Oracle Schema Objects——Index
索引主要的作用是查询优化.
查看执行计划的权限:查看执行计划plustrace:set autotrace trace exp stat(SP2-0618、SP2-0611)
Oracle索引Index
索引
- 就像一个目录,很快搜索数据
- 目的---用于加快数据的访问
- 缺点---占据额外空间,影响DML操作的效率(在表上进程操作时,同时会更新索引的键值)。
- 索引也是段对象,会占用一定的空间。
索引的种类
- 按数据的组织方式
– B-tree B树索引
– Bitmap 位图索引
– TEXT 全文索引
|
创建索引: |
create index idx_t_part on t_part(id); |
|
查看索引大小: |
SQL> desc t; SQL> desc user_segments; SQL> select sum(bytes) from user_segments where segment_name='T'; SQL> create index idx_t on t(name); SQL> select sum(bytes) from user_segments where segment_name='IDX_T'; 注意:上面红色部分一定要写大写。 |
|
(SQL语句的资源消耗情况) |
set autotrace trace exp stat; set autotrace off; |
- B-tree 索引
- 想象一下书的目录
- 这类索引很快,可以使用如下语句查看
- Bitmap 位图索引
- 字段重复率很大时,B-tree就没有意义了
- 用在数据仓库比较多
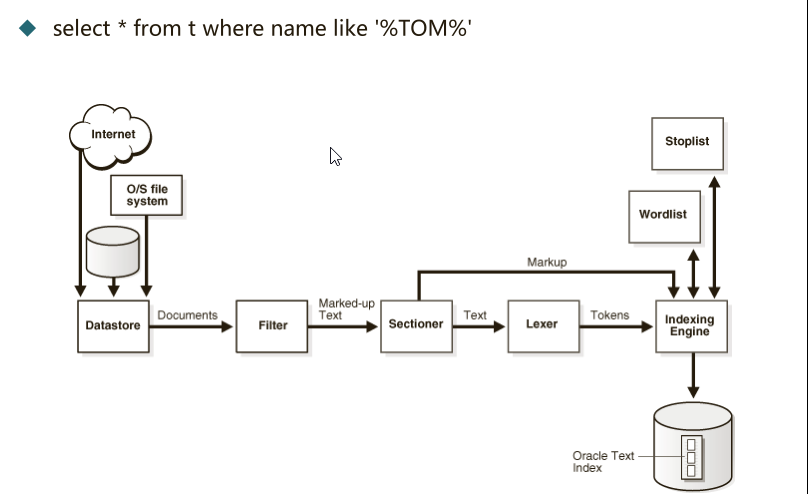
- TEXT 全文索引
- Select * from t where name like ‘%TOM%’
索引基本介绍
- 在数据库之中,索引是一种专门用于数据库查询操作性能的一种手段。
- 在Oracle之中为了维护这种查询性能,需要对某一类数据进行指定结构的排列。
- 但是在Oracle之中,针对于不同的情况会有不同的索引使用,
- 主要讲解Oracle中的:B树索引、降序索引、位图索引、函数索引。
B*Tree索引
- B树索引(又写为:B*Tree)是最为基本的索引结构,在Oracle之中默认建立的索引就是此类型索引。
- 一般B树索引在检索高基数数列(该列上的重复内容较少或没有)的时候可以提供高性能的检索操作。
- 实现方式
- 默认情况下,如果要使用查询,需要采用逐行扫描.
- 如果emp有500万条,那么这500万条记录都要被扫描.
- 如果200万条已经没有满足条件的数据了,但是默认还是需要全部索引.
- 逐行扫描就表示全表扫描,
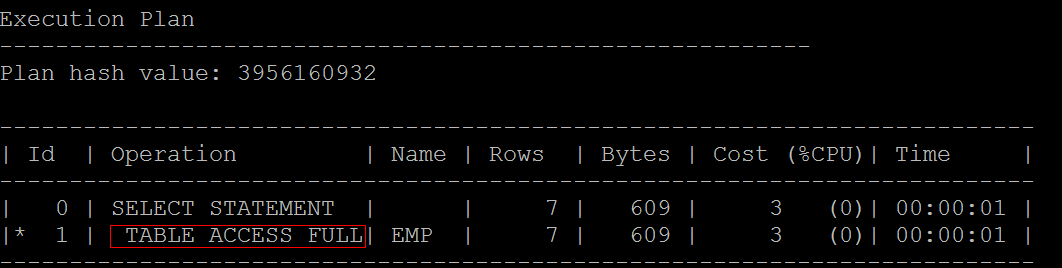
- 可以打开跟踪(需要权限):SET AUTOTRACE ON
- 查询工资大于1500的全部雇员:SELECT * FROM emp WHERE sal>1500 ;
TABLE ACCESS FULL
如果不想全部查询,就要将数据以树的形式展现出来。
在树排列时,要利用ROWID找到对应数据.利用ROWID实现的查询很快.
如果emp表中的工资数据为:“1300、2850、1100、1600、2450、2975、5000、3000、1250、950、800”,则现在可以按照以下的原则进行树结构的绘制:
- 取第一个数据作为根节点;
- 比根节点小的数据放在左子树,比根节点大的数据放在右子树
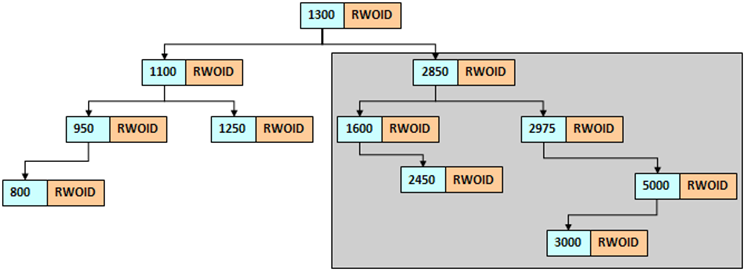
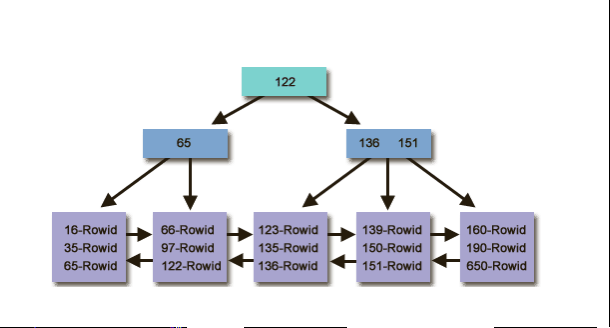
B树索引
- B-Tree索引由分支块(branch block)和叶块(leaf block)组成。
|
分支块(branch block) |
树结构中,位于最底层底块被称为叶块, 包含每个被索引列的值和行所对应的rowid。 |
|
叶块(leaf block) |
在在叶节点的上面是分支块,用来导航结构, 包含了索引列(关键字)范围和另一索引块的地址。 |
创建B*Tree索引
CREATE INDEX [用户名.]索引名称 ON [用户名.]表名称 (列名称 [ASC | DESC] , …) ;
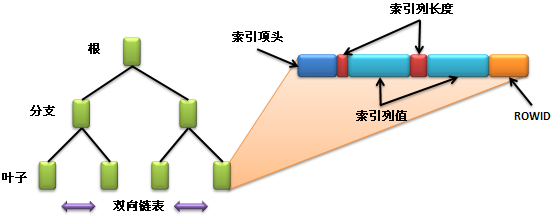
主要包含的组件如下所示:
|
叶子节点(Leaf Node) |
包含直接指向表中的数据行(即:索引项); |
|
分支节点(Branch Node) |
包含指向索引里其他的分支节点或者是叶子节点; |
|
根节点(Root Node) |
一个B树索引只有一个根节点,是位于最顶端的分支节点。 |
每一个索引项都由下面三个部分组成:
|
索引项头(Entry Header) |
存储了行数和锁的信息; |
|
索引列长度和值 |
两者需要同时出现,定义了列的长度而在长度之后保存的就是列的内容; |
|
ROWID |
指向表中数据行的ROWID,通过此ROWID找到完整记录。 |
在数据字典user_indexes,user_ind_columns;中查看INDEX 对象
范例:最好的索引是在高基数列上使用.
|
在emp.sal字段上创建emp_sal_ind索引 |
|
CREATE INDEX emp_sal_ind ON emp(sal) ; |
|
查询:现在是根据基数扫描方式查询 |
|
SELECT * FROM c##scott.emp WHERE sal>1500 ;
|
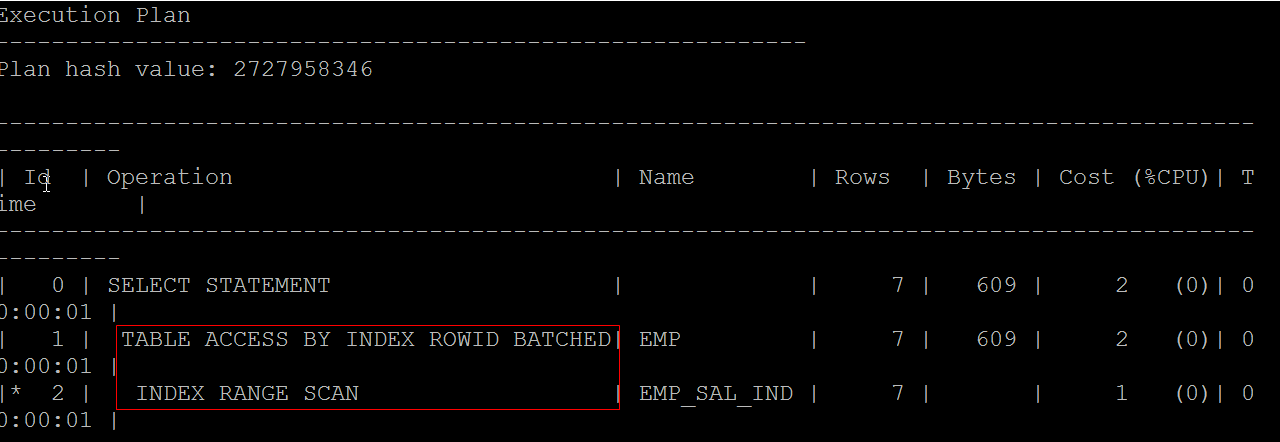
索引不一定能提升性能.如果数据量大,到处都是多表关联,提升性能最好的做法是通过冗余字段,减少多表查询.
索引如果要正常操作,必须维持这一棵树,如果表中的数据要被频繁修改,每次都要重复修改树。
如果要保持高速查找,要接收频繁更新.方法是用时间换空间,牺牲实时性.
降序索引
|
在hiredate字段上设置降序索引 |
|
CREATE INDEX emp_hiredate_ind_desc ON c##scott. emp(hiredate) ; |
|
查询在1981年雇佣的雇员信息 |
|
SELECT * FROM c##scott.emp WHERE hiredate BETWEEN TO_DATE('1981-01-01','yyyy-mm-dd') AND TO_DATE('1981-12-31','yyyy-mm-dd') ORDER BY hiredate DESC ;
|
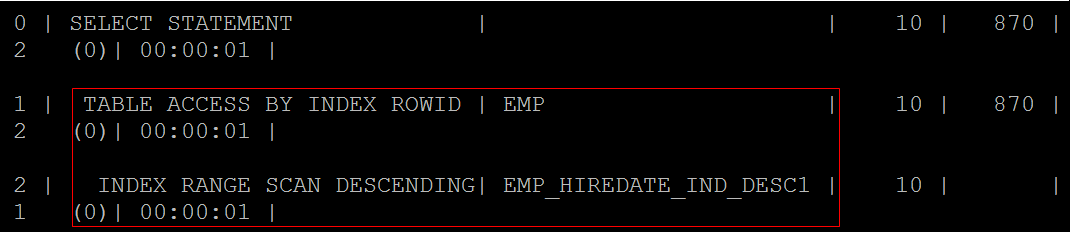
函数索引(b树索引的衍生品)
|
创建函数索引 |
|
CREATE INDEX emp_ename_ind ON emp(LOWER(ename)) ; |
|
查询在1981年雇佣的雇员信息 |
|
SELECT * FROM c##scott.emp WHERE LOWER(ename)='smith' ; |
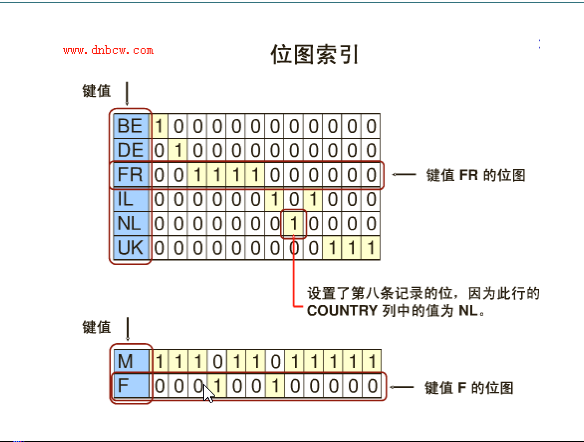
位图索引
- 如果说现在某一列上的数据都属于低基数(Low - Cardinality)列的时候就可以利用位图索引来提升查询的性能,
- 例如:表示雇员的数据表上会存在部门编号(deptno)的数据列,而在部门编号列上现在只有三种取值:10、20、30 ,在这种情况下使用位图索引是最合适的。
位图索引原理
- 对于表中的每一数据行的位图包含了deptno = 10、deptno = 20或dept = 30值,现在一共只包含了3个基数,如果说现在表中有30W条记录,那么最终这些列也只分为了3组,这样在进行位图查找的时候可以非常的方便和快捷。同时,位图索引以一种压缩数据的格式存放,因此所占用的磁盘空间要比B*Tree索引小很多。
创建位图索引
- CREATE BITMAP INDEX [用户名.]索引名称 ON [用户名.]表名称 (列名称 [ASC | DESC] , …) ;
|
在deptno字段上设置位图索引 |
|
CREATE BITMAP INDEX emp_deptno_ind ON emp(deptno) ; |
|
根据部门编号查找雇员信息 |
|
SELECT * FROM c##scott.emp WHERE deptno=10 ; SELECT * FROM c##scott.emp WHERE deptno=10 AND deptno=20 ; |
删除索引
- 于索引本身需要进行自身数据结构的维护,所以一般而言会占用较大的磁盘空间。并且随着表的增长,索引所占用的空间也会越来越大。那么对于数据库之中那些不经常使用的索引就应该尽早删除。索引是以Oracle对象存在的,所以用户可以直接利用DROP语句进行索引的删除。
- 删除索引
- DROP INDEX 索引名称 ;
|
删除emp_sal_ind索引 |
|
DROP INDEX emp_sal_ind ; |
Oracle Schema Objects——Index的更多相关文章
- Oracle Schema Objects(Schema Object Storage And Type)
One characteristic of an RDBMS is the independence of physical data storage from logical data struct ...
- Oracle Schema Objects——Tables——Oracle Data Types
Oracle Schema Objects Oracle Data Types 数据类型 Data Type Description NUMBER(P,S) Number value having a ...
- Oracle Schema Objects——Tables——TableStorage
Oracle Schema Objects Table Storage Oracle数据库如何保存表数据? Oracle Database uses a data segment in a table ...
- Oracle Schema Objects——Tables——TableType
Oracle Schema Objects Object Tables object type An Oracle object type is a user-defined type with a ...
- Oracle Schema Objects——PARTITION
Oracle Schema Objects 表分区 表- - 分区( partition )TABLE PARTITION 一段时间给出一个分区,这样方便数据的管理. 可以按照范围range分区,列表 ...
- Oracle Schema Objects——伪列ROWID Pseudocolumn(ROWNUM、ROWID)
Oracle Schema Objects Oracle Schema Objects——Tables——Oracle Data Types Oracle伪列 在Oracle数据库之中为了实现完整的关 ...
- Oracle Schema Objects——Synonyms
Oracle Schema Objects 同义词 同义词 = 表的别名. 现在假如说有一张数据表的名称是“USER1.student”,而现在又为这张数据表起了一个“USER1”的名字,以后就可以直 ...
- Oracle Schema Objects——Sequences(伪列:nextval,currval)
Oracle Schema Objects 序列的作用 许多的数据库之中都会为用户提供一种自动增长列的操作,例如:在微软的Access数据库之中就提供了一种自动编号的增长列(ID列).在oracle数 ...
- Oracle Schema Objects——View
Oracle Schema Objects Oracle视图View 普通视图.物化视图 视图(视图不包含数据,不是段对象,不占用空间,只是一个代码.) 作用: 简化SQL 为安全,不暴露表的名称 视 ...
随机推荐
- (转)ffplay的音视频同步分析之视频同步到音频
以前工作中参与了一些音视频程序的开发,不过使用的都是芯片公司的SDK,没有研究到更深入一层,比如说音视频同步是怎么回事.只好自己抽点时间出来分析开源代码了,做音视频编解码的人都知道ffmp ...
- 终于AC了“最短路径”
今天做了一道关于最短路径的算法题,虽然最后AC了,但是我写的第一个算法,我认为是没有问题的,自己编写的测试用例也全部通过,反复调试了,都没有错误.可是在OJ上一提交就提示Wrong Answer,真是 ...
- 节日(CCF试题)
试题编号: 201503-3试题名称: 节日时间限制: 1.0s内存限制: 256.0MB问题描述 有一类节日的日期并不是固定的,而是以“a月的第b个星期c”的形式定下来的,比 ...
- Unity3D之碰撞体,刚体
一 概念介绍 刚体 Rigidbody(刚体)组件可使游戏对象在物理系统的控制下来运动,刚体可接受外力与扭矩力用来保证游戏对象像在真实世界中那样进行运动.任何游戏对象只有添加了刚体组件才能受到重力的影 ...
- 【Java面试题】47 heap和stack有什么区别
java的内存分为两类,一类是栈内存,一类是堆内存.栈内存是指程序进入一个方法时,会为这个方法单独分配一块私属存储空间,用于存储这个方法内部的局部变量,当这个方法结束时,分配给这个方法的栈会释放,这个 ...
- HTML性能优化
摘要: 页面优化是对网页中的HTML代码进行必要的调整,可以有效地精简页面中的冗余代码,加快网页显示速度,减少网页占用搜索引擎服务器的存储空间,提高用户体验和搜索引擎友好性,当然也可以更好的突出页面的 ...
- Maven War包 POM配置文件
如何为你的Web程序(war包设定配置文件) 约定 http://maven.apache.org/plugins/maven-war-plugin/examples/adding-filtering ...
- php-新特性,生成器的创建和使用
mark 一下~ http://laravelacademy.org/post/4317.html
- CH7-WEB开发(集成在一起)
- Linux 下安装 Python3
Linux CentOS 7 安装 Python3: [root@localhost ~]$ yum install -y epel-release [root@localhost ~]$ yum i ...