Arm Cache学习总结
cache,高速缓存,其原始意义是指访问速度比一般随机存取内存(RAM)快的一种RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。
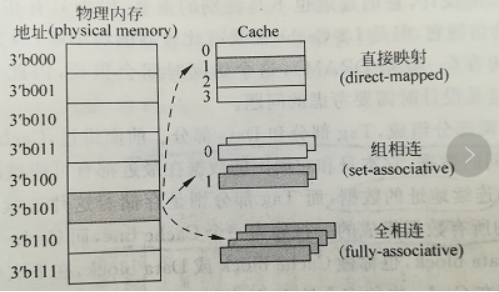
1、cache映射方式
cache中的数据就是物理内存中的数据的子集,那么对于物理内存的一个数据,根据cache中可以放置这个数据位置的多少,可以分为三种:①如果cache中只有一个位置可以容纳这个数据,则为直接映射的cache;②如果cache中有多个地方可以放置这个数据,它就是组相联的cache;③如果cache中的任何地方都可以放置这个数据,那么它就是全相连的cache;如下图所示
2、cache的结构
更详细的讲,cache的结构其实和内存的结构类似,也包含地址和内容,只是cache的内容除了存的数据(data)之外,还包含存的数据的物理内存的地址信息(tag),因为CPU发出的寻址信息都是针对物理内存发出的,所以cache中除了要保存数据信息之外,还要保存数据对应的地址,这样才能在cache中根据物理内存的地址信息查找物理内存中对应的数据。(当然为了加快寻找速度,cache中一般还包含一个有效位(valid),用来标记这个cache line是否保存着有效的数据)。一个tag和它对应的数据组成的一行称为一个cache line。如下图所示,下表中的一行就是一个cache line。
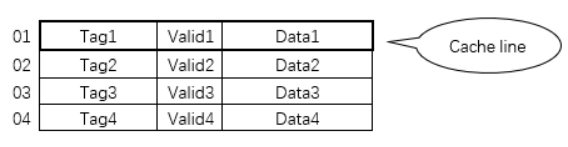
图3 cache的基本结构
具体的Data、Valid、Tag各有多大,在介绍了内存的地址划分之后再在下文中讲。
3、cache中去寻找对应的数据
知道了cache的结构之后,如何在cache中去寻找对应的数据呢?简单起见,我们先选择 直接映射的cache组成方式进行下文的分析。
首先对于一段物理内存(block),该物理内存上的每个字节的地址划分为以下几段:[3]

图4 处理器物理内存地址的划分
这样的话物理内存中的数据到cache的映射关系如下图5所示:

图5 cache的查找过程
上图的映射原则就是:根据物理地址的中间三位(index字段)来定位当前数据应该在cache的哪一行,把物理地址的tag字段和该地址对应的内容放入对应的cache line的tag字段和data字段,并把相应的valid位置1。那么在之后进行cache寻找的时候就可以根据cache line的tag字段来辨认当前line中的数据是数据哪个block的。
上图5中的地址00 000 00~11 111 11按照图4的原则进行地址划分:地址的最高两位为Tag字段;中间三位为index字段;最低两位为Block Offset 字段;由于Block Offset是两位,也就是一个block的大小是2²=4个字节的数据,也就是一个cache line的data字段包含4个字节的数据;index为3位,说明cache共包含2³=8个组(对于直接映射的cache,也称为8个行);很明显,cache的一个行中只能存储1 块(Block )=4字节的数据,但是按照图5的映射方式,会有2^(tag位数) = 2^2 = 4块的数映射到同一个行,此时通过Tag字段的比较来辨别是不是我们要取数据的地址,如果不是的话,也就是发生了cache的缺失。如图5的Block 0和Block 1的index字段都是000,按照上面的理论它们都应该映射到第 000=0行(这儿的行也就是组,因为图5是直接映射的cache),但是现在第0行的内容是K、L、M、N,也就是Block 1的内容,为什么呢?仔细看该cache line的tag=01,映射到第0行的块只有Block 1的tag字段=01,所以可以得知此时该cache line中存储的数据是Block 1的数据,此时如果CPU发出的访存请求是访问Block 0 的话,也就是发生了缺失。此时进一步定量分析的话,共有4个数据块竞争使用cache 第0行的位置,也就是说cache的命中率为25%。
上面的过程总结起来就是:物理内存的索引字段(Index)选择cache 的行,通过对比物理内存和cache line的Tag来判断是否命中。块偏移字段(Block Offset)可以从cache line的数据块中选择期望数据。注意在这个过程中cache的index是不占空间的,它就类似于物理内存的地址,对于物理内存来说是通过地址去寻找数据,对于cache来说,是通过index来找到对应的cache line,或者更通俗的讲就是:cache line的地址对应的就是物理内存的index字段。
此时该cache的容量计算如下:每一个cache line的数据字段占4个字节,共2³=8行,所以数据占据4×8=32个字节,一个cache line中tag字段和valid位占2+1=3bit,整个cache的tag+valid=3bit×8行=24bit=3Byte,通常情况下我们都是一cache中数据部分占的空间表示cache的容量,也就是32字节,但是实际上,它还额外多占用了3字节的存储空间[4]。
图5的分析是针对直接映射的cache进行的,对于组相联或者全相连的cache的分析与之类似。如果是组相连的cache,每个组(set)里面包含多个行(line),通过内存地址的index字段来寻址组,确定组之后再根据tag来确定是否命中;对于全相连的cache,就不需要index字段了,因为全相连的cache相当于只有一个组的组相连cache。这是只需要根据要寻址的地址的tag来逐一与cache中的tag字段比较,如果有与之匹配的cache line,也就是cache hit了,如果遍历整个cache,也没有找到匹配的cache line,那就是cache miss了。
注:为了叙述的简单性,省略了内存地址通过TLB的的虚实转换部分,由[1]可知,内存地址的Tag部分其实是需要先经过TLB的转化才能够去和cache line的tag部分去进行匹配的。
4、cache的读写机制
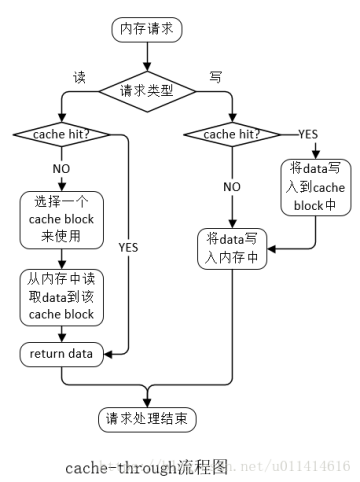
cache的读写一般遵循两种机制:cache-through和cache-back。
cache-through:数据更新时,在写入缓存之后,立即也将数据写入内存,如果此时请求指定的地址没有对应的缓存,那么直接写入内存。
cache-back:数据更新时,在写入缓存之后,不会立即更新对应的内存,只有当该缓存被用于其他的内存数据(即数据被替换出缓存)时,被修改的缓存中的数据才会被覆盖式地写入到对应的内存中。

备注:
(1)“选择cache block”的算法有很多种,比如:最久未使用算法(LRU)、先进先出算法(FIFO)、最近最少使用算法(LFU)、非最近使用算法(NMRU)等。
(2)DRAM,动态随机存取存储器(Dynamic Random Access Memory,DRAM)是一种半导体内存,主要的作用原理是利用电容内存储电荷的多寡来代表一个二进制比特(bit)是1还是0。由于在现实中电容会有漏电的现象,导致电位差不足而使记忆消失,因此除非电容经常周期性地充电,否则无法确保记忆长存。由于这种需要定时刷新的特性,因此被称为“动态”内存。
(3)SRAM,静态随机存取存储器(Static Random-Access Memory,SRAM)是随机存取存储器的一种。所谓的“静态”,是指这种存储器只要保持通电,里面储存的数据就可以恒常保持[1]。相对之下,动态随机存取存储器(DRAM)里面所储存的数据就需要周期性地更新。然而,当电力供应停止时,SRAM储存的数据还是会消失(被称为volatile memory),这与在断电后还能储存资料的ROM或闪存是不同的。
5 文件Cache相关API及其实现
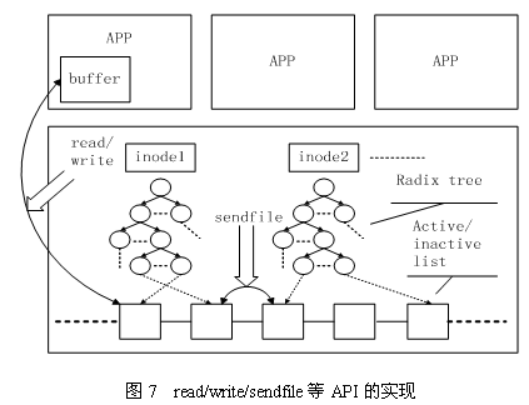
Linux内核中与文件Cache操作相关的API有很多,按其使用方式可以分成两类:一类是以拷贝方式操作的相关接口,如read/write/sendfile等,其中sendfile在2.6系列的内核中已经不再支持;另一类是以地址映射方式操作的相关接口,如mmap等。
第一种类型的API在不同文件的Cache之间或者Cache与应用程序所提供的用户空间buffer之间拷贝数据,其实现原理如图7所示。
第二种类型的API将Cache项映射到用户空间,使得应用程序可以像使用内存指针一样访问文件,Memory map访问Cache的方式在内核中是采用请求页面机制实现的,其工作过程如图8所示。
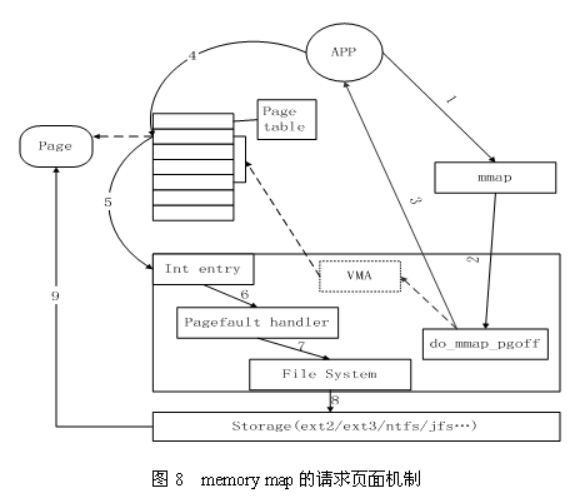
首先,应用程序调用mmap(图中1),陷入到内核中后调用do_mmap_pgoff(图中2)。该函数从应用程序的地址空间中分配一段区域作为映射的内存地址,并使用一个VMA(vm_area_struct)结构代表该区域,之后就返回到应用程序(图中3)。当应用程序访问mmap所返回的地址指针时(图中4),由于虚实映射尚未建立,会触发缺页中断(图中5)。之后系统会调用缺页中断处理函数(图中6),在缺页中断处理函数中,内核通过相应区域的VMA结构判断出该区域属于文件映射,于是调用具体文件系统的接口读入相应的Page Cache项(图中7、8、9),并填写相应的虚实映射表。经过这些步骤之后,应用程序就可以正常访问相应的内存区域了。
参考博客
https://blog.csdn.net/baidu_35679960/article/details/78610804
https://blog.csdn.net/wangwei222/article/details/79748597
https://www.cnblogs.com/pangblog/p/3362171.html
Arm Cache学习总结的更多相关文章
- ARM指令学习,王明学learn
ARM指令学习 一.算数和逻辑指令 1— MOV 数据传送指令 2.— MVN 数据取反传送指令 3.— CMP 比较指令 4.— CMN 反值比较指令 5.— TST 位测试 ...
- ARM寄存器学习,王明学learn
ARM寄存器学习 ARM微处理器共有37个32位寄存器,其中31个为通用寄存器,6个为状态寄存器.但是这些寄存器不能被同时访问,具体哪些寄存器是可以访问的,取决ARM处理器的工作状态及具体的运行模式. ...
- 痞子衡嵌入式:史上最强ARM Cortex-M学习资源汇总(持续更新中...)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是ARM Cortex-M学习资源. 类别 资源 版本 短评 官方汇总 cortex-m-resources / ARM公司专家Josep ...
- arm汇编学习(三)
一.ndk编译android上运行的c程序 新建个hello目录,底下要有jni目录,下面就是Android.mk文件 1.Android.mk文件内容如下: LOCAL_PATH:= $(call ...
- android ARM 汇编学习 —— hello world
android ARM 汇编学习—— 在 android 设备上编译c/cpp代码并用objdump/readelf等工具分析 adb putty 连上手机,用busybox vi 写一个 hello ...
- spring cache 学习——@CachePut 使用详解
1. 功能说明 当需要在不影响方法执行的情况下更新缓存时,可以使用 @CachePut,也就是说,被 @CachePut 注解的缓存方法总是会执行,而且会尝试将结果放入缓存(当然,是否真的会缓存还跟一 ...
- 关于ARM NEON学习的一些资料
在对基于ARM-v7处理器及以上的程序进行优化时,可以使用neon优化技术来加速程序.不过搞这个的人比较少,所以网上有用的资料很稀少.我翻了半天国内国外的博客,发现还是ARM公司的帮助网站最有用: h ...
- arm汇编学习(五)
新增个手写GNU语法arm的方法,以后可以狂逆狂写 hello.S文件 .data msg: .ascii "Hello, ARM!\n" len = . - msg .text ...
- android ARM 汇编学习—— 在 android 设备上编译c/cpp代码并用objdump/readelf等工具分析
学习 android 逆向分析过程中,需要学习 Arm 指令,不可避免要编写一些 test code 并分析其指令,这是这篇文档的背景. 在目前 android 提供的开发环境里,如果要编写 c / ...
随机推荐
- [BZOJ5250][九省联考2018]秘密袭击(DP)
5250: [2018多省省队联测]秘密袭击 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 3 Solved: 0[Submit][Status][D ...
- 【欧拉回路】【Fleury算法】CDOJ1642 老当益壮, 宁移白首之心?
题意: 构造一个01串,使得满足以下条件: 1. 环状(即首尾相连) 2. 每一位取值为0或1 3. 长度是2^n 4. 对于每个(2^n个)位置,从其开始沿逆时针方向的连续的n位01串(包括自己) ...
- ContOS下部署javaweb项目
1.jdk安装 下载jdk jdk-7u79-linux-x64.rpm # rpm -ivh jdk-7u79-linux-x64.rpm安装 # rpm -e jdk-7u79-linux-x6 ...
- (转)Linux下数据段的区别(数据段、代码段、堆栈段、BSS段)
进程(执行的程序)会占用一定数量的内存,它或是用来存放从磁盘载入的程序代码,或是存放取自用户输入的数据等等.不过进程对这些内存的管理方式因内存用途 不一而不尽相同,有些内存是事先静态分配和统一回收的, ...
- Integer引用类型问题
public class TestMain { public static void main(String[] args) { Integer integer = 2; go(2); System. ...
- SIP消息类型和消息格式
转自:http://blog.chinaunix.net/uid-1797566-id-2840904.html sip消息类型和消息格式 SIP是一个基于文本的协议,使用的是UTF-8字符集. SI ...
- Android进阶笔记:AIDL内部实现详解 (一)
AIDL内部实现详解 (一) AIDL的作用是实现跨进程通讯使用方法也非常的简单,他的设计模式是典型的C/S架构.使用AIDL只要在Client端和Server端的项目根目录下面创建一个aidl的文件 ...
- C/C++ 宏定义中#、##、#@的区别
#表示:对应变量字符串化 ##表示:把宏参数名与宏定义代码序列中的标识符连接在一起,形成一个新的标识符 连接符#@:它将单字符标记符变换为单字符,即加单引号.例如: #define B(x) #@x ...
- [转载]《Delphi 版 everything、光速搜索代码》 关于获取文件全路径 GetFullFileName 函数的优化
Delphi 版 everything.光速搜索代码>,文章中关于获取文件全路径的函数:GetFullFileName,有一个地方值得优化. 就是有多个文件,它们可能属于同一个目录. 譬如 Sy ...
- 流畅的python第十五章上下文管理器和else块学习记录
with 语句和上下文管理器for.while 和 try 语句的 else 子句 with 语句会设置一个临时的上下文,交给上下文管理器对象控制,并且负责清理上下文.这么做能避免错误并减少样板代码, ...