笔记整理--C语言
linux下错误的捕获:errno和strerror的使用 - Google Chrome (2014/2/26 17:31:39)
linux下错误的捕获:errno和strerror的使用
2011-08-09 13:44:12
在程序代码中包含 #include <errno.h>,然后每次程序调用失败的时候,系统会自动用用错误代码填充errno这个全局变量,这样你只需要读errno这个全局变量就可以获得失败原因了。
例如:
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main(void)
{
int fd;
extern int errno;
if((fd = open("/dev/dsp",O_WRONLY)) < 0)
{
printf("errno=%d\n",errno);
}
exit(0);
}
如果dsp设备忙的话errno值将是16。
errno.h中定义的错误代码值如下:
查 看错误代码errno是调试程序的一个重要方法。当linuc C api函数发生异常时,一般会将errno变量(需include errno.h)赋一个整数值,不同的值表示不同的含义,可以通过查看该值推测出错的原因。在实际编程中用这一招解决了不少原本看来莫名其妙的问题。比较 麻烦的是每次都要去linux源代码里面查找错误代码的含义,现在把它贴出来,以后需要查时就来这里看了。
以下来自linux 2.4.20-18的内核代码中的/usr/include/asm/errno.h
#ifndef _I386_ERRNO_H
#define _I386_ERRNO_H
#define EPERM 1 /* Operation not permitted */
#define ENOENT 2 /* No such file or directory */
#define ESRCH 3 /* No such process */
#define EINTR 4 /* Interrupted system call */
#define EIO 5 /* I/O error */
#define ENXIO 6 /* No such device or address */
#define E2BIG 7 /* Arg list too long */
#define ENOEXEC 8 /* Exec format error */
#define EBADF 9 /* Bad file number */
#define ECHILD 10 /* No child processes */
#define EAGAIN 11 /* Try again */
#define ENOMEM 12 /* Out of memory */
#define EACCES 13 /* Permission denied */
#define EFAULT 14 /* Bad address */
#define ENOTBLK 15 /* Block device required */
#define EBUSY 16 /* Device or resource busy */
#define EEXIST 17 /* File exists */
#define EXDEV 18 /* Cross-device link */
#define ENODEV 19 /* No such device */
#define ENOTDIR 20 /* Not a directory */
#define EISDIR 21 /* Is a directory */
#define EINVAL 22 /* Invalid argument */
#define ENFILE 23 /* File table overflow */
#define EMFILE 24 /* Too many open files */
#define ENOTTY 25 /* Not a typewriter */
#define ETXTBSY 26 /* Text file busy */
#define EFBIG 27 /* File too large */
#define ENOSPC 28 /* No space left on device */
#define ESPIPE 29 /* Illegal seek */
#define EROFS 30 /* Read-only file system */
#define EMLINK 31 /* Too many links */
#define EPIPE 32 /* Broken pipe */
#define EDOM 33 /* Math argument out of domain of func */
#define ERANGE 34 /* Math result not representable */
#define EDEADLK 35 /* Resource deadlock would occur */
#define ENAMETOOLONG 36 /* File name too long */
#define ENOLCK 37 /* No record locks available */
#define ENOSYS 38 /* Function not implemented */
#define ENOTEMPTY 39 /* Directory not empty */
#define ELOOP 40 /* Too many symbolic links encountered */
#define EWOULDBLOCK EAGAIN /* Operation would block */
#define ENOMSG 42 /* No message of desired type */
#define EIDRM 43 /* Identifier removed */
#define ECHRNG 44 /* Channel number out of range */
#define EL2NSYNC 45 /* Level 2 not synchronized */
#define EL3HLT 46 /* Level 3 halted */
#define EL3RST 47 /* Level 3 reset */
#define ELNRNG 48 /* Link number out of range */
#define EUNATCH 49 /* Protocol driver not attached */
#define ENOCSI 50 /* No CSI structure available */
#define EL2HLT 51 /* Level 2 halted */
#define EBADE 52 /* Invalid exchange */
#define EBADR 53 /* Invalid request descriptor */
#define EXFULL 54 /* Exchange full */
#define ENOANO 55 /* No anode */
#define EBADRQC 56 /* Invalid request code */
#define EBADSLT 57 /* Invalid slot */
#define EDEADLOCK EDEADLK
#define EBFONT 59 /* Bad font file format */
#define ENOSTR 60 /* Device not a stream */
#define ENODATA 61 /* No data available */
#define ETIME 62 /* Timer expired */
#define ENOSR 63 /* Out of streams resources */
#define ENONET 64 /* Machine is not on the network */
#define ENOPKG 65 /* Package not installed */
#define EREMOTE 66 /* Object is remote */
#define ENOLINK 67 /* Link has been severed */
#define EADV 68 /* Advertise error */
#define ESRMNT 69 /* Srmount error */
#define ECOMM 70 /* Communication error on send */
#define EPROTO 71 /* Protocol error */
#define EMULTIHOP 72 /* Multihop attempted */
#define EDOTDOT 73 /* RFS specific error */
#define EBADMSG 74 /* Not a data message */
#define EOVERFLOW 75 /* Value too large for defined data type */
#define ENOTUNIQ 76 /* Name not unique on network */
#define EBADFD 77 /* File descriptor in bad state */
#define EREMCHG 78 /* Remote address changed */
#define ELIBACC 79 /* Can not access a needed shared library */
#define ELIBBAD 80 /* Accessing a corrupted shared library */
#define ELIBSCN 81 /* .lib section in a.out corrupted */
#define ELIBMAX 82 /* Attempting to link in too many shared libraries */
#define ELIBEXEC 83 /* Cannot exec a shared library directly */
#define EILSEQ 84 /* Illegal byte sequence */
#define ERESTART 85 /* Interrupted system call should be restarted */
#define ESTRPIPE 86 /* Streams pipe error */
#define EUSERS 87 /* Too many users */
#define ENOTSOCK 88 /* Socket operation on non-socket */
#define EDESTADDRREQ 89 /* Destination address required */
#define EMSGSIZE 90 /* Message too long */
#define EPROTOTYPE 91 /* Protocol wrong type for socket */
#define ENOPROTOOPT 92 /* Protocol not available */
#define EPROTONOSUPPORT 93 /* Protocol not supported */
#define ESOCKTNOSUPPORT 94 /* Socket type not supported */
#define EOPNOTSUPP 95 /* Operation not supported on transport endpoint */
#define EPFNOSUPPORT 96 /* Protocol family not supported */
#define EAFNOSUPPORT 97 /* Address family not supported by protocol */
#define EADDRINUSE 98 /* Address already in use */
#define EADDRNOTAVAIL 99 /* Cannot assign requested address */
#define ENETDOWN 100 /* Network is down */
#define ENETUNREACH 101 /* Network is unreachable */
#define ENETRESET 102 /* Network dropped connection because of reset */
#define ECONNABORTED 103 /* Software caused connection abort */
#define ECONNRESET 104 /* Connection reset by peer */
#define ENOBUFS 105 /* No buffer space available */
#define EISCONN 106 /* Transport endpoint is already connected */
#define ENOTCONN 107 /* Transport endpoint is not connected */
#define ESHUTDOWN 108 /* Cannot send after transport endpoint shutdown */
#define ETOOMANYREFS 109 /* Too many references: cannot splice */
#define ETIMEDOUT 110 /* Connection timed out */
#define ECONNREFUSED 111 /* Connection refused */
#define EHOSTDOWN 112 /* Host is down */
#define EHOSTUNREACH 113 /* No route to host */
#define EALREADY 114 /* Operation already in progress */
#define EINPROGRESS 115 /* Operation now in progress */
#define ESTALE 116 /* Stale NFS file handle */
#define EUCLEAN 117 /* Structure needs cleaning */
#define ENOTNAM 118 /* Not a XENIX named type file */
#define ENAVAIL 119 /* No XENIX semaphores available */
#define EISNAM 120 /* Is a named type file */
#define EREMOTEIO 121 /* Remote I/O error */
#define EDQUOT 122 /* Quota exceeded */
#define ENOMEDIUM 123 /* No medium found */
#define EMEDIUMTYPE 124 /* Wrong medium type */
#endif
同时也可以使用strerror()来自己翻译
如:
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main(void)
{
int fd;
extern int errno;
if((fd = open("/dev/dsp",O_WRONLY)) < 0)
{
printf("errno=%d\n",errno);
char * mesg = strerror(errno);
printf("Mesg:%s\n",mesg);
}
exit(0);
}
dsp设备忙的话将输出如下:
errno=16
Mesg:Device or resource busy
linux中c语言errno的使用 | 博学无忧 - Google Chrome (2014/2/26 17:48:45)
在linux中使用c语言编程时,errno是个很有用的动动。他可以把最后一次调用c的方法的错误代码保留。但是如果最后一次成功的调用c的方法,errno不会改变。因此,只有在c语言函数返回值异常时,再检测errno。
errno会返回一个数字,每个数字代表一个错误类型。详细的可以查看头文件。/usr/include/asm/errno.h
如何把errno的数字转换成相应的文字说明?
方式一:可以使用strerrno函数
|
1
|
char *strerror(int errno) |
使用方式如下:
|
1
|
fprintf(stderr,"error in CreateProcess %s, Process ID %d ",strerror(errno),processID) |
将错误代码转换为字符串错误信息,可以将该字符串和其它的信息组合输出到用户界面。
注:假设processID是一个已经获取了的整形ID
方式二:使用perror函数
|
1
|
void perror(const char *s) |
函数说明
perror ( )用来将上一个函数发生错误的原因输出到标准错误(stderr),参数s 所指的字符串会先打印出,后面再加上错误原因 字符串。此错误原因依照全局变量 errno 的值来决定要输出的字符串。
另外并不是所有的c函数调用发生的错误信息都会修改errno。例如gethostbyname函数。
errno是否是线程安全的?
errno是支持线程安全的,而且,一般而言,编译器会自动保证errno的安全性。
我们看下相关头文件 /usr/include/bits/errno.h
会看到如下内容:
# if !defined _LIBC || defined _LIBC_REENTRANT
/* When using threads, errno is a per-thread value. */
# define errno (*__errno_location ())
# endif
# endif /* !__ASSEMBLER__ */
#endif /* _ERRNO_H */
也就是说,在没有定义__LIBC或者定义_LIBC_REENTRANT的时候,errno是多线程/进程安全的。
为了检测一下你编译器是否定义上述变量,不妨使用下面一个简单程序。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#include <stdio.h>#include <errno.h>int main( void ){#ifndef __ASSEMBLER__ printf( "Undefine __ASSEMBLER__/n" );#else printf( "define __ASSEMBLER__/n" );#endif#ifndef __LIBC printf( "Undefine __LIBC/n" );#else printf( "define __LIBC/n" );#endif#ifndef _LIBC_REENTRANT printf( "Undefine _LIBC_REENTRANT/n" );#else printf( "define _LIBC_REENTRANT/n" );#endif return 0;} |
数组指针和指针数组的区别 - hongcha_717 - 博客园 - Google Chrome (2014/2/24 17:04:35)
数组指针和指针数组的区别
数组指针(也称行指针)
定义 int (*p)[n];
()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。
如要将二维数组赋给一指针,应这样赋值:
int a[3][4];
int (*p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a; //将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++; //该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
所以数组指针也称指向一维数组的指针,亦称行指针。
指针数组
定义 int *p[n];
[]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1是错误的,这样赋值也是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p=a; 这里*p表示指针数组第一个元素的值,a的首地址的值。
如要将二维数组赋给一指针数组:
int *p[3];
int a[3][4];
for(i=0;i<3;i++)
p[i]=a[i];
这里int *p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2]
所以要分别赋值。
这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。
还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。
比如要表示数组中i行j列一个元素:
*(p[i]+j)、*(*(p+i)+j)、(*(p+i))[j]、p[i][j]
优先级:()>[]>*
数组指针(也称行指针)
定义 int (*p)[n];
()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。
如要将二维数组赋给一指针,应这样赋值:
int a[3][4];
int (*p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a; //将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++; //该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
所以数组指针也称指向一维数组的指针,亦称行指针。
指针数组
定义 int *p[n];
[]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1是错误的,这样赋值也是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p=a; 这里*p表示指针数组第一个元素的值,a的首地址的值。
如要将二维数组赋给一指针数组:
int *p[3];
int a[3][4];
for(i=0;i<3;i++)
p[i]=a[i];
这里int *p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2]
所以要分别赋值。
这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。
还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。
比如要表示数组中i行j列一个元素:
*(p[i]+j)、*(*(p+i)+j)、(*(p+i))[j]、p[i][j]
优先级:()>[]>*
失落的C语言结构体封装艺术 - 博客 - 伯乐在线 - Google Chrome (2014/2/8 11:53:57)
失落的C语言结构体封装艺术
Eric S. Raymond
目录
1. 谁该阅读这篇文章
2. 我为什么写这篇文章
3.对齐要求
4.填充
5.结构体对齐及填充
6.结构体重排序
7.难以处理的标量的情况
8.可读性和缓存局部性
9.其他封装的技术
10.工具
11.证明及例外
12.版本履历
1. 谁该阅读这篇文章
本文是关于削减C语言程序内存占用空间的一项技术——为了减小内存大小而手工重新封装C结构体声明。你需要基本的C语言的基本知识来读懂本文。
如果你要为内存有限制的嵌入式系统、或者操作系统内核写代码,那么你需要懂这项技术。如果你在处理极大的应用程序数据集,以至于你的程序常常达到内存的界限时,这项技术是有帮助的。在任何你真的真的需要关注将高速缓存行未命中降到最低的应用程序里,懂得这项技术是很好的。
最后,理解该技术是一个通往其他深奥的C语言话题的入口。直到你掌握了它,你才成为一个高端的C程序员。直到你可以自己写出这篇文档并且可以理智地评论它,你才成为一位C语言大师。
2. 我为什么写这篇文章
本文之所以存在,是因为在2013年底,我发现我自己在大量使用一项C语言的优化技术,我早在二十多年前就已经学会了该技术,不过在那之后并没怎么使用过。
我需要减小一个程序的内存占用空间,它用了几千——有时是几十万个——C结构体的实例。这个程序是cvs-fast-export,而问题在于处理巨大的代码库时,它曾因内存耗尽的错误而濒临崩溃。
在这类情况下,有好些办法能极大地减少内存使用的,比如小心地重新安排结构体成员的顺序之类的。这可以获得巨大的收益——在我的事例中,我能够减掉大约40%的工作区大小,使得程序能够在不崩溃的情况下处理大得多的代码库。
当我解决这个问题,并且回想我所做的工作时,我开始发现,我在用的这个技术现今应被忘了大半了。一个网络调查确认,C程序员好像已经不再谈论该技术了,至少在搜索引擎可以看到的地方不谈论了。有几个维基百科条目触及了这个话题,但是我发现没人能全面涵盖。
实际上这个现象也是有合理的理由的。计算机科学课程(应当)引导人们避开细节的优化而去寻找更好的算法。机器资源价格的暴跌已经使得压榨内存用量变得不那么必要了。而且,想当年,骇客们曾经学习如何使用该技术,使得他们在陌生的硬件架构上撞墙了——现在已经不太常见的经历。
但是这项技术仍然在重要的场合有价值, 并且只要内存有限,就能永存。本文目的就是让C程序员免于重新找寻这项技术,而让他们可以集中精力在更重要的事情上。
3. 对齐要求(Alignment Requirement)
要明白的第一件事是,在现代处理器上,你的C编译器在内存里对基本的C数据类型的存放方式是受约束的,为的是内存访问更快。
在x86或者ARM处理器上,基本的C数据类型的储存一般并不是起始于内存中的任意字节地址。而是,每种类型,除了字符型以外,都有对齐要求;字符可以起始于任何字节地址,但是2字节的短整型必须起始于一个偶数地址,4字节整型或者浮点型必须起始于被4整除的地址,以及8字节长整型或者双精度浮点型必须起始于被8整除的地址。带符号与不带符号之间没有差别。
这个的行话叫:在x86和ARM上,基本的C语言类型是自对齐(self-aligned)的。指针,无论是32位(4字节)亦或是64位(8字节)也都是自对齐的。
自对齐使得访问更快,因为它使得一条指令就完成对类型化数据的取和存操作。没有对齐的约束,反过来,代码最终可能会不得不跨越机器字的边界做两次或更多次访问。字符是特殊的情况;无论在一个单机器字中的何处,存取的花费都是一样的。那就是为什么字符型没有被建议对齐。
我说“在现代的处理器上”是因为,在一些旧的处理器上,强制让你的C程序违反对齐约束(比方说,将一个奇数的地址转换成一个整型指针,并试图使用它)不仅会使你的代码慢下来,还会造成非法指令的错误。比如在Sun的SPARC芯片上就曾经这么干。实际上,只要够决心并在处理器上设定正确(e18)的硬件标志位,你仍然可以在x86上触发此错误。
此外,自对齐不是唯一的可能的规则。历史上,一些处理器(特别是那些缺少移位暂存器的)有更强的限制性规则。如果你做嵌入式系统,你也许会在跌倒在这些丛林陷阱中。注意,这是有可能的。
有时你可以通过编译指示,强制让你的编译器不使用处理器正常的对齐规则,通常是#pragma pack。不要随意使用,因为它会导致产生开销更大、更慢的代码。使用我在这里描述的技术,通常你可以节省同样或者几乎同样多的内存。
#pragma pack的唯一好处是,如果你不得不将你的C语言数据分布精确匹配到某些位级别的硬件或协议的需求,比如一个内存映射的硬件端口,要求违反正常的对齐才能奏效。如果你遇到那种情况,并且你还未理解我在这里写的这一切,你会有大麻烦的,我只能祝你好运了。
4. 填充(Padding)
现在我们来看一个简单变量在内存里的分布的例子。考虑在C模块的最顶上的以下一系列的变量声明:
|
1
2
3
|
char *p;char c;int x; |
如果你不知道任何关于数据对齐的事情,你可能会假设这3个变量在内存里会占据一个连续字节空间。那也就是说,在一个32位机器上,指针的4字节,之后紧接着1字节的字符型,且之后紧接着4字节的整型。在64位机器只在指针是8字节上会有所不同。
这里是实际发生的(在x86或ARM或其他任何有自对齐的处理器类型)。p的存储地址始于一个自对齐的4字节或者8字节边界,取决于机器的字长。这是指针对齐——可能是最严格的情况。
紧跟着的是c的存储地址。但是x的4字节对齐要求,在内存分布上造成了一个间隙;变成了恰似第四个变量插在其中,像这样:
|
1
2
3
4
|
char *p; /* 4 or 8 bytes */char c; /* 1 byte */char pad[3]; /* 3 bytes */int x; /* 4 bytes */ |
pad[3]字符数组表示了一个事实,结构体中有3字节的无用的空间。 老派的术语称之为“slop(水坑)”。
比较如果x是2字节的短整型会发生什么:
|
1
2
3
|
char *p;char c;short x; |
在那个情况下,实际的内存分布会变成这样:
|
1
2
3
4
|
char *p; /* 4 or 8 bytes */char c; /* 1 byte */char pad[1]; /* 1 byte */short x; /* 2 bytes */ |
另一方面,如果x是一个在64位机上的长整型
|
1
2
3
|
char *p;char c;long x; |
最终我们会得到:
|
1
2
3
4
|
char *p; /* 8 bytes */char c; /* 1 bytechar pad[7]; /* 7 bytes */long x; /* 8 bytes */ |
如果你已仔细看到这里,现在你可能会想到越短的变量声明先声明的情况:
|
1
2
3
|
char c;char *p;int x; |
如果实际的内存分布写成这样:
|
1
2
3
4
5
|
char c;char pad1[M];char *p;char pad2[N];int x; |
我们可以说出M和N的值吗?
首先,在这个例子中,N是零。x的地址,紧接在p之后,是保证指针对齐的,肯定比整型对齐更严格的。
M的值不太能预测。如果编译器恰巧把c映射到机器字的最后一个字节,下一个字节(p的第一部分)会成为下一个机器字的第一个字节,并且正常地指针对齐。M为零。
c更可能会被映射到机器字的第一个字节。在那个情况下,M会是以保证p指针对齐而填补的数——在32位机器上是3,64位机器上是7。
如果你想让那些变量占用更少的空间,你可以通过交换原序列中的x和c来达到效果。
|
1
2
3
|
char *p; /* 8 bytes */long x; /* 8 bytes */char c; /* 1 byte |
通常,对于C程序里少数的简单变量,你可以通过调整声明顺序来压缩掉极少几个字节数,不会有显著的节约。但当用于非标量变量(nonscalar variables),尤其是结构体时,这项技术会变得更有趣。
在我们讲到非标量变量之前,让我们讲一下标量数组。在一个有自对齐类型的平台上,字符、短整型、整型、长整型、指针数组没有内部填充。每个成员会自动自对齐到上一个之后(译者注:原文 self-aligned at the end of the next one 似有误)。
在下一章,我们会看到对于结构体数组,一样的规则并不一定正确。
5. 结构体的对齐和填充
总的来说,一个结构体实例会按照它最宽的标量成员对齐。编译器这样做,把它作为最简单的方式来保证所有成员是自对齐,为了快速访问的目的。
而且,在C语言里,结构体的地址与它第一个成员的地址是相同的——没有前置填充。注意:在C++里,看上去像结构体的类可能不遵守这个规则!(遵不遵守依赖于基类和虚拟内存函数如何实现,而且因编译器而不同。)
(当你不能确定此类事情时,ANSI C提供了一个offsetof()宏,能够用来表示出结构体成员的偏移量。)
考虑这个结构体:
|
1
2
3
4
5
|
struct foo1 { char *p; char c; long x;}; |
假设一台64位的机器,任何struct foo1的实例会按8字节对齐。其中的任何一个的内存分布看上去无疑应该像这样:
|
1
2
3
4
5
6
|
struct foo1 { char *p; /* 8 bytes */ char c; /* 1 byte char pad[7]; /* 7 bytes */ long x; /* 8 bytes */}; |
它的分布就恰好就像这些类型的变量是单独声明的。但是如果我们把c放在第一个,这就不是了。
|
1
2
3
4
5
6
|
struct foo2 { char c; /* 1 byte */ char pad[7]; /* 7 bytes */ char *p; /* 8 bytes */ long x; /* 8 bytes */}; |
如果成员是单独的变量,c可以起始于任何字节边界,并且pad的大小会不同。但因为struct foo2有按其最宽成员进行的指针对齐,那就不可能了。现在c必须于指针对齐,之后7个字节的填充就被锁定了。
现在让我们来说说关于在结构体成员的尾随填充(trailing padding)。要解释这个,我需要介绍一个基本概念,我称之为结构体的跨步地址(stride address)。它是跟随结构体数据后的第一个地址,与结构体拥有同样对齐方式。
结构体尾随填充的通常规则是这样的:编译器的行为就如把结构体尾随填充到它的跨步地址。这条规则决定了sizeof()的返回值。
考虑在64位的x86或ARM上的这个例子:
|
1
2
3
4
5
6
7
|
struct foo3 { char *p; /* 8 bytes */ char c; /* 1 byte */};struct foo3 singleton;struct foo3 quad[4]; |
你可能会认为,sizeof(struct foo3)应该是9,但实际上是16。跨步地址是(&p)[2]的地址。如此,在quad数组中,每个成员有尾随填充的7字节,因为每个跟随的结构体的第一个成员都要自对齐到8字节的边界上。内存分布就如结构体像这样声明:
|
1
2
3
4
5
|
struct foo3 { char *p; /* 8 bytes */ char c; /* 1 byte */ char pad[7];}; |
作为对照,考虑下面的例子:
|
1
2
3
4
|
struct foo4 { short s; /* 2 bytes */ char c; /* 1 byte */}; |
因为s只需对齐到2字节, 跨步地址就只有c后面的一个字节,struct foo4作为一个整体,只需要一个字节的尾随填充。它会像这样分布
|
1
2
3
4
5
|
struct foo4 { short s; /* 2 bytes */ char c; /* 1 byte */ char pad[1];}; |
并且sizeof(struct foo4)会返回4。
现在让我们考虑位域(bitfield)。它们是你能够声明比字符宽度还小的结构体域,小到1位,像这样:
|
1
2
3
4
5
6
7
|
struct foo5 { short s; char c; int flip:1; int nybble:4; int septet:7;}; |
关于位域需要知道的事情是,它们以字或字节级别的掩码和移位指令来实现。从编译器的观点来看,struct foo5的位域看上去像2字节,16位的字符数组里只有12位被使用。接着是填充,使得这个结构体的字节长度成为sizeof(short)的倍数即最长成员的大小。
|
1
2
3
4
5
6
7
8
9
|
struct foo5 { short s; /* 2 bytes */ char c; /* 1 byte */ int flip:1; /* total 1 bit */ int nybble:4; /* total 5 bits */ int septet:7; /* total 12 bits */ int pad1:4; /* total 16 bits = 2 bytes */ char pad2; /* 1 byte */}; |
这里是最后一个重要的细节:如果你的结构体含有结构体的成员,里面的结构体也需要按最长的标量对齐。假设如果你写成这样:
|
1
2
3
4
5
6
7
|
struct foo6 { char c; struct foo5 { char *p; short x; } inner;}; |
内部结构体的char *p成员使得外部的结构体与内部的一样成为指针对齐。在64位机器上,实际的分布是像这样的:
|
1
2
3
4
5
6
7
8
9
|
struct foo6 { char c; /* 1 byte*/ char pad1[7]; /* 7 bytes */ struct foo6_inner { char *p; /* 8 bytes */ short x; /* 2 bytes */ char pad2[6]; /* 6 bytes */ } inner;}; |
这个结构体给了我们一个启示,重新封装结构体可能节省空间。24个字节中,有13个字节是用作填充的。超过50%的无用空间!
6. 结构体重排序(reordering)
现在你知道如何以及为何编译器要插入填充,在你的结构体之中或者之后,我们要考察你可以做些什么来挤掉这些“水坑”。这就是结构体封装的艺术。
第一件需要注意的事情是,“水坑”仅发生于两个地方。一个是大数据类型(有更严格的对齐要求)的存储区域紧跟在一个较小的数据类型的存储区域之后。另一个是结构体自然结束于它的跨步地址之前,需要填充,以使下一个实例可以正确对齐。
消除“水坑”的最简单的方法是按对齐的降序来对结构体成员重排序。就是说:所有指针对齐的子域在前面,因为在64位的机器上,它们会有8字节。接下来是4字节的整型;然后是2字节的短整型;然后是字符域。
因此,举个例子,考虑这个简单的链表结构体:
|
1
2
3
4
5
|
struct foo7 { char c; struct foo7 *p; short x;}; |
显现出隐含的“水坑”,这样:
|
1
2
3
4
5
6
7
|
struct foo7 { char c; /* 1 byte */ char pad1[7]; /* 7 bytes */ struct foo7 *p; /* 8 bytes */ short x; /* 2 bytes */ char pad2[6]; /* 6 bytes */}; |
24个字节。如果我们按大小重新排序,我们得到:
|
1
2
3
4
5
|
struct foo8 { struct foo8 *p; short x; char c;}; |
考虑到自对齐,我们看到没有数据域需要填充。这是因为一个较长的、有较严格对齐的域的跨步地址,对于较短的、较不严格对齐的域来说,总是合法对齐的起始地址。所有重封装的结构体实际上需要的只是尾随填充:
|
1
2
3
4
5
6
|
struct foo8 { struct foo8 *p; /* 8 bytes */ short x; /* 2 bytes */ char c; /* 1 byte */ char pad[5]; /* 5 bytes */}; |
我们重封装的转变把大小降到了16字节。这可能看上去没什么,但是假设你有一个200k的这样的链表呢?节省的空间累积起来就不小了。
注意重排序并不能保证节省空间。把这个技巧运用到早先的例子,struct foo6,我们得到:
|
1
2
3
4
5
6
7
|
struct foo9 { struct foo9_inner { char *p; /* 8 bytes */ int x; /* 4 bytes */ } inner; char c; /* 1 byte*/}; |
把填充写出来,就是这样
|
1
2
3
4
5
6
7
8
9
|
struct foo9 { struct foo9_inner { char *p; /* 8 bytes */ int x; /* 4 bytes */ char pad[4]; /* 4 bytes */ } inner; char c; /* 1 byte*/ char pad[7]; /* 7 bytes */}; |
它仍然是24字节,因为c不能转换到内部结构体成员的尾随填充。为了获得节省空间的好处,你需要重新设计你的数据结构。
自从发布了这篇指南的第一版,我就被问到了,如果通过重排序来得到最少的“水坑”是如此简单,为什么C编译器不自动完成呢?答案是:C语言最初是被设计用来写操作系统和其他接近硬件的语言。自动重排序会妨碍到系统程序员规划结构体,精确匹配字节和内存映射设备控制块的位级分布的能力。
7. 难以处理的标量的情况
使用枚举类型而不是#defines是个好主意,因为符号调试器可以用那些符号并且可以显示它们,而不是未处理的整数。但是,尽管枚举要保证兼容整型类型,C标准没有明确规定哪些潜在的整型类型会被使用。
注意,当重新封装你的结构体时,虽然枚举类型变量通常是整型,但它依赖于编译器;它们可能是短整型、长整型、甚至是默认的字符型。你的编译器可能有一个编译指示或者命令行选项来强制规定大小。
long double类型也是个相似的麻烦点。有的C平台以80位实现,有的是128, 还有的80位的平台填充到96或128位。
在这两种情况下,最好用sizeof()来检查存储大小。
最后,在x86下,Linux的双精度类型有时是一个自对齐规则的特例;一个8字节的双精度数据在一个结构体内可以只要求4字节对齐,虽然单独的双精度变量要求8字节的自对齐。这依赖于编译器及其选项。
8. 可读性和缓存局部性
尽管按大小重排序是消除“水坑”的最简单的方式,但它不是必定正确的。还有两个问题:可读性和缓存局部性。
程序不只是与计算机的交流,还是与其他人的交流。代码可读性是重要的,即便(或者尤其是!)交流的另一方不只是未来的你。
笨拙的、机械的结构体重排序会损害可读性。可能的话,最好重排域,使得语义相关的数据段紧紧相连,能形成连贯的组群。理想情况下,你的结构体设计应该传达到你的程序。
当你的程序经常访问一个结构体,或者结构体的一部分,如果访问常命中缓存行(当被告知去读取任何一个块里单个地址时,你的处理器读取的整一块内存)有助于提高性能。在64位x86机上一条缓存行为64字节,始于一个自对齐的地址;在其他平台上经常是32字节。
你应该做的事情是保持可读性——把相关的和同时访问的数据组合到毗邻的区域——这也会提高缓存行的局部性。这都是用代码的数据访问模式的意识,聪明地重排序的原因。
如果你的代码有多线程并发访问一个结构体,就会有第三个问题:缓存行反弹(cache line bouncing)。为了减少代价高昂的总线通信,你应该组织你的数据,使得在紧凑的循环中,从一条缓存行中读取,而在另一条缓存行中写。
是的,这与之前关于把相关数据组成同样大小的缓存行块的指南有些矛盾。多线程是困难的。缓存行反弹以及其它的多线程优化问题是十分高级的话题,需要整篇关于它们的教程。这里我能做的最好的就就是让你意识到这些问题的存在。
9. 其它封装技术
当重排序与其他技术结合让你的结构体瘦身时效果最好。如果你在一个结构体里有若干布尔型标志,举个例子,可以考虑将它们减小到1位的位域,并且将它们封装到结构体里的一个本会成为“水坑”的地方。
为此,你会碰到些许访问时间上的不利——但是如果它把工作区挤压得足够小,这些不利会被避免缓存不命中的得益所掩盖。
更普遍的,寻找缩小数据域大小的方式。比如在cvs-fast-export里,我用的一项压缩技术里用到了在1982年之前RCS和CVS代码库还不存在的知识。我把64位的Unix time_t(1970年作为起始0日期)减少到32位的、从1982-01-01T00:00:00开始的时间偏移量;这会覆盖2118年前的日期。(注意:如果你要玩这样的花招,每当你要设定字段,你都要做边界检查以防讨厌的错误!)
每一个这样被缩小的域不仅减少了你结构体显在的大小,还会消除“水坑”,且/或创建额外的机会来得到域重排序的好处。这些效果的良性叠加不难得到。
最有风险的封装形式是使用联合体。如果你知道你结构体中特定的域永远不会被用于与其他特定域的组合,考虑使用联合体使得它们共享存储空间。但你要额外小心,并且用回归测试来验证你的工作,因为如果你的生命周期分析即使有轻微差错,你会得到各种程序漏洞,从程序崩溃到(更糟糕的)不易发觉的数据损坏。
10. 工具
C语言编译器有个-Wpadded选项,能使它产生关于对齐空洞和填充的消息。
虽然我自己还没用过,但是一些反馈者称赞了一个叫pahole的程序。这个工具与编译器合作,产生关于你的结构体的报告,记述了填充、对齐及缓存行边界。
11. 证明及例外
你可以下载一个小程序的代码,此代码用来展示了上述标量和结构体大小的论断。就是packtest.c。
如果你浏览足够多的编译器、选项和不常见的硬件的奇怪组合,你会发现针对我讲述的一些规则的特例。如果你回到越旧的处理器设计,就会越常见。
比知道这些规则更进一步,是知道如何以及何时这些规则会被打破。在我学习它们的那些年(1980年代早期),我们把不懂这些的人称为“世界都是VAX综合征”的受害者。记住世界上不只有PC。
12. 版本履历
1.5 @ 2014-01-03
解释了为什么不自动做结构体成员的重排序。
1.4 @ 2014-01-06
关于x86 Linux下双精度的注意。
1.3 @ 2014-01-03
关于难以处理的标量实例、可读性和缓存局部性及工具的段落。
1.2 @ 2014-01-02
修正了一个错误的地址计算。
1.1 @ 2014-01-01
解释为什么对齐的访问会更快。提及offsetof。各种小修复,包括packtest.c的下载链接。
1.0 @ 2014-01-01
初版
Stack的三种含义 - 博客 - 伯乐在线 - Google Chrome (2013/12/1 23:19:50)
Stack的三种含义
学习编程的时候,经常会看到stack这个词,它的中文名字叫做”栈”。
理解这个概念,对于理解程序的运行至关重要。容易混淆的是,这个词其实有三种含义,适用于不同的场合,必须加以区分。
含义一:数据结构
stack的第一种含义是一组数据的存放方式,特点为LIFO,即后进先出(Last in, first out)。

在这种数据结构中,数据像积木那样一层层堆起来,后面加入的数据就放在最上层。使用的时候,最上层的数据第一个被用掉,这就叫做”后进先出”。
与这种结构配套的,是一些特定的方法,主要为下面这些。
- push:在最顶层加入数据。
- pop:返回并移除最顶层的数据。
- top:返回最顶层数据的值,但不移除它。
- isempty:返回一个布尔值,表示当前stack是否为空栈。
含义二:代码运行方式
stack的第二种含义是“调用栈”(call stack),表示函数或子例程像堆积木一样存放,以实现层层调用。
下面以一段Java代码为例(来源)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class Student{ int age; String name; public Student(int Age, String Name) { this.age = Age; setName(Name); } public void setName(String Name) { this.name = Name; }}public class Main{ public static void main(String[] args) { Student s; s = new Student(23,"Jonh"); }} |
上面这段代码运行的时候,首先调用main方法,里面需要生成一个Student的实例,于是又调用Student构造函数。在构造函数中,又调用到setName方法。

这三次调用像积木一样堆起来,就叫做”调用栈”。程序运行的时候,总是先完成最上层的调用,然后将它的值返回到下一层调用,直至完成整个调用栈,返回最后的结果。
含义三:内存区域
stack的第三种含义是存放数据的一种内存区域。程序运行的时候,需要内存空间存放数据。一般来说,系统会划分出两种不同的内存空间:一种叫做stack(栈),另一种叫做heap(堆)。

它们的主要区别是:stack是有结构的,每个区块按照一定次序存放,可以明确知道每个区块的大小;heap是没有结构的,数据可以任意存放。因此,stack的寻址速度要快于heap。

其他的区别还有,一般来说,每个线程分配一个stack,每个进程分配一个heap,也就是说,stack是线程独占的,heap是线程共用的。此外,stack创建的时候,大小是确定的,数据超过这个大小,就发生stack overflow错误,而heap的大小是不确定的,需要的话可以不断增加。
根据上面这些区别,数据存放的规则是:只要是局部的、占用空间确定的数据,一般都存放在stack里面,否则就放在heap里面。请看下面这段代码(来源)。
|
1
2
3
4
5
6
7
8
|
public void Method1(){ int i=4; int y=2; class1 cls1 = new class1();} |
上面代码的Method1方法,共包含了三个变量:i, y 和 cls1。其中,i和y的值是整数,内存占用空间是确定的,而且是局部变量,只用在Method1区块之内,不会用于区块之外。cls1也是局部变量,但是类型为指针变量,指向一个对象的实例。指针变量占用的大小是确定的,但是对象实例以目前的信息无法确知所占用的内存空间大小。
这三个变量和一个对象实例在内存中的存放方式如下。

从上图可以看到,i、y和cls1都存放在stack,因为它们占用内存空间都是确定的,而且本身也属于局部变量。但是,cls1指向的对象实例存放在heap,因为它的大小不确定。作为一条规则可以记住,所有的对象都存放在heap。
接下来的问题是,当Method1方法运行结束,会发生什么事?
回答是整个stack被清空,i、y和cls1这三个变量消失,因为它们是局部变量,区块一旦运行结束,就没必要再存在了。而heap之中的那个对象实例继续存在,直到系统的垃圾清理机制(garbage collector)将这块内存回收。因此,一般来说,内存泄漏都发生在heap,即某些内存空间不再被使用了,却因为种种原因,没有被系统回收。
(完)
C宏定义的简单总结 - BLUESKY - C++博客 - Google Chrome (2013/10/8 14:29:44)
今天在网上突然发现了下面几个关于c代码中的宏定义的说明,回想下,好像在系统的代码中也见过这些零散的定义,但没有注意,看到别人总结了下,发现果然很有用,虽然不知有的道可用与否,但也不失为一种手段,所以就先把它摘抄下来,增加一点见识:
1,防止一个头文件被重复包含
#ifndef BODYDEF_H
#define BODYDEF_H
//头文件内容
#endif
2,得到指定地址上的一个字节或字
#define MEM_B( x ) ( *( (byte *) (x) ) )
#define MEM_W( x ) ( *( (word *) (x) ) )
3,得到一个field在结构体(struct)中的偏移量
#define FPOS( type, field ) ( (dword) &(( type *) 0)-> field )
4,得到一个结构体中field所占用的字节数
#define FSIZ( type, field ) sizeof( ((type *) 0)->field )
5,得到一个变量的地址(word宽度)
#define B_PTR( var ) ( (byte *) (void *) &(var) )
#define W_PTR( var ) ( (word *) (void *) &(var) )
6,将一个字母转换为大写
#define UPCASE( c ) ( ((c) >= ''a'' && (c) <= ''z'') ? ((c) - 0x20) : (c) )
7,判断字符是不是10进值的数字
#define DECCHK( c ) ((c) >= ''0'' && (c) <= ''9'')
8,判断字符是不是16进值的数字
#define HEXCHK( c ) ( ((c) >= ''0'' && (c) <= ''9'') ||((c) >= ''A'' && (c) <= ''F'') ||((c) >= ''a'' && (c) <= ''f'') )
9,防止溢出的一个方法
#define INC_SAT( val ) (val = ((val)+1 > (val)) ? (val)+1 : (val))
10,返回数组元素的个数
#define ARR_SIZE( a ) ( sizeof( (a) ) / sizeof( (a[0]) ) )
11,使用一些宏跟踪调试
ANSI标准说明了五个预定义的宏名。它们是:
_LINE_ (两个下划线),对应%d
_FILE_ 对应%s
_DATE_ 对应%s
_TIME_ 对应%s
_STDC_
宏中"#"和"##"的用法
我们使用#把宏参数变为一个字符串,用##把两个宏参数贴合在一起.
#define STR(s) #s
#define CONS(a,b) int(a##e##b)
Printf(STR(vck)); // 输出字符串"vck"
printf("%d\n", CONS(2,3)); // 2e3 输出:2000
当宏参数是另一个宏的时候
需要注意的是凡宏定义里有用"#"或"##"的地方宏参数是不会再展开.
#define A (2)
#define STR(s) #s
#define CONS(a,b) int(a##e##b)
printf("%s\n", CONS(A, A)); // compile error
这一行则是:
printf("%s\n", int(AeA));
INT_MAX和A都不会再被展开, 然而解决这个问题的方法很简单. 加多一层中间转换宏.
加这层宏的用意是把所有宏的参数在这层里全部展开, 那么在转换宏里的那一个宏(_STR)就能得到正确的宏参数
#define STR(s) _STR(s) // 转换宏
#define CONS(a,b) _CONS(a,b) // 转换宏
printf("int max: %s\n", STR(INT_MAX)); // INT_MAX,int型的最大值,为一个变量 #include<climits>
输出为: int max: 0x7fffffff
STR(INT_MAX) --> _STR(0x7fffffff) 然后再转换成字符串;
printf("%d\n", CONS(A, A));
输出为:200
CONS(A, A) --> _CONS((2), (2)) --> int((2)e(2))
"#"和"##"的一些应用特例
1、合并匿名变量名
#define ___ANONYMOUS1(type, var, line) type var##line
#define __ANONYMOUS0(type, line) ___ANONYMOUS1(type, _anonymous, line)
#define ANONYMOUS(type) __ANONYMOUS0(type, __LINE__)
例:ANONYMOUS(static int); 即: static int _anonymous70; 70表示该行行号;
第一层:ANONYMOUS(static int); --> __ANONYMOUS0(static int, __LINE__);
第二层: --> ___ANONYMOUS1(static int, _anonymous, 70);
第三层: --> static int _anonymous70;
即每次只能解开当前层的宏,所以__LINE__在第二层才能被解开;
2、填充结构
#define FILL(a) {a, #a}
enum IDD{OPEN, CLOSE};
typedef struct MSG{
IDD id;
const char * msg;
}MSG;
MSG _msg[] = {FILL(OPEN), FILL(CLOSE)};
相当于:
MSG _msg[] = {{OPEN, "OPEN"},
{CLOSE, "CLOSE"}};
3、记录文件名
#define _GET_FILE_NAME(f) #f
#define GET_FILE_NAME(f) _GET_FILE_NAME(f)
static char FILE_NAME[] = GET_FILE_NAME(__FILE__);
4、得到一个数值类型所对应的字符串缓冲大小
#define _TYPE_BUF_SIZE(type) sizeof #type
#define TYPE_BUF_SIZE(type) _TYPE_BUF_SIZE(type)
char buf[TYPE_BUF_SIZE(INT_MAX)];
--> char buf[_TYPE_BUF_SIZE(0x7fffffff)];
--> char buf[sizeof "0x7fffffff"];
这里相当于:
char buf[11];
结构体对齐的问题_人生若只如初见_百度空间 - Google Chrome (2013/9/25 12:36:20)
结构体对齐的问题
C语言结构体对齐也是老生常谈的话题了。基本上是面试题的必考题。内容虽然很基础,但一不小心就会弄错。写出一个struct,然后sizeof,你会不会经常对结果感到奇怪?sizeof的结果往往都比你声明的变量总长度要大,这是怎么回事呢?
开始学的时候,也被此类问题困扰很久。其实相关的文章很多,感觉说清楚的不多。结构体到底怎样对齐?
有人给对齐原则做过总结,具体在哪里看到现在已记不起来,这里引用一下前人的经验(在没有#pragma pack宏的情况下):
原则1、数据成员对齐规则:结构(struct或联合union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储)。
原则2、结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储。)
原则3、收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。
这三个原则具体怎样理解呢?我们看下面几个例子,通过实例来加深理解。
例1:struct {
short a1;
short a2;
short a3;
}A;
struct {
long a1;
short a2;
}B;
sizeof(A) = 6; 这个很好理解,三个short都为2。
sizeof(B) = 8; 这个比是不是比预想的大2个字节?long为4,short为2,整个为8,因为原则3。
例2:struct A {
int a;
char b;
short c;
};
struct B {
char b;
int a;
short c;
};
sizeof(A) = 8; int为4,char为1,short为2,这里用到了原则1和原则3。
sizeof(B) = 12; 是否超出预想范围?char为1,int为4,short为2,怎么会是12?还是原则1和原则3。
深究一下,为什么是这样,我们可以看看内存里的布局情况。
a b c
A的内存布局:1111, 1*, 11
b a c
B的内存布局:1***, 1111, 11**
其中星号*表示填充的字节。A中,b后面为何要补充一个字节?因为c为short,其起始位置要为2的倍数,就是原则1。c的后面没有补充,因为b和c正好占用4个字节,整个A占用空间为4的倍数,也就是最大成员int类型的倍数,所以不用补充。
B中,b是char为1,b后面补充了3个字节,因为a是int为4,根据原则1,起始位置要为4的倍数,所以b后面要补充3个字节。c后面补充两个字节,根据原则3,整个B占用空间要为4的倍数,c后面不补充,整个B的空间为10,不符,所以要补充2个字节。
再看一个结构中含有结构成员的例子:
例3:struct A {
int a;
double b;
float c;
};
struct B {
char e[2];
int f;
double g;
short h;
struct A i;
};
sizeof(A) = 24; 这个比较好理解,int为4,double为8,float为4,总长为8的倍数,补齐,所以整个A为24。
sizeof(B) = 48; 看看B的内存布局。
e f g h i
B的内存布局:11* *, 1111, 11111111, 11 * * * * * *, 1111* * * *, 11111111, 1111 * * * *
i其实就是A的内存布局。i的起始位置要为24的倍数,所以h后面要补齐。把B的内存布局弄清楚,有关结构体的对齐方式基本就算掌握了。
以上讲的都是没有#pragma pack宏的情况,如果有#pragma pack宏,对齐方式按照宏的定义来。比如上面的结构体前加#pragma pack(1),内存的布局就会完全改变。sizeof(A) = 16; sizeof(B) = 32;
有了#pragma pack(1),内存不会再遵循原则1和原则3了,按1字节对齐。没错,这不是理想中的没有内存对齐的世界吗。
a b c
A的内存布局:1111, 11111111, 1111
e f g h i
B的内存布局:11, 1111, 11111111, 11 , 1111, 11111111, 1111
那#pragma pack(2)的结果又是多少呢?#pragma pack(4)呢?留给大家自己思考吧,相信没有问题。
这里,#pragma pack (value)宏指令,value就是指定的对齐值。
还有一种常见的情况,结构体中含位域字段。位域成员不能单独被取sizeof值。C99规定int、unsigned int和bool可以作为位域类型,但编译器几乎都对此作了扩展,允许其它类型的存在。
使用位域的主要目的是压缩存储,其大致规则为:
1) 如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止;
2) 如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
3) 如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式,Dev-C++采取压缩方式;
4) 如果位域字段之间穿插着非位域字段,则不进行压缩;
5) 整个结构体的总大小为最宽基本类型成员大小的整数倍。
还是让我们来看看例子。
例4:struct A{
char f1 : 3;
char f2 : 4;
char f3 : 5;
};
a b c
A的内存布局:111, 1111 *, 11111 * * *
位域类型为char,第1个字节仅能容纳下f1和f2,所以f2被压缩到第1个字节中,而f3只能从下一个字节开始。因此sizeof(A)的结果为2。
例5:struct B{
char f1 : 3;
short f2 : 4;
char f3 : 5;
};
由于相邻位域类型不同,在VC6中其sizeof为6,在Dev-C++中为2。
例6:struct C{
char f1 : 3;
char f2;
char f3 : 5;
};
非位域字段穿插在其中,不会产生压缩,在VC6和Dev-C++中得到的大小均为3。
考虑一个问题,为什么要设计内存对齐的处理方式呢?如果体系结构是不对齐的,成员将会一个挨一个存储,显然对齐更浪费了空间。那么为什么要使用对齐呢?体系结构的对齐和不对齐,是在时间和空间上的一个权衡。对齐节省了时间。假设一个体系结构的字长为w,那么它同时就假设了在这种体系结构上对宽度为w的数据的处理最频繁也是最重要的。它的设计也是从优先提高对w位数据操作的效率来考虑的。有兴趣的可以google一下,人家就可以跟你解释的,一大堆的道理。
最后顺便提一点,在设计结构体的时候,一般会遵照一个习惯,就是把占用空间小的类型排在前面,占用空间大的类型排在后面,这样可以相对节约一些对齐空间。
很酷的C语言技巧 - 博客 - 伯乐在线 - Google Chrome (2013/8/18 11:27:40)
很酷的C语言技巧
C语言常常让人觉得它所能表达的东西非常有限。它不具有类似第一级函数和模式匹配这样的高级功能。但是C非常简单,并且仍然有一些非常有用的语法技巧和功能,只是没有多少人知道罢了。
指定的初始化
很多人都知道像这样来静态地初始化数组:
|
1
|
int fibs[] = {1, 1, 2, 3, |
C99标准实际上支持一种更为直观简单的方式来初始化各种不同的集合类数据(如:结构体,联合体和数组)。
数组
我们可以指定数组的元素来进行初始化。这非常有用,特别是当我们需要根据一组#define来保持某种映射关系的同步更新时。来看看一组错误码的定义,如:
|
1
2
3
4
5
6
7
8
9
10
|
/* Entries may not#define EINVAL 1#define ENOMEM 2#define EFAULT 3/* ... */#define E2BIG #define EBUSY /* ... */#define ECHILD 12/* ... |
现在,假设我们想为每个错误码提供一个错误描述的字符串。为了确保数组保持了最新的定义,无论头文件做了任何修改或增补,我们都可以用这个数组指定的语法。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
char *err_strings[] = { [0] = "Success", [EINVAL] = "Invalid argument", [ENOMEM] = "Not enough memory", [EFAULT] = "Bad address", /* ... */ [E2BIG ] = "Argument list too long", [EBUSY ] = "Device or resource busy", /* ... */ [ECHILD] = "No child processes" /* ... */}; |
这样就可以静态分配足够的空间,且保证最大的索引是合法的,同时将特殊的索引初始化为指定的值,并将剩下的索引初始化为0。
结构体与联合体
|
1
|
用结构体与联合体的字段名称来初始化数据是非常有用的。假设我们定义: |
|
1
2
3
4
5
|
struct point { int x; int y; int z;} |
|
1
|
然后我们这样初始化struct point: |
|
1
|
struct point p = {.x = 3, .y = 4, .z = |
当我们不想将所有字段都初始化为0时,这种作法可以很容易的在编译时就生成结构体,而不需要专门调用一个初始化函数。
对联合体来说,我们可以使用相同的办法,只是我们只用初始化一个字段。
宏列表
C中的一个惯用方法,是说有一个已命名的实体列表,需要为它们中的每一个建立函数,将它们中的每一个初始化,并在不同的代码模块中扩展它们的名字。这在Mozilla的源码中经常用到,我就是在那时学到这个技巧的。例如,在我去年夏天工作的那个项目中,我们有一个针对每个命令进行标记的宏列表。其工作方式如下:
|
1
2
3
4
5
6
7
8
|
#define _(InWorklist) _(EmittedAtUses) _(LoopInvariant) _(Commutative) _(Movable) _(Lowered) _(Guard) |
它定义了一个FLAG_LIST宏,这个宏有一个参数称之为 _
,这个参数本身是一个宏,它能够调用列表中的每个参数。举一个实际使用的例子可能更能直观地说明问题。假设我们定义了一个宏DEFINE_FLAG,如:
|
1
2
3
4
5
6
7
|
#define DEFINE_FLAG(flag) enum Flag { None = 0, FLAG_LIST(DEFINE_FLAG) Total };#undef |
对FLAG_LIST(DEFINE_FLAG)做扩展能够得到如下代码:
|
1
2
3
4
5
6
7
8
9
10
11
|
enum Flag { None = 0, DEFINE_FLAG(InWorklist) DEFINE_FLAG(EmittedAtUses) DEFINE_FLAG(LoopInvariant) DEFINE_FLAG(Commutative) DEFINE_FLAG(Movable) DEFINE_FLAG(Lowered) DEFINE_FLAG(Guard) Total }; |
接着,对每个参数都扩展DEFINE_FLAG宏,这样我们就得到了enum如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
enum Flag { None = 0, InWorklist, EmittedAtUses, LoopInvariant, Commutative, Movable, Lowered, Guard, Total }; |
接着,我们可能要定义一些访问函数,这样才能更好的使用flag列表:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#define FLAG_ACCESSOR(flag)bool is##flag() const {\ return hasFlags(1 <<}\void set##flag() {\ JS_ASSERT(!hasFlags(1 << setFlags(1 <<}\void setNot##flag() {\ JS_ASSERT(hasFlags(1 << removeFlags(1 <<}FLAG_LIST(FLAG_ACCESSOR)#undef |
一步步的展示其过程是非常有启发性的,如果对它的使用还有不解,可以花一些时间在gcc
–E上。
编译时断言
这其实是使用C语言的宏来实现的非常有“创意”的一个功能。有些时候,特别是在进行内核编程时,在编译时就能够进行条件检查的断言,而不是在运行时进行,这非常有用。不幸的是,C99标准还不支持任何编译时的断言。
但是,我们可以利用预处理来生成代码,这些代码只有在某些条件成立时才会通过编译(最好是那种不做实际功能的命令)。有各种各样不同的方式都可以做到这一点,通常都是建立一个大小为负的数组或结构体。最常用的方式如下:
|
1
2
3
4
5
6
7
8
9
|
/* Force a compilation * (of value 0 and type * initializer (or wherever/* Linux calls these#define#define/* Force a compilation#define |
如果(condition)计算结果为一个非零值(即C中的真值),即!
(condition)为零值,那么代码将能顺利地编译,并生成一个大小为零的结构体。如果(condition)结果为0(在C真为假),那么在试图生成一个负大小的结构体时,就会产生编译错误。
它的使用非常简单,如果任何某假设条件能够静态地检查,那么它就可以在编译时断言。例如,在上面提到的标志列表中,标志集合的类型为uint32_t,所以,我们可以做以下断言:
|
1
|
STATIC_ASSERT(Total <= |
它扩展为:
|
1
|
(void)sizeof(struct { int:-!(Total <= 32) |
现在,假设Total<=32。那么-!(Total
<= 32)等于0,所以这行代码相当于:
|
1
|
(void)sizeof(struct { int: 0 |
这是一个合法的C代码。现在假设标志不止32个,那么-!(Total
<= 32)等于-1,所以这时代码就相当于:
|
1
|
(void)sizeof(struct { int: -1 } |
因为位宽为负,所以可以确定,如果标志的数量超过了我们指派的空间,那么编译将会失败。
忽略大小写的字符串查找 (2013/6/3 9:32:55)
&& (*pt1 != 0))
转成小写进行比较
if((*pt1>='A') && (*pt1<='Z') && (*pt2>='a') &&
(*pt2<='z'))
if((*pt1+32) != (*pt2)){ break; }
if((*pt1>='a') && (*pt1<='z') && (*pt2>='A') &&
(*pt2<='Z'))
if((*pt1-32) != (*pt2)){ break; }
if(*pt1 != *pt2){ break; } }
cmp_len++;
pt1++;
pt2++;
return(pString_pt); }
匹配长度不够了
堆和栈在内存中的区别_.Net编程 - 好工具站长分享平台 - Google Chrome (2013/3/26 17:51:45)
堆和栈在内存中的区别
作者:孤独的猫 | 出处:博客园 | 阅读67次 2011/5/11 15:23:52
堆和栈在内存中的区别
2009年06月29日 星期一 20:47
【转载】:原文 http://blog.csdn.net/nileel/archive/2009/06/29/4307284.aspx
1、内存分配方面:
堆:一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式是类似于链表。可能用到的关键字如下:new、malloc、delete、free等等。
栈:由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、申请方式方面:
堆:需要程序员自己申请,并指明大小。在c中malloc函数如p1 = (char *)malloc(10);在C++中用new运算符,但是注意p1、p2本身是在栈中的。因为他们还是可以认为是局部变量。
栈:由系统自动分配。 例如,声明在函数中一个局部变量 int b;系统自动在栈中为b开辟空间。
3、系统响应方面:
堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表 中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete语句才能正确的 释放本内存空间。另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
4、大小限制方面:
堆:是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
栈:在Windows下, 栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是固定 的(是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
5、效率方面:
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便,另外,在WINDOWS下,最好的方式是用 VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
6、存放内容方面:
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
栈:在函数调用时第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址然后是函数的各个参数,在大多数的C编译器中,参数是由 右往左入栈,然后是函数中的局部变量。 注意: 静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续 运行。
7、存取效率方面:
堆:char *s1 = "Hellow Word";是在编译时就确定的;
栈:char s1[] = "Hellow Word"; 是在运行时赋值的;用数组比用指针速度要快一些,因为指针在底层汇编中需要用edx寄存器中转一下,而数组在栈上直接读取。
=========转载第二篇文章=================
堆和栈的区别
一、预备知识?程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)? 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) ? 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)?,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区?常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区?存放函数体的二进制代码。
二、例子程序
这是一个前辈写的,非常详细
//main.cpp
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = "abc"; 栈
char *p2; 栈
char *p3 = "123456"; 123456在常量区,p3在栈上。
static int c =0; 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); 123456放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
二、堆和栈的理论知识
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2
申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会
遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内
存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大
小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据
结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之
是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#include
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
|
【转载】:原文 http://blog.csdn.net/nileel/archive/2009/06/29/4307284.aspx 1、内存分配方面: 堆:一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式是类似于链表。可能用到的关键字如下:new、malloc、delete、free等等。 栈:由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。 2、申请方式方面: 堆:需要程序员自己申请,并指明大小。在c中malloc函数如p1 = (char *)malloc(10);在C++中用new运算符,但是注意p1、p2本身是在栈中的。因为他们还是可以认为是局部变量。 栈:由系统自动分配。 例如,声明在函数中一个局部变量 int b;系统自动在栈中为b开辟空间。 3、系统响应方面: 堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表 中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete语句才能正确的 释放本内存空间。另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。 栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。 4、大小限制方面: 堆:是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。 栈:在Windows下, 栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是固定 的(是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。 5、效率方面: 堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便,另外,在WINDOWS下,最好的方式是用 VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。 6、存放内容方面: 堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。 栈:在函数调用时第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址然后是函数的各个参数,在大多数的C编译器中,参数是由 右往左入栈,然后是函数中的局部变量。 注意: 静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续 运行。 7、存取效率方面: 堆:char *s1 = "Hellow Word";是在编译时就确定的; 栈:char s1[] = "Hellow Word"; 是在运行时赋值的;用数组比用指针速度要快一些,因为指针在底层汇编中需要用edx寄存器中转一下,而数组在栈上直接读取。 =========转载第二篇文章================= |
sizeof()用法汇总 (2013/3/11 16:03:56)
strlen()计算字符数组的字符数,以"\0"为结束判断,不计算为'\0'的数组元素。
而sizeof计算数据(包括数组、变量、类型、结构体等)所占内存空间,用字节数表示。
但sizeof(*p)相当于sizeof(int);
sizeof(a)等于4*10=40;
sizeof(b)等于6;
void fun(char p[])
{sizeof(p)等于4}
a为指针
*a为一个有3*6个指针元素的数组
**a为数组一维的6个指针
***a为一维的第一个指针
****a为一个double变量
既然a是执行double*[3][6]类型的指针,*a就表示一个double*[3][6]的多维数组类型,因此sizeof(*a)=3*6*sizeof(double*)=72。同样的,**a表示一个double*[6]类型的数组,所以sizeof(**a)=6*sizeof
(double*)=24。***a就表示其中的一个元素,也就是double*了,所以sizeof(***a)=4。至于****a,就是一个double了,所以sizeof(****a)=sizeof(double)=8。
(2)数据对齐原则----内存按结构成员的先后顺序排列,当排到该成员变量时,其前面已摆放的空间大小必须是该成员类型大小的整倍数,如果不够则补齐,以此向后类推。。。。。
同样是两个char类型,一个int类型,一个double类型,但是因为对齐问题,导致他们的大小不同。计算结构体大小可以采用元素摆放法,我举例子说明一下:首先,CPU判断结构体的对界,根据上一节的结论,s1和s2的对界都取最大的元素类型,也就是double类型的对界8。然后开始摆放每个元素。
对于s1,首先把a放到8的对界,假定是0,此时下一个空闲的地址是1,但是下一个元素d是double类型,要放到8的对界上,离1最接近的地址是8了,所以d被放在了8,此时下一个空闲地址变成了16,下一个元素c的对界是4,16可以满足,所以c放在了16,此时下一个空闲地址变成了20,下一个元素d需要对界1,也正好落在对界上,所以d放在了20,结构体在地址21处结束。由于s1的大小需要是8的倍数,所以21-23的空间被保留,s1的大小变成了24。
对于s2,首先把a放到8的对界,假定是0,此时下一个空闲地址是1,下一个元素的对界也是1,所以b摆放在1,下一个空闲地址变成了2;下一个元素c的对界是4,所以取离2最近的地址4摆放c,下一个空闲地址变成了8,下一个元素d的对界是8,所以d摆放在8,所有元素摆放完毕,结构体在15处结束,占用总空间为16,正好是8的倍数。
sscanf()和sprintf()的用法总结 (2013/3/11 15:56:37)
sscanf函数的高级用法
sscanf与scanf类似,都是用于输入的,只是后者以屏幕(stdin)为输入源,前者以固定字符串为输入源。
函数原型:
int sscanf( const char *format [,argument]... );
其中的format可以是一个或多个:{%[*][width][{h|l|I64|L}]type|' '|'\t'|'\n'|非%符号},
注:
1)、 * 亦可用于格式中, (即 %*d 和 %*s) 加了星号 (*) 表示跳过此数据不读入。
(也就是不把此数据读入参数中)
2)、{a|b|c}表示a,b,c中选一,[d],表示可以有d也可以没有d。
3)、width:宽度,一般可以忽略,用法如:
const char sourceStr[] = "hello, world";
char buf[10] = {0};
sscanf(sourceStr, "%5s", buf); //%5s,只取5个字符
cout << buf<< endl;
结果为:hello
4)、{h|I|I64|L}:参数的size,通常h表示单字节size,I表示2字节 size,
L表示4字节size(double例外),l64表示8字节size。
5)、type :这就很多了,就是%s,%d之类。
6)、特别的:%*[width] [{h|l|I64|L}]type 表示满足该条件的被过滤掉,
不会向目标参数中写入值。如:
const char sourceStr[] = "hello, world";
char buf[10] = {0};
sscanf(sourceStr, "%*s%s", buf);
//%*s表示第一个匹配到的%s被过滤掉,即hello被过滤了
cout << buf<< endl;
结果为:world
7)、支持集合操作:
%[a-z] 表示匹配a到z中任意字符,贪婪性(尽可能多的匹配)
%[aB'] 匹配a、B、'中一员,贪婪性
%[^a] 匹配非a的任意字符,贪婪性
和正则表达式很相似,而且仍然支持过滤,即可以有%*[a-z]。
例子:
1、 常见用法。
char buf[512] = {0};
sscanf("123456 ", "%s", buf);
printf("%s\n", buf);
结果为:123456
2、 取指定长度的字符串。如在下例中,取最大长度为4字节的字符串。
sscanf("123456 ", "%4s", buf);
printf("%s\n", buf);
结果为:1234
3、 取到指定字符为止的字符串。如在下例中,取遇到空格为止字符串。
sscanf("123456 abcdedf", "%[^ ]", buf);
printf("%s\n", buf);
结果为:123456
4、 取仅包含指定字符集的字符串。如在下例中,取仅包含1到9和小写字母的字符串。
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", buf);
printf("%s\n", buf);
结果为:123456abcdedf
5、 取到指定字符集为止的字符串。如在下例中,取遇到大写字母为止的字符串。
sscanf("123456abcdedfBCDEF", "%[^A-Z]", buf);
printf("%s\n", buf);
结果为:123456abcdedf
6、给定一个字符串iios/12DDWDFF@122,获取 / 和 @ 之间的字符串,
先将 "iios/"过滤掉,再将非'@'的一串内容送到buf中
sscanf("iios/12DDWDFF@122", "%*[^/]/%[^@]", buf);
printf("%s\n", buf);
结果为:12DDWDFF
7、给定一个字符串““hello, world”,仅保留world。(注意:“,”之后有一空格)
sscanf(“hello, world”, "%*s%s", buf);
printf("%s\n", buf);
结果为:world
%*s表示第一个匹配到的%s被过滤掉,即hello被过滤了,如果没有空格则结果为 NULL。
8、分隔字符串2006:03:18
int a, b, c;
sscanf("2006:03:18", "%d:%d:%d", a, b, c);
9、分隔字符串2006:03:18 - 2006:04:18
char sztime1[16] = "", sztime2[16] = "";
sscanf("2006:03:18 - 2006:04:18", "%s - %s", sztime1, sztime2);
10、分隔字符串2006:03:18-2006:04:18
char sztime1[16] = "", sztime2[16] = "";
sscanf("2006:03:18-2006:04:18", "%[0-9,:] - %[0-9,:]", sztime1, sztime2);
仅仅是取消了‘-’两边的空格,却打破了%s对字符串的界定format-type中有%[]这样的type field。如果读取的字符串,不是以空格来分隔的话,就可以使用%[]。%[]类似于一个正则表达式。[a-z]表示读取a-z的所有字符,[^a-z]表示读取除a-z以外的所有字符。
sscanf的功能很类似于正则表达式, 但却没有正则表达式强大,所以如果对于比较复杂的字符串处理,建议使用正则表达式.
sprintf
sprintf 将字串格式化。
在头文件 #include<stdio.h>中
语法: string sprintf(string format, mixed [args]...);
传回值: 字串
1. 处理字符方向。-负号时表时从后向前处理。
2. 填空字元。 0 的话表示空格填 0;空格是内定值,表示空格就放着。
3. 字符总宽度。为最小宽度。
4. 精确度。指在小数点后的浮点数位数。
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
转换字符
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
% 印出百分比符号,不转换。
b 整数转成二进位。
c 整数转成对应的 ASCII 字元。
d 整数转成十进位。
f 倍精确度数字转成浮点数。
o 整数转成八进位。
s 整数转成字串。
x 整数转成小写十六进位。
X 整数转成大写十六进位。
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
<?
$money = 123.1
$formatted = sprintf ("%06.2f", $money); // 此时变数 $ formatted 值为 "123.10"
$formatted = sprintf ("%08.2f", $money); // 此时变数 $ formatted 值为 "00123.10"
$formatted = sprintf ("%-08.2f", $money); // 此时变数 $ formatted 值为 "123.1000"
$formatted = sprintf ("%.2f%%", 0.95 * 100); // 格式化为百分比
?>
¢%08.2f 解释:
%开始符
0是 "填空字元" 表示,如果长度不足时就用0来填满。
6格式化后总长度
2f小数位长度,即2位
¢第4行值为"00123.10" 解释:
因为2f是(2位)+小数点符号(1)+前面123(3位)=6位,总长度为8位,故前面用[填空字元]0表示,即00123.10
¢第4行值为"-123.1000" 解释:
-号为反向操作,然后填空字元0添加在最后面了
/********************************************************
以下选自《CSDN 社区电子杂志——C/C++杂志》
*********************************************************/
在将各种类型的数据构造成字符串时,sprintf 的强大功能很少会让你失望。由于sprintf 跟printf 在用法上几乎一样,只是打印的目的地不同而已,前者打印到字符串中,后者则直接在命令行上输出。这也导致sprintf 比printf 有用得多。
sprintf 是个变参函数,定义如下:
int sprintf( char *buffer, const char *format [, argument] ... );
除了前两个参数类型固定外,后面可以接任意多个参数。而它的精华,显然就在第二个参数:格式化字符串上。
printf 和sprintf 都使用格式化字符串来指定串的格式,在格式串内部使用一些以“%”开头的格式说明符(format specifications)来占据一个位置,在后边的变参列表中提供相应的变量,最终函数就会用相应位置的变量来替代那个说明符,产生一个调用者想要的字符串。
格式化数字字符串
sprintf 最常见的应用之一莫过于把整数打印到字符串中,所以,spritnf 在大多数场合可以替代itoa。
如:
//把整数123 打印成一个字符串保存在s 中。
sprintf(s, "%d", 123); //产生"123"
可以指定宽度,不足的左边补空格:
sprintf(s, "%8d%8d", 123, 4567); //产生:" 123 4567"
当然也可以左对齐:
sprintf(s, "%-8d%8d", 123, 4567); //产生:"123 4567"
也可以按照16 进制打印:
sprintf(s, "%8x", 4567); //小写16 进制,宽度占8 个位置,右对齐
sprintf(s, "%-8X", 4568); //大写16 进制,宽度占8 个位置,左对齐
这样,一个整数的16 进制字符串就很容易得到,但我们在打印16 进制内容时,通常想要一种左边补0 的等宽格式,那该怎么做呢?很简单,在表示宽度的数字前面加个0 就可以了。
sprintf(s, "%08X", 4567); //产生:"000011D7"
上面以”%d”进行的10 进制打印同样也可以使用这种左边补0 的方式。
这里要注意一个符号扩展的问题:比如,假如我们想打印短整数(short)-1 的内存16 进制表示形式,在Win32 平台上,一个short 型占2 个字节,所以我们自然希望用4 个16 进制数字来打印它:
short si = -1;
sprintf(s, "%04X", si);
产生“FFFFFFFF”,怎么回事?因为spritnf 是个变参函数,除了前面两个参数之外,后面的参数都不是类型安全的,函数更没有办法仅仅通过一个“%X”就能得知当初函数调用前参数压栈时被压进来的到底是个4 字节的整数还是个2 字节的短整数,所以采取了统一4 字节的处理方式,导致参数压栈时做了符号扩展,扩展成了32 位的整数-1,打印时4 个位置不够了,就把32 位整数-1 的8 位16 进制都打印出来了。
如果你想看si 的本来面目,那么就应该让编译器做0 扩展而不是符号扩展(扩展时二进制左边补0 而不是补符号位):
sprintf(s, "%04X", (unsigned short)si);
就可以了。或者:
unsigned short si = -1;
sprintf(s, "%04X", si);
sprintf 和printf 还可以按8 进制打印整数字符串,使用”%o”。注意8 进制和16 进制都不会打印出负数,都是无符号的,实际上也就是变量的内部编码的直接的16 进制或8 进制表示。
控制浮点数打印格式
浮点数的打印和格式控制是sprintf 的又一大常用功能,浮点数使用格式符”%f”控制,默认保留小数点后6 位数字,比如:
sprintf(s, "%f", 3.1415926); //产生"3.141593"
但有时我们希望自己控制打印的宽度和小数位数,这时就应该使用:”%m.nf”格式,其中m 表示打印的宽度,n 表示小数点后的位数。比如:
sprintf(s, "%10.3f", 3.1415626); //产生:" 3.142"
sprintf(s, "%-10.3f", 3.1415626); //产生:"3.142 "
sprintf(s, "%.3f", 3.1415626); //不指定总宽度,产生:"3.142"
注意一个问题,你猜
int i = 100;
sprintf(s, "%.2f", i);
会打出什么东东来?“100.00”?对吗?自己试试就知道了,同时也试试下面这个:
sprintf(s, "%.2f", (double)i);
第一个打出来的肯定不是正确结果,原因跟前面提到的一样,参数压栈时调用者并不知道跟i相对应的格式控制符是个”%f”。而函数执行时函数本身则并不知道当年被压入栈里的是个整数,于是可怜的保存整数i 的那4 个字节就被不由分说地强行作为浮点数格式来解释了,整个乱套了。不过,如果有人有兴趣使用手工编码一个浮点数,那么倒可以使用这种方法来检验一下你手工编排的结果是否正确。
字符/Ascii 码对照
我们知道,在C/C++语言中,char 也是一种普通的scalable 类型,除了字长之外,它与short,int,long 这些类型没有本质区别,只不过被大家习惯用来表示字符和字符串而已。(或许当年该把这个类型叫做“byte”,然后现在就可以根据实际情况,使用byte 或short 来把char 通过typedef 定义出来,这样更合适些)于是,使用”%d”或者”%x”打印一个字符,便能得出它的10 进制或16 进制的ASCII 码;反过来,使用”%c”打印一个整数,便可以看到它所对应的ASCII 字符。以下程序段把所有可见字符的ASCII 码对照表打印到屏幕上(这里采用printf,注意”#”与”%X”合用时自动为16 进制数增加”0X”前缀):
for(int i = 32; i < 127; i++) {
printf("[ %c ]: %3d 0x%#04X\n", i, i, i);
}
连接字符串
sprintf 的格式控制串中既然可以插入各种东西,并最终把它们“连成一串”,自然也就能够连接字符串,从而在许多场合可以替代strcat,但sprintf 能够一次连接多个字符串(自然也可以同时在它们中间插入别的内容,总之非常灵活)。比如:
char* who = "I";
char* whom = "CSDN";
sprintf(s, "%s love %s.", who, whom); //产生:"I love CSDN. "
strcat 只能连接字符串(一段以’’结尾的字符数组或叫做字符缓冲,null-terminated-string),但有时我们有两段字符缓冲区,他们并不是以 ’’结尾。比如许多从第三方库函数中返回的字符数组,从硬件或者网络传输中读进来的字符流,它们未必每一段字符序列后面都有个相应的’’来结尾。如果直接连接,不管是sprintf 还是strcat 肯定会导致非法内存操作,而strncat 也至少要求第一个参数是个null-terminated-string,那该怎么办呢?我们自然会想起前面介绍打印整数和浮点数时可以指定宽度,字符串也一样的。比如:
char a1[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
char a2[] = {'H', 'I', 'J', 'K', 'L', 'M', 'N'};
如果:
sprintf(s, "%s%s", a1, a2); //Don't do that!
十有八九要出问题了。是否可以改成:
sprintf(s, "%7s%7s", a1, a2);
也没好到哪儿去,正确的应该是:
sprintf(s, "%.7s%.7s", a1, a2);//产生:"ABCDEFGHIJKLMN"
这可以类比打印浮点数的”%m.nf”,在”%m.ns”中,m 表示占用宽度(字符串长度不足时补空格,超出了则按照实际宽度打印),n 才表示从相应的字符串中最多取用的字符数。通常在打印字符串时m 没什么大用,还是点号后面的n 用的多。自然,也可以前后都只取部分字符:
sprintf(s, "%.6s%.5s", a1, a2);//产生:"ABCDEFHIJKL"
在许多时候,我们或许还希望这些格式控制符中用以指定长度信息的数字是动态的,而不是静态指定的,因为许多时候,程序要到运行时才会清楚到底需要取字符数组中的几个字符,这种动态的宽度/精度设置功能在sprintf 的实现中也被考虑到了,sprintf 采用”*”来占用一个本来需要一个指定宽度或精度的常数数字的位置,同样,而实际的宽度或精度就可以和其它被打印的变量一样被提供出来,于是,上面的例子可以变成:
sprintf(s, "%.*s%.*s", 7, a1, 7, a2);
或者:
sprintf(s, "%.*s%.*s", sizeof(a1), a1, sizeof(a2), a2);
实际上,前面介绍的打印字符、整数、浮点数等都可以动态指定那些常量值,比如:
sprintf(s, "%-*d", 4, 'A'); //产生"65 "
sprintf(s, "%#0*X", 8, 128); //产生"0X000080","#"产生0X
sprintf(s, "%*.*f", 10, 2, 3.1415926); //产生" 3.14"
打印地址信息
有时调试程序时,我们可能想查看某些变量或者成员的地址,由于地址或者指针也不过是个32 位的数,你完全可以使用打印无符号整数的”%u”把他们打印出来:
sprintf(s, "%u", &i);
不过通常人们还是喜欢使用16 进制而不是10 进制来显示一个地址:
sprintf(s, "%08X", &i);
然而,这些都是间接的方法,对于地址打印,sprintf 提供了专门的”%p”:
sprintf(s, "%p", &i);
我觉得它实际上就相当于:
sprintf(s, "%0*x", 2 * sizeof(void *), &i);
利用sprintf 的返回值
较少有人注意printf/sprintf 函数的返回值,但有时它却是有用的,spritnf 返回了本次函数调用最终打印到字符缓冲区中的字符数目。也就是说每当一次sprinf 调用结束以后,你无须再调用一次strlen 便已经知道了结果字符串的长度。如:
int len = sprintf(s, "%d", i);
对于正整数来说,len 便等于整数i 的10 进制位数。
下面的是个完整的例子,产生10 个[0, 100)之间的随机数,并将他们打印到一个字符数组s 中,以逗号分隔开。
#include
#include
#include
int main() {
srand(time(0));
char s[64];
int offset = 0;
for(int i = 0; i < 10; i++) {
offset += sprintf(s + offset, "%d,", rand() % 100);
}
s[offset - 1] = '\n';//将最后一个逗号换成换行符。
printf(s);
return 0;
}
设想当你从数据库中取出一条记录,然后希望把他们的各个字段按照某种规则连接成一个字符串时,就可以使用这种方法,从理论上讲,他应该比不断的strcat 效率高,因为strcat 每次调用都需要先找到最后的那个’’的位置,而在上面给出的例子中,我们每次都利用sprintf 返回值把这个位置直接记下来了。
使用sprintf 的常见问题
sprintf 是个变参函数,使用时经常出问题,而且只要出问题通常就是能导致程序崩溃的内存访问错误,但好在由sprintf 误用导致的问题虽然严重,却很容易找出,无非就是那么几种情况,通常用眼睛再把出错的代码多看几眼就看出来了。
?? 缓冲区溢出
第一个参数的长度太短了,没的说,给个大点的地方吧。当然也可能是后面的参数的问题,建议变参对应一定要细心,而打印字符串时,尽量使用”%.ns”的形式指定最大字符数。
?? 忘记了第一个参数
低级得不能再低级问题,用printf 用得太惯了。//偶就常犯。:。(
?? 变参对应出问题
通常是忘记了提供对应某个格式符的变参,导致以后的参数统统错位,检查检查吧。尤其是对应”*”的那些参数,都提供了吗?不要把一个整数对应一个”%s”,编译器会觉得你欺她太甚了(编译器是obj 和exe 的妈妈,应该是个女的,:P)。
strftime
sprnitf 还有个不错的表妹:strftime,专门用于格式化时间字符串的,用法跟她表哥很像,也是一大堆格式控制符,只是毕竟小姑娘家心细,她还要调用者指定缓冲区的最大长度,可能是为了在出现问题时可以推卸责任吧。这里举个例子:
time_t t = time(0); //产生"YYYY-MM-DD hh:mm:ss"格式的字符串。
char s[32];
strftime(s, sizeof(s), "%Y-%m-%d %H:%M:%S", localtime(&t));
sprintf 在MFC 中也能找到他的知音:CString::Format,strftime 在MFC 中自然也有她的同道:CTime::Format,这一对由于从面向对象那里得到了赞助,用以写出的代码更觉优雅。
sprintf
sprintf 将字串格式化。
在头文件 #include<stdio.h>中
语法: string sprintf(string format, mixed [args]...);
传回值: 字串
1. 处理字符方向。-负号时表时从后向前处理。
2. 填空字元。 0 的话表示空格填 0;空格是内定值,表示空格就放着。
3. 字符总宽度。为最小宽度。
4. 精确度。指在小数点后的浮点数位数。
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
转换字符
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
% 印出百分比符号,不转换。
b 整数转成二进位。
c 整数转成对应的 ASCII 字元。
d 整数转成十进位。
f 倍精确度数字转成浮点数。
o 整数转成八进位。
s 整数转成字串。
x 整数转成小写十六进位。
X 整数转成大写十六进位。
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
<?
$money = 123.1
$formatted = sprintf ("%06.2f", $money); // 此时变数 $ formatted 值为 "123.10"
$formatted = sprintf ("%08.2f", $money); // 此时变数 $ formatted 值为 "00123.10"
$formatted = sprintf ("%-08.2f", $money); // 此时变数 $ formatted 值为 "123.1000"
$formatted = sprintf ("%.2f%%", 0.95 * 100); // 格式化为百分比
?>
¢%08.2f 解释:
%开始符
0是 "填空字元" 表示,如果长度不足时就用0来填满。
6格式化后总长度
2f小数位长度,即2位
¢第4行值为"00123.10" 解释:
因为2f是(2位)+小数点符号(1)+前面123(3位)=6位,总长度为8位,故前面用[填空字元]0表示,即00123.10
¢第4行值为"-123.1000" 解释:
-号为反向操作,然后填空字元0添加在最后面了
/********************************************************
以下选自《CSDN 社区电子杂志——C/C++杂志》
*********************************************************/
在将各种类型的数据构造成字符串时,sprintf 的强大功能很少会让你失望。由于sprintf 跟printf 在用法上几乎一样,只是打印的目的地不同而已,前者打印到字符串中,后者则直接在命令行上输出。这也导致sprintf 比printf 有用得多。
sprintf 是个变参函数,定义如下:
int sprintf( char *buffer, const char *format [, argument] ... );
除了前两个参数类型固定外,后面可以接任意多个参数。而它的精华,显然就在第二个参数:格式化字符串上。
printf 和sprintf 都使用格式化字符串来指定串的格式,在格式串内部使用一些以“%”开头的格式说明符(format specifications)来占据一个位置,在后边的变参列表中提供相应的变量,最终函数就会用相应位置的变量来替代那个说明符,产生一个调用者想要的字符串。
格式化数字字符串
sprintf 最常见的应用之一莫过于把整数打印到字符串中,所以,spritnf 在大多数场合可以替代itoa。
如:
//把整数123 打印成一个字符串保存在s 中。
sprintf(s, "%d", 123); //产生"123"
可以指定宽度,不足的左边补空格:
sprintf(s, "%8d%8d", 123, 4567); //产生:" 123 4567"
当然也可以左对齐:
sprintf(s, "%-8d%8d", 123, 4567); //产生:"123 4567"
也可以按照16 进制打印:
sprintf(s, "%8x", 4567); //小写16 进制,宽度占8 个位置,右对齐
sprintf(s, "%-8X", 4568); //大写16 进制,宽度占8 个位置,左对齐
这样,一个整数的16 进制字符串就很容易得到,但我们在打印16 进制内容时,通常想要一种左边补0 的等宽格式,那该怎么做呢?很简单,在表示宽度的数字前面加个0 就可以了。
sprintf(s, "%08X", 4567); //产生:"000011D7"
上面以”%d”进行的10 进制打印同样也可以使用这种左边补0 的方式。
这里要注意一个符号扩展的问题:比如,假如我们想打印短整数(short)-1 的内存16 进制表示形式,在Win32 平台上,一个short 型占2 个字节,所以我们自然希望用4 个16 进制数字来打印它:
short si = -1;
sprintf(s, "%04X", si);
产生“FFFFFFFF”,怎么回事?因为spritnf 是个变参函数,除了前面两个参数之外,后面的参数都不是类型安全的,函数更没有办法仅仅通过一个“%X”就能得知当初函数调用前参数压栈时被压进来的到底是个4 字节的整数还是个2 字节的短整数,所以采取了统一4 字节的处理方式,导致参数压栈时做了符号扩展,扩展成了32 位的整数-1,打印时4 个位置不够了,就把32 位整数-1 的8 位16 进制都打印出来了。
如果你想看si 的本来面目,那么就应该让编译器做0 扩展而不是符号扩展(扩展时二进制左边补0 而不是补符号位):
sprintf(s, "%04X", (unsigned short)si);
就可以了。或者:
unsigned short si = -1;
sprintf(s, "%04X", si);
sprintf 和printf 还可以按8 进制打印整数字符串,使用”%o”。注意8 进制和16 进制都不会打印出负数,都是无符号的,实际上也就是变量的内部编码的直接的16 进制或8 进制表示。
控制浮点数打印格式
浮点数的打印和格式控制是sprintf 的又一大常用功能,浮点数使用格式符”%f”控制,默认保留小数点后6 位数字,比如:
sprintf(s, "%f", 3.1415926); //产生"3.141593"
但有时我们希望自己控制打印的宽度和小数位数,这时就应该使用:”%m.nf”格式,其中m 表示打印的宽度,n 表示小数点后的位数。比如:
sprintf(s, "%10.3f", 3.1415626); //产生:" 3.142"
sprintf(s, "%-10.3f", 3.1415626); //产生:"3.142 "
sprintf(s, "%.3f", 3.1415626); //不指定总宽度,产生:"3.142"
注意一个问题,你猜
int i = 100;
sprintf(s, "%.2f", i);
会打出什么东东来?“100.00”?对吗?自己试试就知道了,同时也试试下面这个:
sprintf(s, "%.2f", (double)i);
第一个打出来的肯定不是正确结果,原因跟前面提到的一样,参数压栈时调用者并不知道跟i相对应的格式控制符是个”%f”。而函数执行时函数本身则并不知道当年被压入栈里的是个整数,于是可怜的保存整数i 的那4 个字节就被不由分说地强行作为浮点数格式来解释了,整个乱套了。不过,如果有人有兴趣使用手工编码一个浮点数,那么倒可以使用这种方法来检验一下你手工编排的结果是否正确。
字符/Ascii 码对照
我们知道,在C/C++语言中,char 也是一种普通的scalable 类型,除了字长之外,它与short,int,long 这些类型没有本质区别,只不过被大家习惯用来表示字符和字符串而已。(或许当年该把这个类型叫做“byte”,然后现在就可以根据实际情况,使用byte 或short 来把char 通过typedef 定义出来,这样更合适些)于是,使用”%d”或者”%x”打印一个字符,便能得出它的10 进制或16 进制的ASCII 码;反过来,使用”%c”打印一个整数,便可以看到它所对应的ASCII 字符。以下程序段把所有可见字符的ASCII 码对照表打印到屏幕上(这里采用printf,注意”#”与”%X”合用时自动为16 进制数增加”0X”前缀):
for(int i = 32; i < 127; i++) {
printf("[ %c ]: %3d 0x%#04X\n", i, i, i);
}
连接字符串
sprintf 的格式控制串中既然可以插入各种东西,并最终把它们“连成一串”,自然也就能够连接字符串,从而在许多场合可以替代strcat,但sprintf 能够一次连接多个字符串(自然也可以同时在它们中间插入别的内容,总之非常灵活)。比如:
char* who = "I";
char* whom = "CSDN";
sprintf(s, "%s love %s.", who, whom); //产生:"I love CSDN. "
strcat 只能连接字符串(一段以’’结尾的字符数组或叫做字符缓冲,null-terminated-string),但有时我们有两段字符缓冲区,他们并不是以 ’’结尾。比如许多从第三方库函数中返回的字符数组,从硬件或者网络传输中读进来的字符流,它们未必每一段字符序列后面都有个相应的’’来结尾。如果直接连接,不管是sprintf 还是strcat 肯定会导致非法内存操作,而strncat 也至少要求第一个参数是个null-terminated-string,那该怎么办呢?我们自然会想起前面介绍打印整数和浮点数时可以指定宽度,字符串也一样的。比如:
char a1[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
char a2[] = {'H', 'I', 'J', 'K', 'L', 'M', 'N'};
如果:
sprintf(s, "%s%s", a1, a2); //Don't do that!
十有八九要出问题了。是否可以改成:
sprintf(s, "%7s%7s", a1, a2);
也没好到哪儿去,正确的应该是:
sprintf(s, "%.7s%.7s", a1, a2);//产生:"ABCDEFGHIJKLMN"
这可以类比打印浮点数的”%m.nf”,在”%m.ns”中,m 表示占用宽度(字符串长度不足时补空格,超出了则按照实际宽度打印),n 才表示从相应的字符串中最多取用的字符数。通常在打印字符串时m 没什么大用,还是点号后面的n 用的多。自然,也可以前后都只取部分字符:
sprintf(s, "%.6s%.5s", a1, a2);//产生:"ABCDEFHIJKL"
在许多时候,我们或许还希望这些格式控制符中用以指定长度信息的数字是动态的,而不是静态指定的,因为许多时候,程序要到运行时才会清楚到底需要取字符数组中的几个字符,这种动态的宽度/精度设置功能在sprintf 的实现中也被考虑到了,sprintf 采用”*”来占用一个本来需要一个指定宽度或精度的常数数字的位置,同样,而实际的宽度或精度就可以和其它被打印的变量一样被提供出来,于是,上面的例子可以变成:
sprintf(s, "%.*s%.*s", 7, a1, 7, a2);
或者:
sprintf(s, "%.*s%.*s", sizeof(a1), a1, sizeof(a2), a2);
实际上,前面介绍的打印字符、整数、浮点数等都可以动态指定那些常量值,比如:
sprintf(s, "%-*d", 4, 'A'); //产生"65 "
sprintf(s, "%#0*X", 8, 128); //产生"0X000080","#"产生0X
sprintf(s, "%*.*f", 10, 2, 3.1415926); //产生" 3.14"
打印地址信息
有时调试程序时,我们可能想查看某些变量或者成员的地址,由于地址或者指针也不过是个32 位的数,你完全可以使用打印无符号整数的”%u”把他们打印出来:
sprintf(s, "%u", &i);
不过通常人们还是喜欢使用16 进制而不是10 进制来显示一个地址:
sprintf(s, "%08X", &i);
然而,这些都是间接的方法,对于地址打印,sprintf 提供了专门的”%p”:
sprintf(s, "%p", &i);
我觉得它实际上就相当于:
sprintf(s, "%0*x", 2 * sizeof(void *), &i);
利用sprintf 的返回值
较少有人注意printf/sprintf 函数的返回值,但有时它却是有用的,spritnf 返回了本次函数调用最终打印到字符缓冲区中的字符数目。也就是说每当一次sprinf 调用结束以后,你无须再调用一次strlen 便已经知道了结果字符串的长度。如:
int len = sprintf(s, "%d", i);
对于正整数来说,len 便等于整数i 的10 进制位数。
下面的是个完整的例子,产生10 个[0, 100)之间的随机数,并将他们打印到一个字符数组s 中,以逗号分隔开。
#include
#include
#include
int main() {
srand(time(0));
char s[64];
int offset = 0;
for(int i = 0; i < 10; i++) {
offset += sprintf(s + offset, "%d,", rand() % 100);
}
s[offset - 1] = '\n';//将最后一个逗号换成换行符。
printf(s);
return 0;
}
设想当你从数据库中取出一条记录,然后希望把他们的各个字段按照某种规则连接成一个字符串时,就可以使用这种方法,从理论上讲,他应该比不断的strcat 效率高,因为strcat 每次调用都需要先找到最后的那个’’的位置,而在上面给出的例子中,我们每次都利用sprintf 返回值把这个位置直接记下来了。
使用sprintf 的常见问题
sprintf 是个变参函数,使用时经常出问题,而且只要出问题通常就是能导致程序崩溃的内存访问错误,但好在由sprintf 误用导致的问题虽然严重,却很容易找出,无非就是那么几种情况,通常用眼睛再把出错的代码多看几眼就看出来了。
?? 缓冲区溢出
第一个参数的长度太短了,没的说,给个大点的地方吧。当然也可能是后面的参数的问题,建议变参对应一定要细心,而打印字符串时,尽量使用”%.ns”的形式指定最大字符数。
?? 忘记了第一个参数
低级得不能再低级问题,用printf 用得太惯了。//偶就常犯。:。(
?? 变参对应出问题
通常是忘记了提供对应某个格式符的变参,导致以后的参数统统错位,检查检查吧。尤其是对应”*”的那些参数,都提供了吗?不要把一个整数对应一个”%s”,编译器会觉得你欺她太甚了(编译器是obj 和exe 的妈妈,应该是个女的,:P)。
strftime
sprnitf 还有个不错的表妹:strftime,专门用于格式化时间字符串的,用法跟她表哥很像,也是一大堆格式控制符,只是毕竟小姑娘家心细,她还要调用者指定缓冲区的最大长度,可能是为了在出现问题时可以推卸责任吧。这里举个例子:
time_t t = time(0); //产生"YYYY-MM-DD hh:mm:ss"格式的字符串。
char s[32];
strftime(s, sizeof(s), "%Y-%m-%d %H:%M:%S", localtime(&t));
sprintf 在MFC 中也能找到他的知音:CString::Format,strftime 在MFC 中自然也有她的同道:CTime::Format,这一对由于从面向对象那里得到了赞助,用以写出的代码更觉优雅。
内存管理 (2013/3/4 19:40:15)
内存管理
内存分配方式
内存分配方式有三种:
从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。
在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
从堆上分配,亦称动态内存分配。程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用 free 或 delete 释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
常见的内存错误及其对策
发生内存错误是件非常麻烦的事情。编译器不能自动发现这些错误,通常是在程序运行时才能捕捉到。而这些错误大多没有明显的症状,时隐时现,增加了改错的难度。有时用户怒气冲冲地把你找来,程序却没有发生任何问题,你一走,错误又发作了。
常见的内存错误及其对策如下:
内存分配未成功,却使用了它。
编程新手常犯这种错误,因为他们没有意识到内存分配会不成功。常用解决办法是,在使用内存之前检查指针是否为 NULL。如果指针 p 是函数的参数,那么在函数的入口处用assert(p!=NULL)进行检查。 如果是用malloc或new来申请内存, 应该用if(p==NULL) 或 if(p!=NULL)进行防错处理。
内存分配虽然成功,但是尚未初始化就引用它。
犯这种错误主要有两个起因:一是没有初始化的观念;二是误以为内存的缺省初值全为零,导致引用初值错误(例如数组) 。
内存的缺省初值究竟是什么并没有统一的标准,尽管有些时候为零值,我们宁可信其无不可信其有。所以无论用何种方式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦。
内存分配成功并且已经初始化,但操作越过了内存的边界。
例如在使用数组时经常发生下标“多 1”或者“少 1”的操作。特别是在 for 循环语句中,循环次数很容易搞错,导致数组操作越界。
忘记了释放内存,造成内存泄露。
含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充足,你看不到错误。终有一次程序突然死掉,系统出现提示:内存耗尽。
动态内存的申请与释放必须配对,程序中 malloc 与 free 的使用次数一定要相同,否则肯定有错误(new/delete 同理) 。
释放了内存却继续使用它。
有三种情况:
(1 )程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
( 2 )函数的 return 语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用” ,因为该内存在函数体结束时被自动销毁。
( 3 )使用 free 或 delete 释放了内存后,没有将指针设置为 NULL。导致产生“野指针” 。
用 malloc 或 new 申请内存之后,应该立即检查指针值是否为 NULL。防止使用指针值为 NULL 的内存。
不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
避免数组或指针的下标越界,特别要当心发生“多 1”或者“少 1”操作。
动态内存的申请与释放必须配对,防止内存泄漏。
用 free 或 delete 释放了内存之后,立即将指针设置为 NULL,防止产生“野指针” 。
指针与数组的对比
C++/C 程序中,指针和数组在不少地方可以相互替换着用,让人产生一种错觉,以为两者是等价的。
数组要么在静态存储区被创建(如全局数组) ,要么在栈上被创建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变,只有数组的内容可以改变。
指针可以随时指向任意类型的内存块,它的特征是“可变” ,所以我们常用指针来操作动态内存。指针远比数组灵活,但也更危险。
下面以字符串为例比较指针与数组的特性。
修改内容
字符数组 a 的容量是 6 个字符,其内容为 hello\0。a 的内容可以改变,如 a[0]= ‘X’。指针 p 指向常量字符串“world” (位于静态存储区,内容为 world\0) ,常量字符串的内容是不可以被修改的。从语法上看,编译器并不觉得语句 p[0]= ‘X’有什么不妥,但是该语句企图修改常量字符串的内容而导致运行错误。
char a[] = “hello”;
a[0] = ‘X’;
cout << a << endl;
char *p = “world”; // 注意 p 指向常量字符串
p[0] = ‘X’; // 编译器不能发现该错误
cout << p << endl;
内容复制与比较
不能对数组名进行直接复制与比较。示例 7-3-2 中,若想把数组 a 的内容复制给数组 b,不能用语句 b = a ,否则将产生编译错误。应该用标准库函数 strcpy 进行复制。同理, 比较 b 和 a 的内容是否相同, 不能用 if(b==a) 来判断, 应该用标准库函数 strcmp进行比较。 语句 p = a 并不能把 a 的内容复制指针 p,而是把 a 的地址赋给了 p。要想复制 a的内容,可以先用库函数 malloc 为 p 申请一块容量为 strlen(a)+1 个字符的内存,再用 strcpy 进行字符串复制。同理,语句 if(p==a) 比较的不是内容而是地址,应该用库函数 strcmp 来比较。
// 数组…
char a[] = "hello";
char b[10];
strcpy(b, a); // 不能用 b = a;
if(strcmp(b, a) == 0) // 不能用 if (b == a)
…
// 指针…
int len = strlen(a);
char *p = (char *)malloc(sizeof(char)*(len+1));
strcpy(p,a); // 不要用 p = a;
if(strcmp(p, a) == 0) // 不要用 if (p == a)
…
计算内存容量
用运算符 sizeof 可以计算出数组的容量(字节数) 。示例 7-3-3(a)中,sizeof(a)的值是 12(注意别忘了’\0’) 。指针 p 指向 a,但是 sizeof(p)的值却是 4。这是因为sizeof(p)得到的是一个指针变量的字节数,相当于 sizeof(char*),而不是 p 所指的内存容量。C++/C 语言没有办法知道指针所指的内存容量,除非在申请内存时记住它。
char a[] = "hello world";
char *p = a;
cout<< sizeof(a) << endl; // 12 字节
cout<< sizeof(p) << endl; // 4 字节
注意当数组作为函数的参数进行传递时,该数组自动退化为同类型的指针。示例7-3-3(b)中,不论数组 a 的容量是多少,sizeof(a)始终等于 sizeof(char *)。
void Func(char a[100])
{
cout<< sizeof(a) << endl; // 4 字节而不是 100 字节
}
free 和 delete 把指针怎么啦?
别看 free 和 delete 的名字恶狠狠的(尤其是 delete) ,它们只是把指针所指的内存给释放掉,但并没有把指针本身干掉。
用调试器跟踪示例 7-5,发现指针 p 被 free 以后其地址仍然不变(非 NULL) ,只是该地址对应的内存是垃圾,p 成了“野指针” 。如果此时不把 p 设置为 NULL,会让人误以为 p 是个合法的指针。
如果程序比较长,我们有时记不住 p 所指的内存是否已经被释放,在继续使用 p 之前,通常会用语句 if (p != NULL)进行防错处理。很遗憾,此时 if 语句起不到防错作用,因为即便 p 不是 NULL 指针,它也不指向合法的内存块。
char *p = (char *) malloc(100);
strcpy(p, “hello”);
free(p); // p 所指的内存被释放,但是 p 所指的地址仍然不变
…
if(p != NULL) // 没有起到防错作用
{
strcpy(p, “world”); // 出错
}
动态内存会被自动释放吗?
函数体内的局部变量在函数结束时自动消亡。很多人误以为示例 7-6 是正确的。理由是 p 是局部的指针变量,它消亡的时候会让它所指的动态内存一起完蛋。这是错觉!
void Func(void)
{
char *p = (char *) malloc(100); // 动态内存会自动释放吗?
}
示例 7-6 试图让动态内存自动释放
我们发现指针有一些“似是而非”的特征:
(1)指针消亡了,并不表示它所指的内存会被自动释放。
(2)内存被释放了,并不表示指针会消亡或者成了 NULL 指针。
这表明释放内存并不是一件可以草率对待的事。也许有人不服气,一定要找出可以草率行事的理由:
如果程序终止了运行,一切指针都会消亡,动态内存会被操作系统回收。既然如此,在程序临终前,就可以不必释放内存、不必将指针设置为 NULL 了。终于可以偷懒而不会发生错误了吧?
想得美。如果别人把那段程序取出来用到其它地方怎么办?
杜绝“野指针”
“野指针”不是 NULL 指针,是指向“垃圾”内存的指针。人们一般不会错用 NULL指针,因为用 if 语句很容易判断。但是“野指针”是很危险的,if 语句对它不起作用。
“野指针”的成因主要有两种:
(1)指针变量没有被初始化。任何指针变量刚被创建时不会自动成为 NULL 指针,它的缺省值是随机的,它会乱指一气。所以,指针变量在创建的同时应当被初始化,要么将指针设置为 NULL,要么让它指向合法的内存。例如
char *p = NULL;
char *str = (char *) malloc(100);
(2)指针 p 被 free 或者 delete 之后,没有置为 NULL,让人误以为 p 是个合法的指针。
(3)指针操作超越了变量的作用范围。这种情况让人防不胜防,示例程序如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
class A { public: void Func(void){ cout << “Func of class A” << endl; } }; void Test(void) { A *p; { A a; p = &a; // 注意 a 的生命期 } p->Func(); // p 是“野指针” } |
函数 Test 在执行语句 p->Func()时,对象 a 已经消失,而 p 是指向 a 的,所以 p 就成了“野指针” 。但奇怪的是我运行这个程序时居然没有出错,这可能与编译器有关。
有了 malloc/free 为什么还要 new/delete ?
malloc 与 free 是 C++/C 语言的标准库函数,new/delete 是 C++的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用 maloc/free 无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free 是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于 malloc/free。
因此 C++语言需要一个能完成动态内存分配和初始化工作的运算符 new,以及一个能完成清理与释放内存工作的运算符 delete。注意 new/delete 不是库函数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
class Obj { public : Obj(void){ cout << “Initialization” << endl; } ~Obj(void){ cout << “Destroy” << endl; } void Initialize(void){ cout << “Initialization” << endl; } void Destroy(void){ cout << “Destroy” << endl; } }; void UseMallocFree(void) { Obj *a = (obj *)malloc(sizeof(obj)); // 申请动态内存 a->Initialize(); // 初始化 //… a->Destroy(); // 清除工作 free(a); // 释放内存 } void UseNewDelete(void) { Obj *a = new Obj; // 申请动态内存并且初始化 //… delete a; // 清除并且释放内存 } |
内存耗尽怎么办?
如果在申请动态内存时找不到足够大的内存块,malloc 和 new 将返回 NULL 指针,宣告内存申请失败。通常有三种方式处理“内存耗尽”问题。
(1)判断指针是否为 NULL,如果是则马上用 return 语句终止本函数。
(2)判断指针是否为 NULL,如果是则马上用 exit(1)终止整个程序的运行。
(3)为 new 和 malloc 设置异常处理函数。例如 Visual C++可以用_set_new_hander 函数为 new 设置用户自己定义的异常处理函数,也可以让 malloc 享用与 new 相同的异常处理函数。
|
1
2
3
4
5
6
7
8
9
10
11
|
void main(void) { float *p = NULL; while(TRUE) { p = new float[1000000]; cout << “eat memory” << endl; if(p==NULL) exit(1); } } |
malloc/free 的使用要点
函数 malloc 的原型如下:
void * malloc(size_t size);
用 malloc 申请一块长度为 length 的整数类型的内存,程序如下:
int *p = (int *) malloc(sizeof(int) * length);
我们应当把注意力集中在两个要素上: “类型转换”和“sizeof” 。
malloc 返回值的类型是 void *,所以在调用 malloc 时要显式地进行类型转换,将
void * 转换成所需要的指针类型。
malloc 函数本身并不识别要申请的内存是什么类型,它只关心内存的总字节数。我
们通常记不住 int, float 等数据类型的变量的确切字节数。 例如 int 变量在 16 位系统
下是 2 个字节,在 32 位下是 4 个字节;而 float 变量在 16 位系统下是 4 个字节,在
32 位下也是 4 个字节。最好用以下程序作一次测试:
cout << sizeof(char) << endl;
cout << sizeof(int) << endl;
cout << sizeof(unsigned int) << endl;
cout << sizeof(long) << endl;
cout << sizeof(unsigned long) << endl;
cout << sizeof(float) << endl;
cout << sizeof(double) << endl;
cout << sizeof(void *) << endl;
assert用法总结 (2013/3/4 17:28:42)
assert宏的原型定义在<assert.h>中,其作用是如果它的条件返回错误,则终止程序执行,原型定义:
#include <assert.h>
void assert( int expression );
assert的作用是现计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,
然后通过调用 abort 来终止程序运行。
请看下面的程序清单badptr.c:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
int main( void )
{
FILE *fp;
fp = fopen( "test.txt", "w" );//以可写的方式打开一个文件,如果不存在就创建一个同名文件
assert( fp ); //所以这里不会出错
fclose( fp );
fp = fopen( "noexitfile.txt", "r" );//以只读的方式打开一个文件,如果不存在就打开文件失败
assert( fp ); //所以这里出错
fclose( fp ); //程序永远都执行不到这里来
return 0;
}
[root@localhost error_process]# gcc badptr.c
[root@localhost error_process]# ./a.out
a.out: badptr.c:14: main: Assertion `fp' failed.
已放弃
使用assert的缺点是,频繁的调用会极大的影响程序的性能,增加额外的开销。
在调试结束后,可以通过在包含#include <assert.h>的语句之前插入 #define NDEBUG 来禁用assert调用,示例代码如下:
#include <stdio.h>
#define NDEBUG
#include <assert.h>
用法总结与注意事项:
1)在函数开始处检验传入参数的合法性
如:
int resetBufferSize(int nNewSize)
{
//功能:改变缓冲区大小,
//参数:nNewSize 缓冲区新长度
//返回值:缓冲区当前长度
//说明:保持原信息内容不变 nNewSize<=0表示清除缓冲区
assert(nNewSize >= 0);
assert(nNewSize <= MAX_BUFFER_SIZE);
...
}
2)每个assert只检验一个条件,因为同时检验多个条件时,如果断言失败,无法直观的判断是哪个条件失败
不好: assert(nOffset>=0 && nOffset+nSize<=m_nInfomationSize);
好: assert(nOffset >= 0);
assert(nOffset+nSize <= m_nInfomationSize);
3)不能使用改变环境的语句,因为assert只在DEBUG个生效,如果这么做,会使用程序在真正运行时遇到问题
错误: assert(i++ < 100)
这是因为如果出错,比如在执行之前i=100,那么这条语句就不会执行,那么i++这条命令就没有执行。
正确: assert(i < 100)
i++;
4)assert和后面的语句应空一行,以形成逻辑和视觉上的一致感
5)有的地方,assert不能代替条件过滤
高质量C编程指南—林锐 (2013/3/4 15:18:04)
头文件的作用略作解释:
(1)通过头文件来调用库功能。在很多场合,源代码不便(或不准)向用户公布,只要向用户提供头文件和二进制的库即可。用户只需要按照头文件中的接口声明来调用库功能,而不必关心接口怎么实现的。编译器会从库中提取相应的代码。
(2)头文件能加强类型安全检查。如果某个接口被实现或被使用时,其方式与头文件中的声明不一致,编译器就会指出错误,这一简单的规则能大大减轻程序员调试、改错的负担。
如果一个软件的头文件数目比较多(如超过十个) ,通常应将头文件和定义文件分别保存于不同的目录,以便于维护。例如可将头文件保存于 include 目录,将定义文件保存于 source 目录(可以是多级目录) 。
如果某些头文件是私有的,它不会被用户的程序直接引用,则没有必要公开其“声明” 。为了加强信息隐藏,这些私有的头文件可以和定义文件存放于同一个目录。
空行
空行起着分隔程序段落的作用。空行得体(不过多也不过少)将使程序的布局更加
清晰。空行不会浪费内存,虽然打印含有空行的程序是会多消耗一些纸张,但是值得。
所以不要舍不得用空行。
在每个类声明之后、每个函数定义结束之后都要加空行。参见示例2-1(a)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 空行 void Function1(…) { … } // 空行 void Function2(…) { … } // 空行 void Function3(…) { … } |
示例 2-1(a) 函数之间的空行
在一个函数体内,逻揖上密切相关的语句之间不加空行,其它地方应加空行分隔。参见示例 2-1(b )
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 空行 while (condition) { statement1; // 空行 if (condition) { statement2; } else { statement3; } // 空行 statement4; } |
示例 2-1(b) 函数内部的空行
代码行
一行代码只做一件事情,如只定义一个变量,或只写一条语句。这样的代码容易阅读,并且方便于写注释。
if、for、while、do 等语句自占一行,执行语句不得紧跟其后。不论执行语句有多少都要加{}。这样可以防止书写失误。
风格良好的代码行
12345678910111213141516intwidth;// 宽度intheight;// 高度intdepth;// 深度x = a + b;y = c + d;z = e + f;if(width < height){dosomething();}for(initialization; condition; update){dosomething();}// 空行other();风格不良的代码行
12345678intwidth, height, depth;// 宽度高度深度X = a + b; y = c + d; z = e + f;if(width < height) dosomething();for(initialization; condition; update)dosomething();other();尽可能在定义变量的同时初始化该变量(就近原则)
如果变量的引用处和其定义处相隔比较远,变量的初始化很容易被忘记。如果引用了未被初始化的变量,可能会导致程序错误。本建议可以减少隐患。
例如
int width = 10; // 定义并初绐化 width
int height = 10; // 定义并初绐化 height
int depth = 10; // 定义并初绐化 depth
代码行内的空格
关键字之后要留空格。象 const、virtual、inline、case 等关键字之后至少要留一个空格,否则无法辨析关键字。象 if、for、while 等关键字之后应留一个空格再跟左括号‘ (’ ,以突出关键字。
函数名之后不要留空格,紧跟左括号‘ (’ ,以与关键字区别。
‘ (’向后紧跟, ‘) ’ 、 ‘, ’ 、 ‘;’向前紧跟,紧跟处不留空格。
‘, ’之后要留空格,如 Function(x, y, z)。如果‘;’不是一行的结束符号,其后要留空格,如 for (initialization; condition; update)。
赋值操作符、比较操作符、算术操作符、逻辑操作符、位域操作符,如“=” 、 “+=” “>=” 、 “<=” 、 “+” 、 “*” 、 “%” 、 “&&” 、 “||” 、 “<<”,“^”等二元操作符的前后应当加空格。
一元操作符如“!” 、 “~” 、 “++” 、 “--” 、 “&” (地址运算符)等前后不加空格。
象“ [] ” 、 “.” 、 “->”这类操作符前后不加空格。
对于表达式比较长的 for 语句和 if 语句,为了紧凑起见可以适当地去掉一些空格,如 for (i=0; i<10; i++)和 if ((a<=b) && (c<=d))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
void Func1(int x, int y, int z); // 良好的风格 void Func1 (int x,int y,int z); // 不良的风格 if (year >= 2000) // 良好的风格 if(year>=2000) // 不良的风格 if ((a>=b) && (c<=d)) // 良好的风格 if(a>=b&&c<=d) // 不良的风格 for (i=0; i<10; i++) // 良好的风格 for(i=0;i<10;i++) // 不良的风格 for (i = 0; I < 10; i ++) // 过多的空格 x = a < b ? a : b; // 良好的风格 x=a<b?a:b; // 不好的风格 int *x = &y; // 良好的风格 int * x = & y; // 不良的风格 array[5] = 0; // 不要写成 array [ 5 ] = 0; a.Function(); // 不要写成 a . Function(); b->Function(); // 不要写成 b -> Function(); |
对齐
程序的分界符‘{’和‘}’应独占一行并且位于同一列,同时与引用它们的语句左对齐。
{ }之内的代码块在‘{’右边数格处左对齐。
长行拆分
代码行最大长度宜控制在 70 至 80 个字符以内。代码行不要过长,否则眼睛看不过来,也不便于打印。
长表达式要在低优先级操作符处拆分成新行, 操作符放在新行之首 (以便突出操作符) 。拆分出的新行要进行适当的缩进,使排版整齐,语句可读。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
if ((very_longer_variable1 >= very_longer_variable12) && (very_longer_variable3 <= very_longer_variable14) && (very_longer_variable5 <= very_longer_variable16)) { dosomething(); } virtual CMatrix CMultiplyMatrix (CMatrix leftMatrix, CMatrix rightMatrix); for (very_longer_initialization; very_longer_condition; very_longer_update) { dosomething(); } |
修饰符的位置
修饰符 * 和 & 应该靠近数据类型还是该靠近变量名,是个有争议的活题。若将修饰符 * 靠近数据类型,例如:int* x; 从语义上讲此写法比较直观,即 x是 int 类型的指针。 上述写法的弊端是容易引起误解,例如:int* x, y; 此处 y 容易被误解为指针变量。虽然将 x 和 y 分行定义可以避免误解,但并不是人人都愿意这样做。
因此,应当将修饰符 * 和 & 紧靠变量名 。
例如:
char *name;
int *x, y; // 此处 y 不会被误解为指针
注释
C 语言的注释符为“/*…*/” 。C++语言中,程序块的注释常采用“/*…*/” ,行注释一般采用“//…” 。注释通常用于:
(1)版本、版权声明;
(2)函数接口说明;
(3)重要的代码行或段落提示。
虽然注释有助于理解代码,但注意不可过多地使用注释。参见示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
/* * 函数介绍: * 输入参数: * 输出参数: * 返回值 : */void Function(float x, float y, float z) { … } if (…) { … while (…) { … } // end of while … } // end of if |
类的版式
类的版式主要有两种方式:
(1) 将 private 类型的数据写在前面, 而将 public 类型的函数写在后面, 如示例 8-3 (a) 。采用这种版式的程序员主张类的设计“以数据为中心” ,重点关注类的内部结构。
|
1
2
3
4
5
6
7
8
9
10
11
|
class A { private: int i, j; float x, y; … public: void Func1(void); void Func2(void); … } |
(2)将 public 类型的函数写在前面,而将 private 类型的数据写在后面,如示例 8.3(b)采用这种版式的程序员主张类的设计“以行为为中心” ,重点关注的是类应该提供什么样的接口(或服务) 。
|
1
2
3
4
5
6
7
8
9
10
11
|
class A { public: void Func1(void); void Func2(void); … private: int i, j; float x, y; … } |
布尔变量与零值比较
不可将布尔变量直接与 TRUE、FALSE 或者 1、0 进行比较。
根据布尔类型的语义,零值为“假” (记为 FALSE) ,任何非零值都是“真” (记为TRUE) 。TRUE 的值究竟是什么并没有统一的标准。例如 Visual C++ 将 TRUE 定义为1,而 Visual Basic 则将 TRUE 定义为-1。
假设布尔变量名字为 flag,它与零值比较的标准 if 语句如下:
if (flag) // 表示 flag 为真
if (!flag) // 表示 flag 为假
它的用法都属于不良风格,例如:
if (flag == TRUE)
if (flag == 1 )
if (flag == FALSE)
if (flag == 0)
整型变量与零值比较
应当将整型变量用“==”或“!=”直接与 0 比较。
假设整型变量的名字为 value,它与零值比较的标准 if 语句如下:
if (value == 0)
if (value != 0)
不可模仿布尔变量的风格而写成
if (value) // 会让人误解 value 是布尔变量
if (!value)
浮点变量与零值比较
不可将浮点变量用“==”或“!=”与任何数字比较。
千万要留意,无论是 float 还是 double 类型的变量,都有精度限制。所以一定要避免将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”形式。
假设浮点变量的名字为 x,应当将
if (x == 0.0) // 隐含错误的比较
转化为
if ((x>=-EPSINON) && (x<=EPSINON))
其中 EPSINON 是允许的误差(即精度) 。
指针变量与零值比较
应当将指针变量用“==”或“!=”与 NULL 比较。
指针变量的零值是“空” (记为 NULL) 。尽管 NULL 的值与 0 相同,但是两者意义不同。假设指针变量的名字为 p,它与零值比较的标准 if 语句如下:
if (p == NULL) // p 与 NULL 显式比较,强调 p 是指针变量
if (p != NULL)
不要写成
if (p == 0) // 容易让人误解 p 是整型变量
if (p != 0)
或者
if (p) // 容易让人误解 p 是布尔变量
if (!p)
const 与 #define 的比较
C++ 语言可以用 const 来定义常量,也可以用 #define 来定义常量。但是前者比后者有更多的优点:
(1) const 常量有数据类型,而宏常量没有数据类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且在字符替换可能会产生意料不到的错误(边际效应) 。
(2) 有些集成化的调试工具可以对 const 常量进行调试,但是不能对宏常量进行调试。
在 C++ 程序中只使用 const 常量而不使用宏常量,即 const 常量完全取代宏常量。
常量定义规则
需要对外公开的常量放在头文件中,不需要对外公开的常量放在定义文件的头部。为便于管理,可以把不同模块的常量集中存放在一个公共的头文件中。
如果某一常量与其它常量密切相关,应在定义中包含这种关系,而不应给出一些孤立的值。
例如:
const float RADIUS = 100;
const float DIAMETER = RADIUS * 2;
类中的常量
由于#define 定义的宏常量是全局的,不能达到目的,于是想当然地觉得应该用 const 修饰数据成员来实现。const 数据成员的确是存在的,但其含义却不是我们所期望的。const 数据成员只在某个对象生存期内是常量,而对于整个类而言却是可变的,因为类可以创建多个对象,不同的对象其 const 数据成员的值可以不同。
不能在类声明中初始化 const 数据成员。
以下用法是错误的,因为类的对象未被创建时,编译器不知道 SIZE 的值是什么。
class A
{…
const int SIZE = 100; // 错误,企图在类声明中初始化 const 数据成员
int array[SIZE]; // 错误,未知的 SIZE
};
const 数据成员的初始化只能在类构造函数的初始化表中进行,例如
class A
{…
A(int size); // 构造函数
const int SIZE ;
};
A::A(int size) : SIZE(size) // 构造函数的初始化表
{
…
}
A a(100); // 对象 a 的 SIZE 值为 100
A b(200); // 对象 b 的 SIZE 值为 200
怎样才能建立在整个类中都恒定的常量呢?别指望 const 数据成员了,应该用类中的枚举常量来实现。例如
class A
{…
enum { SIZE1 = 100, SIZE2 = 200}; // 枚举常量
int array1[SIZE1];
int array2[SIZE2];
};
枚举常量不会占用对象的存储空间,它们在编译时被全部求值。枚举常量的缺点是:它的隐含数据类型是整数,其最大值有限,且不能表示浮点数(如 PI=3.14159) 。
使用断言
使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的。
在函数的入口处,使用断言检查参数的有效性(合法性) 。
在编写函数时, 要进行反复的考查, 并且自问: “我打算做哪些假定?”一旦确定了的假定,就要使用断言对假定进行检查。
一般教科书都鼓励程序员们进行防错设计,但要记住这种编程风格可能会隐瞒错误。当进行防错设计时,如果“不可能发生”的事情的确发生了,则要使用断言进行报警。
引用与指针的比较
引用是 C++中的概念,初学者容易把引用和指针混淆一起。一下程序中,n 是 m 的一个引用(reference) ,m 是被引用物(referent) 。
int m;
int &n = m;
n 相当于 m 的别名(绰号) ,对 n 的任何操作就是对 m 的操作。例如有人名叫王小毛,他的绰号是“三毛” 。说“三毛”怎么怎么的,其实就是对王小毛说三道四。所以 n 既不是 m 的拷贝,也不是指向 m 的指针,其实 n 就是 m 它自己。
引用的一些规则如下:
(1)引用被创建的同时必须被初始化(指针则可以在任何时候被初始化) 。
(2)不能有 NULL 引用,引用必须与合法的存储单元关联(指针则可以是 NULL) 。
(3)一旦引用被初始化,就不能改变引用的关系(指针则可以随时改变所指的对象) 。
以下示例程序中,k 被初始化为 i 的引用。语句 k = j 并不能将 k 修改成为 j 的引用,只是把 k 的值改变成为 6。由于 k 是 i 的引用,所以 i 的值也变成了 6。
int i = 5;
int j = 6;
int &k = i;
k = j; // k 和 i 的值都变成了 6;
上面的程序看起来象在玩文字游戏,没有体现出引用的价值。引用的主要功能是传递函数的参数和返回值。C++语言中,函数的参数和返回值的传递方式有三种:值传递、指针传递和引用传递。
以下是“值传递”的示例程序。由于 Func1 函数体内的 x 是外部变量 n 的一份拷贝,改变 x 的值不会影响 n, 所以 n 的值仍然是 0。
|
1
2
3
4
5
6
7
8
9
|
void Func1(int x) { x = x + 10; } … int n = 0; Func1(n); cout << “n = ” << n << endl; // n = 0 |
以下是“指针传递”的示例程序。由于 Func2 函数体内的 x 是指向外部变量 n 的指针,改变该指针的内容将导致 n 的值改变,所以 n 的值成为 10。
|
1
2
3
4
5
6
7
8
|
void Func2(int *x) { (* x) = (* x) + 10; } … int n = 0; Func2(&n); cout << “n = ” << n << endl; // n = 10 |
以下是“引用传递”的示例程序。由于 Func3 函数体内的 x 是外部变量 n 的引用,x 和 n 是同一个东西,改变 x 等于改变 n,所以 n 的值成为 10。
|
1
2
3
4
5
6
7
8
|
void Func3(int &x) { x = x + 10; } … int n = 0; Func3(n); cout << “n = ” << n << endl; // n = 10 |
对比上述三个示例程序,会发现“引用传递”的性质象“指针传递” ,而书写方式象“值传递” 。实际上“引用”可以做的任何事情“指针”也都能够做,为什么还要“引用”这东西?
答案是“用适当的工具做恰如其分的工作” 。
指针能够毫无约束地操作内存中的如何东西,尽管指针功能强大,但是非常危险。就象一把刀,它可以用来砍树、裁纸、修指甲、理发等等,谁敢这样用?
如果的确只需要借用一下某个对象的“别名” ,那么就用“引用” ,而不要用“指针” ,以免发生意外。比如说,某人需要一份证明,本来在文件上盖上公章的印子就行了,如果把取公章的钥匙交给他,那么他就获得了不该有的权利。
让C程序更高效的10种方法 - 博客 - 伯乐在线 (2013/2/27 10:12:10)
让C程序更高效的10种方法
代码之美,不仅在于为一个给定问题找到解决方案,而且还在代码的简单性、有效性、紧凑性和效率(内存)。代码设计比实际执行更难 。因此,每一个程序员当用C语言编程时,都应该记着这些东西。本文向你介绍规范你的C代码的10种方法。
0. 避免不必要的函数调用
考虑下面的2个函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
void str_print( char *str ) { int i; for ( i = 0; i < strlen ( str ); i++ ) { printf("%c",str[ i ] ); } } void str_print1 ( char *str ) { int len; len = strlen ( str ); for ( i = 0; i < len; i++ ) { printf("%c",str[ i ] ); } } |
请注意 这两个函数的功能相似。然而,第一个函数调用strlen()函数多次,而第二个函数只调用函数strlen()一次。因此第二个函数性能明显比第一个好。
1、避免不必要的内存引用
这次我们再用2个例子来对比解释:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
int multiply ( int *num1 , int *num2 ) { *num1 = *num2; *num1 += *num2; return *num1; } int multiply1 ( int *num1 , int *num2 ) { *num1 = 2 * *num2; return *num1; } |
同样,这两个函数具有类似的功能。所不同的是在第一个函数( 1 for reading *num1 , 2 for reading *num2 and 2 for writing to *num1)有5个内存的引用,而在第二个函数是只有2个内存引用(one for reading *num2 and one for writing to *num1)。现在你认为哪一个好些?
2、节约内存(内存对齐和填充的概念)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
struct { char c; int i; short s; }str_1; struct { char c; short s; int i; }str_2; |
假设一个字符需要1个字节,short占用2个字节和int需要4字节的内存。起初,我们会认为上面定义的结构是相同的,因此占据相同数量的内存。然而,而str_1占用12个字节,第二个结构只需要8个字节?这怎么可能呢?
请注意,在第一个结构,3个不同的4个字节被分配到三种数据类型,而在第二个结构的前4个自己char和short可以被采用,int可以采纳在第二个的4个字节边界(一共8个字节)。
3、使用无符号整数,而不是整数的,如果你知道的值将永远是否定的。
有些处理器可以处理无符号的整数比有符号整数的运算速度要快。(这也是很好的实践,帮助self-documenting代码)。
4、在一个逻辑条件语句中常数项永远在左侧。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
int x = 4; if ( x = 1 ) { x = x + 2; printf("%d",x); // Output is 3 } int x = 4; if ( 1 = x ) { x = x + 2; printf("%d",x); // Compilation error } |
使用“=”赋值运算符,替代“==”相等运算符,这是个常见的输入错误。 常数项放在左侧,将产生一个编译时错误,让你轻松捕获你的错误。注:“=”是赋值运算符。 b = 1会设置变量b等于值1。 “==”相等运算符。如果左侧等于右侧,返回true,否则返回false。
5、在可能的情况下使用typedef替代macro。当然有时候你无法避免macro,但是typedef更好。
|
1
2
3
4
5
6
7
|
typedef int* INT_PTR; INT_PTR a , b; # define INT_PTR int*; INT_PTR a , b; |
在这个宏定义中,a是一个指向整数的指针,而b是只有一个整数声明。使用typedef a和b都是 整数的指针。
6、确保声明和定义是静态的,除非您希望从不同的文件中调用该函数。
在同一文件函数对其他函数可见,才称之为静态函数。它限制其他访问内部函数,如果我们希望从外界隐藏该函数。现在我们并不需要为内部函数创建头文件,其他看不到该函数。
静态声明一个函数的优点包括:
- A)两个或两个以上具有相同名称的静态函数,可用于在不同的文件。
- B)编译消耗减少,因为没有外部符号处理。
让我们做更好的理解,下面的例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
/*first_file.c*/ static int foo ( int a ) { /*Whatever you want to in the function*/ } /*second_file.c*/ int foo ( int ) int main() { foo(); // This is not a valid function call as the function foo can only be called by any other function within first_file.c where it is defined. return 0; } |
7、使用Memoization,以避免递归重复计算
考虑Fibonacci(斐波那契)问题;
Fibonacci问题是可以通过简单的递归方法来解决:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
int fib ( n ) { if ( n == 0 || n == 1 ) { return 1; } else { return fib( n - 2 ) + fib ( n - 1 ); } } |
注:在这里,我们考虑Fibonacci 系列从1开始,因此,该系列看起来:1,1,2,3,5,8,...

注意:从递归树,我们计算fib(3)函数2次,fib(2)函数3次。这是相同函数的重复计算。如果n非常大,fib
这个简单的技术叫做Memoization,可以被用在递归,加强计算速度。
fibonacci 函数Memoization的代码,应该是下面的这个样子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
int calc_fib ( int n ) { int val[ n ] , i; for ( i = 0; i <=n; i++ ) { val[ i ] = -1; // Value of the first n + 1 terms of the fibonacci terms set to -1 } val[ 0 ] = 1; // Value of fib ( 0 ) is set to 1 val[ 1 ] = 1; // Value of fib ( 1 ) is set to 1 return fib( n , val ); } int fib( int n , int* value ) { if ( value[ n ] != -1 ) { return value[ n ]; // Using memoization } else { value[ n ] = fib( n - 2 , value ) + fib ( n - 1 , value ); // Computing the fibonacci term } return value[ n ]; // Returning the value } |
这里calc_fib( n )函数被main()调用。
8、避免悬空指针和野指针
一个指针的指向对象已被删除,那么就成了悬空指针。野指针是那些未初始化的指针,需要注意的是野指针不指向任何特定的内存位置。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
void dangling_example() { int *dp = malloc ( sizeof ( int )); /*........*/ free( dp ); // dp is now a dangling pointer dp = NULL; // dp is no longer a dangling pointer } void wild_example() { int *ptr; // Uninitialized pointer printf("%u"\n",ptr ); printf("%d",*ptr ); } |
当遭遇这些指针,程序通常是”怪异“的表现。
9、 永远记住释放你分配给程序的任何内存。上面的例子就是如果释放dp指针(我们使用malloc()函数调用)。
原文:fortystones 译文:oschina

.t_login_text {margin:0; padding:0;}.t_login_button {margin:0; padding: 5px 0;}.t_login_button a{margin:0; padding-right:4px; line-height:15px}.t_login_button img{display:inline; border:none;}
C语言指针5分钟教程
英文原文: Dennis Kubes,编译:伯乐在线 – 唐尤华
指针、引用和取值
什么是指针?什么是内存地址?什么叫做指针的取值?指针是一个存储计算机内存地址的变量。在这份教程里“引用”表示计算机内存地址。从指针指向的内存读取数据称作指针的取值。指针可以指向某些具体类型的变量地址,例如int、long和double。指针也可以是void类型、NULL指针和未初始化指针。本文会对上述所有指针类型进行探讨。
根据出现的位置不同,操作符 * 既可以用来声明一个指针变量,也可以用作指针的取值。当用在声明一个变量时,*表示这里声明了一个指针。其它情况用到*表示指针的取值。
&是地址操作符,用来引用一个内存地址。通过在变量名字前使用&操作符,我们可以得到该变量的内存地址。
|
1
2
3
4
5
6
7
8
9
|
// 声明一个int指针 int *ptr; // 声明一个int值 int val = 1; // 为指针分配一个int值的引用 ptr = &val; // 对指针进行取值,打印存储在指针地址中的内容 int deref = *ptr; printf("%d\n", deref); |
第2行,我们通过*操作符声明了一个int指针。接着我们声明了一个int变量并赋值为1。然后我们用int变量的地址初始化我们的int指针。接下来对int指针取值,用变量的内存地址初始化int指针。最终,我们打印输出变量值,内容为1。
第6行的&val是一个引用。在val变量声明并初始化内存之后,通过在变量名之前使用地址操作符&我们可以直接引用变量的内存地址。
第8行,我们再一次使用*操作符来对该指针取值,可直接获得指针指向的内存地址中的数据。由于指针声明的类型是int,所以取到的值是指针指向的内存地址存储的int值。
这里可以把指针、引用和值的关系类比为信封、邮箱地址和房子。一个指针就好像是一个信封,我们可以在上面填写邮寄地址。一个引用(地址)就像是一个邮件地址,它是实际的地址。取值就像是地址对应的房子。我们可以把信封上的地址擦掉,写上另外一个我们想要的地址,但这个行为对房子没有任何影响。

void指针、NULL指针和未初始化指针
一个指针可以被声明为void类型,比如void *x。一个指针可以被赋值为NULL。一个指针变量声明之后但没有被赋值,叫做未初始化指针。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
int *uninit; // int指针未初始化 int *nullptr = NULL; // 初始化为NULL void *vptr; // void指针未初始化 int val = 1; int *iptr; int *castptr; // void类型可以存储任意类型的指针或引用 iptr = &val; vptr = iptr; printf("iptr=%p, vptr=%p\n", iptr, vptr); // 通过显示转换,我们可以把一个void指针转成 // int指针并进行取值 castptr = (int *)vptr; printf("*castptr=%d\n", *castptr); // 打印null和未初始化指针 printf("uninit=%p, nullptr=%p\n", uninit, nullptr); // 不知道你会得到怎样的返回值,会是随机的垃圾地址吗? // printf("*nullptr=%d\n", nullptr); // 这里会产生一个段错误 // printf("*nullptr=%d\n", nullptr); |
执行上面的代码,你会得到类似下面对应不同内存地址的输出。
|
1
2
3
|
iptr=0x7fff94b89c6c, vptr=0x7fff94b89c6c *castptr=1 uninit=0x7fff94b89d50, nullptr=(nil) |
第1行我们声明了一个未初始化int指针。所有的指针在赋值为NULL、一个引用(地址)或者另一个指针之前都是未被初始化的。第2行我们声明了一个NULL指针。第3行声明了一个void指针。第4行到第6行声明了一个int值和几个int指针。
第9行到11行,我们为int指针赋值为一个引用并把int指针赋值为void指针。void指针可以保存各种其它指针类型。大多数时候它们被用来存储数据结构。可以注意到,第11行我们打印了int和void指针的地址。它们现在指向了同样的内存地址。所有的指针都存储了内存地址。它们的类型只在取值时起作用。
第15到16行,我们把void指针转换为int指针castptr。请注意这里需要显示转换。虽然C语言并不要求显示地转换,但这样会增加代码的可读性。接着我们对castptr指针取值,值为1。
第19行非常有意思,在这里打印未初始化指针和NULL指针。值得注意的是,未初始化指针是有内存地址的,而且是一个垃圾地址。不知道这个内存地址指向的值是什么。这就是为什么不要对未初始化指针取值的原因。最好的情况是你取到的是垃圾地址接下来你需要对程序进行调试,最坏的情况则会导致程序崩溃。
NULL指针被初始化为o。NULL是一个特殊的地址,用NULL赋值的指针指向的地址为0而不是随机的地址。只有当你准备使用这个地址时有效。不要对NULL地址取值,否则会产生段错误。
指针和数组
C语言的数组表示一段连续的内存空间,用来存储多个特定类型的对象。与之相反,指针用来存储单个内存地址。数组和指针不是同一种结构因此不可以互相转换。而数组变量指向了数组的第一个元素的内存地址。
一个数组变量是一个常量。即使指针变量指向同样的地址或者一个不同的数组,也不能把指针赋值给数组变量。也不可以将一个数组变量赋值给另一个数组。然而,可以把一个数组变量赋值给指针,这一点似乎让人感到费解。把数组变量赋值给指针时,实际上是把指向数组第一个元素的地址赋给指针。
|
1
2
3
4
5
6
7
8
|
int myarray[4] = {1,2,3,0}; int *ptr = myarray; printf("*ptr=%d\n", *ptr); // 数组变量是常量,不能做下面的赋值 // myarray = ptr // myarray = myarray2 // myarray = &myarray2[0] |
第1行初始化了一个int数组,第2行用数组变量初始化了一个int指针。由于数组变量实际上是第一个元素的地址,因此我们可以把这个地址赋值给指针。这个赋值与*ptr = &myarray[0]效果相同,显示地把数组的第一个元素地址赋值到了ptr引用。这里需要注意的是,这里指针需要和数组的元素类型保持一致,除非指针类型为void。
指针与结构体
就像数组一样,指向结构体的指针存储了结构体第一个元素的内存地址。与数组指针一样,结构体的指针必须声明和结构体类型保持一致,或者声明为void类型。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
struct person { int age; char *name; }; struct person first; struct person *ptr; first.age = 21; char *fullname = "full name"; first.name = fullname; ptr = &first; printf("age=%d, name=%s\n", first.age, ptr->name); |
第1至6行声明了一个person结构体,一个变量指向了一个person结构体和指向person结构体的指针。第8行为age成员赋了一个int值。第9至10行我们声明了一个char指针并赋值给一个char数组并赋值给结构体name成员。第11行我们把一个person结构体引用赋值给结构体变量。
第13行我们打印了结构体实例的age和name。这里需要注意两个不同的符号,’.’ 和 ‘->’ 。结构体实例可以通过使用 ‘.’ 符号访问age变量。对于结构体实例的指针,我们可以通过 ‘->’ 符号访问name变量。也可以同样通过(*ptr).name来访问name变量。
总结
希望这份简短的概述能够有助于了解不同的指针类型。在后续的博文中我们会探讨其它类型的指针和高级用法,比如函数指针。
欢迎提出提问并给出评论。
英文原文: Dennis Kubes 编译:伯乐在线 – 唐尤华
【如需转载,请标注并保留原文链接、译文链接和译者等信息,谢谢合作!】
C语言深度剖析 (2013/2/27 9:36:09)
.selectTdClass{background-color:#3399FF !important;}table.noBorderTable td{border:1px dashed #ddd !important}table{clear:both;margin-bottom:10px;border-collapse:collapse;word-break:break-all;}.pagebreak{display:block;clear:both !important;cursor:default !important;width: 100% !important;margin:0;}.anchorclass{background: url("") no-repeat scroll left center transparent;border: 1px dotted #0000FF;cursor: auto;display: inline-block;height: 16px;width: 15px;}.view{padding:0;word-wrap:break-word;cursor:text;height:100%;}
body{margin:8px;font-family:'微软雅黑, sans-serif';font-size:18px;}li{clear:both}p{margin:0;}body{background-color:#ffffff;background-image:;background-repeat:repeat;background-position:0% 0%;height:442px;}
.selectTdClass{background-color:#3399FF !important;}table.noBorderTable td{border:1px dashed #ddd !important}table{clear:both;margin-bottom:10px;border-collapse:collapse;word-break:break-all;}.pagebreak{display:block;clear:both !important;cursor:default !important;width: 100% !important;margin:0;}.anchorclass{background: url("") no-repeat scroll left center transparent;border: 1px dotted #0000FF;cursor: auto;display: inline-block;height: 16px;width: 15px;}.view{padding:0;word-wrap:break-word;cursor:text;height:100%;}
body{margin:8px;font-family:'微软雅黑, sans-serif';font-size:18px;}li{clear:both}p{margin:0;}body{background-color:#ffffff;background-image:;background-repeat:repeat;background-position:0% 0%;height:481px;}
定义声明最重要的区别:定义创建了对象并为这个对象分配了内存,声明没有分配内存。
register:寄存器变量,请求编译器将变量尽可能的将变量存放在CPU内部寄存器中而提高访问效率。
寄存器其实就是一块一块小的存储空间,只不过其存取速度比内存快。
register 变量必须是能被 CPU 寄存器所接受的类型。意味着 register 变量必须是一个单个的值,并且其长度应小于或等于整型的长度。 而且
register 变量可能不存放在内存中,所以不能用取址运算符“&”来获取 register 变量的地址。
static
的作用:第一修饰变量,变量分为局部变量和全局变量,它们都在内存的静态区。
静态全局变量,作用域仅限于变量被定义的文件中,其他文件即使用 extern 声明也没法使用他。准确地说作用域是从定义之处开始,到文件结尾处结束,在定义之处前面的那些代码行也不能使用它。想要使用就得在前面再加
extern ***。恶心吧?要想不恶心,很简单,直接在文件顶端定义不就得了。
静态局部变量,在函数体里面定义的,就只能在这个函数里用了,同一个文档中的其他
函数也用不了。由于被 static
修饰的变量总是存在内存的静态区,所以即使这个函数运行结束,这个静态变量的值还是不会被销毁,函数下次使用时仍然能用到这个值。
第二修饰函数,函数前加 static使得函数成为静态函数。但此处“static”的含义不是指存储方式,而是指对函数的作用域仅局限于本文件(所以又称内部函数)。使用内部函数的好处是:不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名。
sizeof在计算变量所占空间大小时,括号可以省略,而计算类型大小时不能省略。
#include <stdio.h>
#include <string.h>
int main(int argc, char const *argv[])
{
char a[1000];
int i;
for(i = 0; i < 1000; i++){
a[i] = -1-i;
}
printf("%d\n",strlen(a));
return 0;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
按照我们上面的解释,那-0 和+0在内存里面分别怎么存储?int i = unsigned j = 10;i+j的值为多少?为什么?下面的代码有什么问题?unsigned i ;for (i=9;i>=0;i--){ printf("%u\n",i);} |
bool变量与“零值”进行比较
bool bTestFlag = FALSE;
if(bTestFlag);
if(!bTestFlag);
float变量与“零值”进行比较
float fTestVal = 0.0;
if((fTestVal >= -EPSINON) && (fTestVal <= EPSINON)); //EPSINON
为定义好的
精度。
指针变量与“零值”进行比较
int*p=NULL;
if(NULL == p);
if(NULL != p);
if、else一般表示两个分支或是嵌套表示少量的分支,但如果分支很多的话……还是用switch、case组合吧。
每个case 语句的结尾绝对不要忘了加 break,否则将导致多个分支重叠(除非有意使多个分支重叠)。
最后必须使用default 分支。即使程序真的不需要 default 处理,也应该保留语句:
default :
break;
这样做并非画蛇添足,可以避免让人误以为你忘了 default处理。
case 后面只能是整型或字符型的常量或常量表达式(想想字符型数据在内存里是怎么存的)
。
case语句的排列顺序:
按字母或数字顺序排列各条case语句。
把正常情况放在前面,而把异常情况放在后面。
按执行频率排列case语句。
把default子句只用于检查真正的默认情况。
在 switch case 语句中能否使用
continue关键字?为什么?
循环语句的注意点
在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少 CPU 跨切循环层的次数。
建议for 语句的循环控制变量的取值采用“半开半闭区间”写法。
不能在for循环体内修改循环变量,防止循环失控。
循环要尽可能的短,要使代码清晰,一目了然。
把循环嵌套控制在3 层以内。
void真正发挥的作用在于:
(1) 对函数返回的限定;
(2) 对函数参数的限定。
任何类型的指针都可以直接赋值给它,无需进行强制类型转换。
void修饰函数返回值和参数
如果函数没有返回值,那么应声明为 void类型。
如果函数无参数,那么应声明其参数为void。
无论在 C
还是C++中,若函数不接受任何参数,一定要指明参数为 void。
void指针
不能对
void指针进行算法操作。是因为它坚持:进行算法操作的指针必须是确定知道其指向数据类型大小的。也就是说必须知道内存目的地址的确切值。但是大名鼎鼎的
GNU(GNU's Not Unix的递归缩写)则不这么认定,它指定 void *的算法操作与 char *一致。
如果函数的参数可以是任意类型指针,那么应声明其参数为void *。
void不能代表一个真实的变量。
void体现了一种抽象,这个世界上的变量都是“有类型”的。
return用来终止一个函数并返回其后面跟着的值。
return 语句不可返回指向“栈内存”的“指针” ,因为该内存在函数体结束时被自动销毁。
定义 const只读变量,具有不可变性。
const修饰的只读变量必须在定义的同时初始化。
编译器通常不为普通
const只读变量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的值,没有了存储与读内存的操作,使得它的效率也很高。
const定义的只读变量在程序运行过程中只有一份拷贝(因为它是全局的只读变量,存放在静态区)
,而#define定义的宏常量在内存中有若干个拷贝。#define宏是在预编译阶段进行替换,而
const修饰的只读变量是在编译的时候确定其值。#define宏没有类型,而 const修饰的只读变量具有特定的类型。
const修饰的只读变量不能用来作为定义数组的维数,也不能放在 case关键字后面。
修饰一般变量
这种只读变量在定义时,修饰符 const可以用在类型说明符前,也可以用在类型说明符后。例如:int const i=2; 或 const int
i=2;修饰数组
定义或说明一个只读数组可采用如下格式:int const a[5]={1, 2, 3, 4, 5};或const int a[5]={1, 2, 3,
4, 5};修饰指针
const int *p; // p 可变,p指向的对象不可变
int const *p; // p可变,p指向的对象不可变
int*constp; //p不可变,p指向的对象可变
const int *const p; //指针 p和 p指向的对象都不可变
先忽略类型名,看
const离哪个近,离谁近就修饰谁。
const int *p;
//const修饰*p,p是指针,*p是指针指向的对象,不可变
int const
*p;//const修饰*p,p是指针,*p是指针指向的对象,不可变
int *const p;//const修饰
p,p不可变,p 指向的对象可变
const int *const p; //前一个
const修饰*p,后一个 const修饰p,指针 p和 p 指向的对象都不可变
修饰函数的参数
const修饰符也可以修饰函数的参数,当不希望这个参数值被函数体内意外改变时使用。例如:void Fun(const int
i);告诉编译器i在函数体中的不能改变, 从而防止了使用者的一些无意的或错误的修改。修饰函数的返回值
const修饰符也可以修饰函数的返回值,返回值不可被改变。例如:const int Fun (void);
最易变的关键字----volatile
用它修饰的变量表示可以被某些编译器,未知的因素更改,比如操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
最会带帽子的关键字----extern
extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中。
struct 关键字
结构体所占的内存大小是其成员所占内存之和,空结构体的大小就定位 1 个byte。
struct与 class的区别
在 C++里 struct关键字与 class关键字一般可以通用,只有一个很小的区别。struct的成员默认情况下属性是
public的,而class成员却是 private的。
在union中所有的数据成员共用一个空间,同一时间只能储存其中一个数据成员,所有的数据成员具有相同的起始地址。
一个 union只配置一个足够大的空间以来容纳最大长度的数据成员。
大端模式和小端模式。
大端模式(Big_endian) :字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端模式(Little_endian) :字数据的高字节存储在高地址中,而字数据的低字节则存放在低地址中。
union型数据所占的空间等于其最大的成员所占的空间。
对 union型的成员的存取都是相对于该联合体基地址的偏移量为 0 处开始, 也就是联合体的访问不论对哪个变量的存取都是从
union的首地址位置开始。
请写一个 C 函数,若处理器是Big_endian的,则返回 0;若是Little_endian的,则返回 1。
利用 union类型数据的特点:所有成员的起始地址一致。
枚举与#define宏的区别
#define宏常量是在预编译阶段进行简单替换。枚举常量则是在编译的时候确定其值。
一般在编译器里,可以调试枚举常量,但是不能调试宏常量。
枚举可以一次定义大量相关的常量,而#define宏一次只能定义一个。
注释的使用规则
y=x/*p 表示把x赋值给y,同时注释开始
y=x/(*p) 表示把x除以 p 指向的内存里的值,把结果赋值为 y
0。
1,最高位是补0 或是补1 取决于编译系统的规定。TurboC和很多系统规定为补 1。









4字节对齐,这时就按4 字节对齐,所以sizeof(TestStruct4)应该为 8;
个字节,它按什么对齐呢?对于结构来说,它的默认对齐方式就是它的所有成员使用的对齐参数中最大的一个,TestStruct4的就是4.所以,成员d就是按4字节对齐.成员e是8个字节,它是默认按8字节对齐,和指定的一样,所以它对到8字节的边界上,这时,已经使用了12个字节了,所以又添加了
4 个字节的空,从第 16个字节开始放置成员 e.这时,长度为24,已经可以被 8(成员 e按 8字节对齐)整除.这样,一共使用了 24个字节.内存布局如下
(*表示空闲内存, 1表示使用内存。单位为 1byete) :
a b
c TestStruct4.a TestStruct4.b
d
1111,****, 11111111


指针和数组
byte,其值为某一个内存的地址。指针可以指向任何地方,但是不是任何地方你都能通过这个指针变量访问到。
byte,这块内存也没有名字。对这块内存的访问完全是匿名的访问。比如现在需要读取字符‘e’ ,我们有两种方式:
0x0000FF04。然后取出 0x0000FF04地址上的值。
p里存储的地址值,然后加上中括号中
4个元素的偏移量,计算出新的地址,然后从新的地址中取出值。也就是说以下标的形式访问在本质上与以指针的形式访问没有区别,只是写法上不同罢了。
a找到数组首元素的首地址,然后根据偏移量找到相应的值。这是一种典型的“具名+匿名”访问。比如现在需要读取字符‘5’ ,我们有两种方式:
0x0000FF04。然后取出 0x0000FF04地址上的值。
4个元素的偏移量,计算出新的地址,然后从新的地址中取出值。
XXX的形式的访问”这种表达方式。另外一个需要强调的是:上面所说的偏移量 4 代表的是4 个元素,而不是 4 个byte。只不过这里刚好是 char类型数据
1个字符的大小就为 1个 byte。记住这个偏移量的单位是元素的个数而不是
byte数,在计算新地址时千万别弄错了。

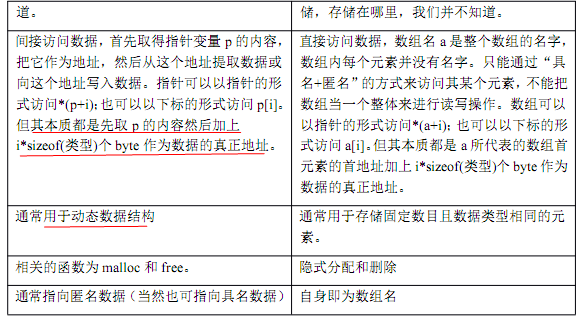
4个字节,至于它指向的数组占多少字节,不知道。它是“指向数组的指针”的简称。
p1,int*修饰的是数组的内容,即数组的每个元素。那现在我们清楚,这是一个数组,其包含 10个指向 int类型数据的指针,即指针数组。至于
p2就更好理解了,在这里“ () ”的优先级比“[]”高, “*”号和 p2构成一个指针的定义,指针变量名为
p2,int修饰的是数组的内容,即数组的每个元素。数组在这里并没有名字,是个匿名数组。那现在我们清楚 p2是一个指针,它指向一个包含 10个
int类型数据的数组,即数组指针。
数组指针(也称行指针)
定义
int (*p)[n];
()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。
如要将二维数组赋给一指针,应这样赋值:
int
a[3][4];
int
(*p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a;
//将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++;
//该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
所以数组指针也称指向一维数组的指针,亦称行指针。
指针数组
定义
int *p[n];
[]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1是错误的,这样赋值也是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样
*p=a; 这里*p表示指针数组第一个元素的值,a的首地址的值。
如要将二维数组赋给一指针数组:
int
*p[3];
int
a[3][4];
for(i=0;i<3;i++)
p[i]=a[i];
这里int
*p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2]
所以要分别赋值。
这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。
还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。
比如要表示数组中i行j列一个元素:
*(p[i]+j)、*(*(p+i)+j)、(*(p+i))[j]、p[i][j]
优先级:()>[]>*
。
int类型数据的指针。
(int)Function;表示将函数的入口地址赋值给指针变量 p。
静态区:保存自动全局变量和 static变量(包括 static全局和局部变量)
。静态区的内容在总个程序的生命周期内都存在,由编译器在编译的时候分配。栈:保存局部变量。栈上的内容只在函数的范围内存在,当函数运行结束,这些内容也会自动被销毁。其特点是效率高,但空间大小有限。
堆:由 malloc系列函数或 new操作符分配的内存。其生命周期由 free或
delete决定。在没有释放之前一直存在,直到程序结束。其特点是使用灵活,空间比较大,但容易出错。
语句不可返回指向“栈内存”的“指针”,因为该内存在函数体结束时被自动销毁。
assert(NULL!=strDest);
return('\0'!=*strDest)?(1+my_strlen(strDest+1)):0;
文件操作 (2013/2/26 15:07:24)













数据链表与内存分配 (2013/2/26 14:50:13)





链表




结构体,共用体 (2013/2/26 12:24:47)








位运算



字符与字符串 (2013/2/25 21:49:09)





指针 (2013/2/25 21:13:44)








数组名是数组的首地址是一个常量
数组的名称是首地址,但是是常量地址,不能改变,不能赋值;
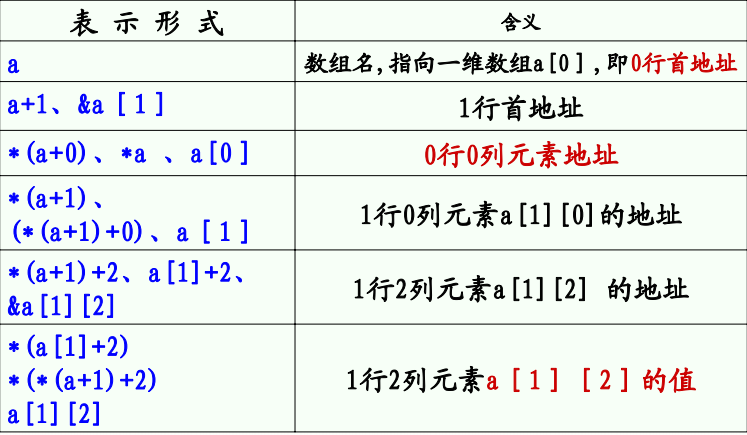




 指针相关运算总结
指针相关运算总结





C基础 (2013/2/25 20:37:39)



auto: 花括号内的都是auto型变量,局部变量,现在很少使用,都是缺省了
extern:具有外部变量链接;如果在别的文件中定义了变量如:int ER; 在其他的文件中要使用它,可以用extern int ER;此时的ER变量和前面保持一致;如果在其他文件中去掉extern,如:int ER;此ER为局部变量和前面完全不同。
register: 寄存器变量,寄存器变量比内存变读取速度更快,但是寄存器变量资源有限,不能存放太多变量和太大变量比如:double型.
static:静态变量,从第一次调用的时候初始化一次,然后在域没消失前,数据不会初始化;数据会常驻内存,一直到程序结束。
const:把变量声明转换成常量的声明;所谓转换成常量并不是真的变成了常量,只是把变量设置成只读变量;
例如:const int num;//把num转换成只读变量
num=12;//不允许写入,只能读;即会错误提示
const int num=12;//允许在定义阶段初始化。
sizeof:返回一个类型或变量的字节数;例如:char a[]="asdfs";sizeof(a)=5;注意这里的/0不会计算在内;
volatile:告诉编译器定义的变量是一个常改变的值;使得在编译器优化的时候把变量读入缓存的问题;
volatile的作用: 作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值.
auto: 花括号内的都是auto型变量,局部变量,现在很少使用,都是缺省了
extern:具有外部变量链接;如果在别的文件中定义了变量如:int ER; 在其他的文件中要使用它,可以用extern int ER;此时的ER变量和前面保持一致;如果在其他文件中去掉extern,如:int ER;此ER为局部变量和前面完全不同。
register: 寄存器变量,寄存器变量比内存变读取速度更快,但是寄存器变量资源有限,不能存放太多变量和太大变量比如:double型.
static:静态变量,从第一次调用的时候初始化一次,然后在域没消失前,数据不会初始化;数据会常驻内存,一直到程序结束。
const:把变量声明转换成常量的声明;所谓转换成常量并不是真的变成了常量,只是把变量设置成只读变量;
例如:const int num;//把num转换成只读变量
num=12;//不允许写入,只能读;即会错误提示
const int num=12;//允许在定义阶段初始化。
sizeof:返回一个类型或变量的字节数;例如:char a[]="asdfs";sizeof(a)=5;注意这里的/0不会计算在内;
volatile:告诉编译器定义的变量是一个常改变的值;使得在编译器优化的时候把变量读入缓存的问题;
volatile的作用: 作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值.






















.fluid-width-video-wrapper { width: 100%; position: relative; padding: 0; } .fluid-width-video-wrapper iframe, .fluid-width-video-wrapper object, .fluid-width-video-wrapper embed { position: absolute; top: 0; left: 0; width: 100%; height: 100%; }
.ckrating_highly_rated {background-color:#FFFFCC !important;}
.ckrating_poorly_rated {opacity:0.6;filter:alpha(opacity=60) !important;}
.ckrating_hotly_debated {background-color:#FFF0F5 !important;}
#wp-admin-bar-user-info .avatar-64 {width:64px}
.syntaxhighlighter,
.syntaxhighlighter a,
.syntaxhighlighter div,
.syntaxhighlighter code,
.syntaxhighlighter table,
.syntaxhighlighter table td,
.syntaxhighlighter table tr,
.syntaxhighlighter table tbody,
.syntaxhighlighter table thead,
.syntaxhighlighter table caption,
.syntaxhighlighter textarea {
font-size: 12px !important;
font-family: "Consolas", "Bitstream Vera Sans Mono", "Courier New", Courier, monospace !important;
}
.syntaxhighlighter table caption {
font-size: 14px !important;
font-family: "Consolas", "Bitstream Vera Sans Mono", "Courier New", Courier, monospace !important;
}
.syntaxhighlighter.nogutter td.code .line {
padding-left: 3px !important;
}
.syntaxhighlighter {
overflow-y: hidden !important;
padding: 1px !important;
}
.widget-area.syntaxhighlighter a,
.widget-area.syntaxhighlighter div,
.widget-area.syntaxhighlighter code,
.widget-area.syntaxhighlighter table,
.widget-area.syntaxhighlighter table td,
.widget-area.syntaxhighlighter table tr,
.widget-area.syntaxhighlighter table tbody,
.widget-area.syntaxhighlighter table thead,
.widget-area.syntaxhighlighter table caption,
.widget-area.syntaxhighlighter textarea {
font-size: 14px !important;
font-family: "Consolas", "Bitstream Vera Sans Mono", "Courier New", Courier, monospace !important;
}
.widget-area table caption {
font-size: 10px !important;
font-family: "Consolas", "Bitstream Vera Sans Mono", "Courier New", Courier, monospace !important;
}
*::selection { background: #0099cc; }
*::-moz-selection { background: #0099cc; }
body { background: #ffffff }
a, .tabs ul.nav li a:hover, .tabs ul.nav li.active a, .dropcap, .toggle.hover .toggle-title, li.comment cite a:hover, h3.widget-title, .post-meta .meta-title:hover, .the-latest a:hover h4, .aw_socialcounter_widget li a:hover, .aw_tabbed_widget #tab-latest-comments a:hover { color: #0099cc; }
a:hover { color: #b30000; }
input:focus, textarea:focus { border-color: #0099cc; }
#searchsubmit, .highlight, .aw_tabbed_widget .tabs ul.nav li.active a, footer .aw_tabbed_widget .tabs ul.nav li.active a, #top .aw_tabbed_widget .tabs ul.nav li.active a, .aw_tabbed_widget .tabs ul.nav li a:hover, footer .aw_tabbed_widget .tabs ul.nav li a:hover, #top .aw_tabbed_widget .tabs ul.nav li a:hover, .aw_twitter_widget .twitter-icon, .testimonial-icon, #top-closed:hover, .flex-control-nav a:hover, .flex-control-nav a.flex-active { background-color: #0099cc; }
.submit { background-color: #0099cc; border-color: #007399; }
.submit:hover { background-color: #b30000; border-color: #860000; }
#searchsubmit:hover { background-color: #b30000; }
.toggle.hover .toggle-icon { border-top-color: #0099cc; }
.toggle.hover.active .toggle-icon { border-bottom-color: #0099cc; }
.flex-direction-nav li .flex-prev:hover { border-right-color: #0099cc; }
.flex-direction-nav li .flex-next:hover { border-left-color: #0099cc; }
@media only screen and (min-width: 768px) and (max-width: 959px) {
.aw_tabbed_widget .tabs ul.nav li a:hover, .tabs ul.nav li.active a { color: #0099cc; }
}
@media screen and (max-width: 767px) {
.tabs ul.nav li a:hover, .tabs ul.nav li.active a { color: #0099cc; }
}
@media Print
{
.gmnoprint {
DISPLAY: none
}
}
@media Screen
{
.gmnoscreen {
DISPLAY: none
}
}
.t_login_text {margin:0; padding:0;}.t_login_button {margin:0; padding: 5px 0;}.t_login_button a{margin:0; padding-right:4px; line-height:15px}.t_login_button img{display:inline; border:none;}
附件列表
笔记整理--C语言的更多相关文章
- 笔记整理——C语言-http-1
http 传输原理及格式 - friping - ITeye技术网站 - Google Chrome (2013/4/1 14:02:36) http 传输原理及格式 博客分类: 其他 应用服务器浏览 ...
- 笔记整理——C语言-http
C语言 HTTP GZIP数据解压 - 大烧饼的实验室 - 博客园 - Google Chrome (2013/4/10 18:22:26) C语言 HTTP GZIP数据解压 这个代码在http ...
- golang学习笔记13 Golang 类型转换整理 go语言string、int、int64、float64、complex 互相转换
golang学习笔记13 Golang 类型转换整理 go语言string.int.int64.float64.complex 互相转换 #string到intint,err:=strconv.Ato ...
- 从0开始学Swift笔记整理(五)
这是跟在上一篇博文后续内容: --Core Foundation框架 Core Foundation框架是苹果公司提供一套概念来源于Foundation框架,编程接口面向C语言风格的API.虽然在Sw ...
- Deep Learning(深度学习)学习笔记整理系列之(七)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(二)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- java笔记整理
Java 笔记整理 包含内容 Unix Java 基础, 数据库(Oracle jdbc Hibernate pl/sql), web, JSP, Struts, Ajax Spring, E ...
- Spring:笔记整理(1)——HelloWorld
Spring:笔记整理(1)——HelloWorld 导入JAR包: 核心Jar包 Jar包解释 Spring-core 这个jar 文件包含Spring 框架基本的核心工具类.Spring 其它组件 ...
- 最全mysql笔记整理
mysql笔记整理 作者:python技术人 博客:https://www.cnblogs.com/lpdeboke Windows服务 -- 启动MySQL net start mysql -- 创 ...
随机推荐
- Java排序方法sort的使用详解
对数组的排序: //对数组排序 public void arraySort(){ int[] arr = {1,4,6,333,8,2}; Arrays.sort(arr);//使用java.util ...
- 2016 ACM/ICPC Asia Regional Qingdao Online 1002 Cure
Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submission( ...
- TypeScript -- 面向对象特性
.class关键字和类名就可以定义一个类 . 类的访问控制符--有三个,.] = ] = ] = ;.声明参数 .用接口声明方法 .理解模块--一个文件就是一个模块,就是这么个意思 ,不用想的多么高大 ...
- InnoDB与MyISAM引擎区别
mysql中InnoDB与MyISAM两种数据库引擎的区别: 一.InnoDB引擎: 1.支持事务性, 2.支持外部键, 3.行级锁, 4.不保存表的具体行数,执行select count(*) fr ...
- RedisDesktopManager
下载地址: https://github.com/uglide/RedisDesktopManager/releases
- DHCP源码分析--主流程
DHCP 服务器,客户端代码都采用了统一的事件轮询(event loop),包含了任务处理消息,定时器消息,socke收发消息等等. static struct { isc_appmethods_t ...
- js onblur 和 onkeyup 事件用法
1. onblur 表示失去焦点时触发 2. onkeyup 表示键盘每输完一个字符之后触发,就是键盘上的按键被放开时. 例子如下: <!DOCTYPE HTML PUBLIC "-/ ...
- re模块 | Python 3.5
https://docs.python.org/3/library/re.html http://www.cnblogs.com/PythonHome/archive/2011/11/19/22554 ...
- 关于Java配置文件properties的学习
在Java早期的开发中,常用*.properties文件存储一些配置信息.其文件中的信息主要是以key=value的方式进行存储,在早期受到广泛的应用.而后随着xml使用的广泛,其位置渐渐被取代,不过 ...
- MFC 刷新失效的Picture控件
问题描述:如在摄像头显示时,关闭摄像头,此时Picture控件仍然显示最后一帧图像,需要刷新掉,还原Picture控件.或者重复显示两张不同大小的图片时,第二张背景有第一张图片残留. 解决方法1:(最 ...