Hadoop详细安装配置过程
步骤一:基础环境搭建
1.下载并安装ubuntukylin-15.10-desktop-amd64.iso
2.安装ssh
sudo apt-get install openssh-server openssh-client
3.搭建vsftpd
#sudo apt-get update
#sudo apt-get install vsftpd
配置参考 http://www.linuxidc.com/Linux/2015-01/111970.htm
http://jingyan.baidu.com/article/67508eb4d6c4fd9ccb1ce470.html
http://zhidao.baidu.com/link?url=vEmPmg5sV6IUfT4qZqivtiHtXWUoAQalGAL7bOC5XrTumpLRDfa-OmFcTzPetNZUqAi0hgjBGGdpnldob6hL5IhgtGVWDGSmS88iLvhCO4C
vsftpd的开始、关闭和重启
$sudo /etc/init.d/vsftpd start #开始
$sudo /etc/init.d/vsftpd stop #关闭
$sudo /etc/init.d/vsftpd restart #重启
4.安装jdk1.7
sudo chown -R hadoop:hadoop /opt
cp /soft/jdk-7u79-linux-x64.gz /opt
sudo vi /etc/profile
alias untar='tar -zxvf'
sudo source /etc/profile
source /etc/profile
untar jdk*
环境变量配置
# vi /etc/profile
●在profile文件最后加上
# set java environment
export JAVA_HOME=/opt/jdk1.7.0_79
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
配置完成后,保存退出。
●不重启,更新命令
#source /etc/profile
●测试是否安装成功
# Java –version
其他问题:
1.sudo 出现unable to resolve host 解决方法
参考 http://blog.csdn.net/yuzhiyuxia/article/details/19998665
2.Linux开机时停在 Starting sendmail 不动了的解决方案
参考 http://blog.chinaunix.net/uid-21675795-id-356995.html
3.ubuntu 安装软件时出现 E: Unable to locate package vsftpd
参考 http://www.ithao123.cn/content-2584008.html
4.[Linux/Ubuntu] vi/vim 使用方法讲解
参考 http://www.cnblogs.com/emanlee/archive/2011/11/10/2243930.html
步骤二:环境克隆
1.克隆master虚拟机至node1 、node2
分别修改master的主机名为master、node1的主机名为node1、node2的主机名为node2
(启动node1、node2系统默认分配递增ip,无需手动修改)
分别修改/etc/hosts中的ip和主机名(包含其他节点ip和主机名)
---------
步骤三:配置ssh免密码连入
hadoop@node1:~$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Created directory '/home/hadoop/.ssh'.
Your identification has been saved in /home/hadoop/.ssh/id_dsa.
Your public key has been saved in /home/hadoop/.ssh/id_dsa.pub.
The key fingerprint is:
SHA256:B8vBju/uc3kl/v9lrMqtltttttCcXgRkQPbVoU hadoop@node1
The key's randomart image is:
+---[DSA 1024]----+
| ...o.o. |
| o+.E . |
| . oo + |
| .. + + |
|o +. o ooo +|
|=o. . o. ooo. o.|
|*o... .+=o .+++.+|
+----[SHA256]-----+
hadoop@node1:~$ cd .ssh
hadoop@node1:~/.ssh$ ll
总用量 16
drwx------ 2 hadoop hadoop 4096 Jul 24 20:31 ./
drwxr-xr-x 18 hadoop hadoop 4096 Jul 24 20:31 ../
-rw------- 1 hadoop hadoop 668 Jul 24 20:31 id_dsa
-rw-r--r-- 1 hadoop hadoop 602 Jul 24 20:31 id_dsa.pub
hadoop@node1:~/.ssh$ cat id_dsa.pub >> authorized_keys
hadoop@node1:~/.ssh$ ll
总用量 20
drwx------ 2 hadoop hadoop 4096 Jul 24 20:32 ./
drwxr-xr-x 18 hadoop hadoop 4096 Jul 24 20:31 ../
-rw-rw-r-- 1 hadoop hadoop 602 Jul 24 20:32 authorized_keys
-rw------- 1 hadoop hadoop 668 Jul 24 20:31 id_dsa
-rw-r--r-- 1 hadoop hadoop 602 Jul 24 20:31 id_dsa.pub
步骤四:单机回环ssh免密码登录测试
hadoop@node1:~/.ssh$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ECDSA key fingerprint is SHA256:daO0dssyqt12tt9yGUauImOh6tt6A1SgxzSfSmpQqJVEiQTxas.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
270 packages can be updated.
178 updates are security updates.
New release '16.04 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Last login: Sun Jul 24 20:21:39 2016 from 192.168.219.1
hadoop@node1:~$ exit
注销
Connection to localhost closed.
hadoop@node1:~/.ssh$
出现以上信息说明操作成功,其他两个节点同样操作
让主结点(master)能通过SSH免密码登录两个子结点(slave)
hadoop@node1:~/.ssh$ scp hadoop@master:~/.ssh/id_dsa.pub ./master_dsa.pub
The authenticity of host 'master (192.168.219.128)' can't be established.
ECDSA key fingerprint is SHA256:daO0dssyqtt9yGUuImOh646A1SgxzSfatSmpQqJVEiQTxas.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master,192.168.219.128' (ECDSA) to the list of known hosts.
hadoop@master's password:
id_dsa.pub 100% 603 0.6KB/s 00:00
hadoop@node1:~/.ssh$ cat master_dsa.pub >> authorized_keys
如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,
这一过程需要密码验证。接着,将master结点的公钥文件追加至authorized_keys文件中,通过这步操作,
如果不出问题,master结点就可以通过ssh远程免密码连接node1结点了。在master结点中操作如下:
hadoop@master:~/.ssh$ ssh node1
The authenticity of host 'node1 (192.168.219.129)' can't be established.
ECDSA key fingerprint is SHA256:daO0dssyqt9yGUuImOh3466A1SttgxzSfSmpQqJVEiQTxas.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node1,192.168.219.129' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
270 packages can be updated.
178 updates are security updates.
New release '16.04 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Last login: Sun Jul 24 20:39:30 2016 from 192.168.219.1
hadoop@node1:~$ exit
注销
Connection to node1 closed.
hadoop@master:~/.ssh$
由上图可以看出,node1结点首次连接时需要,“YES”确认连接,
这意味着master结点连接node1结点时需要人工询问,无法自动连接,
输入yes后成功接入,紧接着注销退出至master结点。要实现ssh免密码连接至其它结点,
还差一步,只需要再执行一遍ssh node1,如果没有要求你输入”yes”,就算成功了,过程如下:
hadoop@master:~/.ssh$ ssh node1
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
270 packages can be updated.
178 updates are security updates.
New release '16.04 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Last login: Sun Jul 24 20:47:20 2016 from 192.168.219.128
hadoop@node1:~$ exit
注销
Connection to node1 closed.
hadoop@master:~/.ssh$
如上图所示,master已经可以通过ssh免密码登录至node1结点了。
对node2结点也可以用上面同样的方法进行
表面上看,这两个结点的ssh免密码登录已经配置成功,但是我们还需要对主结点master也要进行上面的同样工作,
这一步有点让人困惑,但是这是有原因的,具体原因现在也说不太好,据说是真实物理结点时需要做这项工作,
因为jobtracker有可能会分布在其它结点上,jobtracker有不存在master结点上的可能性。
对master自身进行ssh免密码登录测试工作:
hadoop@master:~/.ssh$ scp hadoop@master:~/.ssh/id_dsa.pub ./master_dsa.pub
The authenticity of host 'master (127.0.0.1)' can't be established.
ECDSA key fingerprint is SHA256:daO0dssttqt9yGUuImOahtt166AgxttzSfSmpQqJVEiQTxas.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master' (ECDSA) to the list of known hosts.
id_dsa.pub 100% 603 0.6KB/s 00:00
hadoop@master:~/.ssh$ cat master_dsa.pub >> authorized_key
hadoop@master:~/.ssh$ ssh master
Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64)
* Documentation: https://help.ubuntu.com/
270 packages can be updated.
178 updates are security updates.
New release '16.04 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Last login: Sun Jul 24 20:39:24 2016 from 192.168.219.1
hadoop@master:~$ exit
注销
Connection to master closed.
至此,SSH免密码登录已经配置成功。
-------------------------
解压hadoop-2.6.4.tar.gz
/opt$untar hadoop-2.6.4.tar.gz
mv hadoop-2.6.4.tar.gz hadoop
步骤五:更新环境变量
vi /etc/profile
export JAVA_HOME=/opt/jdk1.7.0_79
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
alias untar='tar -zxvf'
alias viprofile='vi /etc/profile'
alias sourceprofile='source /etc/profile'
alias catprofile='cat /etc/profile'
alias cdhadoop='cd /opt/hadoop/'
source /etc/profile
------------------
步骤六:修改配置
一共有7个文件要修改:
$HADOOP_HOME/etc/hadoop/hadoop-env.sh
$HADOOP_HOME/etc/hadoop/yarn-env.sh
$HADOOP_HOME/etc/hadoop/core-site.xml
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
$HADOOP_HOME/etc/hadoop/mapred-site.xml
$HADOOP_HOME/etc/hadoop/yarn-site.xml
$HADOOP_HOME/etc/hadoop/slaves
其中$HADOOP_HOME表示hadoop根目录
a) hadoop-env.sh 、yarn-env.sh
这二个文件主要是修改JAVA_HOME后的目录,改成实际本机jdk所在目录位置
vi etc/hadoop/hadoop-env.sh (及 vi etc/hadoop/yarn-env.sh)
找到下面这行的位置,改成(jdk目录位置,大家根据实际情况修改)
export JAVA_HOME=/opt/jdk1.7.0_79
另外 hadoop-env.sh中 , 建议加上这句:
export HADOOP_PREFIX=/opt/hadoop
b) core-site.xml 参考下面的内容修改:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>
注:/opt/hadoop/tmp 目录如不存在,则先mkdir手动创建
core-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/core-default.xml
c) hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
注:dfs.replication 表示数据副本数,一般不大于 datanode 的节点数。
hdfs-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
d) mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapred-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
e)yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
yarn-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
另外,hadoop 1.x与2.x相比, 1.x中的很多参数已经被标识为过时,具体可参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
最后一个文件slaves暂时不管(可以先用mv slaves slaves.bak 将它改名),上述配置弄好后,就可以在master上启用 NameNode测试了,方法:
$HADOOP_HOME/bin/hdfs namenode –format 先格式化
16/07/25 。。。
16/07/25 20:34:42 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1076359968-127.0.0.1-140082506
16/07/25 20:34:42 INFO common.Storage: Storage directory /opt/hadoop/tmp/dfs/name has been successfully formatted.
16/07/25 20:34:43 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
16/07/25 20:34:43 INFO util.ExitUtil: Exiting with status 0
16/07/25 20:34:43 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/127.0.0.1
************************************************************/
等看到这个时,表示格式化ok
$HADOOP_HOME/sbin/start-dfs.sh
启动完成后,输入jps (ps -ef | grep ...)查看进程,如果看到以下二个进程:
5161 SecondaryNameNode
4989 NameNode
表示master节点基本ok了
再输入$HADOOP_HOME/sbin/start-yarn.sh ,完成后,再输入jps查看进程
5161 SecondaryNameNode
5320 ResourceManager
4989 NameNode
如果看到这3个进程,表示yarn也ok了
f) 修改 /opt/hadoop/etc/hadoop/slaves
如果刚才用mv slaves slaves.bak对该文件重命名过,先运行 mv slaves.bak slaves 把名字改回来,再
vi slaves 编辑该文件,输入
node1
node2
保存退出,最后运行
$HADOOP_HOME/sbin/stop-dfs.sh
$HADOOP_HOME/sbin/stop-yarn.sh
停掉刚才启动的服务
步骤七:将master上的hadoop目录复制到 node1,node2
仍然保持在master机器上
cd 先进入主目录 cd /opt
zip -r hadoop.zip hadoop
scp -r hadoop.zip hadoop@node1:/opt/
scp -r hadoop.zip hadoop@node2:/opt/
unzip hadoop.zip
注: node1 、 node2 上的hadoop临时目录(tmp)及数据目录(data),仍然要先手动创建。
-----
步骤八:验证
master节点上,重新启动
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
------
hadoop@master:/opt/hadoop/sbin$ start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop/logs/hadoop-hadoop-namenode-master.out
node1: starting datanode, logging to /opt/hadoop/logs/hadoop-hadoop-datanode-node1.out
node2: starting datanode, logging to /opt/hadoop/logs/hadoop-hadoop-datanode-node2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/logs/hadoop-hadoop-secondarynamenode-master.out
------
hadoop@master:/opt/hadoop/sbin$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/logs/yarn-hadoop-resourcemanager-master.out
node1: starting nodemanager, logging to /opt/hadoop/logs/yarn-hadoop-nodemanager-node1.out
node2: starting nodemanager, logging to /opt/hadoop/logs/yarn-hadoop-nodemanager-node2.out
------
顺利的话,master节点上有几下3个进程:
ps -ef | grep ResourceManager
ps -ef | grep SecondaryNameNode
ps -ef | grep NameNode
7482 ResourceManager
7335 SecondaryNameNode
7159 NameNode
slave01、slave02上有几下2个进程:
ps -ef | grep DataNode
ps -ef | grep NodeManager
2296 DataNode
2398 NodeManager
同时可浏览:
http://master:50070/
http://master:8088/
查看状态
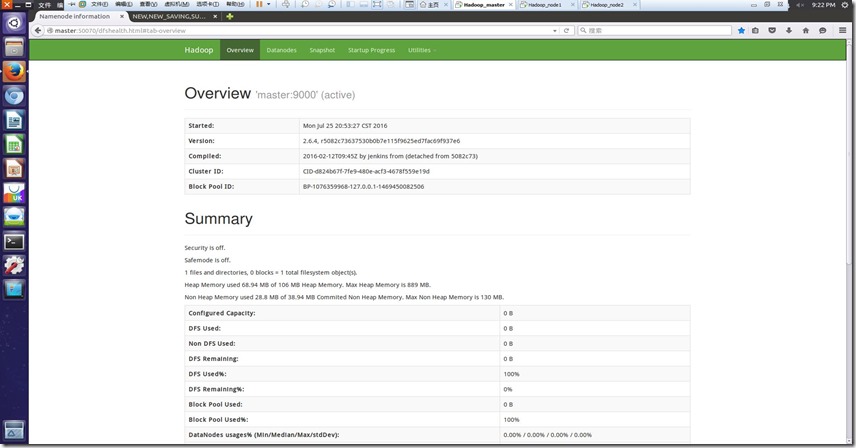
另外也可以通过 bin/hdfs dfsadmin -report 查看hdfs的状态报告
其它注意事项:
a) master(即:namenode节点)若要重新格式化,请先清空各datanode上的data目录(最好连tmp目录也一起清空),否则格式化完成后,启动dfs时,datanode会启动失败
b) 如果觉得master机器上只运行namenode比较浪费,想把master也当成一个datanode,直接在slaves文件里,添加一行master即可
c) 为了方便操作,可修改/etc/profile,把hadoop所需的lib目录,先加到CLASSPATH环境变量中,同时把hadoop/bin,hadoop/sbin目录也加入到PATH变量中,可参考下面的内容(根据实际情况修改):
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0
export JAVA_HOME=/usr/java/jdk1.7.0_51
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar:$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
by colplay
2016.07.25
Hadoop详细安装配置过程的更多相关文章
- windows 下android react native详细安装配置过程
写在前面: 在网上搜了很多安装配置文档,感觉没有一个真的跟我安装的过程一模一样的,东拼拼西凑凑,总算是装好了,我不会告诉你,断断续续,我花了两天时间...一到黑屏报错就傻眼,幸好在react群里遇到了 ...
- Hadoop单机安装配置过程:
1. 首先安装JDK,必须是sun公司的jdk,最好1.6版本以上. 最后java –version 查看成功与否. 注意配置/etc/profile文件,在其后面加上下面几句: export JAV ...
- WAMP(Windows、Apache、MySQL、php)安装配置过程常见问题
WAMP(Windows.Apache.MySQL.php)安装配置过程 可以参考该网友的总结(总结的不错,鼓掌!!): http://www.cnblogs.com/pharen/archive/2 ...
- LAMP安装配置过程
Mysql ./configure --prefix=/usr/local/mysql (注意/configure前有“.”,是用来检测你的安装平台的目标特征的,prefix是安装路径) #make ...
- 【转】Syncthing – 数据同步利器---自己的网盘,详细安装配置指南,内网使用,发现服务器配置
Syncthing – 数据同步利器---自己的网盘,详细安装配置指南,内网使用,发现服务器配置 原贴:https://www.cnblogs.com/jackadam/p/8568833.html ...
- Tomcat7.0/8.0 详细安装配置图解,以及UTF-8编码配置
Tomcat7.0/8.0 详细安装配置图解,以及UTF-8编码配置 2017年01月24日 10:01:48 阅读数:51265 标签: tomcattomcat安装tomcat配置tomcat编码 ...
- Hadoop三种模的安装配置过程
JDK+Hadoop安装配置.单机模式配置 以下操作在SecureCRT里面完成 1.关闭防火墙 firewall-cmd --state 显示防火墙状态running/not running sys ...
- Gentoo安装配置过程与总结
前些时间在VMware上安装了Gentoo Linux,用了当前最新版的Gentoo,安装过程记录下来了,但一直没有整理到blog上.今天重新整理一下,写出来与大家分享和备用.接触Gentoo不久,对 ...
- 游戏服务端pomelo完整安装配置过程
版权声明:本文为博主原创文章,转载或又一次发表请先与我联系. https://blog.csdn.net/jonahzheng/article/details/27658985 游戏服务端pomelo ...
随机推荐
- m_Orchestrate learning system---二十九、什么情况下用数据库做配置字段,什么情况下用配置文件做配置
m_Orchestrate learning system---二十九.什么情况下用数据库做配置字段,什么情况下用配置文件做配置 一.总结 一句话总结: 配置文件 开发人员 重置 数据库 非开发人员 ...
- 039——VUE中组件之子组件中data使用实例与text-xtemplate的使用方法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- DIY远程移动图像监测(tiny6410+USB摄像头+motion+yeelink+curl)
看到有博客上采用motion搭建移动图像监测系统,感觉很强大,但大多缺少远程监测能力,大多局限于局域网.OK,笔者手头刚好有一个30W像素的USB摄像头,那么借用yeelink服务,也来DIY一把,哈 ...
- Java 工程师求职遇害|多一分警惕,少一份悲剧
当朋友圈里满是战狼票房屡创新高的刷屏文章时,一则有关 Java 开发工程师李文星面试遇害的报道,却令人唏嘘不已.年仅23岁.正值青春年少.怀揣着通过打拼奋斗实现养家糊口梦想的大学毕业生,在初入职场的第 ...
- [QT]QPixmap图片缩放和QLabel 的图片自适应效果对比
图片大小为600x600 效果图: ui->label->setScaledContents(true); ...
- 51Nod 1006:最长公共子序列Lcs(打印LCS)
1006 最长公共子序列Lcs 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 给出两个字符串A B,求A与B的最长公共子序列(子序列不要求是连续的). ...
- java面试题6
1.写一个冒泡排序的算法 升序排列: int[] nums = {5,6,9,10,20,30,28,27,15}; for(int i = 0;i<nums.length;i++){ for( ...
- python3文件操作方法
在python3中,我们可以使用open打开一个文件,那么打开文件后,文件有什么操作方法呢?接下来我就记录一下比较常用的方法. 1. close() 关闭打开的文件 2. fileno() 返回文件句 ...
- 《DSP using MATLAB》Problem 2.7
1.代码: function [xe,xo,m] = evenodd_cv(x,n) % % Complex signal decomposition into even and odd parts ...
- HTML第一课——基础知识普及【1】
请关注公众号:自动化测试实战 HTML概念及编写规范 html叫做超本文标记语言,注意它知识标记语言,不是编程语言. 编写规范: 由标记(html, div, p, h1等)组成 标记成对出现(< ...