.NET面向对象特性之“继承”
整体简介
1.理解继承——继承关系图
2.实现继承与接口多继承
3.new、 virtual、override方法
4.抽象方法和抽象类的继承
5.继承的本质
6.继承的复用性、扩展性和安全性
7.多聚合,少继承;低耦合,高内聚
8.扩展方法。
1.理解继承——继承关系图
理解继承。以下图为例:

继承实际上包含了对现实的一种抽象,现实生活中不存在动物这种实体东西,但是它却代表了具有相同特征和属性的一类事物。类别与类别之间的关系放映为相似或者不相似某种抽象关系。继承体现了面向对象技术中的复用性、扩展性和安全性。
特点分析:
a.麻雀继承自鸟类,麻雀拥有了鸟类的所有特性;鸟类继承自动物,具有动物的所有特征。但同时麻雀也具有动物的所有特征。也就是说子类会继承父类以及父类的父类(它上层)所有类的特性(继承传递性)。并且这种关系是单向的,子类可以调用父类方法和字段,而父类不能调用子类方法和字段。比如麻雀有鸟类的所有特性但是鸟类却不具备所有麻雀的特性。
b.继承自上而下是一种逐层具体化过程,而自下而上是一种逐层抽象化过程。例如,最高层的动物具有最普遍的特征,而最低层的则具有较具体的特征。子类是对父类的扩展,必须继承父类方法,同时可以添加新方法。
c.一个类只能继承“一个”类:比如麻雀继承自鸟类就不能继承自鱼类。一个类只能有一个基类。
d.继承不能访问父类的private修饰的方法和属性。
总结:继承,就是面向对象中类与类之间的一种关系。通过继承,使得子类具有父类的属性和方法,同时子类也可以通过加入新的属性和方法或者修改父类的属性和方法建立新的类层次。继承机制体现了面向对象技术中的复用性、扩展性和安全性。
2.单继承与接口多继承
实现继承:一个类只能继承一个类。派生类会继承基类的所有属性和方法,但只能有一个基类。System.Object 是所有类型的最终基类,这种继承方式称为实现继承。
接口继承:一个类只能继承一个类,但却可以继承多个接口。接口继承只是继承了接口的方法签名,而没有方法实现,具体的实现必须在派生类中完成。
实现继承和接口同时继承:一个类继承一个类的同时,可以同时继承自多个接口。中间用逗号隔开。
3.new、 virtual、override方法
new方法
方法签名:方法签名由方法名、参数数量、和参数类型共同决定。与返回类型无关。
当派生类和基类具有相同的方法签名时,调用派生类的方法时会屏蔽基类中具有相同签名的方法。但是在编译应用程序的时候会显示一条警告信息。New的作用就是关闭这种警告。而且会隐藏基类具有相同方法签名的方法。其实就是创建了与父类同名的另一个方法。
virtual和override方法
基类将一个方法声明为virtual,派生类就可以使用override来声明方法的另一个实现。在派生类中,一个方法的新的实现可以用base调用方法在基类中的原始实现。
规则:
1.不允许把Virtual或override方法声明为一个private。
2.两个方法的方法签名(名称、参数类型、参数个数)必须完全一致,返回类型也必须相同。
3.override只能重写virsual方法。
4.基类声明了一个virsual方法,如果它的派生类不用override声明方法,就不会重写基类。它就会成为和基类的方法完全不相关的另一个实现。这时也会出现警告,可以用NEW来消除警告。
5.一个override方法将隐式转换成virsual方法,可以在这个派生类未来的派生类中override。
…………
由于override和virsual涉及到多态的内容,如想了解更多请见下一章节“.NET面向对象特性之多态”的代码讲解。
4.抽象方法和抽象类的继承
抽象方法:抽象方法(abstract)与virsual方法相似,只是它不含方法主体。派生类必须重写。派生类必须有它对该方法的实现。
抽象类:为了明确声明不允许创建某个类的实例,必须将那个类显示地声明为抽象类。
抽象类是一种纯粹的抽象概念,目的是进行更好的分类。
5.继承的本质
继承主要强调的是通信,共性。
先看这段代码:
测试:
由于 Animal 为抽象类,我们只创建 Bird 对象和 Chicken对象。Bird bird 创建的是一个 Bird 类型的引用,而 new Bird()完成的是创建 Bird 对象,分配内存空间和初始化操作,然后将这个对象引用赋给 bird 变量,也就是建立 bird 变量与 Bird 对象的关联。以 Chicken 对象的创建为例,首先是字段,对象一经创建,会首先找到Bird,并为其字段分配存储空间,而 Bird 也会继续找到其父类 Animal,为其分配存储空间,依次类推直到递归结束,也就是完成 System.Object 内存分配为止。因此,对象的创建过程是按照顺序完成了对整个父类及其本身字段的内存创建,并且字段的存储顺序是由上到下排列,最高层类的字段排在最前面。其原因是如果父类和子类出现了同名字段,则在子类对象创建时,编译器会自动认为这是两个不同的字段而加以区别。
再看这行代码:Bird bird2 = new Chicken();
bird2是什么类型呢?
调用子类还是父类的方法,取决于创建的对象是子类对象还是父类对象,而不是它的引用类型。例如 Bird bird2 = new Chicken()时,我们关注的是其创建对象为 Chicken 类型,因此子类将继承父类的字段和方法,或者覆写父类的虚方法,而不用关注 bird2 的引用类型是否为 Bird。引用类型只是决定了方法的访问权限。
也可以这样理解:
Bird bird2=new Chicken();可以看做
Bird bird2=new Bird();
Chiken chiken=new Chiken();
bird2=chiken;
所以,bird2还是chiken类型。那么这个引用类型Bird有什么用?被子类隐藏掉的方法,必须通过转化为父类才能调用其方法。否则只能访问子类的方法。
执行就近原则:对于同名字段或者方法,编译器是按照其顺序查找来引用的,首先访问离它创建最近的字段或者方法。顺序上面已经说过了,父类是在前子类在后,所以和子类近,就先调用子类。这也是为什么new和override会覆盖基类方法,父类优先于子类编译的原因。
6.继承的复用性、扩展性、安全性
看了这么多,继承究竟有什么用,或者有哪些好处?它的复用性、扩展性、和安全性表现在什么地方?
通过继承,可以在不动原来调试好的代码的基础上,对代码进行复用(复用),极大的减少了代码量。还可以在子类中加入新的方法(扩展)。继承还可以复写virsual方法和new隐藏父类方法。任何事物都有两面性,继承也有缺点存在,但是作为面向对象三大特性之一,肯定是利大于弊,我们应该发扬利用其优点尽量避免缺点。
7.多聚合,少继承;低耦合,高内聚
聚合:关联关系,组合关系。
耦合:依赖关系。
待续……
8.扩展方法。
继承很强大,允许从一个类派生出另一个类,从而扩展类的功能。当我们想扩展一个类的时候,有时候继承不是一种最恰当的方案,比如这个类型是结构不能被继承,或者扩展的方法不能在父类实现,会影响现有代码等不利于我们快速扩展一个类型。这时候扩展方法就派上了用场。
欲想了解更多请参加:http://www.cnblogs.com/ldp615/archive/2009/08/07/1541404.html
这一篇涉及太多多态和封装的知识,这里只把含有继承的写出来留个印象,主要总结继承表现在哪些地方,继承的本质。下篇会代码演示继承中包含的多态和封装的内容。
这篇博文还有一个目的就是希望能抛砖引玉。我能力有限,没解释清楚的地方,欢迎总结。关于继承,漏掉的地方,欢迎补充。
总结过程中,我已经收获很多。如有高人补充,这篇博客的意义和价值就更高了。So,既然来了,留点经验吧。
下篇预告:.NET面向对象特性之“多态”。
下下篇预告:.NET面向对象特性之“封装”。
更新时间:待定。
说明:我是一只IT边上的蜗牛,尽管前面道路漫漫,但我始终渴望前行。
目录
背景返回目录
Java 中区分 Api 和 Spi,通俗的讲:Api 和 Spi 都是相对的概念,他们的差别只在语义上,Api 直接被应用开发人员使用,Spi 被框架扩张人员使用,详细内容可以看:http://www.cnblogs.com/happyframework/p/3325560.html。
Java类库中的实例返回目录
代码

1 Class.forName("com.mysql.jdbc.Driver");
2 Connection conn = DriverManager.getConnection(
3 "jdbc:mysql://localhost:3306/test", "root", "123456");
4 Statement stmt = conn.createStatement();
5
6 ResultSet rs = stmt.executeQuery("select * from Users");
说明
java.sql.Driver 是 Spi,com.mysql.jdbc.Driver 是 Spi 实现,其它的都是 Api。
如何实现这种结构?返回目录
代码
1 public class Program {
2
3 public static void main(String[] args) throws InstantiationException,
4 IllegalAccessException, ClassNotFoundException {
5 Class.forName("SpiA");
6
7 Api api = new Api("a");
8 api.Send("段光伟");
9 }
10 }
1 import java.util.*;
2
3 public class Api {
4 private static HashMap<String, Class<? extends Spi>> spis = new HashMap<String, Class<? extends Spi>>();
5 private String protocol;
6
7 public Api(String protocol) {
8 this.protocol = protocol;
9 }
10
11 public void Send(String msg) throws InstantiationException,
12 IllegalAccessException {
13 Spi spi = spis.get(protocol).newInstance();
14
15 spi.send("消息发送开始");
16 spi.send(msg);
17 spi.send("消息发送结束");
18 }
19
20 public static void Register(String protocol, Class<? extends Spi> cls) {
21 spis.put(protocol, cls);
22 }
23 }
1 public interface Spi {
2 void send(String msg);
3 }
1 public class SpiA implements Spi {
2 static {
3 Api.Register("a", SpiA.class);
4 }
5
6 @Override
7 public void send(String msg) {
8 System.out.println("SpiA:" + msg);
9 }
10
11 }
说明
Spi 实现的加载可以使用很多种方式,文中是最基本的方式。
备注返回目录
还记得大学期间学习 Java,当时看到 Spi 的开发方式就感觉一个词:不明觉厉。
时间流逝,经验增加,财富增加,幸福也会增加。
你真的懂printf么?
自从你进入程序员的世界,就开始照着书本编写着各种helloworld,大笔一挥:
printf("Hello World!\n");
于是控制台神奇地出现了一行字符串,计算机一句温馨的问候将多少年轻的骚年们引入了这个比58同城还神奇的世界......
今天的旅行从这里开始:
#include <stdio.h>
int main()
{
float a = 0.5;
printf("float a is %f\n",a);
return 0;
}
第一步:进入调试,我们首先进入了printf.c中的代码:
于是,我们知道了printf中关键的问题就是传入多个参数,以及如何将信息解析并输出。而参数的传递主要就是由几个宏完成的:va_list、va_start、va_end,这三个宏的定义在stdarg.h中又被替换了,而真正的定义则是在vadefs.h中:

我的机器是x86架构,32位win7系统,所以走的是上面这个宏定义块。打开了这个文件,你就知道了printf是多么的体系架构相关,所以导致printf的移植工作相当困难,至少我见过的每一本讲到printf和stdarg.h的书都会来上类似下面的一句:
This is a complex process. -_-b
va_list其实就是char *,唬人用的;va_start(ap, fmt)定位第一个参数的地址,va_end(ap)将ap指针指向空,防止野指针问题。接下来我们可以看到printf函数的实质就是try块中的三个函数,接着我们跟进去看看到底怎么回事。
第二步:接着程序指针又跳到了_stfbuf.c文件里,去执行_stbuf(stdout)函数了。
这个函数主要就是初始化缓冲区,为后面转化和打印做准备,缓冲区大小是4096个字节,若成功执行返回值为1。
第三步:接下来到文件output.c中的_output_l函数中:
这个函数算是核心吧,首先会设置一大堆的标志值,比如浮点精度,前后缀添0的位数什么的,具体每个是干什么的我也说不全。还是来看下面这个过程吧,1068行的while循环就开始解析字符串了,此时format的值就是“float a is %f\n”,一个字符一个字符地取放入ch中,然后下面去检查类型,比如此时ch的值就是f,是一个普通的字符,所以状态state的值就设置为ST_NORMAL,去执行下面的switch语句。

switch语句里,有很多状态分支,普通字符ST_NORMAL、百分号ST_PERCENT(这个对于printf来说就是比较特殊的)、ST_FLAG(符号)等等。对于普通字符,直接就写到缓冲区里去了,每写一个字符,format指针就向后移一位。当解析到%号时,就执行ST_PERCENT的分支。
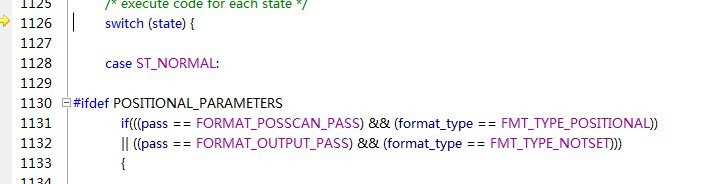
之后读取后一个字符,发现是f则再找到ST_TYPE的分支,执行数据的提取工作。argptr就是指向浮点数a地址的指针。按double类型提取数据并保存到tmp里。


第四步:当数据提取出来后,执行转换函数:
当数据保存到tmp中,就可以执行下列这个函数去将数字转换为字符串并存放到buf里了printf的关键就是如何解析(或者说提取)参数,最终将参数全部转换为字符串放到一个buffer里输出到屏幕上。浮点数转换后存放在char * 型的text.sz里,有兴趣可以深入这个convert函数里看看怎么转换的~(对于浮点好像有个名叫DTOA函数,记不太清了)

在这些工作完成后output_l函数就返回了,返回的是打印的字符数:20。(你可以数一下下面控制台的输出字符数,最后包括了换行符)
第五步:将字符串写到标准输出流:
返回到printf.c中,执行_ftbuf函数,其中再进入flush函数,在执行到下面指针指向的位置时,控制台才真正将所要打印的字符串打印出来,我们的任务这时才算完成了。


好了,再来说说我为什么要写这篇关于printf的文章,是因为在最近的项目里,碰到了跨平台printf的实现问题,浮点数打印不出来,查了很多资料都没有什么相关的,网上众说纷纭。于是我就到stackoverflow上发了个问,但是却是一件很不愉快的事情。看看截图吧,首先是我提的原问题:

接下来就好玩了~:
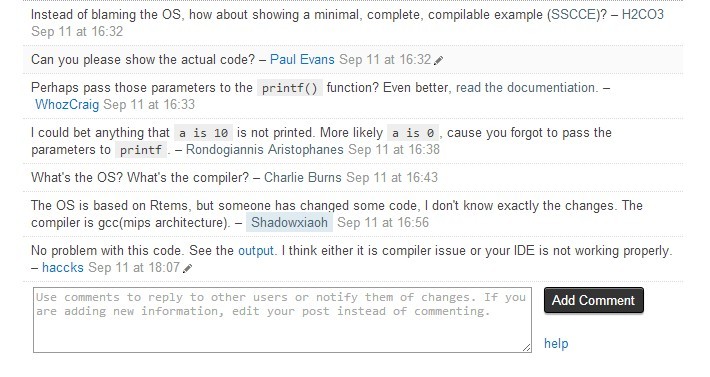
原帖地址:http://stackoverflow.com/questions/18746570/printf-cannot-print-float-double-correctly-on-the-screen
我确实一开始忘记打参数a,b,c了,但是这不影响问题本身,很明显最初回答的人根本没有经过思考,说我连printf的参数怎么写都不知道就来问,更有甚者把发问规则给我贴了出来,叫我不要发垃圾问题,还说我乱归结原因,我只能无奈呵呵了~。那么我想问的是:首先别人提的问题有你想象的那么二么?其次,如果别人真的二,按没写参数的代码区编译执行会出现所描述的现象么?在没有认真看别人问题和现象描述的情况下,秀下限的来了~ 而在我将问题修改过后(仅仅是加上了printf中的a、b、c而已),并且一一回复了留言后(我无一例外的以sorry开头),前面赶着来秀下限的几却个没有一个能回答上来,甚至连自己的看法都提不出(我能说什么呢?呵呵!)。
那么他们为什么回答不出来呢?因为只有真正做过嵌入式交叉开发的人才会知道这个问题的可能原因,在移植的工作中经常会碰到printf的相关问题,不光是浮点数打印不出来。好吧,看看真正懂的人是怎么说的吧,有两个回答都是可能的原因(本来还有人提的一个答案,被我屏蔽掉了,是来秀下限的~),群众的眼睛是雪亮的,从我在项目中调试的结果看,应该是下面第一个原因,任务栈的字节对齐问题,导致浮点传参错误;第二个回答也是一种可能,但我们在编译时确实没有加下面的宏。果断vote之~:

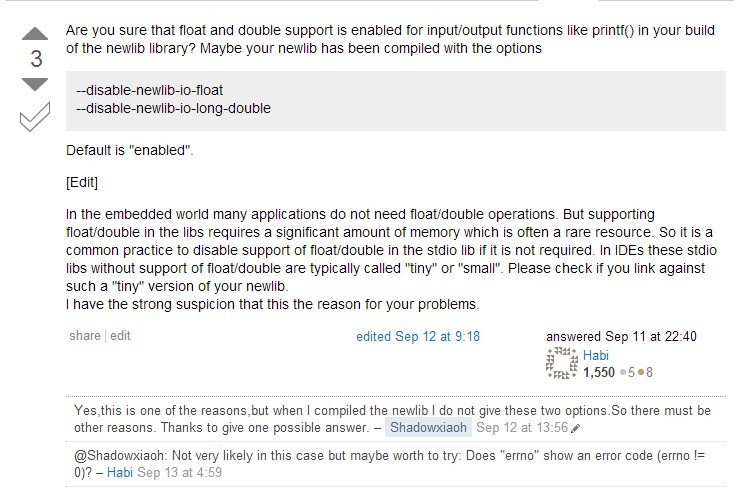
在C Interfaces and Implementations里也讲解了一种printf的实现,对标准C库的printf有一定的改进,代码是要讲可重用性和健壮性的,有兴趣可以看看。
好了,扪心自问一下,你真的懂printf么?
Sparse AutoEncoder简介
1. AutoEncoder
AutoEncoder是一种特殊的三层神经网络, 其输出等于输入:y(i)=x(i), 如下图所示:
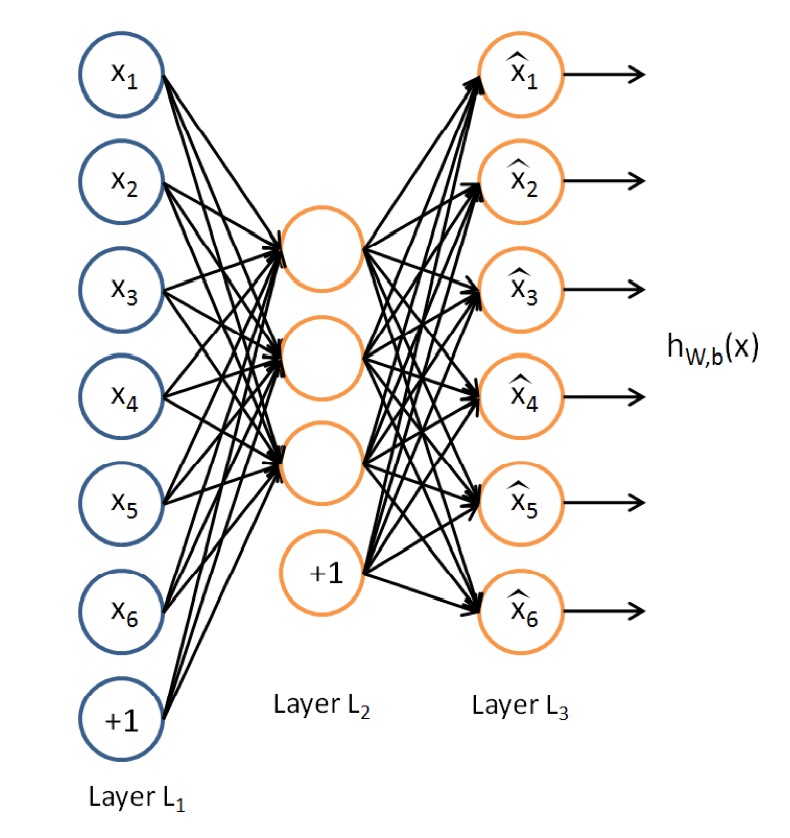
亦即AutoEncoder想学到的函数为fW,b≈x, 来使得输出x^比较接近x. 乍看上去学到的这种函数很平凡, 没啥用处, 实际上, 如果我们限制一下AutoEncoder的隐藏单元的个数小于输入特征的个数, 便可以学到数据的很多有趣的结构. 如果特征之间存在一定的相关性, 则AutoEncoder会发现这些相关性.
2. Sparse AutoEncoder
我们可以限制隐藏单元的个数来学到有用的特征, 或者可以对网络施加其他的限制条件, 而不限制隐藏单元的个数. 特别的, 我们可以对隐藏单元施加稀疏性限制. 具体的, 一个神经元是激活的当且仅当其输出值比较接近1, 一个神经元是不激活的当且仅当其输出值比较接近0. 我们可以限制神经元在大多数时间下都是不激活的(亦即Sparse Filtering中的Lifetime Sparsity概念).
定义a(2)j为AutoEncoder中隐藏单元的激活值, 我们形式化的定义如下的限制:
其中ρ是稀疏性参数, 一般取值为一个比较接近0的数, 比如0.05.
为了使得学到的AutoEncoder达到上述的稀疏性要求, 我们在优化目标里添加了新的一项, 用于惩罚那些偏离ρ太多的ρ^j. 可以使用KL Divergence:
上式可也以写作:
下图展示了KL Divergence的特性: ρ^j越接近ρ(此处为0.2), 则KL Divergence越小.
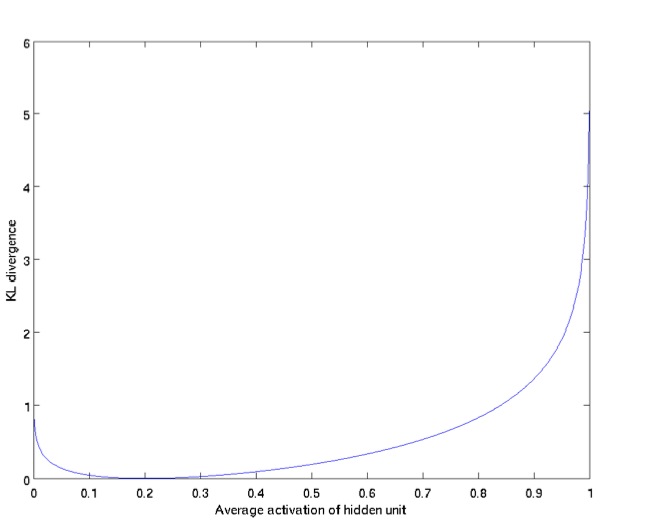
所以, Sparse AutoEncoder的损失函数为:
其中
添加KL Divergence后的cost function后的偏导数为:


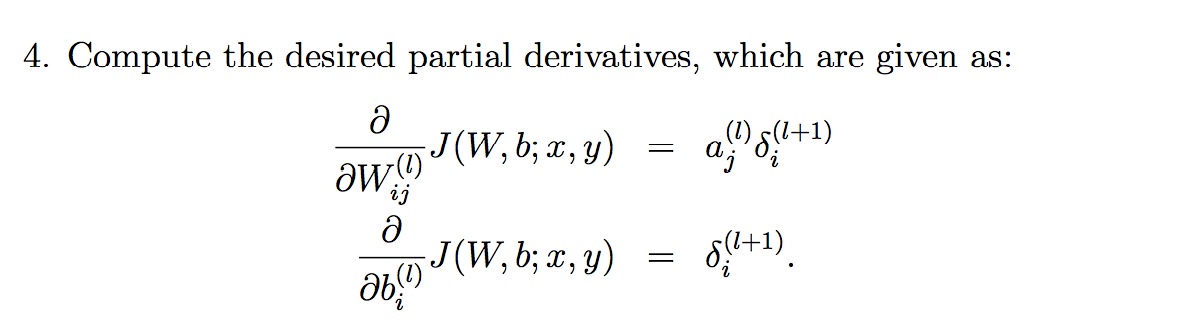
有个新的偏导数之后, 使用Back Propagation来优化整个神经网络:

参考文献:
[1]. Sparse AutoEncoder. Andrew Ng.
将我的博客迁移到亚马逊云端(2)
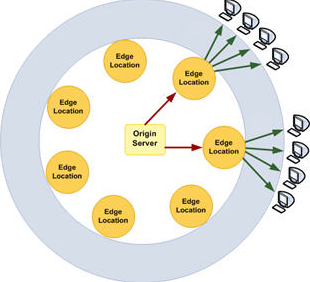
上篇文章中讲了将我的Octopress博客部署到亚马逊的S3上。而这篇文章则主要讲如何使用亚马逊提供的CloudFront作为内容分发并将自己的独立域名绑定到此CloudFront上。
首先,需要启用亚马逊的CloudFront。我刚开始以为只需要‘sign up’就行。但是当我在’AWS Management Console’中点击‘Services’中的CloudFront时,却得到了‘Account Blocked’错误。
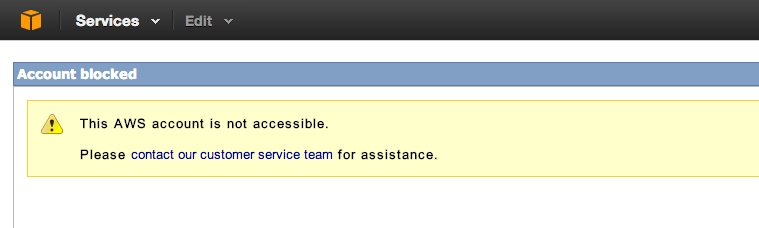
这个问题很奇怪,CloudFront明明已经在’ Services You’re Signed Up For’ list中了,但是咋个无法使用那?我只好使用gmail给Amazon客服中心发了邮件询问,结果客服中心告诉我需要使用一个business email(商业邮箱)来发送激活申请。我只好使用公司邮箱发送了申请,过了几个小时就收到了回信,告诉我已经可以使用了。
登陆’AWS Management Console’后,点击’Services’中的‘CloudFront’,就可以看到控制界面了。
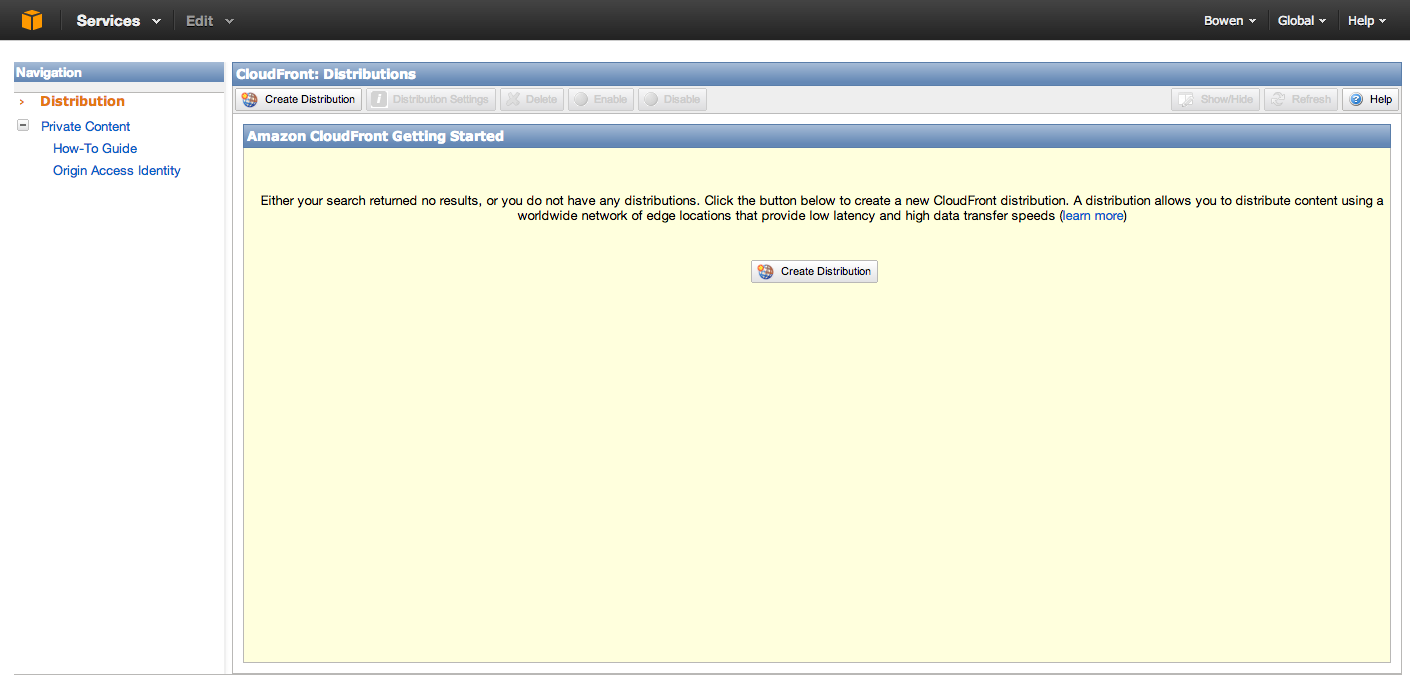
点击’Create Distribution’按钮,Delivery method选择Download。 Download主要针对一些html,css,js等静态文件,而Streaming则主要是一些音视频文件。
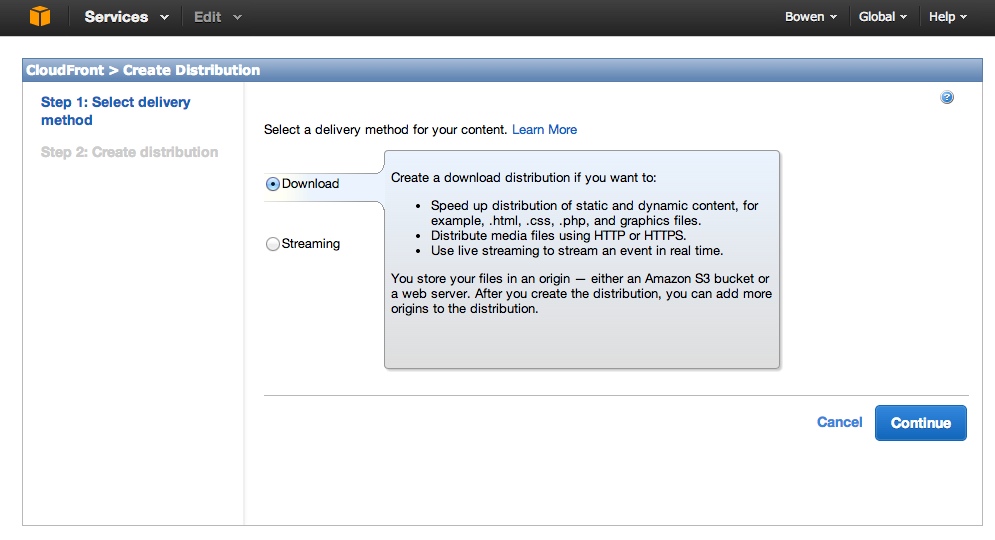
下一步,要选择Origin,即要进行内容分发的源。虽然亚马逊会自动列出你的S3 bucket,但是千万不要选。而是自己手动输入example.com这个Bucket的Endpoint(Endpoint在S3 Console的Properties标签下的Static Website hosting里看得到)。为什么不直接选S3 bucket那?这是因为当我们访问一个目录时,我们期望能返回默认的object。虽然CouldFront有个Default Root Object设置,只是对根目录起作用,对子目录不起作用。如果使用Bucket的Endpoint,再加上之前已经给该Bucket配置了Default Object,就可以解决这个问题。
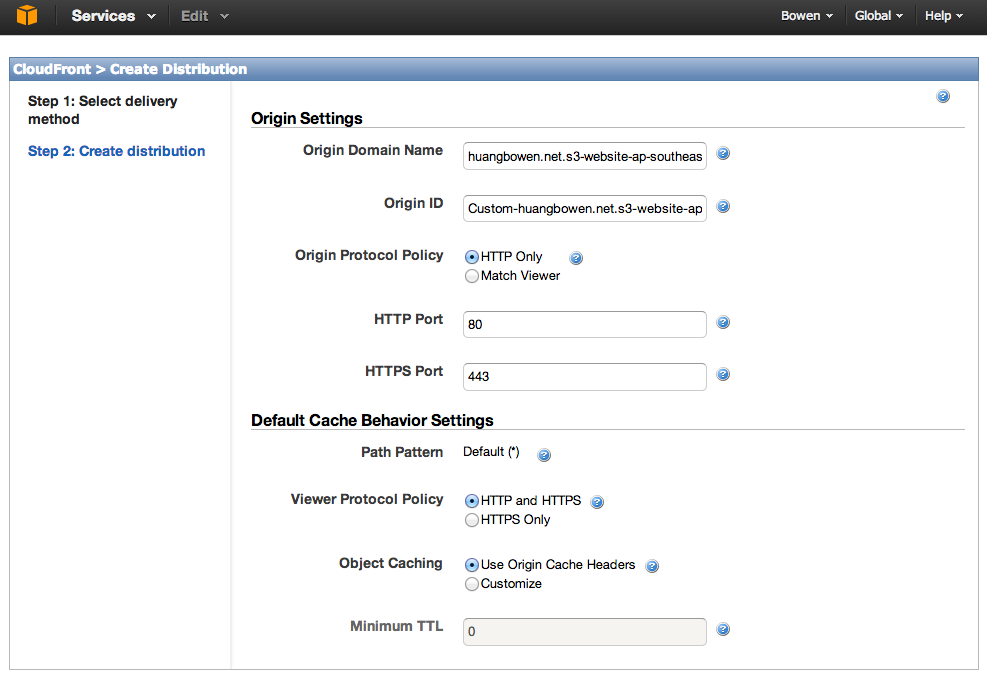
在CNAMEs项中输入自己的域名,多个域名以逗号分隔。
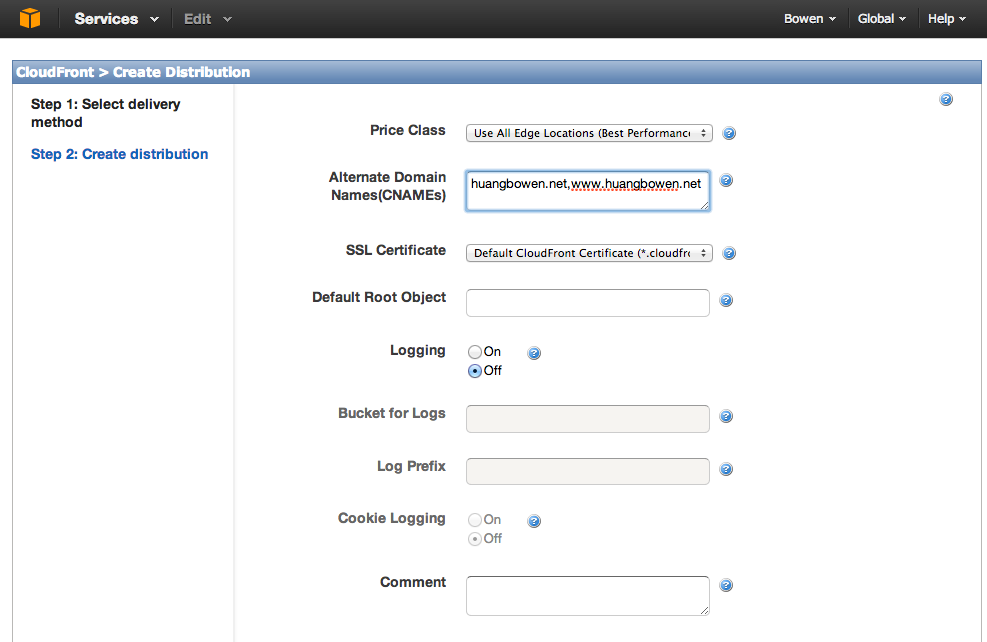
这样子CoudFront就算配置好了。通过管理页面也可以配置Error page等。
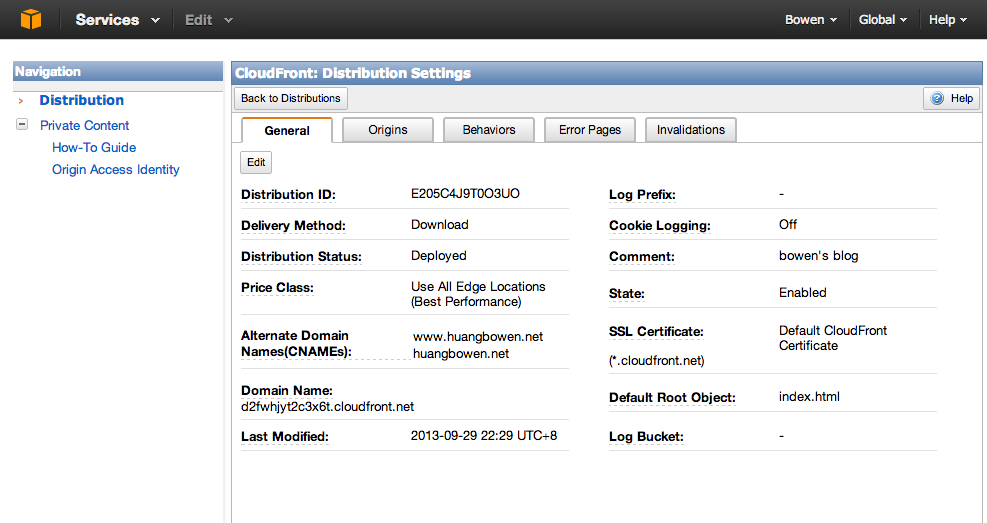
接下来,需要登录自己域名的提供商的管理后台,添加一条自己独立域名的转发,转发到这个CloudFront的Domain Name上。
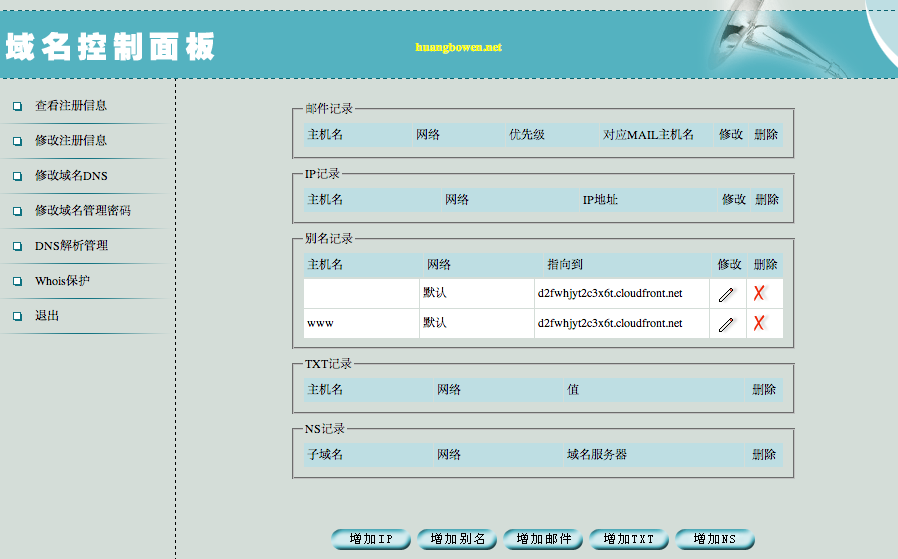
一般需要10分钟到2个小时等待新的域名转发设置生效。
另外要专门提一下CloudFront的cache机制。CloudFront主要通过检测Origin中的http header中的cache-control属性。根据cache-control的值来设置cache时间。但是CloudFront最长只保留24小时的cache,过后就会清空并重新cache。对于我的小博客来说24小时太长了,那如何给Octopress注入cache-control这个http header那?其实在上篇文章已经提过了。S3支持给每个object设置 http header,我们可以通过s3cmd来自动设置,这就是为什么在S3 task中要加入这个参数。
1 |
|
其中S3_cache_secs就是设置cache时间,我把它设置为3600,也就是一个小时。
至此,我的Octopress博客已经在云端了。感觉访问速度比以前快不少。以前我是部署在github pages,服务器放置在美国。现在使用了CloudFront,亚马逊会自动将请求转发到最近的CloudFront edge location。接下来我再研究下 Amazon Route 53,看看有什么好玩的。
我的博客地址: http://www.huangbowen.net
出处:http://www.cnblogs.com/huang0925
黄博文的地盘
本文版权归本人和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
.NET面向对象特性之“继承”的更多相关文章
- OC面向对象特性: 继承
基础知识 1.标识符是有字母,数字,下划线组成的. 2.首字母只能是字母,下划线,不能为数字. 3.标识符要做到见名之意. 4.标识符不能使用已定义的关键字和预定义标识符. 继承 继承:子类可以直接访 ...
- 一种C语言实现面向对象特性的继承,多态
基类: //.h typedef int (*TELE_SEND_CB)(char *pdata, int len); //函数表结构 typedef struct tele_pro_base_vtb ...
- Javascript面向对象特性实现封装、继承、接口详细案例——进级高手篇
Javascript面向对象特性实现(封装.继承.接口) Javascript作为弱类型语言,和Java.php等服务端脚本语言相比,拥有极强的灵活性.对于小型的web需求,在编写javascript ...
- 【游戏开发】在Lua中实现面向对象特性——模拟类、继承、多态
一.简介 Lua是一门非常强大.非常灵活的脚本语言,自它从发明以来,无数的游戏使用了Lua作为开发语言.但是作为一款脚本语言,Lua也有着自己的不足,那就是它本身并没有提供面向对象的特性,而游戏开发是 ...
- Javascript面向对象特性实现封装、继承、接口详细案例
Javascript面向对象特性实现(封装.继承.接口) Javascript作为弱类型语言,和Java.php等服务端脚本语言相比,拥有极强的灵活性.对于小型的web需求,在编写javascript ...
- python基础学习Day17 面向对象的三大特性之继承、类与对象名称空间小试
一.课前回顾 类:具有相同属性和方法的一类事物 实例化:类名() 过程: 开辟了一块内存空间 执行init方法 封装属性 自动的把self返回给实例化对象的地方 对象:实例 一个实实在在存在的实体 组 ...
- Java语言中的面向对象特性:封装、继承、多态,面向对象的基本思想(总结得不错)
Java语言中的面向对象特性(总结得不错) [课前思考] 1. 什么是对象?什么是类?什么是包?什么是接口?什么是内部类? 2. 面向对象编程的特性有哪三个?它们各自又有哪些特性? 3. 你知道jav ...
- Java学习笔记二十一:Java面向对象的三大特性之继承
Java面向对象的三大特性之继承 一:继承的概念: 继承是java面向对象编程技术的一块基石,因为它允许创建分等级层次的类. 继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方 ...
- Java第四次作业——面向对象高级特性(继承和多态)
Java第四次作业--面向对象高级特性(继承和多态) (一)学习总结 1.学习使用思维导图对Java面向对象编程的知识点(封装.继承和多态)进行总结. 2.阅读下面程序,分析是否能编译通过?如果不能, ...
随机推荐
- jquery扩展
jQuery插件的开发包括两种: 一种是类级别的插件开发,即给jQuery添加新的全局函数,相当于给jQuery类本身添加方法.jQuery的全局函数就是属于jQuery命名空间的函数,另一种是对象级 ...
- linux_常用压缩,解压缩命令
01-.tar格式解包:[*******]$ tar xvf FileName.tar打包:[*******]$ tar cvf FileName.tar DirName(注:tar是打包,不是压缩! ...
- 怎样将short[]数组转换成byte[]数组
byte[] byteArray = Array.ConvertAll<short, byte>(shortArray, Convert.ToByte);
- WebView无法放大缩小解决方式
先看看我们之前所写的代码 1) 加入权限:AndroidManifest.xml中必须使用了许可"android.permission.INTERNET" 2) 使用了一个WebV ...
- JqueryAjax异步加载在ASP.NET
前台代码 <script src="Scripts/jquery-1.4.1.min.js" type="text/javascript">< ...
- pinyin4j新手教程
Pinyin4j新手教程 pinyin4j是一个支持将简体和繁体中文转换到成拼音的Java开源类库,作者是Li Min (xmlerlimin@gmail.com). 下面是一些详细的介绍和使用方式. ...
- DevExpress asp.net 导出Excel 自动开启迅雷问题,默认保存为aspx页面
目前采取曲线救国策略: 利用MVC ..... <dx:ASPxGridView ID="ASPxGridView1" runat="server" Au ...
- linux open
一直记住不打开文件时候的mode,今天发现原来可以直接用0644这样的八进制数字代替,好开森 #include <stdio.h> #include <sys/types.h> ...
- code forces 148D Bag of mice (概率DP)
time limit per test 2 seconds memory limit per test 256 megabytes input standard input output standa ...
- 我的MYSQL学习心得(十一)
原文:我的MYSQL学习心得(十一) 我的MYSQL学习心得(十一) 我的MYSQL学习心得(一) 我的MYSQL学习心得(二) 我的MYSQL学习心得(三) 我的MYSQL学习心得(四) 我的MYS ...