从“顶点小说”下载完整小说——python爬虫
此程序只是单纯的为了练习而做,首先这个顶点小说非收费型的那种小说网站(咳咳,我们应该支持正版,正版万岁,✌)。经常在这个网站看小说,所以就光荣的选择了这个网站。此外,其实里面是自带下载功能的,而且支持各种格式:(TXT,CHM,UMD,JAR,APK,HTML),所以可能也并没有设置什么反爬措施,我也只设置了请求头。然后内容是保存为txt格式。
内容涉及到request的使用(编码问题),xpath的使用,字符串的处理(repalce产生列表达到换行效果),文件I/O
顶点小说:https://www.booktxt.net
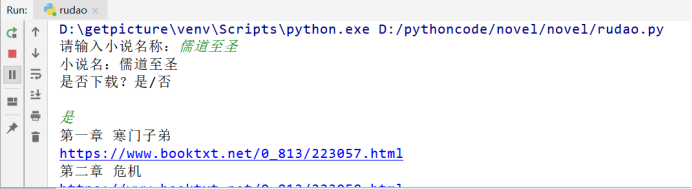
代码功能:输入小说名,若顶点小说中存在,则可直接下载。最终效果如下:
# -*- coding:utf-8 -*-
import requests
from lxml import etree novel_name = '' #全局变量,存放小说名称
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'} def get_url(name):
'''
通过百度获取小说在顶点小说中的网址
name:小说名
'''
#site: booktxt.net + 小说名 指定为该网站搜索
baidu = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=site%3A%20booktxt.net%20'+name #获取该小说在顶点小说中的网址
r = requests.get(baidu, headers=headers)
html = etree.HTML(r.content)
try:
#提取网址链接,若不存在则退出程序
url = html.xpath('//*[@id="1"]/h3/a/@href')[0]
url =requests.get(url, headers=headers).url
except:
print("该小说不存在!")
exit(0)
if url[-4:] == 'html': #搜索结果为某一章节,结果无效
print("该小说不存在!")
exit(0)
get_chapter(url) #获取小说章节 def get_chapter(url):
'''
获取搜索到的小说名,并询问是否下载 :param url: 小说的链接
'''
global novel_name r = requests.get(url=url,headers=headers)
coding = r.apparent_encoding #获取网页编码格式 html = etree.HTML(r.content, parser=etree.HTMLParser(encoding=coding)) novel_name = html.xpath('//*[@id="info"]/h1/text()')[0]
print('小说名:'+novel_name+'\n是否下载?是/否\n')
flag = input()
if flag=='否':
print('退出系统')
exit(0) list = html.xpath('//*[@id="list"]/dl/dd[position()>8]') #获取章节列表
for item in list:
chapter_name = item.xpath('./a')[0].text #每一章的名称
print(chapter_name)
link = item.xpath('./a/@href')[0] #每章的网址链接
full_link = url+link #每章的完整地址
print(full_link)
get_text(chapter_name,full_link) def get_text(name,link):
'''
获取每章的内容并写入至txt文件中
:param name: 小说章节名
:param link: 章节链接
:return:
''' r = requests.get(url=link, headers=headers)
coding = r.apparent_encoding
r = r.content html = etree.HTML(r, parser=etree.HTMLParser(encoding=coding))
#获取一章内容,并以空格为界分割成字符串列表
text = html.xpath('string(//*[@id="content"])').split()
#print(text)
#创建小说名.txt文件
with open('{}.txt'.format(novel_name),'a+',encoding='utf-8') as f:
f.write('\t'*3+name+'\n') #章节名
for i in range(len(text)):
f.write(' '*4+text[i]+'\n') if __name__ == '__main__':
novel_name = input('请输入小说名称:')
get_url(novel_name)
从“顶点小说”下载完整小说——python爬虫的更多相关文章
- 小说免费看!python爬虫框架scrapy 爬取纵横网
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 风,又奈何 PS:如有需要Python学习资料的小伙伴可以加点击下方 ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- Python爬虫-爬小说
用途 用来爬小说网站的小说默认是这本御天邪神,虽然我并没有看小说,但是丝毫不妨碍我用爬虫来爬小说啊. 如果下载不到txt,那不如自己把txt爬下来好了. 功能 将小说取回,去除HTML标签 记录已爬过 ...
- Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)
从某些网站看小说的时候经常出现垃圾广告,一气之下写个爬虫,把小说链接抓取下来保存到txt,用requests_html全部搞定,代码简单,容易上手. 中间遇到最大的问题就是编码问题,第一抓取下来的小说 ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- python爬虫小说代码,可用的
python爬虫小说代码,可用的,以笔趣阁为例子,python3.6以上,可用 作者的QQ:342290433,汉唐自远工程师 import requests import refrom lxml i ...
随机推荐
- MSDN版、OEM版、RTM版、VOL版等的区别
我们常常听说操作系统的MSDN版.OEM版.RTM版.VOL版等等,它们到底是什么意思,有什么不同呢? (一)MSDN (Microsoft Developer Network)版MSDN软件是微软公 ...
- [EffectiveC++]item42:了解typename的双重意义
- iOS真机命令(自动化测试)
获取设备的的UDID idevice_id --list # 显示当前所连接设备的 udid instruments -s devices # 列出所有设备,包括真机.模拟器.mac idevicei ...
- MVC与EF结合:Contoso大学
中文教程 1.通过 MVC 5 使用 Entity Framework 6 Code First 入门 https://docs.microsoft.com/zh-cn/aspnet/mvc/over ...
- Spring Cloud(中文版)
原文链接:Spring Cloud I.云原生应用 Spring Cloud上下文:应用上下文服务 2.1.Bootstrap应用程序上下文 2.2.应用程序上下文层次结构 2.3.更改Bootstr ...
- PHP imagechar() 图形验证码 字体太小问题
bool imagechar ( resource $image , int $font , int $x , int $y , string $c , int$color ) imagechar() ...
- 2241. [SDOI2011]打地鼠【暴力+剪枝】
Description 打地鼠是这样的一个游戏:地面上有一些地鼠洞,地鼠们会不时从洞里探出头来很短时间后又缩回洞中.玩家的目标是在地鼠伸出头时,用锤子砸其头部,砸到的地鼠越多分数也就越高. 游戏中的锤 ...
- 【题解】洛谷P1966 [NOIP2013TG] 火柴排队(树状数组+逆序对)
次元传送门:洛谷P1966 思路 显然在两排中 每排第i小的分别对应就可取得最小值(对此不给予证明懒) 所以我们只在意两排的火柴是第几根 高度只需要用来进行排序(先把两个序列改成有序的方便离散化) 因 ...
- idea 和 maven学习
创建maven项目:http://www.cnblogs.com/wql025/p/5215570.html
- Maven搭建Spring MVC时使用jstl无效
1 Maven引入依赖jar包:jstl.jar和standard.jar <dependency> <groupId>javax.servlet</groupId> ...