WebLogic写的网络爬虫
一、前言
最近因为有爬一些招聘网站的招聘信息的需要,而我之前也只是知道有“网络爬虫”这个神奇的名词,具体是什么、用什么实现、什么原理、如何实现比较好都不清楚,因此最近大致研究了一下,当然,研究的并不是很深入,毕竟一个高大上的知识即使站在巨人的肩膀上,也不能两三天就融会贯通。在这里先做一个技术储备吧,具体的疑难知识点、细节等以后一点一点的完善,如果现在不趁热打铁,以后再想起来恐怕就没印象了,那么以我的懒惰的性格估计就要抛弃对它的爱情了。废话不多说,让我们开始在知识的海洋里遨游吧。哎,等等,说到这我突然想到昨天新记的一首诗感觉挺好,给大家分享一下,缓解一下气氛,再给大家讲爬虫吧:
君生我未生,我生君已老 君恨我生迟,我恨君生早
君生我未生,我生君已老 恨不生同时,日日与君好
我生君未生,君生我已老 我离君天涯,君隔我海角
我生君未生,君生我已老 化蝶去寻花,夜夜栖芳草
二、什么是网络爬虫
是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
三、优点
简单易理解,管理方便。
四、WebMagic总体架构
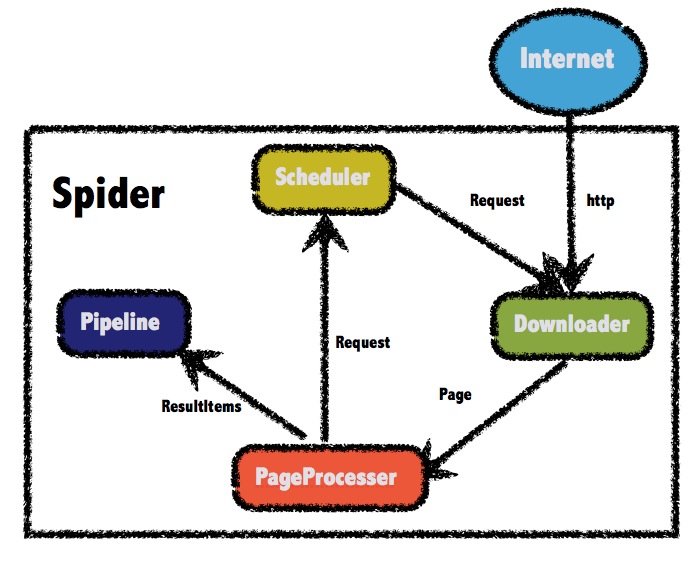
五、如何用WwbMagic
1.5.1 WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
1.5.2 爬虫项目简单例子
依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.6.1</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.6.1</version>
</dependency>
简单代码:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor; public class GithubRepoPageProcessor implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(100); @Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());
page.putField("author", page.getUrl().regex("https://github\\.com/(\\w+)/.*").toString());
page.putField("name", page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString());
if (page.getResultItems().get("name")==null){
//skip this page
page.setSkip(true);
}
page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()"));
} @Override
public Site getSite() {
return site;
} public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor()).addUrl("https://github.com/code4craft").thread(5).run();
}
如果仔细分析这段代码的逻辑,将其弄明白了,那么对于一个简单的爬虫项目,你就可以自己写了。
addUrl是定义从哪一个页面开始爬取;
addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());是指定抓取html页面的符合此正则表达式的所有链接url;
page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString是指定抓取h1标签下的class属性值为entry-title public的子标
签strong下的a标签下的文本内容;
tidyText()所有的直接和间接文本子节点,并将一些标签替换为换行,使纯文本显示更整洁。当然这也就要求大家也要对正则表达式熟悉了。本文用的是xsoup,Xsoup是
基于Jsoup开发的一款XPath 解析器,之前WebMagic使用的解析器是HtmlCleaner,使用过程存在一些问题。主要问题是XPath出错定位不准确,并且其不太合理的代码结构
,也难以 通过注解将值赋给model属性的实体类:
@TargetUrl("https://github.com/\\w+/\\w+")
@HelpUrl("https://github.com/\\w+")
public class GithubRepo {
@ExtractBy(value = "//h1[@class='entry-title public']/strong/a/text()", notNull = true)
private String name;
@ExtractByUrl("https://github\\.com/(\\w+)/.*")
private String author;
@ExtractBy("//div[@id='readme']/tidyText()")
private String readme;
}
提示:HelpUrl/TargetUrl是一个非常有效的爬虫开发模式,TargetUrl是我们最终要抓取的URL,最终想要的数据都来自这里;而HelpUrl则是为了发现这个最终URL,我们需要访问的页面。几乎所有垂直爬虫的需求,都可以归结为对这两类URL的处理:
- 对于博客页,HelpUrl是列表页,TargetUrl是文章页。
- 对于论坛,HelpUrl是帖子列表,TargetUrl是帖子详情。
- 对于电商网站,HelpUrl是分类列表,TargetUrl是商品详情。
模拟浏览器请求:
public VideoSpider(String url, String proxyStr) {
this.client_url = url;
String[] tmp = proxyStr.split(":");
HttpHost proxy = new HttpHost(tmp[1].substring(2), Integer.parseInt(tmp[2]), tmp[0]);
Site site = Site.me().setRetryTimes(3).setHttpProxy(proxy).setSleepTime(100).setTimeOut(10 * 1000).setCharset("UTF-8")
.setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36");
GPHttpClientDownloader downloader = new GPHttpClientDownloader();
Request request = new Request(this.client_url);
this.setCookie(request, site, downloader);
this.setParameters(request, site, downloader);
}
中setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36"),jobInfoDaoPipeline, LieTouJobInfo.class)
是模拟火狐、苹果、谷歌等浏览器进行请求将通过实体类LieTouJobInfo来抓取指定的内容并通过数据库访问层jobInfoDaoPipeline将相关属性存入数据库。
六、思考
简单的爬虫用以上代码基本就可以实现,但是我们要知道,要想真正爬取自己想要的内容,还有一段很长的落要走。因为我们在抓取数据的时候要考虑到去重、动态页面的产生、快速的更新频率、巨大的数据量等等的问题。针对这些问题我们该怎么做才能有效简单的去解决,这是
一个特别值得探讨的问题。就先写到这吧,如果我研究的有进展了,足以在公司项目中稳定投入使用了,再来完善吧。下载:
最新版:WebMagic-0.6.1
Maven依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.6.1</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.6.1</version>
</dependency>
文档:
- 中文: http://webmagic.io/docs/zh/
- English: http://webmagic.io/docs/en
源码:
WebLogic写的网络爬虫的更多相关文章
- WebMagic写的网络爬虫
一.前言 最近因为有爬一些招聘网站的招聘信息的需要,而我之前也只是知道有“网络爬虫”这个神奇的名词,具体是什么.用什么实现.什么原理.如何实现比较好都不清楚,因此最近大致研究了一下,当然,研究的并不是 ...
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看 ...
- 使用Pycharm写一个网络爬虫
在初步了解网络爬虫之后,我们接下来就要动手运用Python来爬取网页了. 我们知道,网络爬虫应用一般分为两个步骤: 1.通过网页链接获取内容: 2.对获得的网页内容进行处理 这两个步骤需要分别使用不同 ...
- 使用Python写的第一个网络爬虫程序
今天尝试使用python写一个网络爬虫代码,主要是想訪问某个站点,从中选取感兴趣的信息,并将信息依照一定的格式保存早Excel中. 此代码中主要使用到了python的以下几个功能,因为对python不 ...
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
原文地址http://blog.csdn.net/qy20115549/article/details/52203722 本文为原创博客,仅供技术学习使用.未经允许,禁止将其复制下来上传到百度文库等平 ...
- 学习推荐《精通Python网络爬虫:核心技术、框架与项目实战》中文PDF+源代码
随着大数据时代的到来,我们经常需要在海量数据的互联网环境中搜集一些特定的数据并对其进行分析,我们可以使用网络爬虫对这些特定的数据进行爬取,并对一些无关的数据进行过滤,将目标数据筛选出来.对特定的数据进 ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- [原创]手把手教你写网络爬虫(4):Scrapy入门
手把手教你写网络爬虫(4) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 上期我们理性的分析了为什么要学习Scrapy,理由只有一个,那就是免费,一分钱都不用花! 咦?怎么有人扔西红柿 ...
随机推荐
- oracle存储过程中文乱码问题
设置环境变量,新建变量,设置变量名:NLS_LANG,变量值:SIMPLIFIED CHINESE_CHINA.ZHS16GBK word哥,还是不行呀: 参考:http://idata.blog.5 ...
- TCMalloc
一. 原理 tcmalloc就是一个内存分配器,管理堆内存,主要影响malloc和free,用于降低频繁分配.释放内存造成的性能损耗,并且有效地控制内存碎片.glibc中的内存分配器是ptmalloc ...
- PHP生成短信验证码
简单版本 <?php function generate_code($length = 6) { $min = pow(10 , ($length - 1)); $max = pow(10, $ ...
- Java NIO------基础理论之缓存区
1.概述:NIO我的理解就是 New IO,是API1.4里提供的新的API,为所有的原始类型做缓存支持. NIO主要的核心组成部分: Buffer(缓存) Channels(通道) Selector ...
- office如何去除多页签
写文档会遇到同时打开多个文档,偶尔可能需要对比,而有时office会出现跟浏览器类似的多页签界面.如何去除多页签,office本身没有此加载项,一般都是作为插件或组件形式另外安装,导致我们不知道从哪里 ...
- Hadoop权威指南: InputFormat,RecordReader,OutputFormat和RecordWriter
InputFormat和RecordReader Hadoop提出了InputFormat的概念 org.apache.hadoop.mapreduce包里的InputFormat抽象类提供了如下列代 ...
- JavaScript———从setTimeout与setInterval到AJAX异步
setTimeout与setInterval执行 首先我们看一下以下代码打印结果 console.log(1); setTimeout(function() { console.log(2); },1 ...
- Java中正则表达式去除html标签
Java中正则表达式去除html的标签,主要目的更精确的显示内容,比如前一段时间在做类似于博客中发布文章功能,当编辑器中输入内容后会将样式标签也传入后台并且保存数据库,但是在显示摘要的时候,比如显示正 ...
- PowerShell 批量修改AD属性
环境:win 2008 R2 在管理工具中打开用于 windows powershell 的ActiveDirectory模块命令行窗口或打开命令提示符窗口输入PowerShell回车再输入impor ...
- 小机器人自动回复(python,可扩展开发微信公众号的小机器人)
api来之图灵机器人.我们都知道微信公众号可以有自动回复,我们先用python脚本编写一个简单的自动回复的脚本,利用图灵机器人的api. http://www.tuling123.com/help/h ...