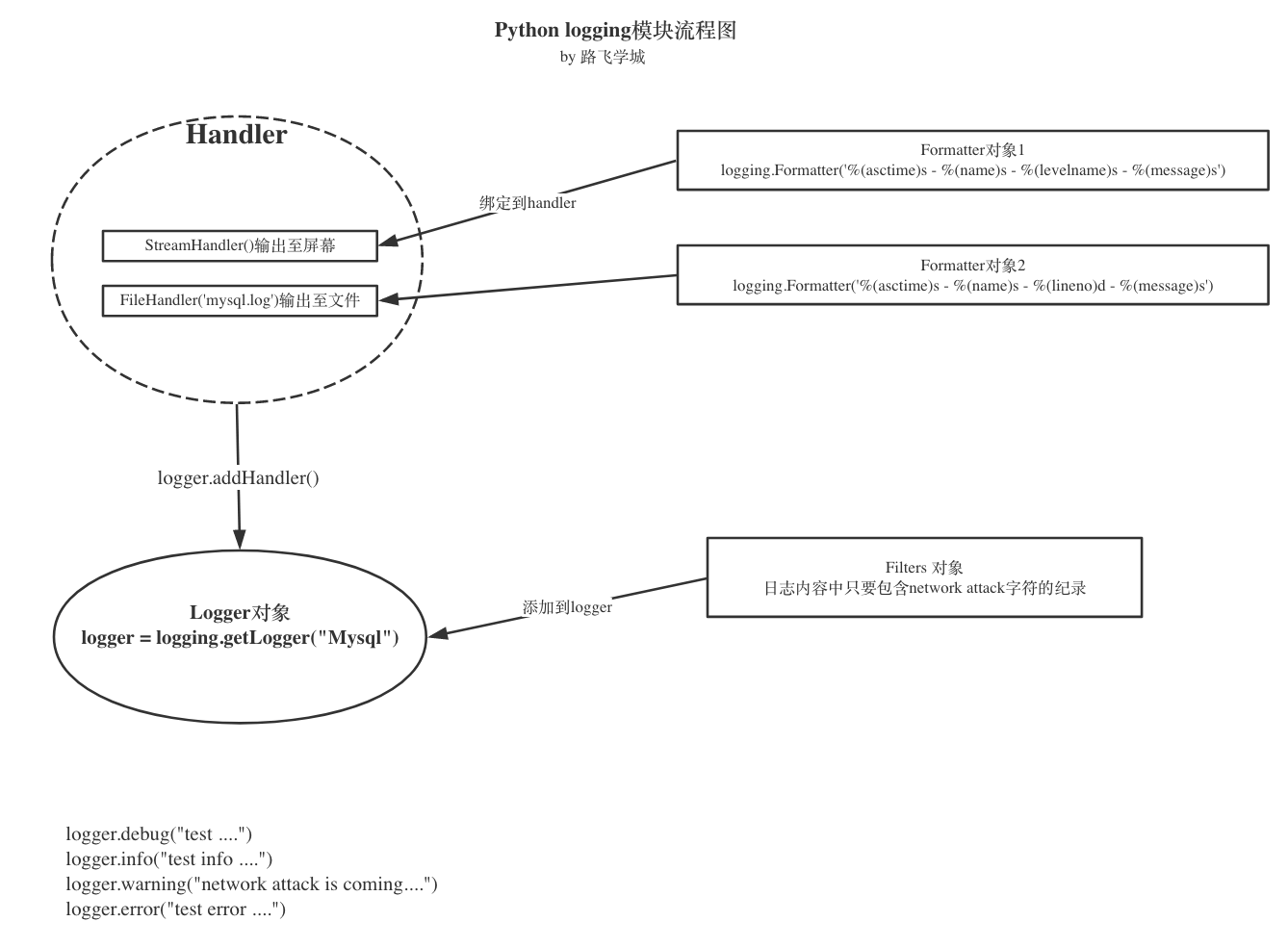
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger 提供了应用程序可以直接使用的接口;
handler 将(logger创建的)日志记录发送到合适的目的输出;
filter 提供了细度设备来决定输出哪条日志记录;
formatter 决定日志记录的最终输出格式。
他们之间的关系是这样的 图
5.每个组件的主要功能
5.1.logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
还可以绑定handler和filters
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
5.2.handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Handler可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
5.2.1.logging.StreamHandler 使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。
5.2.2.logging.FileHandler 和StreamHandler 类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件
5.2.3.logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
5.2.4.logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
5.3.formatter 组件
日志的formatter是个独立的组件,可以跟handler组合
fh = logging.FileHandler("access.log")
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter) #把formmater绑定到fh上
5.4.filter 组件
如果你想对日志内容进行过滤,就可自定义一个filter
class IgnoreBackupLogFilter(logging.Filter):
"""忽略带db backup 的日志"""
def filter(self, record): #固定写法
return "db backup" not in record.getMessage()
注意filter函数会返加True or False,logger根据此值决定是否输出此日志
5.4.1.然后把这个filter添加到logger中
logger.addFilter(IgnoreBackupLogFilter())
5.4.2.下面的日志就会把符合filter条件的过滤掉
logger.debug("test ....")
logger.info("test info ....")
logger.warning("start to run db backup job ....")
logger.error("test error ....")
5.4.3.一个同时输出到屏幕、文件、带filter的完成例子
import logging
class IgnoreBackupLogFilter(logging.Filter):
"""忽略带db backup 的日志"""
def filter(self, record): #固定写法
return "db backup" not in record.getMessage()
#console handler
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
#file handler
fh = logging.FileHandler('mysql.log')
#fh.setLevel(logging.WARNING)
#formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
#bind formatter to ch
ch.setFormatter(formatter)
fh.setFormatter(formatter)
logger = logging.getLogger("Mysql")
logger.setLevel(logging.DEBUG) #logger 优先级高于其它输出途径的
#add handler to logger instance
logger.addHandler(ch)
logger.addHandler(fh)
#add filter
logger.addFilter(IgnoreBackupLogFilter())
logger.debug("test ....")
logger.info("test info ....")
logger.warning("start to run db backup job ....")
logger.error("test error ....")
6.文件自动截断例子
import logging
from logging import handlers
logger = logging.getLogger(__name__)
log_file = "timelog.log"
#fh = handlers.RotatingFileHandler(filename=log_file,maxBytes=10,backupCount=3)
fh = handlers.TimedRotatingFileHandler(filename=log_file,when="S",interval=5,backupCount=3)
formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
logger.warning("test1")
logger.warning("test12")
logger.warning("test13")
logger.warning("test14")
-----------------------------------------------------------------------------------------------
re 模块
正则表达式
1.引子:
请从以下文件里取出所有的手机号
姓名 地区 身高 体重 电话
况咏蜜 北京 171 48 13651054608
王心颜 上海 169 46 13813234424
马纤羽 深圳 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 深圳 177 54 18835324553
贺婉萱 深圳 174 52 18933434452
叶梓萱 上海 171 49 18042432324
杜姗姗 北京 167 49 13324523342
拿到所有手机号 1.1.
f = open("兼职白领学生空姐模特护士联系方式.txt",'r',encoding="gbk")
phones = []
for line in f:
name,city,height,weight,phone = line.split()
if phone.startswith('') and len(phone) == 11:
phones.append(phone)
print(phones) 1.2.
import os
f = open('联系方式.txt','r',encoding='utf-8')
data = f.read()
phones = re.findall("[0-9]{11}",data)
print(phones)
就叫正则表达式:正则表达式就是字符串的匹配规则
2.re常见的匹配语法有以下几种
re.match 从头开始匹配 只匹配一个就返回 场景:手机号
re.search 全局匹配 只匹配一个就返回
re.findall 把所有匹配到的字符放到以列表中的元素返回 phones = re.findall('1[0-9]{10}', data)
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
re.fullmatch 全部匹配 re.match('[0-9]','123dasd') = <_sre.SRE_Match object; span=(0, 1), match=''>
re.search('[0-9]','abc1d3e') = <_sre.SRE_Match object; span=(3, 4), match=''> #
re.findall('[0-9]','abc1d3e') = ['', '']
注:
match 和 search 返回是一个对象 是这样拿值的:需要先判断 否则会报错
res = re.search('[0-9]','abs1d2')
if res:
print(res.group()) re.match('sd','sd*sda') == re.search('^sd','sd*sda') == re.search('\Asd','sd*sda') == sd
re.search('sd$','adssasd') == re.search('sd\Z','adssasd') == sd
re.search('[0-9]','alex23') == re.search('\d','alex23') == 2
3.示例:
re.search('.','*a2a3sdas') == * #任意一个字符
re.search('^sd','sd*sda') == sd #以什么开头
re.search('sd$','sdasd') == sd #以什么结尾
re.match('b$','b') == b #只匹配一个
re.search('ab*','abblex') == abb #*前一个字符0次或多次
re.search('ab*','sdad') == a
re.search('ab+','sdad') == None
re.search('ab+','sdabbbd') == abbb
re.search('a+','sdaa') == aa #+前一个字符1次或多次
re.search('.+','abcd') == abcd #匹配到所有
re.search('a?','aasad') == a #?前一个字符0次或1次
re.search('a{2}','dddaa') == aa #{m}前一个字符m次
re.search('[0-9]','asd232') == 2 #[] 匹配0-9一次 [a-z]
re.search('[a-z]{1,5}','2lex') == lex #{n,m}匹配前一个字符n到m次
re.search('[a|A]lex','alex') == alex #|或 匹配左或右的字符
re.search('([a-z]+)([0-9]+)','alex123').groups() == ('alex', '') #()()分组匹配
re.search('\Aalex','alex') == alex #\A以什么开头
re.search('sd\Z','adssasd') == sd #\Z以什么结尾
re.search('\d','alex23') == 2 #\d匹配数字0-9
re.search('\d+','alex23') == 23
re.search('\D','alex23') == a #匹配非数字
re.search('\D+','@*&234alex23') == @*&
re.search('\w+','!@#23saAS') == 23saAS #匹配[A-Z a-z 0-9]
re.search('\W+','!$@23saAS') == !$@ #匹配非[A-Z a-z 0-9] 即:特殊字符
re.findall('\s','alex\njack\rma ck\tjack') == ['\n', '\r', ' ', '\t'] #匹配空白字符 \n \r \t
s='' #分组,可定义成字典
re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_year>\d{4})',s).groups() == ('', '', '')
re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_year>\d{4})',s).groupdict() == {'province': '', 'city': '', 'born_year': ''}
4.常用的表达式规则
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,(re.S)则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,(re.M)这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾, 若指定flags MULTILINE(re.M) ,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到foo1
'*' 匹配*号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa'
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次 ,re.search('b?','alex').group() 匹配b 0次
'{m}' 匹配前一个字符m次 ,re.search('b{3}','alexbbbs').group() 匹配到'bbb'
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45' '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,相当于re.match('abc',"alexabc") 或^
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
'\s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","").groupdict("city") 结果{'province': '', 'city': '', 'birthday': ''}
.分割:re.split() 替换:re.sub() 全部匹配:re.fullmatch() 全部匹配:pattern = re.compile() pattern.fullmatch() 效率高
s='alex22jack23jinxin50|mack-oldboy'
re.split('\d+|\||-',s) == ['alex', 'jack', 'jinxin', '', 'mack', 'oldboy']
re.findall('\d+|\||-',s) = ['', '', '', '|', '-']
s='alex22jack23jinxin50\mack-oldboy'
re.split('\\\\',s) == ['alex22jack23jinxin50', 'mack-oldboy']
s='9-2*5/3+7/3*99/4*2998+10*568/14'
re.split('\W+',s) == ['', '', '', '', '', '', '', '', '', '', '', '']
re.split('\W+',s,maxsplit=3) == ['', '', '', '3+7/3*99/4*2998+10*568/14']
re.split('[-\*/\+]',s) == ['', '', '', '', '', '', '', '', '', '', '', ''] s = 'alex22jack23jinxin50\\mack-oldboy'
re.sub('\d+','_',s) == 'alex_jack_jinxin_\\mack-oldboy'
re.sub('\d+','_',s,count=2) == 'alex_jack_jinxin50\\mack-oldboy' re.fullmatch('\w+@\w+\.(com|cn|edu)','alex@oldboyedu.com') # 慢 规则需要转换成bytes需时间 pattern = re.compile('\w+@\w+\.(com|cn|edu)') #快 规则转换bytes1次就可以了
pattern.fullmatch('alex@oldboyedu.com') == <_sre.SRE_Match object; span=(0, 18), match='alex@oldboyedu.com'>
6.标识符 Flags
re.I #忽略大小写 re.IGNORECASE
re.M #多行模式 re.MULTILINE
re.S #改变.的行为,.是任意字符,除了换行符\n re.DOTALL
re.X #可对正则 规则 注释 re.VERBOSE re.search('a','Alex',re.I) == A
re.search('foo.$','foo1\nfoo2\n') == foo2
re.search('foo.$','foo1\nfoo2\n',re.M) == foo1
re.search('^s','\nsds',re.M) == s
re.search('.','\n') == None
re.search('.','\n',re.S) == \n
re.search('.','alex') == a
re.search('. #test','alex') == None
re.search('. #test','alex',re.X) = a
总结:
1.logging 模块
2.re 模块
模块 - logging/re的更多相关文章
- Python标准模块--logging
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同 ...
- 日志模块logging使用心得
在应用程序使用中,日志输出对应用维护人员.开发人员判断程序的问题起重要作用. 那么在python中如何定义程序的日志输出? 推荐使用日志模块logging 需求:实现日志内容输出在文件中和控制器中 i ...
- python日志模块logging
python日志模块logging 1. 基础用法 python提供了一个标准的日志接口,就是logging模块.日志级别有DEBUG.INFO.WARNING.ERROR.CRITICAL五种( ...
- Python 日志模块logging
logging模块: logging是一个日志记录模块,可以记录我们日常的操作. logging日志文件写入默认是gbk编码格式的,所以在查看时需要使用gbk的解码方式打开. logging日志等级: ...
- shelve模块,sys模块,logging模块
1.shelve模块 用于序列化的模块,shelve模块比pickle模块简单,只有open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型. impor ...
- python最重要的模块logging
logging模块 这个模块是目前最重要的模块!!!我一定给讲透彻一点 很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python中的loggi ...
- Python标准模块--logging(转载)
转载地址:http://www.cnblogs.com/zhbzz2007/p/5943685.html#undefined Python标准模块--logging 1 logging模块简介 log ...
- 模块 -logging
模块 -logging 一:在控制台显示:默认 import logging logging.debug("debug") logging.info("debug&quo ...
- os模块/sys模块/json/pickle模块/logging模块(day16整理)
目录 今日内容 os模块 对文件操作 对文件夹此操作 辅助性的 了解 sys模块 json和pickle模块 json模块 pickle模块 logging模块 日志级别 添加设置 自定义配置 今日内 ...
- Python日志模块logging简介
日志处理是项目的必备功能,配置合理的日志,可以帮助我们了解系统的运行状况.定位位置,辅助数据分析技术,还可以挖掘出一些额外的系统信息. 本文介绍Python内置的日志处理模块logging的常见用法. ...
随机推荐
- Atitit.进程管理常用api
Atitit.进程管理常用api 1 常用api 进程列表 getProcessList 是否存在某个进程判断 isExistProcess 启动进程run Sleep Exit Shutdown 作 ...
- Sublime Text 2/3如何支持中文GBK编码(亲测实现)
Sublime Text 2/3如何支持中文GBK编码 听语音 | 浏览:17594 | 更新:2014-03-17 10:52 1 2 3 4 5 分步阅读 Sublime Text默认是只支持UT ...
- Xcode5下使用纯代码构建简单的HelloWorld程序
转自:http://blog.csdn.net/developerxyf/article/details/12874935 新发布的Xcode5在使用模板创建工程的时候取消了以往是否要选择storyb ...
- 基于libmemcached,php扩展memcached的安装
基于libmemcached,php扩展memcached的安装 张映 发表于 -- 分类目录: php 标签:libmemcached, memcached, php, 安装 一,为什么要装memc ...
- winform播放音乐
string sound = Application.StartupPath +@"\song\123.wav"; //Application.StartupPath:程序exe所 ...
- 初探csrf学习笔记
以下是学习了对CSRF的理解,大家切勿作为标准,如有出错请告之! 严禁转载.不想拿自己刚学到的知识去[误人子弟]之所以写出来是让自己巩固和增加理解,他日对此文有不当之处自会修改. [00x1]csrf ...
- openssl基础
OpenSSL 是一个安全套接字层密码库,囊括主要的密码算法.常用的密钥和证书封装管理功能及SSL协议,并提供丰富的应用程序供测试或其它目的使用. OpenSSL is an open source ...
- Generating SSH Keys on windows
two ways here I provide: use openSSH command line on git bash(such as msysgit bash) ls -al ~/.ssh ss ...
- GraphicsMagick +im4java高并发处理大型网站图片工具-图片剪切、遮蔽、水印添加之环境搭建
环境: centos 6.5 GraphicsMagick 下载安装 准备环镜: 需要依赖zlib图片操作函数库 下载地址:http://www.zlib.net/ 编译安装 .tar.gz cd z ...
- Elasticsearch增、删、改、查操作深入详解
引言: 对于刚接触ES的童鞋,经常搞不明白ES的各个概念的含义.尤其对“索引”二字更是与关系型数据库混淆的不行.本文通过对比关系型数据库,将ES中常见的增.删.改.查操作进行图文呈现.能加深你对ES的 ...