item Collaborative Filtering
算法步骤:
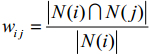




import pandas as pd
from sklearn import cross_validation
import math class ItemCF():
def __init__(self,data,k):
self.train=data
self.k=k
self.ui=self.user_item(self.train)
self.iu = self.item_user(self.train)
self.itemSimilarityMatrix()
'''
获取每个商品对应的用户(购买过该商品的用户)列表,如
{商品A:[用户1,用户2,用户3],
商品B:[用户3,用户4,用户5]...}
'''
def item_user(self,data):
iu = dict()
groups = data.groupby([1])
for item,group in groups:
iu[item]=set(group.ix[:,0]) return iu '''
获取每个用户对应的商品(用户购买过的商品)列表,如
{用户1:[商品A:评分,商品B:评分,商品C:评分],
用户2:[商品D:评分,商品E:评分,商品F:评分]...}
'''
def user_item(self,data):
ui = dict()
groups = data.groupby([0])
for item,group in groups:
ui[item]=dict()
for i in range(group.shape[0]):
ui[item][group.iget_value(i,1)]=group.iget_value(i,2) return ui def itemSimilarityMatrix(self):
matrix = dict()
for u,ps in self.ui.items():
denominator = 1.0/math.log(1+len(ps));
for p1 in ps.keys():
for p2 in ps.keys():
if p1==p2:
continue
if p1 not in matrix:
matrix[p1]=dict()
if p2 not in matrix[p1]:
matrix[p1][p2]=0 matrix[p1][p2] += denominator/math.sqrt(len(self.iu[p1])*len(self.iu[p2])) for p in matrix.keys():
#对每个商品i,将其他商品j按其与i的相似度从大大小排序
matrix[p] = sorted(matrix[p].items(),lambda x,y:cmp(x[1],y[1]),reverse=True);
#归一化
matrix[p] = [(x[0],x[1]/matrix[p][0][1]) for x in matrix[p]]
self.M=matrix
'''
对用户user进行推荐
'''
def getRecommend(self,user):
rank = dict()
uItem=self.ui[user]#获取用户购买历史
for uproduct,urank in uItem.items():
uproduct_simi = self.M[uproduct][0:self.k]
for p_simi in uproduct_simi:
p = p_simi[0]
simi = p_simi[1]
if p in uItem:
continue
if p not in rank:
rank[p]=0
rank[p]+=urank*simi
return rank def estimate(self,test):
ui_test=self.user_item(test)
unions = 0
sumRec = 0
sumTes = 0 itemrec = set() sumPopularity = 0
for user in self.ui.keys():
rank=self.getRecommend(user);
itemtest = set()
if user in ui_test:
itemtest = set(ui_test[user].keys())
sumRec += len(rank)
sumTes += len(itemtest)
for recItem in rank:
sumPopularity += math.log(1+len(self.iu[recItem]))
itemrec.add(recItem)
if recItem in itemtest:
unions += 1;
return unions*1.0/sumRec,unions*1.0/sumTes,len(itemrec)*1.0/len(self.iu.keys()),sumPopularity*1.0/sumRec
item Collaborative Filtering的更多相关文章
- Collaborative filtering
Collaborative filtering, 即协同过滤,是一种新颖的技术.最早于1989年就提出来了,直到21世纪才得到产业性的应用.应用上的代表在国外有Amazon.com,Last. ...
- 协同滤波 Collaborative filtering 《推荐系统实践》 第二章
利用用户行为数据 简介: 用户在网站上最简单存在形式就是日志. 原始日志(raw log)------>会话日志(session log)-->展示日志或点击日志 用户行一般分为两种: 1 ...
- mahout算法源码分析之Collaborative Filtering with ALS-WR (四)评价和推荐
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit. 首先来总结一下 mahout算法源码分析之Collaborative Filtering with AL ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
http://blog.csdn.net/dark_scope/article/details/17228643 〇.说明 本文的所有代码均可在 DML 找到,欢迎点星星. 一.引入 推荐系统(主要是 ...
- [转]-[携程]-A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems
原文链接:推荐系统中基于深度学习的混合协同过滤模型 近些年,深度学习在语音识别.图像处理.自然语言处理等领域都取得了很大的突破与成就.相对来说,深度学习在推荐系统领域的研究与应用还处于早期阶段. 携程 ...
- 【RS】AutoRec: Autoencoders Meet Collaborative Filtering - AutoRec:当自编码器遇上协同过滤
[论文标题]AutoRec: Autoencoders Meet Collaborative Filtering (WWW'15) [论文作者]Suvash Sedhain †∗ , Aditya K ...
- 论文笔记 : NCF( Neural Collaborative Filtering)
ABSTRACT 主要点为用MLP来替换传统CF算法中的内积操作来表示用户和物品之间的交互关系. INTRODUCTION NeuCF设计了一个基于神经网络结构的CF模型.文章使用的数据为隐式数据,想 ...
- chapter3:Collaborative Filtering ---------A Programmer's Guide to Data Mining
Implicit rating and item based filtering Explicit rating: 用户明确的对item评分 Implicit rating:反之 明确评分所存在的问题 ...
随机推荐
- LFS,编译自己的Linux系统 - 前言
近期工作计划:1. 上班时,用Django编写一个网站:2. 下班时,用C#.WPF编写一个单机版应用软件:3. 其他时间,根据LFS编译自己的Linux系统. LFS是一本书,书中列出了从零开始编译 ...
- MYSQL auto_increment 、default 关键字
1. auto_increment: innoDB 中 表中只可以有一个列是auto_increment的,这个列还一定要是索引. create table T(X int auto_incremen ...
- #pragma pack(n) 的作用
在C语言中,结构是一种复合数据类型,其构成元素既可以是基本数据类型(如int.long.float等)的变量,也可以是一些复合数据类型(如数组.结构.联合等)的数据单元.在结构中,编译器为结构的每个成 ...
- (续)顺序表之单循环链表(C语言实现)
单循环链表和单链表的唯一区别在于单循环链表的最后一个节点的指针域指向第一个节点, 使得整个链表形成一个环. C实现代码如下: #include<stdio.h> typedef struc ...
- systemctl 命令完全指南
http://www.linuxidc.com/Linux/2015-07/120833.htm Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器. System ...
- hdu 5570 balls(期望好题)
Problem Description There are n balls with m colors. The possibility of that the color of the i-th b ...
- 记录一个js切换随机背景颜色的代码
<!DOCTYPE HTML> <html lang="en-US"> <head> <meta charset="UTF-8& ...
- Bootstrap 简洁、直观、强悍、移动设备优先的前端开发框架,让web开发更迅速、简单。
http://v3.bootcss.com/ 从2.x升级到3.0版本 Bootstrap 3并不向后兼容Bootstrap v2.x.下面章节列出的内容可以作为从v2.x升级到v3.0的通用指南.如 ...
- 【简单项目框架一】Fragment实现的底部导航
流行的应用的导航一般分为两种,一种是底部导航,一种是侧边栏. 我所做的项目涉及到比较多的是底部导航,今天我就把项目中使用的一种实现方式分享一下. 主要实现思路是:在一个Activity里面底部添加四个 ...
- virtual private catalog
The following databases are registered in the base recovery catalog: PROD1, PROD2, and PROD3.The dat ...