Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1706.03762
Motivation:
- The inherently sequential nature of Recurrent Models precludes parallelization within training examples.
- Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences. In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
Innovation:
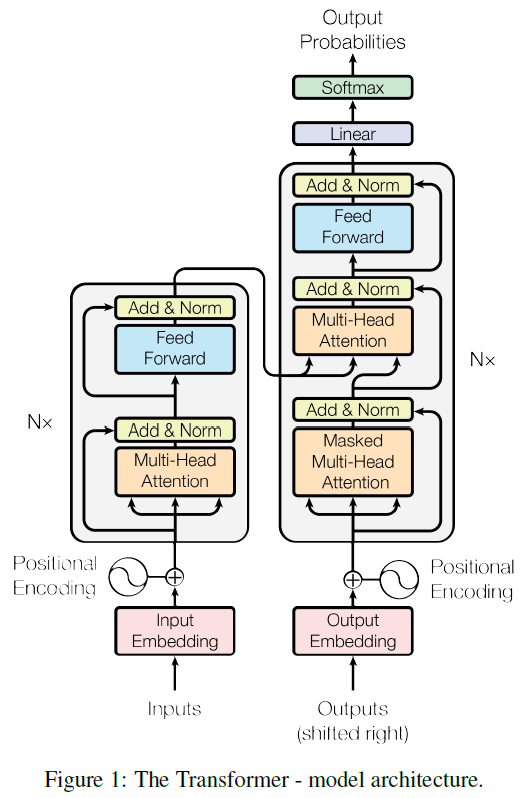
- The first sequence transduction model, the Transformer, relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or Convolutions. The Transformer follows the overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
- Encoder: The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. The authors employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is LayerNorm (x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
- Decoder: The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, they employ residual connections around each of the sub-layers, followed by layer normalization. They also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
- Scaled Dot-Product Attention and Multi-Head Attention. The Transformer uses multi-head attention in three different ways:
- In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as [ Google’s neural machine translation system: Bridging the gap between human and machine translation. ].
- The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder. [ More about Attention Definition ]
- Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. They need to prevent leftward information flow in the decoder to preserve the auto-regressive property. They implement this inside of scaled dot-product attention by masking out (setting to -∞) all values in the input of the softmax which correspond to illegal connections. See Figure 2.
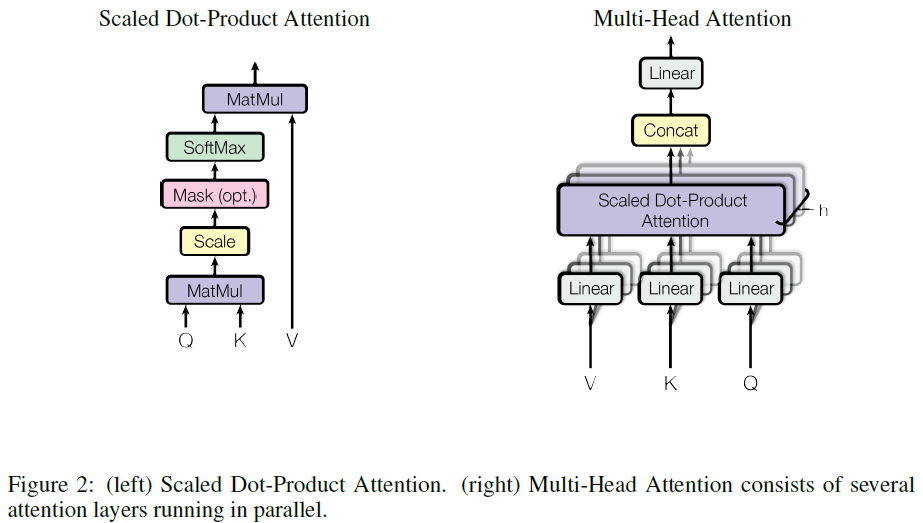
In terms of encoder-decoder, the query Q is usually the hidden state of the decoder. Whereas key K, is the hidden state of the encoder, and the corresponding value V is normalized weight, representing how much attention a key gets. -- The Transformer - Attention is all you need.
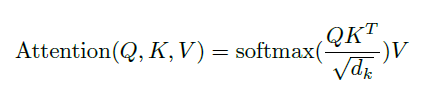

- Positional Encoding: Add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. In this work, they use sine and cosine functions of different frequencies:
- PE(pos, 2i) = sin ( pos / 100002i/dmodel )
- PE(pos, 2i+1) = cos ( pos / 100002i/dmodel)
Improvement:
- Position-wise Feed-Forward Networks: In addition to attention sub-layers, each of the layers in their encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between. FFN(x) = max(0, xW1 + b1)W2 + b2.
General Points:
- An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
- Why Self-Attention:
- One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
- The third is the path length between long-range dependencies in the network.
Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★的更多相关文章
- Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1705.03122 Motivation: Compared to recurrent layers, convol ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- Paper Reading - Im2Text: Describing Images Using 1 Million Captioned Photographs ( NIPS 2011 )
Link of the Paper: http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captio ...
- Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf Main Points: Encoder-Decoder Framework: Enco ...
- Paper Reading - Sequence to Sequence Learning with Neural Networks ( NIPS 2014 )
Link of the Paper: https://arxiv.org/pdf/1409.3215.pdf Main Points: Encoder-Decoder Model: Input seq ...
- [Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
论文链接:https://arxiv.org/pdf/1502.03044.pdf 代码链接:https://github.com/kelvinxu/arctic-captions & htt ...
- Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning
Link of the Paper: https://arxiv.org/abs/1805.09019 Innovations: The authors propose a CNN + CNN fra ...
- Paper Reading - Learning to Evaluate Image Captioning ( CVPR 2018 ) ★
Link of the Paper: https://arxiv.org/abs/1806.06422 Innovations: The authors propose a novel learnin ...
- Paper Reading - Convolutional Image Captioning ( CVPR 2018 )
Link of the Paper: https://arxiv.org/abs/1711.09151 Motivation: LSTM units are complex and inherentl ...
随机推荐
- 身份认证系统(二)多WEB应用的单点登录
随着互联网的发展,web应用的复杂度也一直在提升,慢慢的单一的web应用已经不能满足复杂的业务需求.例如百度的搜索.新闻.百科.贴吧,其实本质上都是不同的网站.当用户使用这些平台的时候,我们当然不希望 ...
- Linux-- 文件编辑器 vi/vim(2)
多文件编辑 vi 可以用来打开多个文件,如下: 进入编辑界面以后,输入 :n 可以切换到下一个文本,:N 可以切换到上一个文本,:files 列出目前这个 vi 打开的所有文件,举例如下: 切换到下一 ...
- 关于iOS Block当中为什么要用weakSelf和strongSelf的思考
场景:当你在某个界面请求网络数据的时候,用户不愿意等待点击了返回按钮,此时在Block当中用如下的方式使用weakSelf的话,有可能会奔溃(因为在并发编程的情况下,虽然在if判断的时候weaksel ...
- No active profile set, falling back to default profiles: default
No active profile set, falling back to default profiles: default 这个错误是由于idea没有设置默认启动环境,设置即可
- vue组件中,iview的modal组件爬坑--modal的显示与否应该是使用v-show
这是我第一次写博客,主要是记录下自己解决问题的过程和知识的总结,如有不对的地方欢迎指出来! 需求:点击btn,弹出modal显示图表(以折现图为例) 这应该是很基本的需求也是很容易实现的,代码和效果如 ...
- rpm与yum,at与crontab,sed命令使用
1.简述rpm与yum命令的常见选项,并举例. rpm——软件包管理系统,它使得在Linux下安装.升级.删除软件包的工作变得容易,并且具有查询.验证软件包的功能. 1)安装选项 命令格式: rpm ...
- linux 命令 sort
Linux下的sort排序命令详解(一) 1 sort的工作原理 sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出. [zook ...
- ajaxSubmit请求返回数据成功,但是不执行success回调函数
最近项目涉及到附件上传就头痛,一直在用plupload插件在做...ie9偶尔抽风但还是可以的... 然后有个需求,表格每行都有个上传按钮,页面多上传按钮. 一.开始的时候,用plupload做的,多 ...
- [上架] iOS 上架更新版本号建议
iOS 上架一個新版本号,就改个版号数字就好,有什么好说的? 是啊~ 如果上架顺利的话,就没什么好说的,如果被退件,再上传更新时,那版号怎么改? 下面说说我的做法(这只是建议,版号随自己喜好,没有固定 ...
- stm32串口通信实验,一点笔记
第一次深入学习stm32,花了好长时间才看懂代码(主要是C语言学习不够深入),又花了段时间自己敲了一遍,然后比对教程,了解了利用中断来串口通信的设置方法. 板子是探索版f407,本实验工程把正点原子库 ...