Python开发【笔记】:为什么pymysql重连后才能查到新添加的数据
PyMysql操控
问题描述:
之前做数据库模块的时候用到了pymysql,测试中发现了一个问题,创建两个程序,select.py从数据库中不断的读取,insert.py在数据库中插入多条数据,但是select.py程序查不到新添加的数据,像是做了缓存一样,查到的数据永远不变;只有重启模块,再次建立连接后,新添加的数据才能被查到;还原当时的代码如下:
查询:
# select.py 不断的进行查询 import pymysql
import time
# Connect to the database
connection = pymysql.connect(host='192.168.1.134',
port=3306,
user='remote',
password='tx_1234abc',
db='Jefrey',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor,
)
while True:
with connection.cursor() as cursor:
# Create a new record
sql = " select * from users WHERE email=%s"
# sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)"
rows_count = cursor.execute(sql, ('webmaster@python.org'))
result = cursor.fetchall()
print(result)
time.sleep(1)
插入:
# insert.py 进行数据插入 import pymysql.cursors
import time # Connect to the database
connection = pymysql.connect(host='192.168.1.134',
port=3306,
user='remote',
password='tx_1234abc',
db='Jefrey',
charset='utf8mb4',
# autocommit=True,
cursorclass=pymysql.cursors.DictCursor,)
try:
# execute方法
with connection.cursor() as cursor:
# Create a new record
start = time.time()
sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)"
for i in range(5):
cursor.execute(sql,('webmaster@python.org','test'))
connection.commit()
time.sleep(1)
finally:
connection.close()
运行30秒,查询输出打印:
()
()
()
()
()
此时数据表中的数据确实是插入进去了:
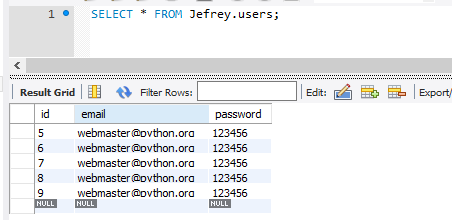
重新启动程序(重新建立的sql连接)后发现,之前添加的数据又都可以查到,但是新添加的数据又都查询不到?!! 问题确实很懵逼 ,了解完下面内容后,问题会迎刃而解,开始补课! -》》相关的问题描述
剖析:
想要解决上述的问题,首先要明白mysql中事务这个概念,本地的mysql数据库是默认安装的,默认存储引擎是(InnoDB),事务隔离级别是(REPEATABLE READ):
查看存储引擎:
mysql> show engines; # 查看数据库支持的存储引擎
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec) mysql> show variables like '%storage_engine%'; # 当前的存储引擎
+----------------------------+--------+
| Variable_name | Value |
+----------------------------+--------+
| default_storage_engine | InnoDB |
| default_tmp_storage_engine | InnoDB |
| storage_engine | InnoDB |
+----------------------------+--------+
3 rows in set (0.00 sec)
查看当前的事务隔离级别:
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.00 sec)
重复读(REPEATABLE READ):
InnoDB 的默认隔离级别。它可以防止任何被查询的行被其他事务更改,从而阻止不可重复的读取,而不是 幻读取。它使用中度严格的锁定策略,以便事务内的所有查询都会查看同一快照中的数据,即数据在事务开始时的数据。
REPEATABLE READ
The default isolation level for InnoDB. It prevents any rows that are queried from being changed by other transactions, thus blocking non-repeatable reads but not phantom reads. It uses a moderately strict locking strategy so that all queries within a transaction see data from the same snapshot, that is, the data as it was at the time the transaction started.
重复读
那么此时问题就找到了,跟当前的事务级别有关系的;当创建查询事务时,事务一直没有进行更新,每次查询到的数据都是之前查询结果的快照,下面会详细介绍每种事务隔离级别的区别
解决:
知道了具体原因是事务级别的问题,导致查询事务并没有更新,那么针对事务隔离级别进行应对就可以了,此类问题有三种解决方案,修改事务隔离级别、每次查询后更新事务、关闭数据库的事务(慎选)
① 每次查询后更新事务:
# 第一种方案,每次查询后进行commit操作,进行事务更新 import pymysql
import time
# Connect to the database
connection = pymysql.connect(host='192.168.1.134',
port=3306,
user='remote',
password='tx_1234abc',
db='Jefrey',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor,
)
while True:
with connection.cursor() as cursor:
# Create a new record
sql = " select * from users WHERE email=%s"
# sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)"
rows_count = cursor.execute(sql, ('webmaster@python.org'))
result = cursor.fetchall()
print(result)
connection.commit() # 新增
time.sleep(1) # 第二种方案,创建connect连接时,autocommit=True,自动进行commit提交
import pymysql
import time
# Connect to the database
connection = pymysql.connect(host='192.168.1.134',
port=3306,
user='remote',
password='tx_1234abc',
db='Jefrey',
charset='utf8mb4',
autocommit = True, #新增
cursorclass=pymysql.cursors.DictCursor,
)
while True:
with connection.cursor() as cursor:
# Create a new record
sql = " select * from users WHERE email=%s"
# sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)"
rows_count = cursor.execute(sql, ('webmaster@python.org'))
result = cursor.fetchall()
print(result)
# connection.commit()
time.sleep(1)
打印输出,可以查到新更新的数据:
()
()
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}]
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}]
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}, {u'password': u'test', u'id': 341, u'email': u'webmaster@python.org'}]
② 修改事务隔离级别(具体级别详情下面介绍)
设置隔离级别命令 set [global/session] transaction isolation level xxxx; 如果使用global则修改的是数据库的默认隔离级别,所有新开的窗口的隔离级别继承自这个默认隔离级别如果使用session修改,则修改的是当前客户端的隔离级别,和数据库默认隔离级别无关。当前的客户端是什么隔离级别,就能防止什么隔离级别问题,和其他客户端是什么隔离级别无关。
# 设置事务隔离级别
mysql> set global transaction isolation level READ COMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
[root@localhost ~]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 130
Server version: 5.6.36 MySQL Community Server (GPL) Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
此时用最刚刚开始的代码查询,即使不更新事务依然可以查的到新添加的数据,打印输出,可以查到新更新的数据:
()
()
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}]
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}]
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}, {u'password': u'test', u'id': 341, u'email': u'webmaster@python.org'}]
③ 关闭数据库的事务(修改存储引擎)
# 查看存储引擎
mysql> show create table users;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| users | CREATE TABLE `users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`email` varchar(255) COLLATE utf8_bin NOT NULL,
`password` varchar(255) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=350 DEFAULT CHARSET=utf8 COLLATE=utf8_bin |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) # 修改为MyISAM
mysql> alter table users engine = MyISAM;
Query OK, 5 rows affected (0.02 sec)
Records: 5 Duplicates: 0 Warnings: 0 # 再次查看存储引擎
mysql> show create table users;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| users | CREATE TABLE `users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`email` varchar(255) COLLATE utf8_bin NOT NULL,
`password` varchar(255) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=350 DEFAULT CHARSET=utf8 COLLATE=utf8_bin |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
再次用最刚刚开始的代码查询,此时跟事务已经没有什么关系了,可以查的到新添加的数据
()
()
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}]
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}]
[{u'password': u'test', u'id': 340, u'email': u'webmaster@python.org'}, {u'password': u'test', u'id': 341, u'email': u'webmaster@python.org'}]
数据库事务:
事务指逻辑上的一组操作,组成这组操作的各个单元,要不全部成功,要不全部不成功
事务特性:
- 原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency):事务前后数据的完整性必须保持一致。在事务执行之前数据库是符合数据完整性约束的,无论事务是否执行成功,事务结束后的数据库中的数据也应该是符合完整性约束的。在某一时间点,如果数据库中的所有记录都能保证满足当前数据库中的所有约束,则可以说当前的数据库是符合数据完整性约束的。比如删部门表前应该删掉关联员工(已经建立外键),如果数据库服务器发生错误,有一个员工没删掉,那么此时员工的部门表已经删除,那么就不符合完整性约束了,所以这样的数据库也就性能太差啦!
- 隔离性(Isolation):事务的隔离性是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离。
- 持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
隔离性:
将数据库设计为串行化程的数据库,让一张表在同一时间内只能有一个线程来操作。如果将数据库设计为这样,那数据库的效率太低了。所以数据库的设计这没有直接将数据库设计为串行化,而是为数据库提供多个隔离级别选项,使数据库的使用者可以根据使用情况自己定义到底需要什么样的隔离级别。
脏读:
一个事务读取到了另一个事务未提交的数据,这是特别危险的,要尽力防止。
a 1000
b 1000
a:
start transaction;
update set money=money+100 where name=b;
b:
start transaction;
select * from account where name=b;--1100
commit;
a:
rollback;
b: start transaction;
select * from account where name=b;--1000
不可重复读(开题遇到的问题就是此项):
在一个事务内读取到另一个事务中更新的数据,多次读取结果不同 a:
start transaction;
select 活期账户 from account where name=b;--1000 活期账户:1000
select 定期账户 from account where name=b;--1000 定期账户:1000
select 固定资产 from account where name=b;--1000 固定资产:1000
------------------------------
b:
start transaction;
update set money=0 where name=b;
commit;
------------------------------
select 活期+定期+固定 from account where name=b; --2000 总资产: 2000
幻读:
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致 b 1000
c 2000
d 3000
a:
start transaction
select sum(money) from account;---3000 3000
-------------------
d:start transaction;
insert into account values(d,3000);
commit;
-------------------
select count(*)from account;---3 3
3000/3 = 1000 1000
更多区别-》》 http://blog.csdn.net/u013474436/article/details/53437220
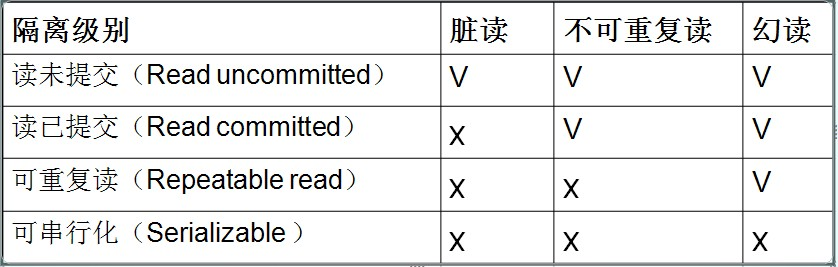
四个隔离级别
Read Uncommitted(读取未提交内容):
所有事务都可以看到其他未提交事务的执行结果
本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少
该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据
#首先,修改隔离级别
set tx_isolation='READ-UNCOMMITTED';
select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:也启动一个事务(那么两个事务交叉了)
在事务B中执行更新语句,且不提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:那么这时候事务A能看到这个更新了的数据吗?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 | --->可以看到!说明我们读到了事务B还没有提交的数据
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:事务B回滚,仍然未提交
rollback;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:在事务A里面看到的也是B没有提交的数据
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->脏读意味着我在这个事务中(A中),事务B虽然没有提交,但它任何一条数据变化,我都可以看到!
| 2 | 2 |
| 3 | 3 |
+------+------+
READ-UNCOMMITTED
Read Committed(读取提交内容):
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变
这种隔离级别出现的问题是——不可重复读(Nonrepeatable Read):不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。
导致这种情况的原因可能有:(1)有一个交叉的事务有新的commit,导致了数据的改变;(2)一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的
#首先修改隔离级别
set tx_isolation='read-committed';
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:也启动一个事务(那么两个事务交叉了)
在这事务中更新数据,且未提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:这个时候我们在事务A中能看到数据的变化吗?
select * from tx; --------------->
+------+------+ |
| id | num | |
+------+------+ |
| 1 | 1 |--->并不能看到! |
| 2 | 2 | |
| 3 | 3 | |
+------+------+ |——>相同的select语句,结果却不一样
|
#事务B:如果提交了事务B呢? |
commit; |
|
#事务A: |
select * from tx; --------------->
+------+------+
| id | num |
+------+------+
| 1 | 10 |--->因为事务B已经提交了,所以在A中我们看到了数据变化
| 2 | 2 |
| 3 | 3 |
+------+------+
READ-COMMITTED
Repeatable Read(可重读):
这是MySQL的默认事务隔离级别
它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
此级别可能出现的问题——幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行
InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题
#首先,更改隔离级别
set tx_isolation='repeatable-read';
select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:开启一个新事务(那么这两个事务交叉了)
在事务B中更新数据,并提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
commit; #事务A:这时候即使事务B已经提交了,但A能不能看到数据变化?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->还是看不到的!(这个级别2不一样,也说明级别3解决了不可重复读问题)
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:只有当事务A也提交了,它才能够看到数据变化
commit;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
REPEATABLE-READ
Serializable(可串行化):
这是最高的隔离级别
它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
在这个级别,可能导致大量的超时现象和锁竞争
#首先修改隔离界别
set tx_isolation='serializable';
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| SERIALIZABLE |
+----------------+ #事务A:开启一个新事务
start transaction; #事务B:在A没有commit之前,这个交叉事务是不能更改数据的
start transaction;
insert tx values('','');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
update tx set num=10 where id=1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
SERIALIZABLE
注:
安全性考虑:Serializable>Repeatable read>Read committed>Read uncommitted
数据库效率:Read uncommitted>Read committed>Repeatable read>Serializable
一般情况下,我们会使用Repeatable read、Read committed mysql数据库默认的数据库隔离级别Repeatable read
Python开发【笔记】:为什么pymysql重连后才能查到新添加的数据的更多相关文章
- python开发笔记-通过xml快捷获取数据
今天在做下python开发笔记之如何通过xml快捷获取数据,下面以调取nltk语料库为例: import nltk nltk.download() showing info https://raw.g ...
- python开发笔记-python调用webservice接口
环境描述: 操作系统版本: root@9deba54adab7:/# uname -a Linux 9deba54adab7 --generic #-Ubuntu SMP Thu Dec :: UTC ...
- python开发笔记-Python3.7+Django2.2 Docker镜像搭建
目标镜像环境介绍: 操作系统:ubuntu16.04 python版本:python 3.7.4 django版本:2.2 操作步骤: 1. 本地安装docker环境(略)2. 拉取ubunut指定 ...
- Hi3516开发笔记(十):Qt从VPSS中获取通道图像数据存储为jpg文件
前言 上一篇已经将himpp套入qt的基础上进行开发.那么qt中拿到frame则是很关键的交互,这是qt与海思可能编解码交叉开发的关键步骤. 受限制 因为直接配置sample的vi比较麻烦 ...
- python开发笔记之zip()函数用法详解
今天分享一篇关于python下的zip()函数用法. zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素按顺序组合成一个tuple,每个tuple中包含的是原 ...
- Python开发笔记之正则表达式的使用
查找正则表达式 import re re_txt = re.compile(r'(\d)*.txt') m = re_txt.search(src) if not m == None: m.group ...
- python开发笔记-类
类的基本概念: 问题空间:问题空间是问题解决者对一个问题所达到的全部认识状态,它是由问题解决者利用问题所包含的信息和已贮存的信息主动的地构成的. 初始状态:一开始时的不完全的信息或令人不满意的状况: ...
- Python开发笔记之-浮点数传输
操作系统 : CentOS7.3.1611_x64 gcc版本 :4.8.5 Python 版本 : 2.7.5 思路如下 : 1.将浮点数a通过内存拷贝,赋值给相同字节的整型数据b: 2.将b转换为 ...
- Python开发笔记:网络数据抓取
网络数据获取(爬取)分为两部分: 1.抓取(抓取网页) · urlib内建模块,特别是urlib.request · Requests第三方库(中小型网络爬虫的开发) · Scrapy框架(大型网络爬 ...
随机推荐
- Fastqc 能够识别的碱基编码格式
Fastqc 能够自动识别序列的碱基编码格式,我查看一下源代码,发现是碱基编码格式一共分为 1)sanger/illumina 1.9 2) illumina 1.3 3) illumina 1.5 ...
- c++ vector init操作
1) string str[n]={"hello", ...}; vector<string> strArray(str,str+n); 2) vector<st ...
- MPC8313ERDB在Linux从NAND FLASH读取UBoot环境变量的代码分析
MPC8313ERDB在Linux从NAND FLASH读取UBoot环境变量的代码分析 Yao.GUET@2014-05-19 一.故事起因 由于文件系统的增大,已经大大的超出了8MB的NOR FL ...
- [Scikit-learn] *Dynamic Bayesian Network - Partical Filter
涉及的一些知识: 机器人的自我定位 Sequential Importance Sampling Ref: http://scipy-cookbook.readthedocs.io/items/Par ...
- C# 温故而知新:Stream篇(二)
TextReader 和StreamReader 目录: 为什么要介绍 TextReader? TextReader的常用属性和方法 TextReader 示例 从StreamReader想到多态 简 ...
- swift--获取window
有时候,我们需要频繁的调用界面,然后给当前页面加一个跟视图,这个时候就需要找windown, 代码如下: let rootVC = UIApplication.shared.delegate as! ...
- swift - UIStepper的用法
在网上查看学习资料的时候,看到有这个控件,所以就自己写了下,感觉在某些特定的地方用的还是挺方便的! 不过,个人感觉,局限性太大! 1.初始化(创建个label是为了让大家看到具体的数值) let st ...
- GIS-004-Cesium版权信息隐藏
.cesium-widget-credits { display: none; } .cesium-viewer .cesium-widget-credits { display: none; }
- MySQL性能优化(四)-- MySQL explain详解
前言 MySQL中的explain命令显示了mysql如何使用索引来处理select语句以及连接表.explain显示的信息可以帮助选择更好的索引和写出更优化的查询语句. 一.格式 explain + ...
- raw_input()
raw_input() 用于接收标准输入,并把标准输入当成字符串类型来处理,只能在 Python2 中使用,Python3 中没有这个函数 #!/usr/bin/env python #-*- cod ...