Checkpoint的运行原理和源码实现
引言
Checkpoint 到底是什么和需要用 Checkpoint 解决什么问题:
- Spark 在生产环境下经常会面临 Transformation 的 RDD 非常多(例如一个Job 中包含1万个RDD) 或者是具体的 Transformation 产生的 RDD 本身计算特别复杂和耗时(例如计算时常超过1个小时) , 可能业务比较复杂,此时我们必需考虑对计算结果的持久化。
- Spark 是擅长多步骤迭代,同时擅长基于 Job 的复用。这个时候如果可以对计算的过程进行复用,就可以极大的提升效率。因为有时候有共同的步骤,就可以免却重复计算的时间。
- 如果采用 persists 把数据在内存中的话,虽然最快速但是也是最不可靠的;如果放在磁盘上也不是完全可靠的,例如磁盘会损坏,系统管理员可能会清空磁盘。
- Checkpoint 的产生就是为了相对而言更加可靠的持久化数据,在 Checkpoint 可以指定把数据放在本地并且是多副本的方式,但是在正常生产环境下放在 HDFS 上,这就天然的借助HDFS 高可靠的特征来完成最大化的可靠的持久化数据的方式。
- Checkpoint 是为了最大程度保证绝对可靠的复用 RDD 计算数据的 Spark 的高级功能,通过 Checkpoint 我们通过把数据持久化到 HDFS 上来保证数据的最大程度的安任性
- Checkpoint 就是针对整个RDD 计算链条中特别需要数据持久化的环节(后面会反覆使用当前环节的RDD) 开始基于HDFS 等的数据持久化复用策略,通过对 RDD 启动 Checkpoint 机制来实现容错和高可用;
Checkpoint 运行原理图
Checkpoint 源码解析
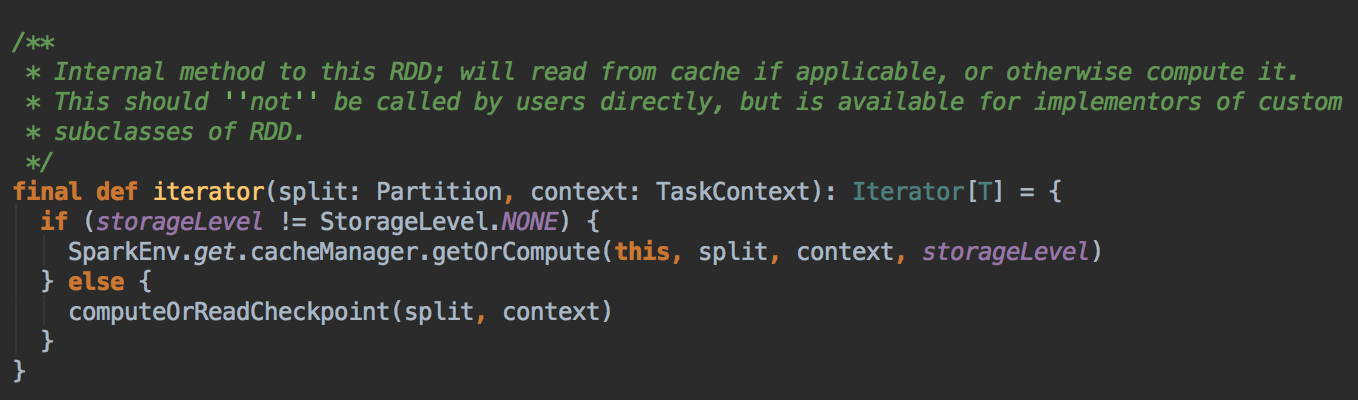
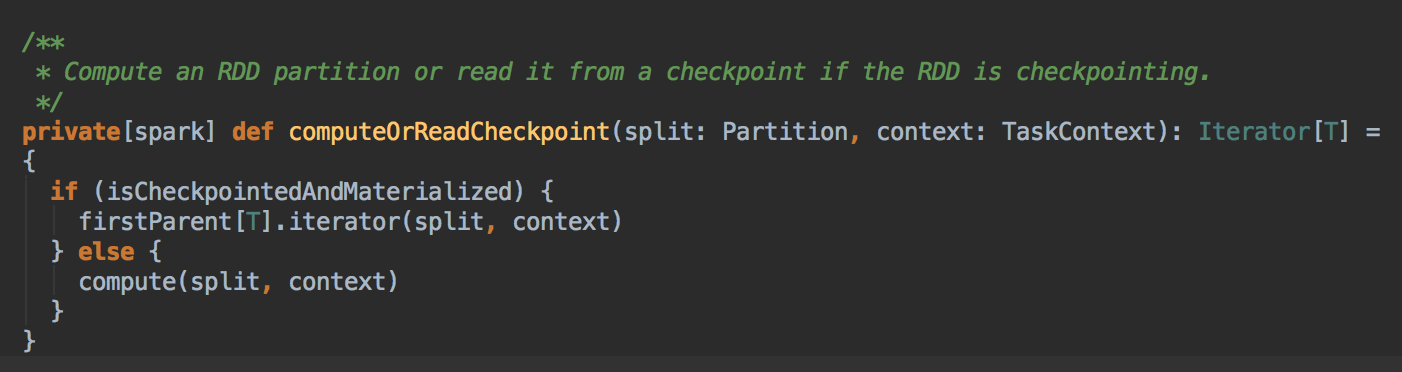
1、RDD.iterator 方法,它会先在缓存中查看数据 (内部会查看 Checkpoint 有没有相关数据),然后再从 CheckPoint 中查看数据
Checkpoint 有两种方法,一种是 reliably 和 一种是 locally
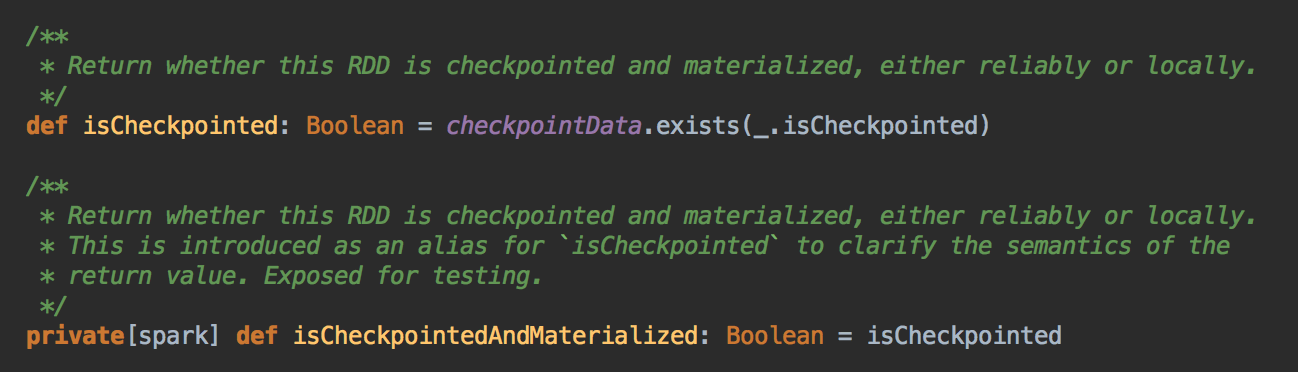
[下图是 RDD.scala 中的 isCheckpointed 变量和 isCheckpointedAndMaterialized 方法]
2、通过调用 SparkContext.setCheckpointDir 方法来指定进行 Checkpoint 操作的 RDD 把数据放在那里,在生产集群中是放在 HDFS 上的,同时为了提高效率在进行 Checkpoint 的时候可以指定很多目录
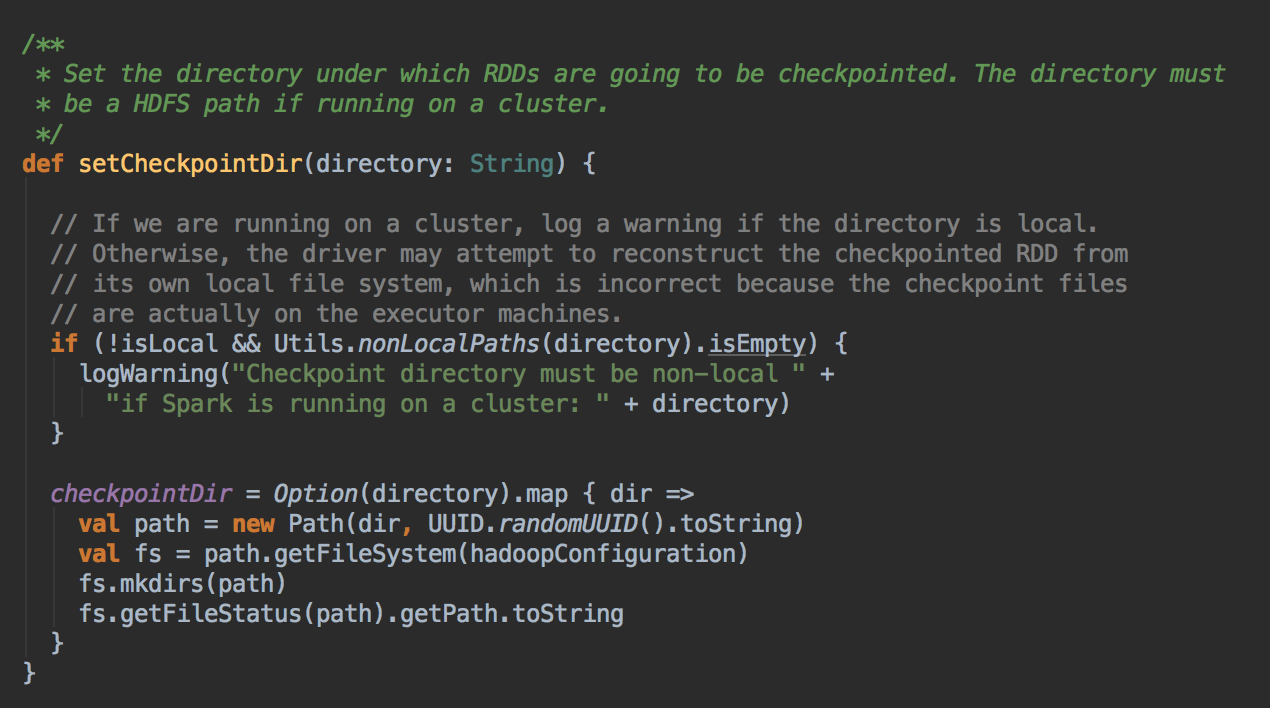
3、在进行 RDD 的 Checkpoint 的时候,其所依赖的所有 RDD 都会清空掉;官方建议如果要进行 checkpoint 时,必需先缓存在内存中。但实际可以考虑缓存在本地磁盘上或者是第三方组件,e.g. Taychon 上。在进行 checkpoint 之前需要通过 SparkConetxt 设置 checkpoint 的文件夹
[下图是 RDD.scala 中的 checkpoint 方法]

4、作为最佳实践,一般在进行 checkpoint 方法调用前都要进行 persists 来把当前 RDD 的数据持久化到内存或者是磁盘上,这是因为 checkpoint 是 lazy 级别,必需有 Job 的执行且在Job 执行完成后才会从后往前回溯哪个 RDD 进行了Checkpoint 标记,然后对该标记了要进行 Checkpoint 的 RDD 新启动一个Job 执行具体 Checkpoint 的过程;
5、Checkpoint 改变了 RDD 的 Lineage
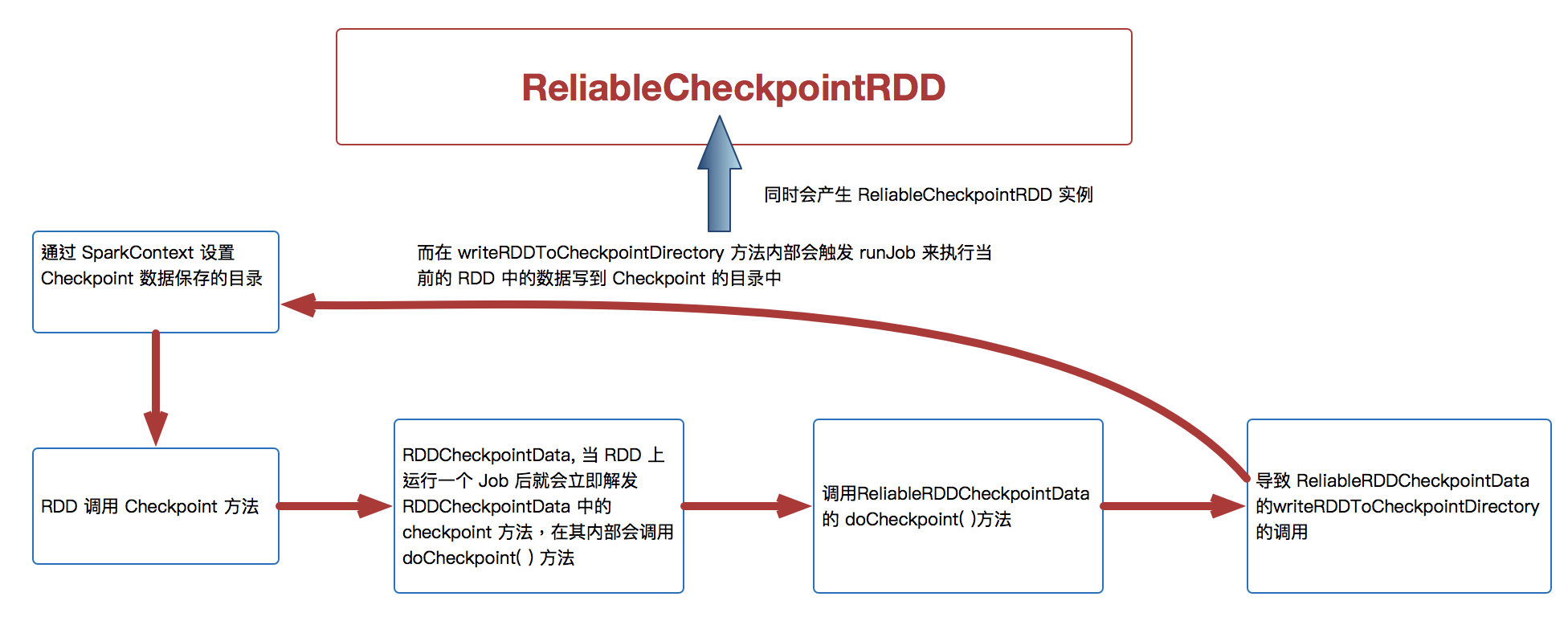
6、当我们调用了checkpoint 方法要对RDD 进行Checkpoint 操作的话,此时框架会自动生成 RDDCheckpointData

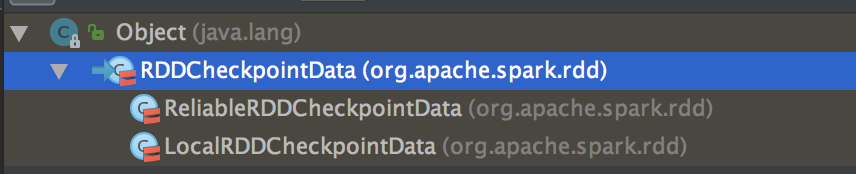
7、当 RDD 上运行一个Job 后就会立即触发 RDDCheckpointData 中的 checkpoint 方法,在其内部会调用 doCheckpoint( )方法,实际上在生产环境上会调用 ReliableRDDCheckpointData 的 doCheckpoint( )方法


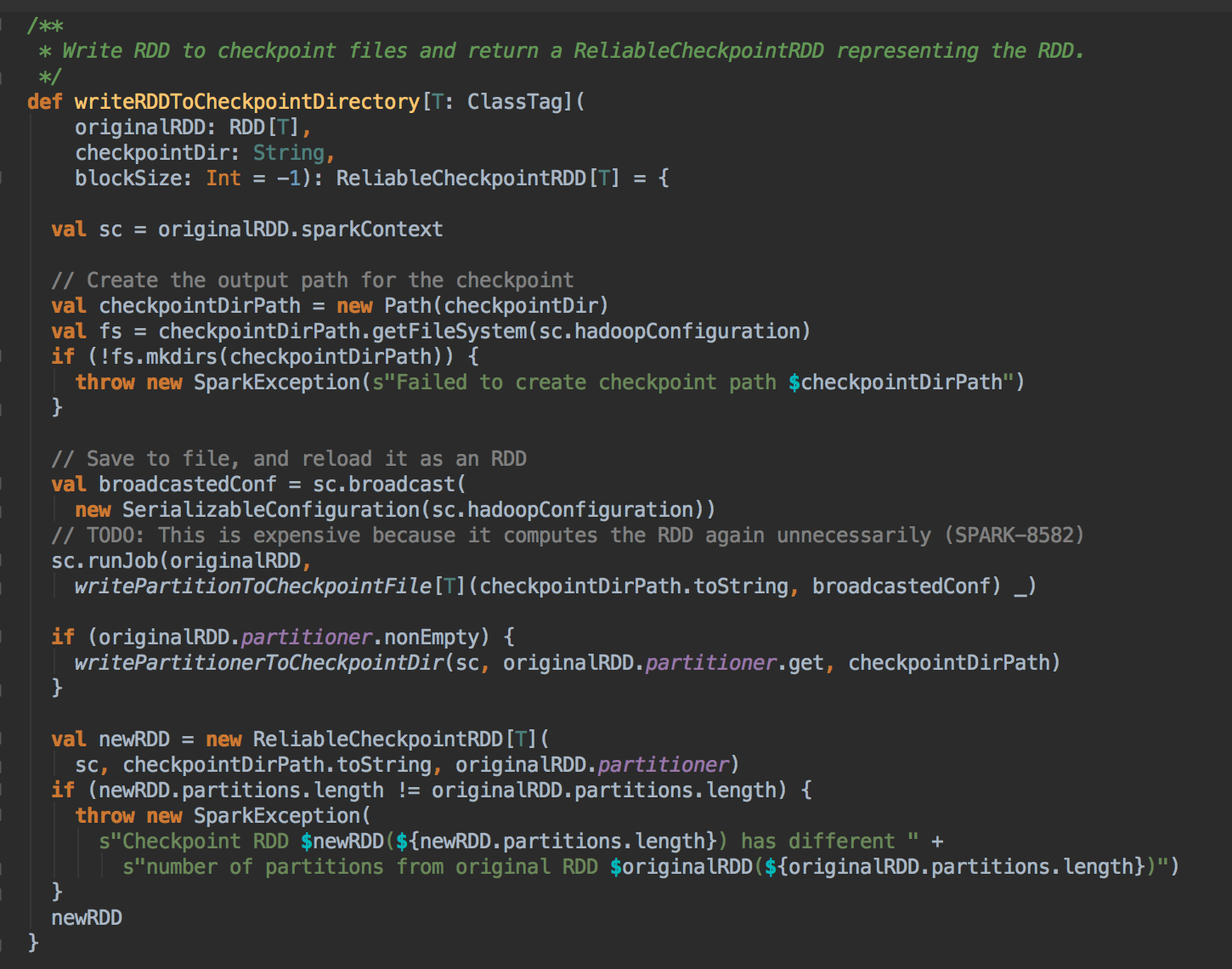
8、在生产环境下会导致 ReliableRDDCheckpointData 的 writeRDDToCheckpointDirectory 的调用,而在 writeRDDToCheckpointDirectory 方法内部会触发runJob 来执行当前的RDD 中的数据写到Checkpoint 的目录中,同时会产生ReliableCheckpointRDD 实例
Checkpoint的运行原理和源码实现的更多相关文章
- [Spark內核] 第41课:Checkpoint彻底解密:Checkpoint的运行原理和源码实现彻底详解
本课主题 Checkpoint 运行原理图 Checkpoint 源码解析 引言 Checkpoint 到底是什么和需要用 Checkpoint 解决什么问题: Spark 在生产环境下经常会面临 T ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- DStream-05 updateStateByKey函数的原理和源码
Demo updateState 可以到达将每次 word count 计算的结果进行累加. object SocketDstream { def main(args: Array[String]): ...
- Kubernetes Job Controller 原理和源码分析(一)
概述什么是 JobJob 入门示例Job 的 specPod Template并发问题其他属性 概述 Job 是主要的 Kubernetes 原生 Workload 资源之一,是在 Kubernete ...
- Kubernetes Job Controller 原理和源码分析(二)
概述程序入口Job controller 的创建Controller 对象NewController()podControlEventHandlerJob AddFunc DeleteFuncJob ...
- Kubernetes Job Controller 原理和源码分析(三)
概述Job controller 的启动processNextWorkItem()核心调谐逻辑入口 - syncJob()Pod 数量管理 - manageJob()小结 概述 源码版本:kubern ...
- Dubbo原理和源码解析之服务引用
一.框架设计 在官方<Dubbo 开发指南>框架设计部分,给出了引用服务时序图: 另外,在官方<Dubbo 用户指南>集群容错部分,给出了服务引用的各功能组件关系图: 本文将根 ...
- Dubbo原理和源码解析之标签解析
一.Dubbo 配置方式 Dubbo 支持多种配置方式: XML 配置:基于 Spring 的 Schema 和 XML 扩展机制实现 属性配置:加载 classpath 根目录下的 dubbo.pr ...
随机推荐
- 生成验证码程序C#
using System; using System.Data; using System.Configuration; using System.Collections; using System. ...
- Fast-RCNN
后面框架回归和分类都放到了神经网络里 测试速度提升100倍 训练10
- 请问C#中string是值传递还是引用传递?
https://www.cnblogs.com/xiangniu/archive/2011/08/17/2143486.html 学了这么久,终于弄明白了... 是引用传递 但是string又有值传递 ...
- [BestCoder Round #5] hdu 4956 Poor Hanamichi (数学题)
Poor Hanamichi Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- swift--获取window
有时候,我们需要频繁的调用界面,然后给当前页面加一个跟视图,这个时候就需要找windown, 代码如下: let rootVC = UIApplication.shared.delegate as! ...
- UE4读取脑电波MindWave插件(展示如何使用第三方库制作UE4插件)
MyEEGPlugin.uplugin { , , "VersionName": "1.0", "FriendlyName": " ...
- 15个常用GCC命令
GCC编译器非常强大 ,在各个发行的Linux系统中都非常流行,本文介绍的是一些常用的gcc编译选项 下面这段代码将回围绕整个文章: 编辑main.c如下. #include<stdio.h&g ...
- Django里面是文件静态化的方法
看Django官网的时候,由于自己的英语基础较差,而实现的谷歌翻译比较烂,只能看懂个大概.在文件静态化的时候,讲的比较繁琐一点,没怎么看懂,遂询问了一下其他人,明白了许多,但是细节需要注意的地方特别多 ...
- Java中list对象的三种遍历方式
1.增强for循环 for(String str : list) {//其内部实质上还是调用了迭代器遍历方式,这种循环方式还有其他限制,不建议使用. System.out.println(str); ...
- Oracle类型number与PG类型numeric对比和转换策略
Oracle 11g number 任意精度数字类型 http://docs.oracle.com/cd/B28359_01/server.111/b28318/datatype.htm#CNCPT3 ...