NUMA 体系架构
NUMA 体系架构
- SMP 体系架构
- NUMA 体系架构
- NUMA 结构基本概念
- Openstack flavor NUMA 策略
- Nova 实现 NUMA 流程
1. SMP 体系架构
CPU 计算平台体系架构分为 SMP 体系架构和 NUMA 体系架构等,下图为 SMP 体系架构:
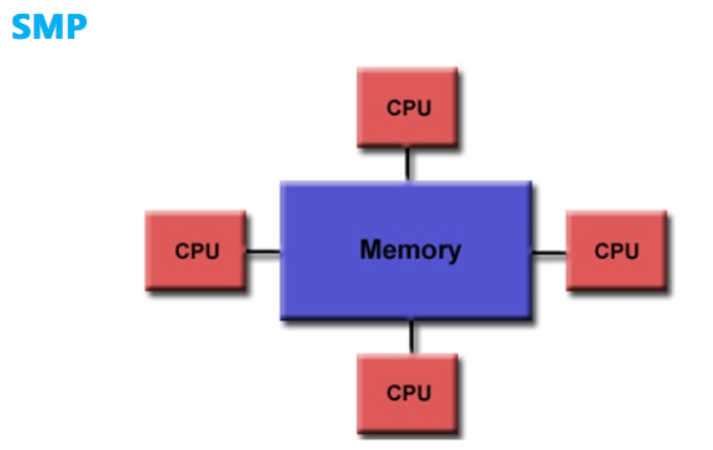
SMP(Sysmmetric Multi-Processor System,对称多处理器系统),它由多个具有对称关系的处理器组成。所谓对称,即处理器之间是水平的镜像关系,没有主从之分。SMP 架构使得一台计算机不再由单个 CPU 组成。
SMP 的结构特征就是「多处理器共享一个集中式存储器」,每个处理器访问存储器的时间片一致,使工作负载能够均匀的分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。但是,如果多个处理器同时请求访问共享资源时,就会引发资源竞争,需要软硬件实现加锁机制来解决这个问题。所以,SMP 又称为 UMA(Uniform Memory Access,一致性存储器访问),其中,一致性指的就是在任意时刻,多个处理器只能为内存的每个数据保存或共享一个唯一的数值。
因此,这样的架构设计无法拥有良好的处理器数量扩展性,因为共享内存的资源竞态总是存在的,处理器利用率最好的情况只能停留在 2 到 4 颗。
2. NUMA 体系架构
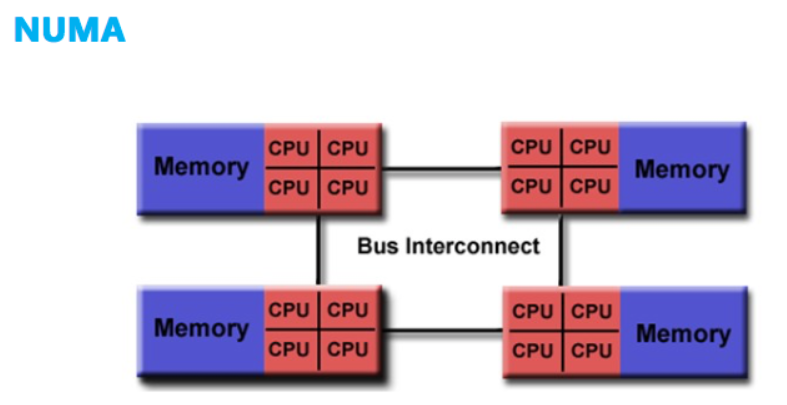
计算机系统中,处理器的处理速度要远快于主存的速度,所以限制计算机计算性能的瓶颈在存储器带宽上。SMP 架构因为限制了处理器访问存储器的频次,所以处理器可能会时刻对数据访问感到饥饿。
NUMA(Non-Uniform Memory Access,非一致性存储器访问)架构优化了 SMP 架构扩展性差以及存储器带宽窄的问题。
从上图可以看出,NUMA 和 SMP 架构是类似的,同样只会保存一份操作系统和数据库的副本,表示 NUMA 架构中的处理器依旧能够访问到整个存储器。两种主要的区别在于 NUMA 架构采用了分布式存储器,将处理器和存储器划分为不同的节点(NUMA Node),每个节点都包含了若干的处理器与内存资源。多节点的设计有效提高了存储器的带宽和处理器的扩展性。假设系统含有 4 个 NUMA 节点,那么在理想情况下系统的存储器带宽将会是 SMP 架构的 4 倍。
另一方面,NUMA 节点的处理器可以访问到整体存储器。按照节点内外,内存被分为节点内部的本地内存以及节点外部的远程内存。当处理器访问本地内存时,走的是内部总线,当处理器访问远程内存时,走的是主板上的 QPI 互联模块。访问前者的速度要远快于后者,NUMA(非一致性存储器访问)因此而得名。
3. NUMA 结构基本概念
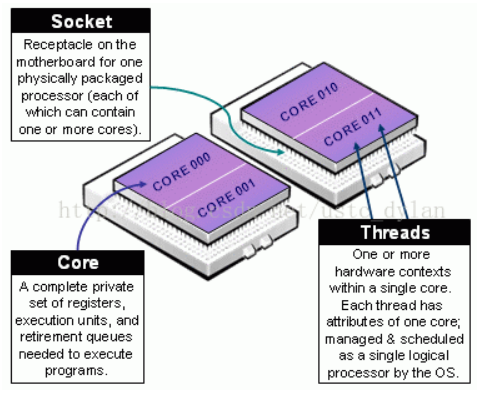
- Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽。
- Core: 物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等。
Thread: 使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。
- Node: 包含有若干个物理 CPU 的组。
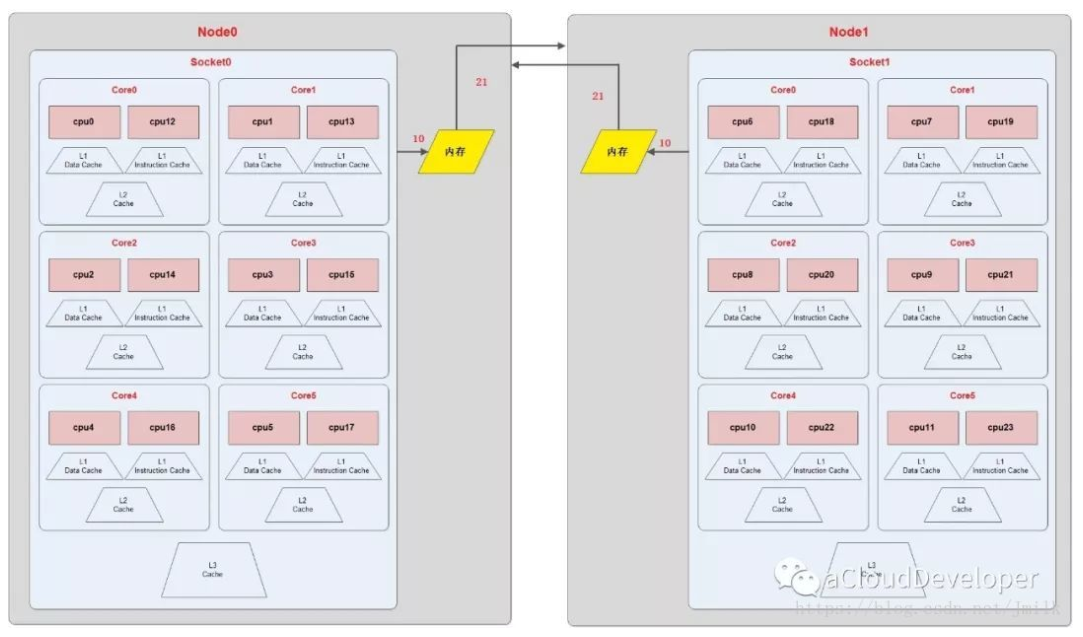
上图的 NUMA Topology 有 2 个 NUMA node,每个 node 有 1 个 socket,即 pCPU, 每个 pCPU 有 6 个 core,1 个 core 有 2 个 Processor,则共有逻辑 cpu processor 24 个。
在 LIUNX 命令行中执行 lscpu 即可看到机器的 NUMA 拓扑结构:
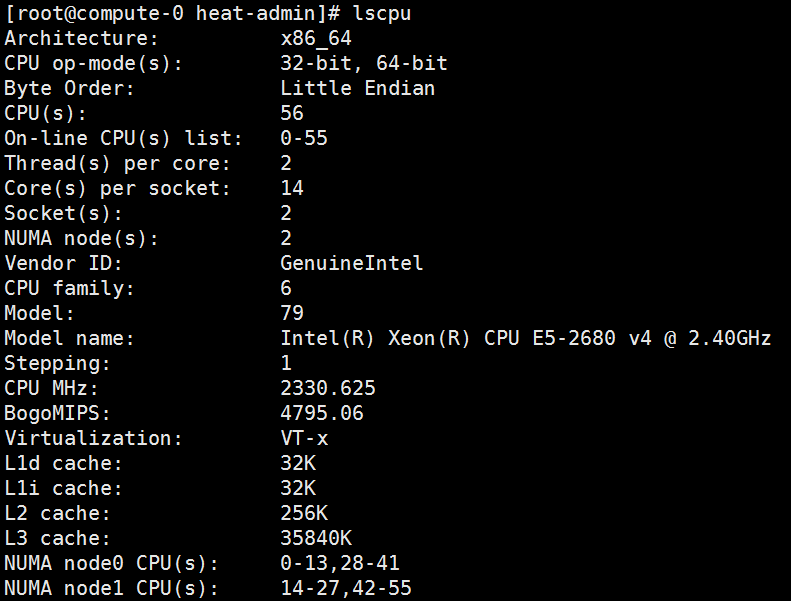
如上图所示,机器有 2 个 node 分配到 2 个 socket 上,每个 socket 有 14 个 core,每个 core 有 2 个 processor, 则共有 56 个 cpu processor。同时,从上图也可看出 NUMA node 0 上的 cpu 分布为 0-13,28-41,而 node 1 上的分布为 14-27, 42-55。
由上节分析知,NUMA node 处理器访问本地内存的速度要快于访问远端内存的速度。访问速度与 node 的距离有关系,node 间的距离称为 node distance,使用 numactl --hardware 可以 show 出该距离:

node0 的本地内存大小为 32209MB,Node1 的本地内存大小为 32316MB。Node0 到本地内存的 distance 为 10,到 node1 的内存 distance 距离为 20。node1 到本地内存的 distance 为10,到 node0 的内存distance距离为20。
进一步对上面的 NUMA Topology 图进行介绍。
Liunx 上使用 cat /proc/cpuinfo 命令 show 出 cpu 信息:
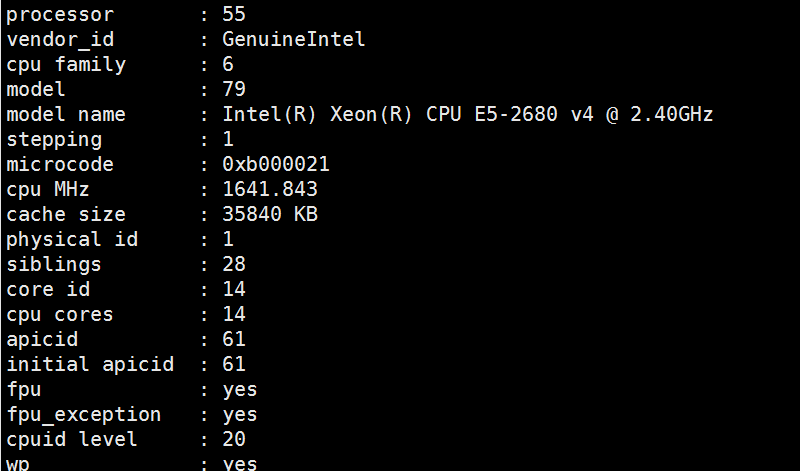
其中 physical id 表示 socket 号。当前的 cpu core 是第 14 个 ,siblings 为 28 表示此 cpu14 在 core14 里面的兄弟逻辑 cpu 为 cpu28。CPU 14 和 CPU 28 共享 L1 Data cache、L1 instruction 和 L2 Cache 。
[***@controller- ~]$ cat /sys/devices/system/cpu/cpu14/cache/index0/type
Data
[***@controller- ~]$ cat /sys/devices/system/cpu/cpu14/cache/index1/type
Instruction
[***@controller- ~]$ cat /sys/devices/system/cpu/cpu14/cache/index2/type
Unified
[***@controller- ~]$ cat /sys/devices/system/cpu/cpu14/cache/index0/size
32K
[***@controller- ~]$ cat /sys/devices/system/cpu/cpu14/cache/index1/size
32K
[***@controller- ~]$ cat /sys/devices/system/cpu/cpu14/cache/index2/size
256K
4. Openstack flavor NUMA 策略
cpu 绑核策略
对 Libvirt 驱动而言,虚拟机的 vCPU 可以绑定到主机的物理 CPU 上(pCPU)。这些配置可以改善虚拟机实例的精确度与性能。
openstack flavor set FLAVOR-NAME \
--property hw:cpu_policy=CPU-POLICY \
--property hw:cpu_thread_policy=CPU-THREAD-POLICY
有效的CPU-POLICY值为:
- shared (默认值) : 虚拟机的 vCPU 允许在主机 pCPU 上自由浮动,尽管可能受到 NUMA 策略的限制。
- dedicated: 虚拟机 vCPU 被严格绑定到一组主机 pCPU 上。
有效的 CPU-THREAD-POLICY 值为:
- prefer (默认值) : 主机可能是也可能不是 SMT 架构,如果应用 SMT 架构时,优选兄弟线程。
- isolate: 应用在主机可能不是 SMT 架构,或者必须模拟非 SMT 架构。当主机不是 SMT 架构时,每个 vCPU 相当于一个核。如果主机应用 SMT 架构,也就是说一个物理核有多个兄弟线程,每个 vCPU 也相当于一个物理核。其他虚拟机的 vCPU 不会放在同一个核上。选中的核上只有一个兄弟线程可用。
- require: 主机必要使用 SMT 架构。每个 vCPU 被分配在兄弟线程上。如果主机没有 SMT 架构,那就不使用此主机。如果主机使用 SMT 架构,却没有足够空闲线程的核,那么 nova 调度失败。
有一点要注意的是 cpu_thread_policy 只在 hw:cpu_policy 设置为 dedicated 时才有效。
NUMA拓扑
Libvirt 驱动程序可以为虚拟机 vCPU 定义放置的 NUMA 节点,或者定义虚拟机从哪个 NUMA 节点分配 vCPU 与内存。
$ openstack flavor set FLAVOR-NAME \
--property hw:numa_nodes=FLAVOR-NODES \
--property hw:numa_cpus.N=FLAVOR-CORES \
--property hw:numa_mem.N=FLAVOR-MEMORY
- FLAVOR-NODES: 限制虚拟机 vCPU 线程运行的可选 NUMA 节点数量。如果不指定,则 vCPU 线程可以运行在任意可用的 NUMA 节点上。
- N: 应用 CPU 或内存配置的虚拟机 NUMA 节点,值的范围从 0 到 FLAVOR-NODES - 1。比如为 0,则运行在NUMA节点 0,为 1,则运行在 NUMA 节点1。
- FLAVOR-CORES: 映射到虚拟机NUMA节点N上的虚拟机vCPU列表。如果不指定,vCPU 在可用的 NUMA 节点之间平均分配。
- FLAVOR-MEMORY: 映射到虚拟机 NUMA 节点 N 上的虚拟机内存大小。如果不指定,则内存平均分配到可用 NUMA 节点。
举例如下:
$ openstack flavor set aze-FLAVOR \
--property hw:numa_nodes= \
--property hw:numa_cpus.=, \
--property hw:numa_cpus.=, \
--property hw:numa_mem.= \
--property hw:numa_mem.= \
注意:hw:numa_cpus.N 与 hw:numa_mem.N 只在设置 hw:numa_nodes 时有效。N 是虚拟机 NUMA 节点的索引,并不一定对应主机 NUMA 节点。例如,在两个 NUMA 节点的平台,根据 hw:numa_mem.0,调度会选择虚拟机 NUMA 节点 0,但是却是在主机 NUMA 节点 1 上,反之亦然。类似的,FLAVOR-CORES 也是虚拟机 vCPU 的编号,并不对应与主机 CPU。因此,这个特性不能用来约束虚拟机所处的主机 CPU 与 NUMA 节点。
大页内存分配
$ openstack flavor set FLAVOR-NAME \
--property hw:mem_page_size=PAGE_SIZE
有效的 PAGE_SIZE 值为:
- small (默认值): 使用最小的内存页面,例如 x86 平台的 4KB。
- large: 虚拟机 RAM 使用大页内存。例如 x86 平台的 2MB 或 1G。
- any: 取决于计算驱动程序。此情况下,Libvirt 驱动可能会尝试寻找内存大页,但最终回落到小页。其他的驱动则可能选择可用策略。
注意:大页内存可以分配给虚拟机内存,而不考虑 Guest OS 是否使用。如果 Guest OS 不使用大页内存,则它值会识别小页。反过来,如果 Guest OS 计划使用大页内存,则一定要给虚拟机分配大页内存。否则虚拟机的性能将不及预期。
5. Nova 实现 NUMA 流程
Nova 实现 NUMA 流程如下所示:
1. nova-api 对 flavor metadata 或 image property 中的 NUMA 配置信息进行解析,生成 Guest NUMA topology,保存为 instance[‘numa_topology’]。
2. nova-scheduler 通过 NUMATopologyFilter 判断 Host NUMA topology 是否能够满足 Guest NUMA topology,进行 ComputeNode 调度。
3. nova-compute 再次通过 instance_claim 检查 Host NUMA 资源是否满足建立 Guest NUMA。
4. nova-compute 建立 Guest NUMA node 和 Host NUMA node 的映射关系,并根据映射关系调用 libvirt driver 生成 XML 文件。
5. Resource Tracker 会刷新 Host NUMA 资源的使用情况。
参考文章
CPU topologies: https://docs.openstack.org/nova/pike/admin/cpu-topologies.html#configuring-compute-nodes-for-instances-with-numa-placement-policies
Nova 的高性能虚拟机支撑: https://blog.csdn.net/jmilk/article/details/80640648
OpenStack中的CPU绑核、NUMA亲和、大页内存: https://www.jianshu.com/p/eaf6a9615acc
NUMA架构下的CPU拓扑: https://blog.csdn.net/weijitao/article/details/52884422
Cpu bindings (一) 理解cpu topology: http://fishcried.com/2015-01-09/cpu_topology/
NUMA 体系架构的更多相关文章
- 【转】XenServer体系架构解析
XenServer是一套已在云计算环境中经过验证的企业级开放式服务器虚拟化解决方案,可以将静态.复杂的IT环境转变为更加动态.易于管理的虚拟数据中心,从而大大降低数据中心成本.同时,它可以提供先进的管 ...
- 说说面向服务的体系架构SOA
序言 在.Net的世界中,一提及SOA,大家想到的应该是Web Service,WCF,还有人或许也会在.NET MVC中的Web API上做上标记,然后泛泛其谈! 的确,微软的这些技术也确实推动着面 ...
- WebLogic集群体系架构
WebLogic Server集群概述 WebLogic Server 群集由多个 WebLogic Server 服务器实例组成,这些服务器实例同时运行并一起工作以提高可缩放性和可靠性.对于客户端 ...
- F2工作流引擎这工作流引擎体系架构(二)
F2工作流体系架构概览图 为了能更好的了解F2工作流引擎的架构体系,花了些时间画了整个架构的体系图.F2工作流引擎遵循参考WFCM规范,目标是实现轻量级的工作流引擎,支持多种数据库及快速应用到任何基于 ...
- Atitit 知识图谱解决方案:提供完整知识体系架构的搜索与知识结果overview
Atitit 知识图谱解决方案:提供完整知识体系架构的搜索与知识结果overview 知识图谱的表示和在搜索中的展1 提升Google搜索效果3 1.找到最想要的信息.3 2.提供最全面的摘要.4 ...
- 《BI那点儿事》SQL Server 2008体系架构
Microsoft SQL Server是一个提供了联机事务处理.数据仓库.电子商务应用的数据库和数据分析的平台.体系架构是描述系统组成要素和要素之间关系的方式.Microsoft SQL Serve ...
- 面向服务体系架构(SOA)和数据仓库(DW)的思考基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台
面向服务体系架构(SOA)和数据仓库(DW)的思考 基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台 当前业界对面向服务体系架构(SOA)和数据仓库(Data Warehouse, ...
- 、web前端的这么知识应该是怎样的一个知识体系架构?
.web前端的这么知识应该是怎样的一个知识体系架构?之前我以为可以以W3C为纲要,把W3C的东西学会了就够了.后来发现我错了,W3C还不全面. 真正全面的覆盖了web前端知识体系的东西是——浏览器内核 ...
- Map/Reduce的类体系架构
Map/Reduce的类体系架构 Map/Reduce案例解析: 先以简单的WordCount例程, 来讲解如何去描述Map/Reduce任务. public static void main(Str ...
随机推荐
- Java 深入理解内部类
摘自海子:Java内部类详解 深入理解内部类 1.为什么成员内部类可以无条件访问外部类的成员? 在此之前,我们已经讨论过了成员内部类可以无条件访问外部类的成员,那具体究竟是如何实现的呢?下面通过反编译 ...
- 为什么我不再用 .NET 框架(网摘)
觉得好就拿过来收藏了,保留出处链接-凌风 2017年08月23日 14:51:32 hisense_大致若愚 阅读数:9355 .NET平台很棒.真的很棒.直到它不再那么棒.我为什么不再用.NET?简 ...
- 菜鸟程序猿之IDEA快捷键
Ctrl+Shift + Enter,语句完成“!”,否定完成,输入表达式时按 “!”键Ctrl+E,最近的文件Ctrl+Shift+E,最近更改的文件Shift+Click,可以关闭文件Ctrl+[ ...
- NSDate|NSTimeZone|时区|日历
NSDate,NSDateFormatter以及时区转换-开发者-51CTO博客 iOS 时区转换 东八区 - 简书 iOS时间的时区转换以及一些方法记录 - 简书 iOS - OC NSTimeZo ...
- 字体在mac win 系统如何优雅的展示
我们知道,不同的操作系统,不同的浏览器,页面字体的显示和渲染存在差异. 那么如何设置font-family,能够使字体在不同的环境下,也拥有好的展示效果? 1.操作系统中字体默认的字体 windows ...
- Java并发编程(二)创建线程的三种方法
进程与线程 1. 进程 进程和代码之间的关系就像音乐和乐谱之间的关系一样,演奏结束的时候音乐就不存在了但乐谱还在:程序执行结束的时候进程就消失了但代码还在,而计算机就是代码的演奏家. 2. 线程 线 ...
- Linux基础入门 第一章:Linux环境搭建——Redhat 6.4图文安装教程
1.创建新的虚拟机 2.选择自定义 3.选择Workstation 10.0 4.选择稍后安装操作系统 5.选择Red Hat 6 64位 6.对虚拟机命名和选择安装位置 7.选择处理器配置 8.选择 ...
- select 宽度跟随option内容自适应
传统的select在没有设置固定宽度的情况,会因为自身的 option 选项的里,宽度最宽的option作为select本身的宽度 例如 可见效果为: select的宽度因为"宽度最宽的op ...
- PHP-掌握基本的分布式架构思想
虽然说写PHP目前都是接触的业务代码,发现写久了,也要熟悉相应的架构 在高并发,高可用的系统下,都是使用高性能的分布式架构,最近在学习相关知识 分享一张图片: 欢迎关注公众号[phper的进阶之路], ...
- 如何使用yii2的缓存依赖特性
目录 如何使用yii2的缓存依赖特性 概述 页面缓存 缓存依赖 链式依赖 总结 如何使用yii2的缓存依赖特性 概述 缓存是Yii2的强大特性之一,合理使用缓存技术可以有效地减小服务器的访问压力.Yi ...