数据同步DataX
数据同步那些事儿(优化过程分享)
简介
很久之前就想写这篇文章了,主要是介绍一下我做数据同步的过程中遇到的一些有意思的内容,和提升效率的过程。
当前在数据处理的过程中,数据同步如同血液一般充满全过程,如图:

数据同步开源产品对比:
DataX,是淘宝的开源项目,可惜不支持Postgresql
Sqoop,Apache开源项目,同步过程中字段需要严格一致,不方便扩展,不易于二次开发
整体设计思路:
使用生产者消费者模型,中间使用内存,数据不落地,直接插入目标数据

优化过程:
1、插入数据部分:
首先生产者通过Jdbc获取源数据内容,放入固定大小的缓存队列,同时消费者不断的从缓存读取数据,根据不同的数据类型分别读取出来,并逐条插入目标数据库。
速度每秒300条,每分钟1.8W条。
这样做表面上看起来非常美好,流水式的处理,来一条处理一下,可是发现插入的速度远远赶不上读取的速度,所以为了提升写入的速度,决定采用批量处理的方法,事例代码:

@Override
public Boolean call() {
long beginTime = System.currentTimeMillis();
this.isRunning.set(true);
try {
cyclicBarrier.await();
int lineNum = 0;
int commitCount = 0; // 缓存数量
List<RowData> tmpRowDataList = new ArrayList<RowData>();// 缓存数组
while (this.isGetDataRunning.get() || this.queue.size() > 0) {
// 从队列获取一条数据
RowData rowData = this.queue.poll(1, TimeUnit.SECONDS);
if (rowData == null) {
logger.info("this.isGetDataRunning:" + this.isGetDataRunning + ";this.queue.size():" + this.queue.size());
Thread.sleep(10000);
continue;
}
// 添加到缓存数组
tmpRowDataList.add(rowData);
lineNum++;
commitCount++;
if (commitCount == SyncConstant.INSERT_SIZE) {
this.insertContractAch(tmpRowDataList); // 批量写入
tmpRowDataList.clear(); // 清空缓存
commitCount = 0;
} if (lineNum % SyncConstant.LOGGER_SIZE == 0) {
logger.info(" commit line: " + lineNum + "; queue size: " + queue.size());
}
} this.insertContractAch(tmpRowDataList); // 批量写入
tmpRowDataList.clear();// 清空缓存
logger.info(" commit line end: " + lineNum);
} catch (Exception e) {
logger.error(" submit data error" , e);
} finally {
this.isRunning.set(false);
}
logger.info(String.format("SubmitDataToDatabase used %s second times", (System.currentTimeMillis() - beginTime) / 1000.00));
return true;
} /**
* 批量插入数据
*
* @param rowDatas
* @return
*/
public int insertContractAch(List<RowData> rowDatas) {
final List<RowData> tmpObjects = rowDatas;
String sql = SqlService.createInsertPreparedSql(tableMetaData); // 获取sql
try {
int[] index = this.jdbcTemplate.batchUpdate(sql, new PreparedStatementSetter(tmpObjects, this.columnMetaDataList));
return index.length;
} catch (Exception e) {
logger.error(" insertContractAch error: " , e);
}
return 0;
} /**
* 处理批量插入的回调类
*/
private class PreparedStatementSetter implements BatchPreparedStatementSetter {
private List<RowData> rowDatas;
private List<ColumnMetaData> columnMetaDataList; /**
* 通过构造函数把要插入的数据传递进来处理
*/
public PreparedStatementSetter(List<RowData> rowDatas, List<ColumnMetaData> columnList) {
this.rowDatas = rowDatas;
this.columnMetaDataList = columnList;
} @Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
RowData rowData = this.rowDatas.get(i);
for (int j = 0; j < rowData.getColumnObjects().length; j++) {
// 类型转换
try {
ColumnAdapterService.setParameterValue(ps, j + 1, rowData.getColumnObjects()[j], this.columnMetaDataList.get(j).getType());
} catch (Exception e) {
ps.setObject(j + 1, null);
}
}
}
}
咱们不是需要讲解代码,所以这里截取了代码片段,全部的代码github上有,感兴趣的同学可以看看。PreparedStatement的好处,可以参考文章:http://www.cnblogs.com/liqiu/p/3825544.html
由于增加批量插入的功能,终于速度提升到每秒1000条
2、多线程优化
每秒1000条,速度依然不理想,特别是写的速度跟不上读取的速度,队列是满的,如图:

所以只能提升消费者的数量,采用了多消费者的模式:

速度提升到每秒3000条。
3、升级读取方式
这时候观察,随着消费者的增加,观察缓存队列经常有空的情况,也就是说生产跟不上消费者速度,如果增加生产者的线程,那么也会增加程序的复杂性,因为势必要将读取的数据进行分割。所以采用Pgdump的方式直接获取数据(并不是所有情况都适用,比如数据中有特殊的分隔符与设定的分隔符一样,或者有分号,单引号之类的)
代码片段如下:
/**
* 将数据放入缓存队列
*/
public void putCopyData() {
DataSourceMetaData dataSource = dataSourceService.getDataSource(syncOptions.getSrcDataSourceName());
String copyCommand = this.getCopyCommand(dataSource, querySql); //获取copy命令
ShellExecuter.execute(copyCommand, queue,columnMetaDatas);
} /**
* 执行copy的shell命令
* @param dataSource
* @param sql
* @return
*/
public String getCopyCommand(DataSourceMetaData dataSource, String sql){
String host = dataSource.getIp();
String user = dataSource.getUserName();
String dataBaseName = dataSource.getDatabaseName();
//String psqlPath = "/Library/PostgreSQL/9.3/bin/psql";
String psqlPath = "/opt/pg93/bin/psql";
String execCopy = psqlPath + " -h " + host + " -U " + user + " " + dataBaseName +" -c \"COPY (" + sql + ") TO STDOUT WITH DELIMITER E'"+ HiveDivideConstant.COPY_COLUMN_DIVIDE+"' CSV NULL AS E'NULL'\" "; // 执行copy命令
LOGGER.info(execCopy);
return execCopy;
}
意思就是通过执行一个Shell程序,获取数据,然后读取进程的输出流,不断写入缓存。这样生产者的问题基本都解决了,速度完全取决于消费者写入数据库的速度了。下面是执行Shell的Java方法代码:
public static int execute(String shellPath, LinkedBlockingQueue<RowData> queue, List<ColumnMetaData> columnMetaDatas) {
int success = -1;
Process pid = null;
String[] cmd;
try {
cmd = new String[]{"/bin/sh", "-c", shellPath};
// 执行Shell命令
pid = Runtime.getRuntime().exec(cmd);
if (pid != null) {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(pid.getInputStream()), SyncConstant.SHELL_STREAM_BUFFER_SIZE);
try {
String line;
while ((line = bufferedReader.readLine()) != null) {
// LOGGER.info(String.format("shell info output [%s]", line));
String[] columnObjects = line.split(HiveDivideConstant.COPY_COLUMN_DIVIDE.toString(), -1);
if (columnObjects.length != columnMetaDatas.size()) {
LOGGER.error(" 待同步的表有特殊字符,不能使用copy [{}] ", line);
throw new RuntimeException("待同步的表有特殊字符,不能使用copy " + line);
}
RowData rowData = new RowData(line.split(HiveDivideConstant.COPY_COLUMN_DIVIDE.toString(), -1));
queue.put(rowData);
}
} catch (Exception ioe) {
LOGGER.error(" execute shell error", ioe);
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
} catch (Exception e) {
LOGGER.error("execute shell, get system.out error", e);
}
}
success = pid.waitFor();
if (success != 0) {
LOGGER.error("execute shell error ");
}
} else {
LOGGER.error("there is not pid ");
}
} catch (Exception ioe) {
LOGGER.error("execute shell error", ioe);
} finally {
if (null != pid) {
try {
//关闭错误输出流
pid.getErrorStream().close();
} catch (IOException e) {
LOGGER.error("close error stream of process fail. ", e);
} finally {
try {
//关闭标准输入流
pid.getInputStream().close();
} catch (IOException e) {
LOGGER.error("close input stream of process fail.", e);
} finally {
try {
pid.getOutputStream().close();
} catch (IOException e) {
LOGGER.error(String.format("close output stream of process fail.", e));
}
}
}
}
}
return success;
}
4、内存优化
在上线一段时间之后,发现使用Jdbc方式获取数据,这个进程会占用非常大的内存,并且GC不掉,分析原因,是Postgresql的Jdbc获取数据的时候,会一次将所有数据放入到内存,如果同步的数据表非常大,那么甚至会将内存撑爆。
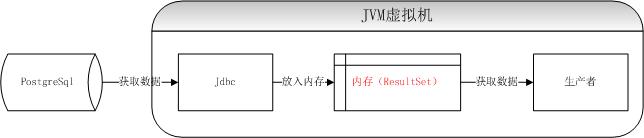
那么优化的方法是设置使Jdbc不是一次全部将数据拿到内存,而是批次获取,代码如下:
con.setAutoCommit(false); //并不是所有数据库都适用,比如hive就不支持,orcle不需要
stmt.setFetchSize(10000); //每次获取1万条记录
整体设计方案:

现在这个项目已经开源,代码放在:https://github.com/lihehuo/synchronous
数据同步DataX的更多相关文章
- 数据同步Datax与Datax_web的部署以及使用说明
一.DataX3.0概述 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳定高 ...
- Spark记录-阿里巴巴开源工具DataX数据同步工具使用
1.官网下载 下载地址:https://github.com/alibaba/DataX DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
- 基于datax的数据同步平台
一.需求 由于公司各个部门对业务数据的需求,比如进行数据分析.报表展示等等,且公司没有相应的系统.数据仓库满足这些需求,最原始的办法就是把数据提取出来生成excel表发给各个部门,这个功能已经由脚本转 ...
- 环境篇:数据同步工具DataX
环境篇:数据同步工具DataX 1 概述 https://github.com/alibaba/DataX DataX是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 ...
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- 增量数据同步中间件DataLink分享(已开源)
项目介绍 名称: DataLink['deitə liŋk]译意: 数据链路,数据(自动)传输器语言: 纯java开发(JDK1.8+)定位: 满足各种异构数据源之间的实时增量同步,一个分布式.可扩展 ...
- 高可用数据同步方案-SqlServer迁移Mysql实战
简介 随着业务量的上升,以前的架构已经不满足业务的发展,数据作为业务中最重要的一环,需要有更好的架构作为支撑.目前我司有sql server转mysql的需求,所以结合当前业务,我挑选了阿里云开源的一 ...
- 基于 MySQL Binlog 的 Elasticsearch 数据同步实践 原
一.背景 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数据可以 ...
- [大数据技术]datax的安装以及使用
1.datax简述 DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlServer.Postgre.HDFS.Hive.ADS.HBase.Ta ...
随机推荐
- 字符串拼接 拆分 NameValueCollection qscoll = HttpUtility.ParseQueryString(result)
string result = "sms&stat=100&message=发送成功"; string d = HttpUtility.ParseQueryStri ...
- _tkinter.TclError: no display name and no $DISPLAY environment variable
_tkinter.TclError: no display name and no $DISPLAY environment variable 这是在使用cocos2d-x的pluginx时遇到的一个 ...
- Spring整合JMS-基于activeMQ实现(二)
Spring整合JMS-基于activeMQ实现(二) 1.消息监听器 在Spring整合JMS的应用中我们在定义消息监听器的时候一共能够定义三种类型的消息监听器,各自是MessageLis ...
- JavaScript权威指南科03章 种类、值和变量(1)
种类.值和变量 数据类型分类: 基本类型(primitive type):数位 弦 布尔值 null undefined 对象类型(object type): 对象是属性的集合,每一个属性都由&quo ...
- 游戏碰撞OBB算法(java代码)
业务需求 游戏2D型号有圆形和矩形,推断说白了就是碰撞检测 : 1.圆形跟圆形是否有相交 2.圆形跟矩形是否相交 3.矩形和矩形是否相交 ...
- Unity3D之Vector3.Dot和Vector3.Cross采用
在Unity3D中.Vector3.Dot表示求两个向量的点积;Vector3.Cross表示求两个向量的叉积. 点积计算的结果为数值,而叉积计算的结果为向量.两者要注意差别开来. 在几何数学 ...
- delphi webbrowser 经常使用的演示样本
var Form : IHTMLFormElement ; D:IHTMLDocument2 ; begin with WebBrowser1 do begin D := Document as IH ...
- iOS 获取联系人,并调用系统地址簿UI
1.加入 AddressBook库 推断授权状态 -(bool)checkAddressBookAuthorizationStatus { //取得授权状态 ABAuthorizationStatus ...
- Prototype Pattern 原型模式
7.6 原型模式总结 原型模式作为一种快速创建大量相同或相似对象的方式,在软件开发中应用较为广泛,很多软件提供的复制(Ctrl + C)和粘贴(Ctrl + V)操作就是原型模式的典型应用,下面对该模 ...
- setInterval定时和ajax请求
fnSetMarkPoint = function (param) { $.ajax({ success: function (returnValue) { window.setInterval(&q ...