jQuery 2.0.3 源码分析Sizzle引擎解析原理
jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢!
先来回答博友的提问:
如何解析
div > p + div.aaron input[type="checkbox"]
顺便在深入理解下解析的原理:
HTML结构

<div id="text">
<p>
<input type="text" />
</p>
<div class="aaron">
<input type="checkbox" name="readme" value="Submit" />
<p>Sizzle</p>
</div>
</div>
选择器语句
div > p + div.aaron input[type="checkbox"]
组合后的意思大概就是:
1. 选择父元素为 <div> 元素的所有子元素 <p> 元素
2. 选择紧接在 <p> 元素之后的所有 <div> 并且class="aaron " 的所有元素
3. 之后选择 div.aaron 元素内部的所有 input并且带有 type="checkbox" 的元素
就针对这个简单的结构,我们实际中是不可能这么写的,但是这里我用简单的结构,描述出复杂的处理
我们用组合语句,jquery中,在高级浏览器上都是用过querySelectorAll处理的,所以我们讨论的都是在低版本上的实现,伪类选择器,XML 要放到后最后,本文暂不涉及这方便的处理.
需要用到的几个知识点:
1: CSS选择器的位置关系
2: CSS的浏览器实现的基本接口
3: CSS选择器从右到左扫描匹配
CSS选择器的位置关系
文档中的所有节点之间都存在这样或者那样的关系
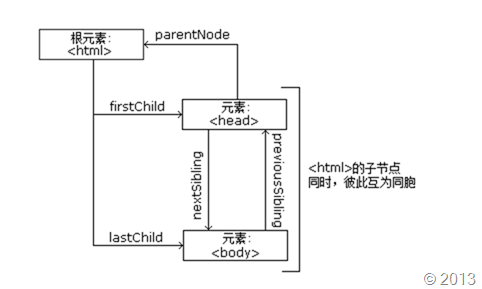
其实不难发现,一个节点跟另一个节点有以下几种关系:
祖宗和后代
父亲和儿子
临近兄弟
普通兄弟
在CSS选择器里边分别是用:空格;>;+;~
(其实还有一种关系:div.aaron,中间没有空格表示了选取一个class为aaron的div节点)
<div id="grandfather">
<div id="father">
<div id="child1"></div>
<div id="child2"></div>
<div id="child3"></div>
</div>
</div>
- 爷爷grandfather与孙子child1属于祖宗与后代关系(空格表达)
- 父亲father与儿子child1属于父子关系,也算是祖先与后代关系(>表达)
- 哥哥child1与弟弟child2属于临近兄弟关系(+表达)
- 哥哥child1与弟弟child2,弟弟child3都属于普通兄弟关系(~表达)
在Sizzle里有一个对象是记录跟选择器相关的属性以及操作:Expr。它有以下属性:
relative = {
">": { dir: "parentNode", first: true },
" ": { dir: "parentNode" },
"+": { dir: "previousSibling", first: true },
"~": { dir: "previousSibling" }
}
所以在Expr.relative里边定义了一个first属性,用来标识两个节点的“紧密”程度,例如父子关系和临近兄弟关系就是紧密的。在创建位置匹配器时,会根据first属性来匹配合适的节点。
CSS的浏览器实现的基本接口
除去querySelector,querySelectorAll
HTML文档一共有这么四个API:
- getElementById,上下文只能是HTML文档。
- getElementsByName,上下文只能是HTML文档。
- getElementsByTagName,上下文可以是HTML文档,XML文档及元素节点。
- getElementsByClassName,上下文可以是HTML文档及元素节点。IE8还没有支持。
所以要兼容的话sizzle最终只会有三种完全靠谱的可用
Expr.find = {
'ID' : context.getElementById,
'CLASS' : context.getElementsByClassName,
'TAG' : context.getElementsByTagName
}
CSS选择器从右到左扫描匹配
接下我们就开始分析解析规则了
1. 选择器语句
div > p + div.aaron input[type="checkbox"]
2. 开始通过词法分析器tokenize分解对应的规则(这个上一章具体分析过了)
分解每一个小块
type: "TAG"
value: "div"
matches .... type: ">"
value: " > " type: "TAG"
value: "p"
matches .... type: "+"
value: " + " type: "TAG"
value: "div"
matches .... type: "CLASS"
value: ".aaron"
matches .... type: " "
value: " " type: "TAG"
value: "input"
matches .... type: "ATTR"
value: "[type="checkbox"]"
matches .... 除去关系选择器,其余的有语意的标签都都对应这分析出matches 比如
最后一个属性选择器分支
"[type="checkbox"]" matches = [
0: "type"
1: "="
2: "checkbox"
]
type: "ATTR"
value: "[type="checkbox"]"
所以就分解出了9个部分了
那么如何匹配才是最有效的方式?
3. 从右往左匹配
最终还是通过浏览器提供的API实现的, 所以Expr.find就是最终的实现接口了
首先确定的肯定是从右边往左边匹配,但是右边第一个是
"[type="checkbox"]"
很明显Expr.find 中不认识这种选择器,所以只能在往前扒一个
趴到了
type: "TAG"
value: "input"
这种标签Expr.find能匹配到了,所以直接调用
Expr.find["TAG"] = support.getElementsByTagName ?
function(tag, context) {
if (typeof context.getElementsByTagName !== strundefined) {
return context.getElementsByTagName(tag);
}
} :
但是getElementsByTagName方法返回的是一个合集
所以
这里引入了seed - 种子合集(搜索器搜到符合条件的标签),放入到这个初始集合seed中
OK了 这里暂停了,不在往下匹配了,在用这样的方式往下匹配效率就慢了
开始整理:
重组一下选择器,剔掉已经在用于处理的tag标签,input
所以选择器变成了:
selector: "div > p + div.aaron [type="checkbox"]"
这里可以优化下,如果直接剔除后,为空了,就证明满足了匹配要求,直接返回结果了
到这一步为止
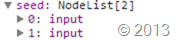
我们能够使用的东东:
1 seed合集
2 通过tokenize分析解析规则组成match合集
本来是9个规则快,因为匹配input,所以要对应的也要踢掉一个所以就是8个了
3 选择器语句,对应的踢掉了input
"div > p + div.aaron [type="checkbox"]"
此时send目标合集有2个最终元素了
那么如何用最简单,最有效率的方式从2个条件中找到目标呢?
涉及的源码:
//引擎的主要入口函数
function select(selector, context, results, seed) {
var i, tokens, token, type, find,
//解析出词法格式
match = tokenize(selector); if (!seed) { //如果外界没有指定初始集合seed了。
// Try to minimize operations if there is only one group
// 没有多组的情况下
// 如果只是单个选择器的情况,也即是没有逗号的情况:div, p,可以特殊优化一下
if (match.length === 1) { // Take a shortcut and set the context if the root selector is an ID
tokens = match[0] = match[0].slice(0); //取出选择器Token序列 //如果第一个是selector是id我们可以设置context快速查找
if (tokens.length > 2 && (token = tokens[0]).type === "ID" &&
support.getById && context.nodeType === 9 && documentIsHTML &&
Expr.relative[tokens[1].type]) { context = (Expr.find["ID"](token.matches[0].replace(runescape, funescape), context) || [])[0];
if (!context) {
//如果context这个元素(selector第一个id选择器)都不存在就不用查找了
return results;
}
//去掉第一个id选择器
selector = selector.slice(tokens.shift().value.length);
} // Fetch a seed set for right-to-left matching
//其中: "needsContext"= new RegExp( "^" + whitespace + "*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\\(" + whitespace + "*((?:-\\d)?\\d*)" + whitespace + "*\\)|)(?=[^-]|$)", "i" )
//即是表示如果没有一些结构伪类,这些是需要用另一种方式过滤,在之后文章再详细剖析。
//那么就从最后一条规则开始,先找出seed集合
i = matchExpr["needsContext"].test(selector) ? 0 : tokens.length; //从右向左边查询
while (i--) { //从后开始向前找!
token = tokens[i]; //找到后边的规则 // Abort if we hit a combinator
// 如果遇到了关系选择器中止
//
// > + ~ 空
//
if (Expr.relative[(type = token.type)]) {
break;
} /*
先看看有没有搜索器find,搜索器就是浏览器一些原生的取DOM接口,简单的表述就是以下对象了
Expr.find = {
'ID' : context.getElementById,
'CLASS' : context.getElementsByClassName,
'NAME' : context.getElementsByName,
'TAG' : context.getElementsByTagName
}
*/
//如果是:first-child这类伪类就没有对应的搜索器了,此时会向前提取前一条规则token
if ((find = Expr.find[type])) { // Search, expanding context for leading sibling combinators
// 尝试一下能否通过这个搜索器搜到符合条件的初始集合seed
if ((seed = find(
token.matches[0].replace(runescape, funescape),
rsibling.test(tokens[0].type) && context.parentNode || context
))) { //如果真的搜到了
// If seed is empty or no tokens remain, we can return early
//把最后一条规则去除掉
tokens.splice(i, 1);
selector = seed.length && toSelector(tokens); //看看当前剩余的选择器是否为空
if (!selector) {
//是的话,提前返回结果了。
push.apply(results, seed);
return results;
} //已经找到了符合条件的seed集合,此时前边还有其他规则,跳出去
break;
}
}
}
}
} // "div > p + div.aaron [type="checkbox"]" // Compile and execute a filtering function
// Provide `match` to avoid retokenization if we modified the selector above
// 交由compile来生成一个称为终极匹配器
// 通过这个匹配器过滤seed,把符合条件的结果放到results里边
//
// //生成编译函数
// var superMatcher = compile( selector, match )
//
// //执行
// superMatcher(seed,context,!documentIsHTML,results,rsibling.test( selector ))
//
compile(selector, match)(
seed,
context, !documentIsHTML,
results,
rsibling.test(selector)
);
return results;
}
这个过程在简单总结一下:
selector:"div > p + div.aaron input[type="checkbox"]" 解析规则:
1 按照从右到左
2 取出最后一个token 比如[type="checkbox"]
{
matches : Array[3]
type : "ATTR"
value : "[type="
checkbox "]"
}
3 过滤类型 如果type是 > + ~ 空 四种关系选择器中的一种,则跳过,在继续过滤
4 直到匹配到为 ID,CLASS,TAG 中一种 , 因为这样才能通过浏览器的接口索取
5 此时seed种子合集中就有值了,这样把刷选的条件给缩的很小了
6 如果匹配的seed的合集有多个就需要进一步的过滤了,修正选择器 selector: "div > p + div.aaron [type="checkbox"]"
7 OK,跳到一下阶段的编译函数
Sizzle不仅仅是简简单单的从右往左匹配的
Sizzle1.8开始引入编译函数的概念,也是下一章的重点
jQuery 2.0.3 源码分析Sizzle引擎解析原理的更多相关文章
- jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 先来回答博友的提问: 如何解析 div > p + div.aaron input[type="checkb ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 编译函数(大篇幅)
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 从Sizzle1.8开始,这是Sizzle的分界线了,引入了编译函数机制 网上基本没有资料细说这个东东的,sizzle引入这 ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 高效查询
为什么Sizzle很高效? 首先,从处理流程上理解,它总是先使用最高效的原生方法来做处理 HTML文档一共有这么四个API: getElementById 上下文只能是HTML文档 浏览器支持情况:I ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 词法解析
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 浏览器从下载文档到显示页面的过程是个复杂的过程,这里包含了重绘和重排.各家浏览器引擎的工作原理略有差别,但也有一定规则. 简 ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 超级匹配
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 通过Expr.find[ type ]我们找出选择器最右边的最终seed种子合集 通过Sizzle.compile函数编译器 ...
- jQuery 2.0.3 源码分析 Deferred(最细的实现剖析,带图)
Deferred的概念请看第一篇 http://www.cnblogs.com/aaronjs/p/3348569.html ******************构建Deferred对象时候的流程图* ...
- jQuery 2.0.3 源码分析core - 选择器
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 打开jQuery源码,一眼看去到处都充斥着正则表达式,jQuery框架的基础就是查询了,查询文档元素对象 ...
- jQuery 2.0.3 源码分析 Deferred概念
JavaScript编程几乎总是伴随着异步操作,传统的异步操作会在操作完成之后,使用回调函数传回结果,而回调函数中则包含了后续的工作.这也是造成异步编程困难的主要原因:我们一直习惯于“线性”地编写代码 ...
- jQuery 2.0.3 源码分析 事件绑定 - bind/live/delegate/on
事件(Event)是JavaScript应用跳动的心脏,通过使用JavaScript ,你可以监听特定事件的发生,并规定让某些事件发生以对这些事件做出响应 事件的基础就不重复讲解了,本来是定位源码分析 ...
随机推荐
- python_基础学习_01_按行读取文件的最优方法
python 按行读取文件 ,网上搜集有N种方法,效率有区别,先mark最优答案,下次补充测试数据 with open('filename') as file: for line in file: d ...
- eclipse打不开data目录解决的方法
1.首先手机必须详细root权限.没有的话,先去root. 2.root过后若还是不能打开,下载一个R.E管理器,然后将须要打开的目录设置为可读.可写.可运行. 附图:
- 【转】Appium测试安卓Launcher以滑动窗体获得目标应用
原文地址:http://blog.csdn.net/zhubaitian/article/details/39755553 所谓Launcher,指的是安卓的桌面管理程序,所有的应用图标都放在laun ...
- js小记 function 的 length 属性
原文:js小记 function 的 length 属性 [1,2,3]., ,这个略懂js的都知道. 但是 eval.length,RegExp.length,"".toStr ...
- centos 7安装源
参照 http://www.linuxidc.com/Linux/2015-03/114690.htm http://www.cnblogs.com/mchina/archive/2013/01/04 ...
- C语言利用va_list、va_start、va_end、va_arg宏定义可变參数的函数
在定义可变參数的函数之前,先来理解一下函数參数的传递原理: 1.函数參数是以栈这样的数据结构来存取的,在函数參数列表中,从右至左依次入栈. 2.參数的内存存放格式:參数的内存地址存放在内存的堆栈段中, ...
- C语言库函数大全及应用实例五
原文:C语言库函数大全及应用实例五 [编程资料]C语言库函数大全及应用实例五 函数名: getcurdi ...
- Jquery.validate表单验证
一.用前必备官方网站:http://bassistance.de/jquery-plugins/jquery-plugin-validation/API: http://jquery.bassista ...
- DDD,ORM还是Ado.Net
三层还是DDD,ORM还是Ado.Net,何去何从? 我本想把这个问题放到博问去,前几次有去博问问过之类的问题,无奈大神们可能都不屑回答别人的低级问题.所以放到随笔里,一方面把自己对ORM.架构的一些 ...
- Python开发环境Wing IDE 5.0测试第八版发布
Wing IDE是著名的Python开发工具,是Wingware公司的主要产品.从1999年起,Wingware公司便开始专注于Python开发设计.Wing IDE在十几年的发展中,不管完善.其强大 ...