Hibernate3 第二天
Hibernate3 第二天
第一天回顾:
- 三个准备
- 创建数据库
- 准备po和hbm文件
- 准备灵魂文件hibernate.cfg.xml
- 七个步骤
- 1 加载配置文件Configuration
- 2 创建会话工厂SessionFactory
- 3 获取连接Session
- 4 开启事务Transaction
- 5 各种操作
- 6 提交事务commit
- 7 关闭连接close
今天内容安排:
- Hibernate的持久化对象(PO)相关状态和操作。(重点理解)
- Hibernate持久化对象的状态(3个)和转换。
- Session的一级缓存。
- Session一级缓存的快照(snapshot)。
- 多表关联映射配置和操作(重点应用)
- 一对多关联映射配置和操作、以及级联配置、外键维护配置。
- 多对多关联映射配置和操作。
学习目标:
- 掌握Hibernate的核心概念:PO的状态+一级缓存和快照
- 掌握多表映射的配置、级联配置和增删改的操作(项目中使用)
- 逐步学会和习惯使用debug
Hibernate的持久化对象相关概念和操作
Hibernate持久化对象(po)的状态和转换
持久化对象的状态
官方描述:
Hibernate 将操作的PO对象分为三种状态:
- 瞬时 (Transient )/ 临时: 通常new 创建对象(持久化类),未与Session关联,没有OID
- 持久 (Persistent) : 在数据库存在对应实例,拥有持久化标识OID, 与Session关联(受session管理)
- 脱管 (Detached)/游离:当Session关闭后,持久状态对象与Session断开关联,称为脱管对象,此时也持有OID
搭建测试环境:创建项目Hibernate3_day02
- 导入开发jar包(11个),将hibernate.cfg.xml、log4j.properties复制到src,修改Hibernate.cfg.xml的jdbc连接参数,导入hibernateUtils工具类。
- 创建包:cn.itcast.a_postate,在包中创建Customer类,代码如下:
- 编写hbm映射
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <!-- 配置java类与数据表的对应关系 name:java类名 table:表名 --> <class name="cn.itcast.a_postate.Customer" table="t_customer"> <!-- 配置主键 --> <id name="id"> <generator class="native"></generator> </id> <!-- 配置其他属性 --> <property name="name"></property> <property name="age"></property> </class> </hibernate-mapping> |
- 在hibernate.cfg.xml加载映射配置

5 创建TestPOState类,描述对象的三状态。
在类中编写测试testSave方法:代码如下:
|
@Test public void testSave(){ //瞬时态: //特点:没有OID,new出来的一个对象,不与session关联,不受session管理,数据库中没有对应的记录 Customer customer = new Customer(); customer.setName("rose"); customer.setAge(18); System.out.println(customer); Session session = HibernateUtils.openSession(); session.beginTransaction(); //在save执行之前,customer都只是瞬时态 //当save执行之后,customer就处于持久态 session.save(customer); //持久态 // /特点:有OID,数据库存在对应的记录,与session关联,受session管理 System.out.println(customer); session.getTransaction().commit(); session.close(); //只要session已关闭,那么久处于脱管态 //有OID,数据库中存在对应的记录,但是不与session关联,不受session管理 System.out.println(customer); } |
三种状态的区别分析:
- 持久态和瞬时态、脱管态:容易区别,持久态主要特点是与Session关联,而且数据库中有对应记录、拥有OID,因此,只要与session关联的就是持久态。
瞬时态和脱管态:相同点是都和Session没关联,不同点是瞬时态没有OID,而脱管态有OID。
【思考】
通过上述的分析,发现,瞬时态和脱管态对象就差一个OID,那么瞬时态的对象中给主键ID属性赋值后就是脱管态了么?
未必!
首先,需要区分持久化标识OID和对象中主键ID属性的关系:
- 在持久化之前,虽然有ID属性,但数据库中没有对应的数据,那么此时OID是null;
- 在持久化之后,这个ID属性值被插入数据库中当主键了,数据库中有对应的数据了,此时OID就有值了,而且与主键值保持一致性,比如类型、长度等。
因此:OID和PO对象中主键ID属性的区别就是:数据库存在不存在,如果存在就是OID,如果不存在,那就是个ID属性而已。
瞬时态和脱管态的区别总结:
- 脱管态对象:有持久化的标识oid,并且在数据库中存在。
- 瞬时态对象:无持久化标识oid,或者有id但在数据库中不存在的。
例如:
Customer对象具有Id属性值,如果数据库中不存在,则该对象还是瞬时态对象,如果数据库中存在,则认为是脱管态的。
【三者的区别最终总结】:
对于三者:在session中存在的,就是持久化对象,不存在的就是瞬时或脱管对象。
对于瞬时和脱管对象:有oid(持久化标识)的就脱管对象,没有的就是瞬时对象。
OID一定是与数据库主键一一对应的
|
是否有持久化标识OID |
session是否存在 |
数据库中是否有 |
|
|
瞬时态对象-临时状态 |
n |
n |
n |
|
持久态对象 |
y |
y |
y/(n:没有提交) |
|
脱管态对象-游离 |
y |
n |
y |
持久化对象状态的相互转换
持久化对象状态转换图(官方规范):


【分析】:(各状态对象的获取方式以及不同状态之间转换的方法介绍):
- 瞬时对象:
如何直接获得 --- new 出来
转换到持久态 ---- save、saveOrUpdate 保存操作
转换到脱管态 ---- setId 设置OID持久化标识(这个id是数据库中存在的)
- 持久对象
如何直接获得 ---- 通过session查询方法获得 get、load、createQuery、createSQLQuery、createCriteria
转换到瞬时态 ---- delete 删除操作 (数据表不存在对应记录 )(其实还有id,只是不叫OID)
转换到脱管态 ---- close 关闭Session, evict、clear 从Session清除对象
- 脱管对象
如何直接获得 ----- 无法直接获得 ,必须通过瞬时对象、持久对象转换获得
转换到瞬时态 ---- 将id设置为 null,或者手动将数据库的对应的数据删掉或者将id修改成数据库中不存在的
转换到持久态 ---- update、saveOrUpdate、lock (对象重新放入Session ,重新与session关联)
在Hibernate所有的操作只认OID,如果两个对象的OID一致,它就直接认为是同一个对象。
Session的一级缓存(重点理解)
什么是一级缓存?
又称为:hibernate一级缓存、session缓存、session一级缓存
- 缓存的概念:在内存上存储一些数据
缓存的介质是一般是内存(硬盘),用来存放数据,当第一次查询数据库的时候,将数据放入缓存,当第二次继续使用这些数据的时候,就不需要要查询数据库了,直接从缓存获取,
- 一级缓存概念:
在Session接口中实现了一系列的java集合,这些java集合构成了Session的缓存,只要Session的生命周期没有结束,session中的数据也就不会被清空。
- 缓存作用:
将数据缓存到内存或者硬盘上,访问这些数据,直接从内存或硬盘加载数据,无需到数据库查询。
好处: 快! 降低数据库压力。
- 一级缓存的生命周期:
Session中对象集合(map),在Session创建时,对象集合(map)也就创建,缓存保存了Session对象数据,当Session销毁后,集合(map)销毁, 一级缓存释放 !
- 什么对象会被放入一级缓存?
只要是持久态对象,都会保存在一级缓存 (与session关联的本质,就是将对象放入了一级缓存)
一级缓存的作用:第一次get/load的时候,肯定会发出sql语句,查询数据库,(此时会将数据放入一级缓存),只要session不关闭,
第二次get/load的时候,直接从缓存中读取数据,不会发出sql语句,查询数据库(这里的数据指的是同一条记录:OID相等)
【示例】证明一级缓存的存在性!
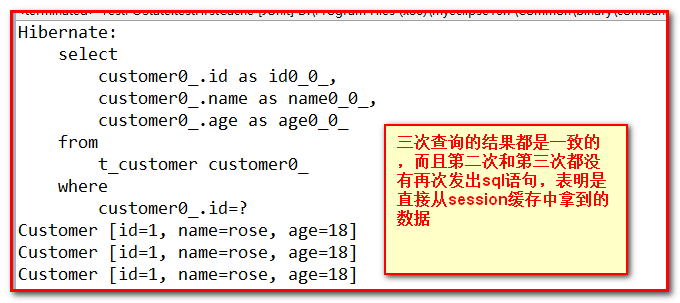
通过多次查询同一个po对象数据,得到同一个对象,且第二次不再从数据库查询,证明一级缓存存在。
|
@Test public void testFirstCacheExist(){ /** * 证明一级缓存的存在性 * 证明思路: * 缓存的作用就是用来少查数据库的,提高访问速度 * 第一步,通过get/load查询数据,由于是第一次查询,所以必然发出sql语句,查询数据库 * 第二步,不关闭session,继续使用当前的session去get/load数据,观察是否发出sql语句 * 如果不发出,表明是从一级缓存取出的数据 */ Session session = HibernateUtils.openSession(); session.beginTransaction(); //第一步:此时必然发出sql语句,然后自动将数据放入一级缓存 Customer customer = (Customer) session.get(Customer.class, 1); System.out.println(customer); //第二步:此时不会发出sql语句,直接从一级缓存获取数据 Customer customer2 = (Customer) session.get(Customer.class, 1); System.out.println(customer2); session.getTransaction().commit(); session.close(); } |
测试(同一个对象):
一级缓存的生命周期
一级缓存的生命周期就是session的生命周期,不能跨Session,可以说,一级缓存和session共存亡!
【示例】
使用两个不同Session来测试生命周期。(一级缓存和session共存亡)
|
@Test public void testFirstCachelifecycle(){ /** * 一级缓存的声明周期:与session同生命共存亡 * 如何证明一级缓存的生命周期? * 只要证明数据不能跨session * 1 获取session1,通过session1拿到customer对象,此时必然发出sql语句,关闭session1 * 2 获取session2,通过session2继续抓取customer对象,观察第二次是否发出sql语句 * 如果发出,,表名session1销毁的时候,把数据也销毁了 */ Session session1 = HibernateUtils.openSession(); session1.beginTransaction(); //此时必然发出sql语句,因为是第一次查询 Customer customer = (Customer)session1.get(Customer.class, 1); System.out.println(customer); // 此处如果需要查询Customer,会发sql语句吗?答:不会,直接走一级缓存 //也能证明数据成功存入了一级缓存 Customer customer2 = (Customer)session1.get(Customer.class, 1); System.out.println(customer2); session1.getTransaction().commit(); session1.close(); /**********第二次*********/ Session session2 = HibernateUtils.openSession(); session2.beginTransaction(); //此时发sql语句吗?答:发,因为session1中的数据跟随session1一起销毁了 Customer customer3 = (Customer)session2.get(Customer.class, 1); System.out.println(customer3); session2.getTransaction().commit(); session2.close(); } |
测试:

小结:缓存的作用,可以提高性能,减少数据库查询的频率。
[补充:原则]所有通过hibernate操作(session操作)的对象都经过一级缓存。
一级缓存是无法关闭的!内置的!hibernate自己维护的!
Session一级缓存的快照
什么是一级缓存的快照(snapshot)
什么是快照?
答:快照,是数据在内存中的副本,是数据库中数据在内存中的映射。
如:

一句话:
快照跟数据库数据保持一致
快照的作用就是用来更新数据的。
一级缓存快照的原理(图)

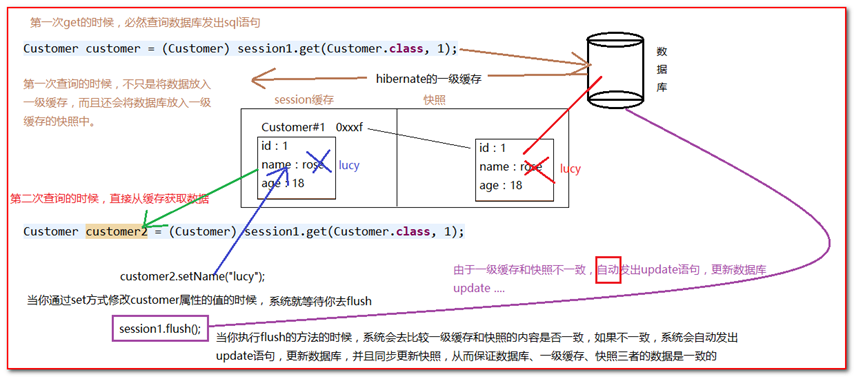
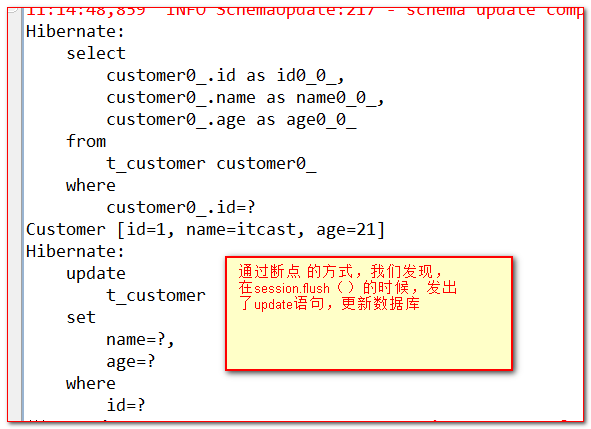
采用快照技术进行更新,不需要手动的调用update 方法,完全是自动的发出update语句。
保正一级缓存、数据库、快照的一致性
【注意】
- 持久态对象原则:po对象尽量保持与数据库一一致。
- 当一级缓存和快照不一致的时候,会先发出update语句,将一级缓存同步到数据库(发出update语句),然后当同步成功之后,再自动内部同步快照。保证三者的一致性。
一级缓存快照的能力
一级缓存的快照是由Hibernate来维护的,用户可以更改一级缓存(PO对象的属性值),但无法手动更改快照!
快照的主要能力(作用)是:用来更新数据!当刷出缓存的时候,如果一级缓存和快照不一致,则更新数据库数据。
【示例】
通过改变查询出来的PO的属性值,来查看一级缓存的更改;通过提交事务,来使用快照更新数据。
|
@Test public void testSnapShot(){ /** * 证明快照的能力:自动更新数据 * 1 从数据库查找一个对象,改变对象的某个值,手动的flush,看控制台是否发出sql语句, * 如果控制台发出update语句,就可以表明快照的能力 */ Session session = HibernateUtils.openSession(); session.beginTransaction(); //get的时候,不光将数据放入一级缓存,还同时将数据同步到了快照中 Customer customer = (Customer)session.get(Customer.class, 1); System.out.println(customer); //修改customer对象的值 customer.setName("lucy"); //这个值是改变过后的值,是内存中的值 System.out.println(customer); //提交事务 //如果不手动flush,在事务commit的时候,会先flush,在commit session.getTransaction().commit(); session.close(); } |
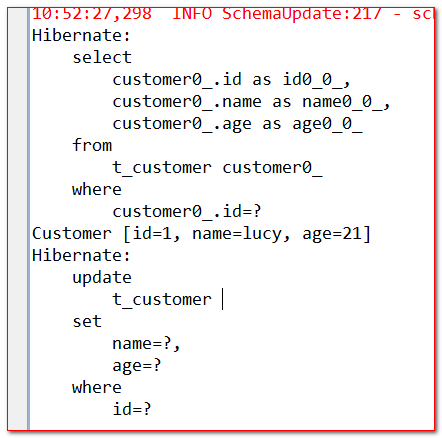
【能力扩展】快照可以用来更新数据,而且,可以用来更新部分数据。
【问题】update也是更新数据,快照也是更新数据?两个有什么区别?
Update更新的时候,会将所有值都更新,如果有某个属性没有赋值,值将会被置空
快照符合我们修改的要求:先查后改
刷出缓存的时机
什么叫刷出缓存?
Session能够在某些时间点,按照缓存中对象的变化来执行相关的SQL语句,来同步更新数据库,这一过程被成为刷出缓存(flush)。
通俗的说法:将一级缓存的数据同步到数据库,就是刷出缓存
什么情况下session会执行 flush操作?
刷新缓存的三个时机:
- 事务提交commit():该方法先刷出缓存(session.flush()),然后再向数据库提交事务。
- 手动刷出flush():直接调用session.flush()。
- 查询操作:当Query查询(get、load除外,这两个会优先从一级缓存获取数据)时,会去比较一级缓存和快照,如果数据一致,则去数据库直接获取数据,如果缓存中持久化对象的属性已经发生了变化,(一级缓存和快照不一样了),则先刷出缓存,发出update语句,然后查询,以保证查询结果能够反映出持久化对象的最新状态。(Query查询数据不走一级缓存)
【补充理解】:
关于Hibernate如何识别同一个对象?
根据OID,
问题:假如先查询出来一个对象oid是1001,数据库主键也是1001,但其他字段的属性不一样,那么,再次查询数据库的数据出来的对象,和原来的对象是否是一个对象?
答案:是!
【示例】
1 、通过commit 的方式隐式的刷出缓存(证明略)
2 、通过flush的方式手动的刷出缓存
|
//采用flush的方式手动的刷出缓存 @Test public void testflushcache2() { Session session = HibernateUtils.openSession(); // 开启 事务 session.beginTransaction(); //获取数据 Customer customer = (Customer)session.get(Customer.class, 1); System.out.println(customer); customer.setName("rose"); //手动的flush,发出update语句,更新数据库,并且同时更新快照 session.flush(); session.getTransaction().commit(); //特点:在数据库中存在对应的记录,有OID,但是不受session管理 session.close(); } |
3 、使用Query的时候,(不包含get、laod:原因:get和load的处理方式,是直接获取缓存的数据,即使一级缓存和快照的数据不一致)
会去比较一级缓存和快照是否一致,如果一致,他直接去查询(1条select语句)
当不一致了,会先发出update语句,更新数据库,然后在查询(1条update语句,1条select语句)
3.1 测试get和load 的处理方式
|
@Test public void testGetAndLoad_Cache(){ /** * 证明get和load优先从缓存取数据,哪怕一级缓存和快照的数据不一致, * 它也是直接取缓存数据 * 证明思路: * 第一步,将数据放入一级缓存和快照 * 第二步,取 ,观察是否发出sql语句和数据 * 第三步,改 * 第四部,取 ,观察是否发出sql语句和数据 * */ Session session = HibernateUtils.openSession(); session.beginTransaction(); // 1 取,并且放入一级缓存和快照 Customer customer1 = (Customer) session.get(Customer.class, 1); System.out.println(customer1); //2 取:肯定不发sql语句,直接从缓存取 Customer customer2 = (Customer) session.get(Customer.class, 1); System.out.println(customer2); //3 改: customer2.setName("tom"); //4 取,虽然此时一级缓存和快照不一致,但是get/load也是直接抓取缓存数据 Customer customer4 = (Customer) session.get(Customer.class, 1); System.out.println(customer4); //隐式flush session.getTransaction().commit(); session.close(); } |
3.2 测试query的工作方式:
【证明1】query对象不走一级缓存
|
//query不走一级缓存 @Test public void testQuery_cache(){ // 证明query不使用session缓存的数据,即使缓存中有,它也会发出sql语句,查询数据库 Session session = HibernateUtils.openSession(); session.beginTransaction(); // /此处也会发出sql语句 Customer customer = (Customer)session.get(Customer.class, 1); System.out.println(customer); //此时必须发出sql语句,因为它不会直接从一级缓存中拿数据 Customer customer2 = (Customer)session.createQuery("from Customer where id = 1").uniqueResult(); System.out.println(customer2); session.getTransaction().commit(); session.close(); } |

【证明2】但是Query对象在查询数据的时候,会去校验一级缓存和快照的数据是否一致,
如果不一致,发出update语句,更新数据库,然后再发出sql查询语句
|
//证明2:query对象虽然不从一级缓存取数据,但是在它去数据库查找数据之前,会干这么一件事情: // 会比较一级缓存和快照是否一致, // 如果一致,直接去数据库查找需要的数据 // 如果不一致,先flush(先发出update语句),再去数据库查找需要的数据 @Test public void testQuery2(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer customer1 = (Customer) session.get(Customer.class, 1); System.out.println(customer1); customer1.setName("tom"); Customer customer2 = (Customer) session.createQuery("from Customer where id = 1").uniqueResult(); System.out.println(customer2); session.getTransaction().commit(); session.close(); } |

【提示】
flush和commit的区别:
- flush是发语句的。
- commit的是数据库层面的是否保存更改的数据(是否提交数据,是否持久化数据到数据库),若不手动发出flush, hibernate在commit之前自动先flush();
一级缓存的刷出模式--(了解)
问题:能否改变一级缓存的刷出时机?答案是可以的.

【示例】
通过在session上设置手动flush模式测试:只能通过flush刷出缓存
|
@Test public void testFlushMode(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); // 1 第一步证明:先不设置FlushMode,看运行结果 Customer customer = (Customer)session.get(Customer.class, 1); //改变缓存中对象的属性 customer.setName("lucy"); // 2 第二证明:设置FlushMode,看运行结果 //这个一旦设置,只有手动flush的时候,才会发出update语句 session.setFlushMode(FlushMode.MANUAL); //第二种方式,手动flush,发出update语句 session.flush(); //在第一种情况下,此处必然发出update语句 //在第二种情况下,此处必然不会发出update语句 session.getTransaction().commit(); session.close(); } |
一级缓存的常用操作
操作一级缓存中的对象
一级缓存除了可以flush之外,还可以清除(clear,evict)、重载(refresh)。
- flush:刷出一级缓存
作用:当一级缓存发生变化时,即和快照不同时,刷出一级缓存,会自动向数据库提交update语句。
- clear:清除一级缓存中所有的数据
作用:清除一级缓存中的所有对象,这些对象被清除后,会从持久态对象变成脱管态.
【扩展理解】
持久态对象与session关联的另一层含义就是对象在一级缓存中存在。
- evict:清除一级缓存指定对象
作用:清除一级缓存中的指定对象,使对象变成脱管态的。
- refresh:刷新一级缓存
通俗的讲:不管内存中对象是否发生了更新,重新将数据库中的内容加载到缓存中,覆盖原来的值
|
@Test public void testClearAndEvict(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //此时数据会被放入一级缓存 Customer customer = (Customer)session.get(Customer.class, 1); System.out.println(customer); //在第二次获取之前插入代码:clear 一级缓存 //clear:清除一级缓存中的所有数据 // session.clear(); //evict:清除一级缓存的指定对象,主要清除的是OID=1的这个对象 session.evict(customer); //由于第一次get的时候,已经发出了sql语句查询数据库,所以,第二次get的时候就不会发sql语句 //如果我们执行了session.clear()代码,表示一级缓存数据被清空了,那么这次获取的时候 //还是要继续发出sql语句的 Customer customer2 = (Customer)session.get(Customer.class, 1); System.out.println(customer2); session.getTransaction().commit(); session.close(); } //refresh: 不管缓存中的数据是否发生了改变,将数据库中的数据重新放入缓存 //如果缓存的数据发生了改变,那么这个改变将会被覆盖 @Test public void testRefresh(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer customer = (Customer)session.get(Customer.class, 1); customer.setName("rose"); System.out.println(customer); //从数据库中根据OID重新加载这条记录,原先的改变失效,数据库中原始的值会覆盖修改的值 session.refresh(customer); System.out.println(customer); session.getTransaction().commit(); session.close(); } |
【面试题】请你说说session的flush和refresh的区别?
为什么要清除一级缓存:
大批量处理数据的时候,有些数据无需在一级缓存存在,或者已经处理完了,为了防止内存泄漏,一级缓存爆满,可以手动清除一级缓存的对象。
get()和load()的区别
【状态变化】直接拿到持久态对象。
【理解 session的get方法和load方法区别】
两者的区别:
get()方法是立即加载,即执行get方法后,立即发出查询语句进行查询,直接返回目标对象。
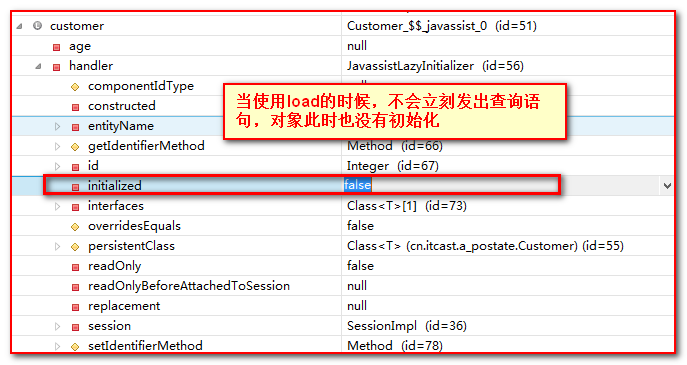
load()方法是延迟加载,即执行load方法后,不会立即发出查询语句,返回具有id的目标对象代理类子对象,再访问对象的除了ID之外的其他属性的时候,才发出SQL语句进行查询。
【示例】
分别用get和load,来根据不同id查询不同对象,使用debug来查看语句发出的时机以及延迟加载时的代理类子对象。
|
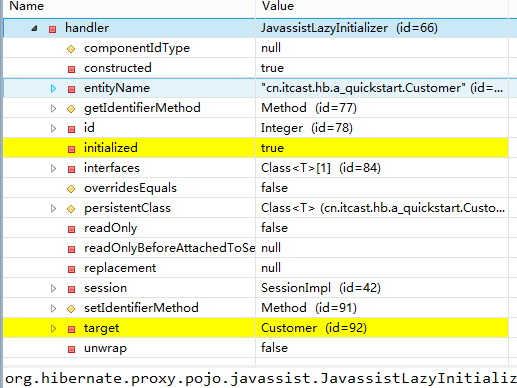
@Test public void testGetAndLoad(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); //比较get和load的区别 //1 观察get和load的sql语句发出时机 //get方法立即发出sql语句 // Customer customer = (Customer) session.get(Customer.class, 1); // System.out.println(customer); //load方法:属于懒加载,如果只用到id属性,是不会发出sql查询语句的 //只有用到id以外的其他属性的时候,才会发出sql查询语句 Customer customer = (Customer) session.load(Customer.class, 1); //简单的打印id,发出sql语句吗? System.out.println(customer.getId()); //发出sql语句吗? System.out.println(customer.getName()); session.getTransaction().commit(); session.close(); } C2引用的Customer的代理子对象 继续调试
初始化后,内部handler中initialized变为true (已经初始化), target 指向真正查询结果对象 |
【关于load延迟加载的几个情况提示】
- 代理子对象,handler属性,包含了主键id,因此只访问id时,不需要发出sql语句。
【示例】
延迟加载时,访问ID属性不发出sql,访问ID之外的属性时发出sql
|
//load:不会立即发出sql,只有在访问除id之外的其他属性的时候,才发出sql Customer customer2 =(Customer) session.load(Customer.class, 2); System.out.println(customer2.getId());//不需要发出sql System.out.println(customer2.getName());//此时才发出sql |
- 当id在数据库中不存在的时候,访问其他属性时会发生 ObjectNotFoundException。
【示例】
两者查不到数据的区别:
|
|
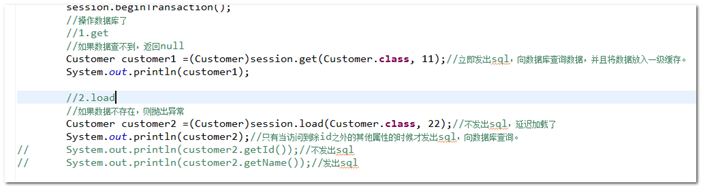
结论:get会返回null,load会报错:

【扩展了解】
代理子对象是谁来负责生成的?

答:通过javassist.jar来进行生成子对象(反射机制)
延迟加载的好处:节约资源,需要的时候再加载(提高内存利用率),如果不需要的话,先不加载。
多表关联映射配置和操作(未来项目肯定会用)
多表设计
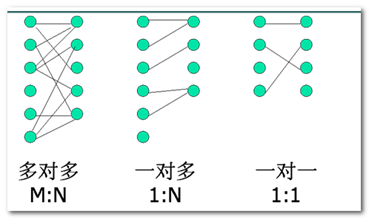
多对多: 学生选课 (一个学生选多门课, 一门课被多个学生选择)
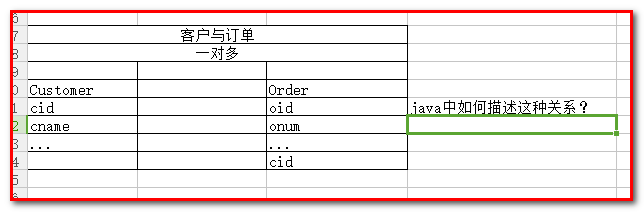
一对多: 客户和订单 (一个客户可以产生很多订单, 一个订单属于一个客户)
一对一: 一个公司对应建表规则:
多对多: 一定产生第三方关系表, 需要三张表 (学生表、 课程表、 选课表), 关系表联合主键,引入两张实体表主键,作为外键
一对多: 在多方表,添加一方主键作为外键 ,不需要第三张表 , 需两张表(客户表 、订单表),在订单表添加客户id
一对一: 在任意一方添加对方主键作为外键
一个地址


范式:可以理解成是数据库设计的规范/标准
为什么表的设计需要有规范和标准?
防止数据冗余,科学的数据库设计可以防止数据冗余
//一般数据库的设计要符合3NF,符合的范式要求越高,表越多
范式之间的关系:

第一范式(1NF):保证每列的原子性(每列都是不可再分割的单元)
学生表
|
stuno |
stuinfo |
Coursename |
|
1 |
Lucy23 |
Java |
|
1 |
Tom18 |
Oracle |
|
1 |
Rose12 |
Hibernate |
上表是不符合第一范式的,修改如下
|
stuno |
Name |
Age |
Coursename |
|
1 |
Lucy |
23 |
Java |
|
1 |
Tom |
18 |
Oracle |
|
1 |
Rose |
12 |
Hibernate |
第二范式:保证表有主键
上表符合第二范式吗?不符合,因为没有主键,修改如下:
|
stuno |
Name |
Age |
Coursename |
|
1 |
Lucy |
23 |
Java |
|
2 |
Tom |
18 |
Oracle |
|
3 |
Rose |
12 |
Hibernate |
第三范式:每张表不包含其他表中非主键以外的字段(每张表的字段都依赖于当前的主键)
上表符合第三范式吗?答:不符合,修改如下
|
stuno |
Name |
Age |
|
1 |
Lucy |
23 |
|
2 |
Tom |
18 |
|
3 |
Rose |
12 |
|
Courseid |
Coursename |
|
1 |
Java |
|
2 |
Oracle |
|
3 |
Hibernate |
关系表:
|
Stuno |
Courseid |
|
1 |
1 |
|
1 |
2 |
|
2 |
1 |
|
2 |
3 |
BCNF
4NF
5NF
java对象(po)描述表关系
Hibernate 是一个完全ORM框架,使用hibernate 编程,可以完成类和表映射
多对多 :
Student {
// 一个学生对应 多门课
// Set、List、bag、数组 代表复数,基本区别:set不能重复,没顺序、list可以重复,有顺序。bag:不能重复,而且有顺序(缺点:效率低)
Set<Cource> cources ;
}
Cource {
// 一门课,多个学生
Set<Student> students ;
}
一对多 :
Customer {
// 一个客户 多个订单
Set<Order> orders ;
}
Order {
// 一个订单 一个客户
Customer customer ;
}
一对一:
Company {
// 一个公司 一个地址
Address address;
}
Address {
// 一个地址 对应一个公司
Company company ;
}
我们下面重点学习一对多和多对多!
一对多关联映射配置
案例:客户和订单(一对多)
建立一个包用于测试: cn.itcast.b_oneToMany
映射配置
编写方法:实体类的编写,先写单表的属性和配置,再加关系。
【第一步】:实体类编写
|
|


【第二步】:hbm映射文件编写
Order.hbm.xml
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <class name="cn.itcast.b_onetomany.Order" table="t_order"> <!-- 主键 --> <id name="id"> <generator class="native"></generator> </id> <!-- 其他属性 --> <property name="name"></property> <!-- 配置关系 name:类中属性 class:这个属性的原型(属性对应对象的完整的包路径) column:customer在Order表中的外键的名字 --> <many-to-one name="customer" class="cn.itcast.b_onetomany.Customer" column="cid"></many-to-one> </class> </hibernate-mapping> |
Customer.hbm.xml
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <!-- class --> <class name="cn.itcast.b_onetomany.Customer" table="t_customer"> <!-- 配置主键 --> <id name="id"> <!-- 主键策略 --> <generator class="native"></generator> </id> <!-- 其他属性 --> <property name="name"></property> <!-- 配置集合 name:类中的属性名 --> <set name="orders"> <!-- 配置当前Customer对象在order表中的外键的名字 --> <key column="cid"></key> <!-- 配置关系 class:当前order对应的完整的包路径(集合中装载的数据的原型) --> <one-to-many class="cn.itcast.b_onetomany.Order"/> </set> </class> </hibernate-mapping> |
注意:两个配置文件的外键必须对应!!!!!
【第三步】:核心配置文件中添加映射
|
<!-- 配置一对多的映射文件 --> <mapping resource="cn/itcast/b_onetomany/Customer.hbm.xml"/> <mapping resource="cn/itcast/b_onetomany/Order.hbm.xml"/> |
【第四步】:建表测试
|
@Test public void createTable() { HibernateUtils.getSessionFactory(); } |
|
建表成功:
|

提示:外键的数据类型自动会使用对方主键的类型
相关操作
本节难点:cascade级联和inverse外键维护
保存操作Save
多表保存的原则:双方都必须是持久态的对象!
目标:学习几种保存方法。
- 双向关联保存
|
@Test public void testSave(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer c1 = new Customer(); c1.setName("rose"); Order o1 = new Order(); o1.setName(c1.getName()+"的订单1"); //双向建立关系 c1.getOrders().add(o1); o1.setCustomer(c1); //必须同时保存两个对象,否则会报错 session.save(c1); session.save(o1); session.getTransaction().commit(); session.close(); } |
这种保存要求:必须双方都建立关系,而且都要执行保存操作.
- 级联保存
【需求】
保存客户的同时自动保存订单。
|
默认情况下:
会报错:
|


原因结论: 在hibernate代码中,在session.flush前,不允许 持久态对象 关联 瞬时态对象
持久态对象只能关联持久态对象!
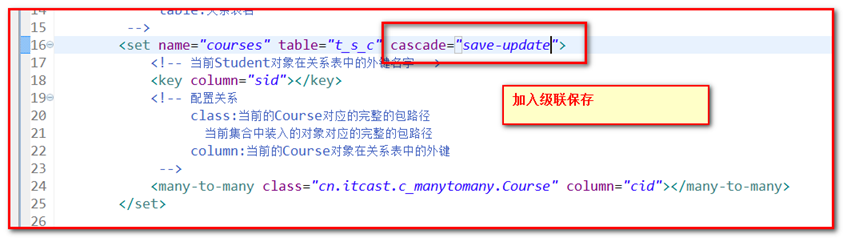
解决:采用级联 ,cascade :cascade="save-update"
它的作用:
可以使持久态对象"关联"瞬时态对象, 自动会隐式执行save操作,变为持久态,
可以使持久态对象"关联"脱管对象,自动会隐式执行update操作,变为持久态
如果通过操作customer来级联保存 order ,需要在Customer.hbm.xml(谁是持久的) 配置级联.
Customer.hbm.xml:
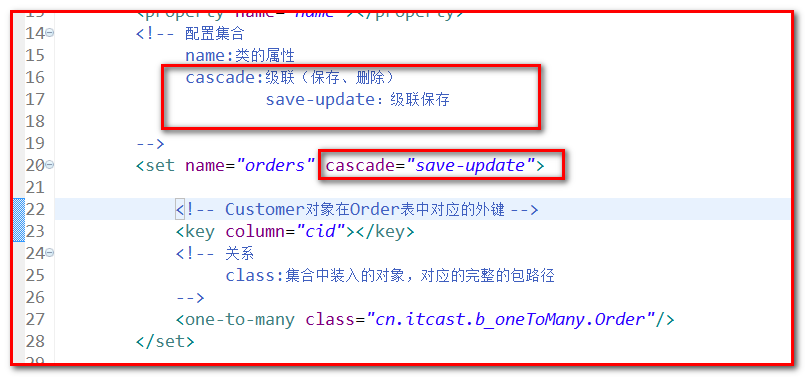
测试代码:
|
@Test public void testSave(){ Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer c1 = new Customer(); c1.setName("lucy"); Order o1 = new Order(); o1.setName(c1.getName()+"的订单1"); Order o2= new Order(); o2.setName(c1.getName()+"的订单2"); Order o3 = new Order(); o3.setName(c1.getName()+"的订单3"); Order o4 = new Order(); o4.setName(c1.getName()+"的订单4"); //当级联保存的时候,当我们在Customer.hbm.xml中设置了级联关系的时候, //那么在设置关系的时候,只需要向Customer的orders集合中添加Order,就可以进行级联保存 c1.getOrders().add(o1); c1.getOrders().add(o2); c1.getOrders().add(o3); c1.getOrders().add(o4); // o1.setCustomer(c1); //必须同时保存两个对象,否则会报错 session.save(c1); // session.save(o1); session.getTransaction().commit(); session.close(); } |
使用级联之后,Hibernate会对瞬时态的这个对象,会自动执行save操作.
问题:如果保存顺序反过来呢?即先保存订单,同时保存客户呢?
分析:先操作order ,级联保存 customer ,需要在 Order.hbm.xml 配置级联
Order.hbm.xml :
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer c1 = new Customer(); c1.setName("jack"); Order o1 = new Order(); o1.setName(c1.getName()+"的订单1"); o1.setCustomer(c1); session.save(o1); session.getTransaction().commit(); session.close(); } |

级联对于大量的保存或更新操作非常有用。
- 对象导航—连续保存—其实是依赖于级联。
对象导航概念:通过一个对象的保存操作,可以自动导航到另外一个关联对象的保存操作。
下面有个面试题,前提:customer和order都配置了级联保存(双向都配置),那么请问下面的1,2,3语句分别产生几条插入的sql语句,
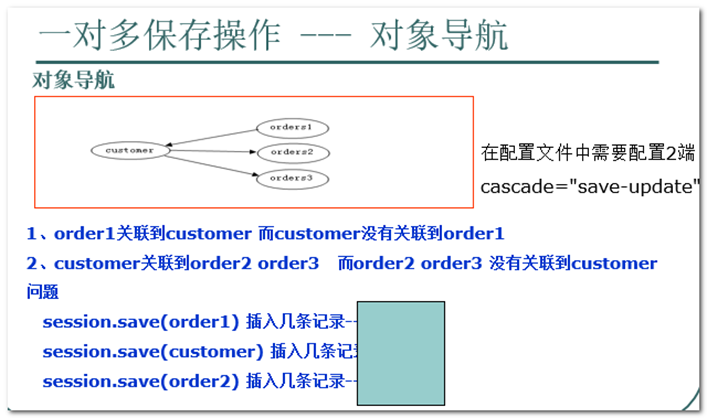
答案: 4 3 1
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); Customer c1 = new Customer(); c1.setName("itcast2"); Order o1 = new Order(); o1.setName(c1.getName()+"的订单1"); Order o2 = new Order(); o2.setName(c1.getName()+"的订单1"); Order o3 = new Order(); o3.setName(c1.getName()+"的订单1"); o1.setCustomer(c1); c1.getOrders().add(o2); c1.getOrders().add(o3); //第一种情况 4 session.save(o1); //第2种情况 3 session.save(c1); //第3种情况 1 session.save(o2); session.getTransaction().commit(); session.close(); } |
Hibernate的外键:是由关系来提供
导航保存对于大量的保存或更新操作非常有用。
删除操作delete
表之间的依赖关系:在一对多中 ,多方表(从表)
依赖
一方表(主表) (order依赖customer)。
- 删除多方的一条数据
|
// 第一种情况:直接删除多方的数据 // Order order = new Order(); // order.setId(7); // // session.delete(order); |
删除多方 (订单),直接删除
- 删除一方的一条数据(问:会如何呢?)
|
//第二种情况:直接删除一方的数据 Customer customer = new Customer(); customer.setId(4); //当customer是一个脱管态对象的时候,先解除关系,删除,所以删除之后,你会发现多方的外键被置空 session.delete(customer); |
删除一方(客户),被依赖
结果:多方的外键被置空了,一方被删除了(内部机制)

原理:Hibernate 先解除对一方外键依赖,然后进行删除
(如果外键设置 not-null , 无法删除 )课后可以试试
- 级联删除-删除客户自动删除对应的订单(知识点:这里就可以看出删脱管对象和持久对象的区别了)
级联删除必须是持久态对象才会有级联删除效果,否则是无效的
问题: 从关系型数据库的角度来说:在一对多数据模型中,多方对一方存在依赖的, 如果一方数据被删除,多方数据不完整,无意义。(客户删除的同时,将订单一块都删了)
解决方法: 在一方 配置 cascade="delete" ,会级联删除.
级联删除的要求:被删除的对象要是持久态的对象
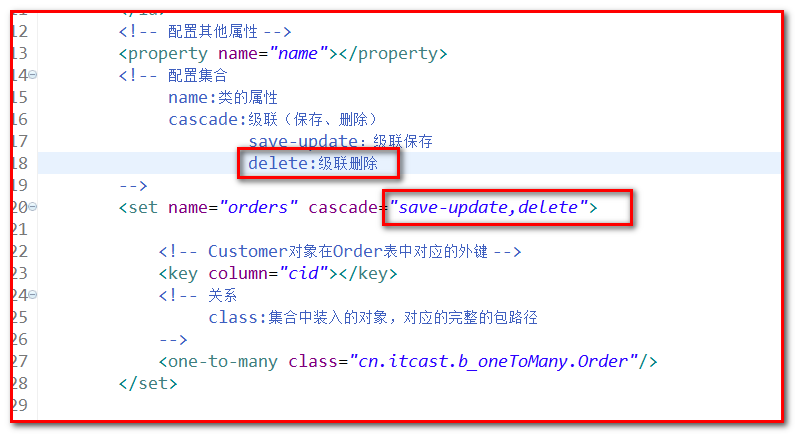
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); //删除多方的数据:直接删除 // Order order = new Order(); // order.setId(15);//设置oid,删除只能根据id删除 // 删除 // session.delete(order); //删除一方的数据 // Customer customer = new Customer(); // customer.setId(7); //当删除的时候,hibernate会先解除关系(将cid置空),然后在进行一方的删除操作 // session.delete(customer); /** * 在进行级联删除的时候,如果删除的对象还是脱管态对象,级联删除失效, * 默认处理方式:先解除关系,再一方删除数据(多方数据还存在,并没有达到级联删除的效果) * * 级联删除:一方对象必须是持久态,这样子,才能实现级联删除的效果 */ //持久态 Customer customer = (Customer)session.get(Customer.class, 6); //由于customer对象是持久态,所以会级联删除order订单 session.delete(customer); session.getTransaction().commit(); session.close(); } |
结论:删除操作中,删除托管对象没有级联效果,删除持久对象可以进行级联删除
级联属性配置-cascade
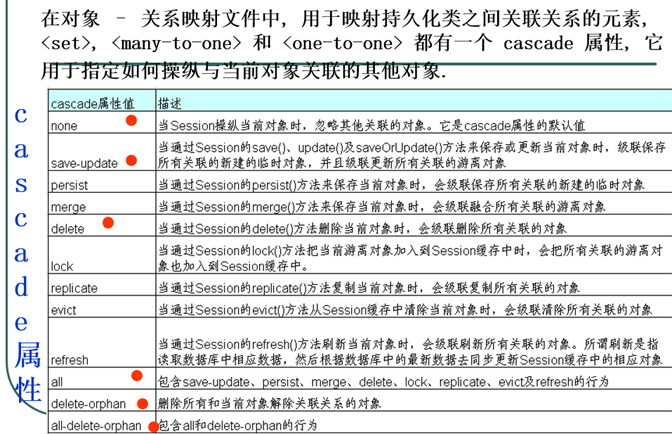
Hibernate级联开发配置, cascade常用的取值:
- save-update:对关联瞬时对象执行save操作,对关联托管对象执行update
- delete:对关联对象进行删除
在实际开发中,一对多模型中,一方一般是主动的一方(多方要依赖一方),如果配置级联,通常在一方进行配置!!!
因为多方需要引用一方的主键作为外键使用
级联删除的情况:删除客户,订单也已经没有存在的意义了
删除订单,没有必要删除客户,没有必要再多方配删除级联
实际项目开发中,一般级联主要是用来进行级联删除操作,很少用来进行级联保存。一般都是先有一方的数据,再有多方的数据,即先有客户,再有订单。所以,保存多方不配置级联(不在多方配置级联)。
总结:
一般在业务开发中,不要两端都配置级联,(多方尽量不要配置级联,尽量在一方配置级联)
配置了级联之后,必须操作持久态对象,否则不会级联删除。
外键的维护问题-inverse
问题:多余sql的问题
示例:
将没有关系的一个客户和一个订单建立关系。(双方)
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); // 获取5号客户 Customer customer = (Customer)session.get(Customer.class, 5); // 获取订单 Order order = (Order)session.get(Order.class, 11); //添加双向关联关系 customer.getOrders().add(order); order.setCustomer(customer); //此时当commit的时候,会隐式的flush session.getTransaction().commit(); session.close(); } |
产生的sql:多余sql

分析图:

解决方法:
采用inverse属性来配置。

简单的说这个属性谁是true,就放弃了主键维护权。
inverse默认值是false,即双方都有外键维护权。
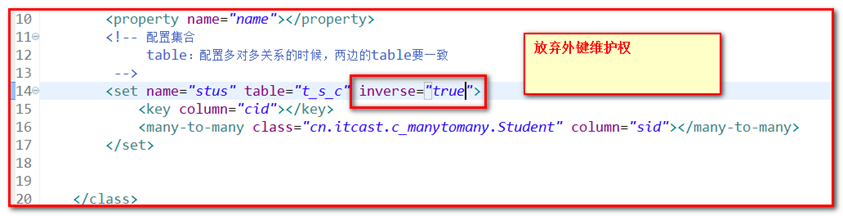
inverse只对集合起作用,也就是只对one-to-many或many-to-many有效.
在业务开发中,一般是在一方放弃。(从业务场景上来分析,一般先存1 方,再存多方,那么就存多方的时候建立关系就比较合理。)

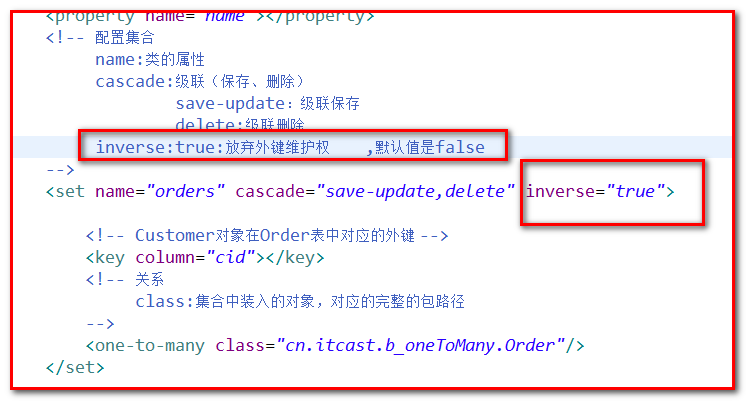
再次运行,发现就一条语句了:

一般,我们都让1方放弃外键维护权!
多对多关联映射
学习点:掌握多对多配置方式。
案例:学生和课程,学生选课
映射配置方式
多对多关系分析(student\course)
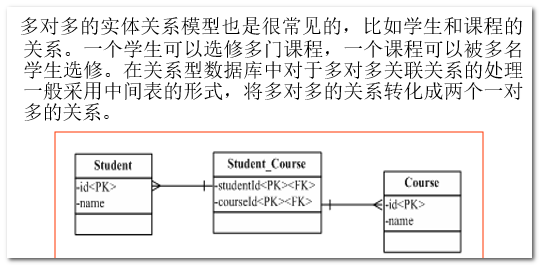
学生和课程 是经典 多对多关系,学生选课是关系表数据
在多对多中,一般情况 没必要使用 cascade 级联的!!!
映射配置
【第一步】:实体类编写,创建cn.itcast.c_manytomany包,然后操作如下:
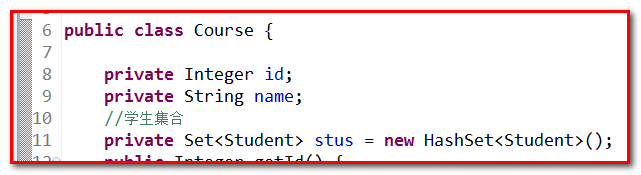
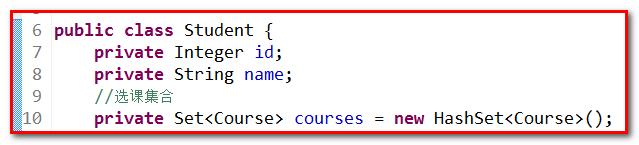
【第二步】:hbm映射文件编写
student.hbm.xml
|
<?xml <!DOCTYPE hibernate-mapping "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <class <id <generator </id> <property <!-- 配置集合 name:类中的属性 table:关系表名 --> <set <!-- 当前Student对象在关系表中的外键名字 --> <key <!-- 配置关系 class:当前的Course对应的完整的包路径 当前集合中装入的对象对应的完整的包路径 column:当前的Course对象在关系表中的外键 --> <many-to-many </set> </class> </hibernate-mapping> |
Course.hbm.xml
|
<?xml <!DOCTYPE hibernate-mapping "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <class <id <generator </id> <property <!-- 配置集合 table:配置多对多关系的时候,两边的table要一致 --> <set <key <many-to-many </set> </class> </hibernate-mapping> |
【第三步】:核心配置中添加映射
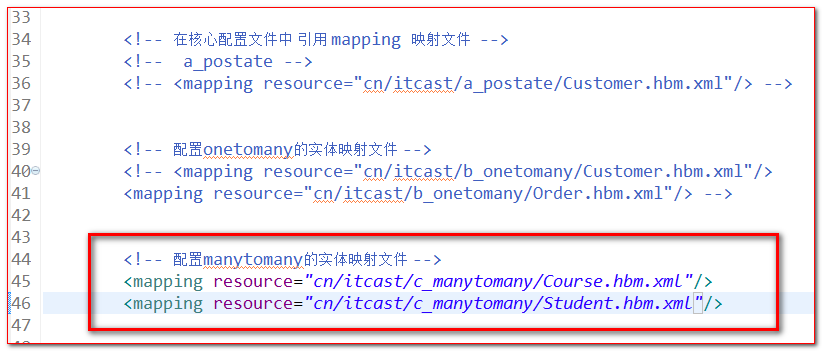
【第四步】:建表测试
建表完成之后,查看建表语句:

映射图解
图解:

只要是多对一的标签,都配置自己在对方的外键属性。
相关操作
保存操作save,同时建立关系
即保存学生和课程数据的同时,在中间选课表插入关联数据。
|
@Test public { Session session = HibernateUtils.openSession(); session.beginTransaction(); //新建一个学生 Student stu = new Student(); stu.setName("rose"); //新建课程 Course course = new Course(); course.setName("hibernate"); // /双向关联 stu.getCourses().add(course); course.getStus().add(stu); //发现抛出异常,如何解决 //1.外键维护权,一方放弃inverse="true",并且不放弃维护权的一方,加入 cascade="save-update" //2.建立关系是,只需要建立一方的关系即可,并且建立关系的一方,加入 cascade="save-update" //双向保存 session.save(course); session.save(stu); session.getTransaction().commit(); session.close(); } 错误:
|

可以采用两种方案解决问题:
第一种方案.外键维护权,一方放弃inverse="true",并且不放弃维护权的一方,加入 cascade="save-update":推荐方案
第二种方案.建立关系时,只需要建立一方的关系即可,并且建立关系的一方,加入 cascade="save-update"
第一种方案:
执行的代码:
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); //创建学生 Student s1 = new Student(); s1.setName("rose"); ///创建课程 Course c1 = new c1.setName("hibernate"); //建立双向关联关系 s1.getCourses().add(c1); c1.getStus().add(s1); //保存 // session.save(c1); // session.save(s1); //第一种方案:一方放弃外键维护权,另一方加入级联保存,未来保存的时候,在另一方进行保存操作 session.save(s1); session.getTransaction().commit(); session.close(); } |
第二种方案:第二种方案xml文件的配置直接采用第一种方案的配置,不做任何修改,此时,我们知道Student.hbm.xml中配置了
Cascade="save-update",所以接下来的测试代码如下:
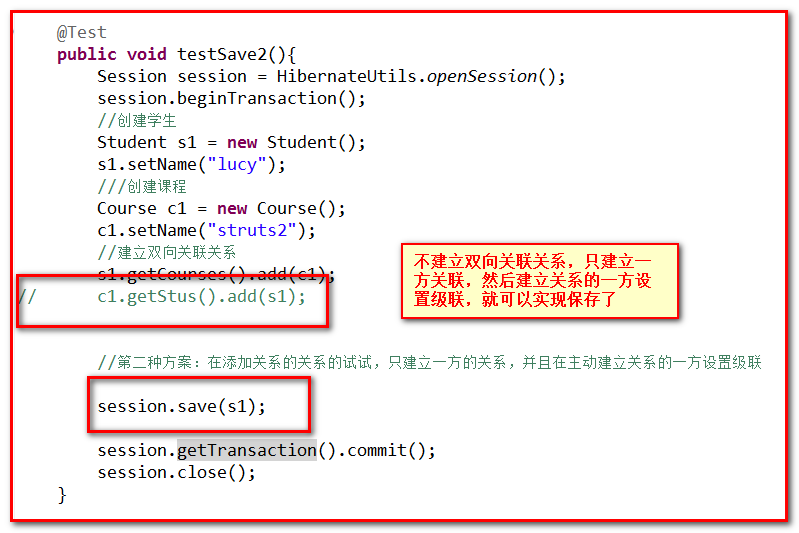
实际业务中,一般不会去级联保存,因为学生和课程是各自产生存在的.
结论:多对多模型中,一次创建关系,对应中间表 一条insert语句 !不需要双方发生关系。
在实际业务中,要么是在一方建立关系,要么是如果两方都建立关系,就配置inverse,让一方主动放弃维护权。
我们推荐一方放弃维护权
解除关系
两个对象解除关系就是删除中间表的关系数据,即将两个对象解除关系。删除的时候,对象必须是持久态对象
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); Student student = (Student) session.get(Student.class, 3); Course course = (Course) session.get(Course.class, 3); //注意:由于course放弃了对集合的维护权,所以此时只能在Student这一方进行集合操作 student.getCourses().remove(course); //不需要手动的删除,直接使用快照的更新功能,commit会隐式的flush session.getTransaction().commit(); session.close(); } |
语句问题:查看语句。
改变关系:必须是持久态的对象
变更选课内容,原来选的语文,改为选数学
----- hibernate 无法生成update语句 (只能由我们自己先delete,后insert—先解除关系,再增加关系 )
分析:假如能update,你要update中间表,但中间表无法通过实体操作。
插入测试数据,-
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); //让2号学生选修3号课程 Student student = (Student) session.get(Student.class, 2); Course course = (Course) session.get(Course.class, 2); //解除关系 student.getCourses().remove(course); //查找3号课程 Course course2 = (Course) session.get(Course.class, 3); //添加关系 student.getCourses().add(course2); //flush session.getTransaction().commit(); session.close(); } |
删除实体:持久态对象
多对多的删除!!!!!!!!!!
一定不能级联删除!!!!!!!
删除学生的时候,Hibernate会自动删除关系表(中间表)的数据(无需级联)
|
@Test public Session session = HibernateUtils.openSession(); session.beginTransaction(); Student stu = (Student)session.get(Student.class, 2); //删除 session.delete(stu); //flush session.getTransaction().commit(); session.close(); } |
注意: 多对多不建议使用 级联 (delete 级联),造成数据丢失 !!!!!!!(如果两边都配置级联,会两边删除,造成表被清空)
测试一下:(实际业务中是不存在的!!3个学生对应3个课程,创建9个关系,随便删除哪个对象,数据直接被置空)
在课程或者学生方配置级联


如果在学生方面配置了级联,那么当删除持久态的学生对象时,会将对应的课程也同时删除掉了!从而造成数据丢失!(删除脱管的不会,因为脱管态对级联不起作用)
(课后尝试多对多的级联删除)
小结+重点
复习:
1 能够说出PO对象三状态
2 理解session一级缓存(能够存储数据)
3 理解快照(用来更新数据的)
4 get和load的区别
5 掌握一对多的配置
6 掌握一对多的CRUD操作
7 掌握多对多的配置
8 掌握对多对的CRUD操作
学会debug,多用debug
作业
【作业一】
完成全天课程练习。
【作业二】
完成课前资料中的:《hibernate知识点作业练习》文档中的练习。
Hibernate3 第二天的更多相关文章
- Spring3 整合Hibernate3.5 动态切换SessionFactory (切换数据库方言)
一.缘由 上一篇文章Spring3.3 整合 Hibernate3.MyBatis3.2 配置多数据源/动态切换数据源 方法介绍到了怎么样在Sping.MyBatis.Hibernate整合的应用中动 ...
- Hibernate3的DetachedCriteria支持
Hibernate3支持DetachedCriteria,这是一个非常有意义的特性!我们知道,在常规的Web编程中,有大量的动态条件查询,即用户在网页上面自由选择某些条件,程序根据用户的选择条件,动态 ...
- Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1.8整合例子(附完整的请假流程例子,jbpm基础,常见问题解决)
Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1.8 整合例子(附完整的请假流程例子). 1.jbpm4.4 测试环境搭建 2.Jbpm4.4+hibernat ...
- [转]Hibernate3如何解决n+1 selects
摘自: http://blog.chinaunix.net/uid-20586655-id-287959.html Hibernate3中取得多层数据的所产生的n+1 selects问题的解决 ...
- Spring4.0整合Hibernate3 .6
转载自:http://greatwqs.iteye.com/blog/1044271 6.5 Spring整合Hibernate 时至今日,可能极少有J2EE应用会直接以JDBC方式进行持久层访问. ...
- SSH综合练习-仓库管理系统-第二天
SSH综合练习-仓库管理系统-第二天 今天的主要内容: 货物入库 页面信息自动补全回显功能:(学习目标:练习Ajax交互) 根据货物简记码来自动查询回显已有货物(Ajax回显) 根据货物名来自动查询补 ...
- Spring第二天
Spring第二天 整体课程安排(3天+2天): 第一天:Spring框架入门.IoC控制反转的配置管理.Spring Web集成.Spring Junit集成. 第二天:Spring AOP面向切面 ...
- Hibernate3 第四天
Hibernate3 第四天 [第一天]三个准备七个步骤 [第二天]一级缓存.一级缓存快照.一对多和多对多配置 [第三天内容回顾] 1.各种查询 对象导航查询:配置信息不能出错, 根据OID查询:ge ...
- Hibernate3 第三天
Hibernate3 第三天 第一天:三个准备.七个步骤 第二天:一级缓存.快照.多对多和一对多的配置 学习内容: Hibernate的查询详解(各种检索(fetch)对象的方式) 1)条件查询分类( ...
随机推荐
- QT Creater与libusb使用
新建一个C项目,然后修改.pro文件,添加LIBS一行 TEMPLATE = app CONFIG += console CONFIG -= app_bundle CONFIG -= qt LIBS ...
- javascript 学习总结(二)Array数组
1.数组常用方法 var colors = ["red", "blue", "green"]; //creates an array wit ...
- Android项目----AsyncTask异步操作
public abstract class AsyncTask extends Object java.lang.Object ↳ android.os.AsyncTask<Params, ...
- SQL数据库面试题
SQL数据库面试题 1.SQL SREVER中,向一个表中插入了新数据,如何快捷的得到自增量字段的当前值 这种情况其实我们经常用到,比如我们新建了一个用户,建立完用户后我们希望马上得到这个新用户的ID ...
- every、some、filter、map、forEach 方法的区别总结
API功能描述: [every]:Boolean 遍历数组并执行回调,如果每个数组元素都能通过回调函数的测试则返回true,否则返回false.一旦返回false,将立即终止循环. [some]:Bo ...
- [转]【Android】9-patch图片以及例子说明
1.何为9-patch? NinePatch图片以*.9.png结尾,和普通图片(png图片)的区别是四周多了一个边框(如下图所示): 采用NinePatch图片做背景,可使背景随着内容的拉伸(缩小) ...
- Bootstrap导航悬浮顶部,stickUp
stickUp 一个 jQuery 插件 这是一个简单的jQuery插件,它能让页面目标元素 “固定” 在浏览器窗口的顶部,即便页面在滚动,目标元素仍然能出现在设定的位置.此插件可以在多页面的网站上工 ...
- C++一些注意点之转换操作符
转换操作符定义 类可通过一个实参调用的非explicit构造函数定义一个隐式转换(其他类型—>类类型).当提供了实参类型的对象而需要一个类类型的对象时,编译器将使用该转换.这种构造函数定义了到类 ...
- DLL文件的引用
首先我们先要写一个DLL文件: 我先创建一个win32的DLL工程,在工程中添加了Math.h和Math.cpp文件,具体内容如下: Math.h: #pragma once #include &qu ...
- 【转】jQuery each函数中的continue及break
continue :return true; break :return false; 也可以利用return即可跳出jQuery 来源:http://bie.xiaowangge.info/brow ...