基于docker快速搭建hbase集群
一、概述
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。

Hadoop生太圈
通过Hadoop生态圈,可以看到HBase的身影,可见HBase在Hadoop的生态圈是扮演这一个重要的角色那就是 实时、分布式、高维数据 的数据存储;
HBase简介
- HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、 实时读写的分布式数据库
- 利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理 HBase中的海量数据,利用Zookeeper作为其分布式协同服务
- 主要用来存储非结构化和半结构化的松散数据(列存NoSQL数据库)
HBase数据模型

以关系型数据的思维下会感觉,上面的表格是一个5列4行的数据表格,但是在HBase中这种理解是错误的,其实在HBase中上面的表格只是一行数据;
Row Key:
– 决定一行数据的唯一标识
– RowKey是按照字典顺序排序的。
– Row key最多只能存储64k的字节数据。
Column Family列族(CF1、CF2、CF3) & qualifier列:
– HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema) 定义的一部分预先给出。如create ‘test’, ‘course’;
– 列名以列族作为前缀,每个“列族”都可以有多个列成员(column,每个列族中可以存放几千~上千万个列);如 CF1:q1, CF2:qw,
新的列族成员(列)可以随后按需、动态加入,Family下面可以有多个Qualifier,所以可以简单的理解为,HBase中的列是二级列,
也就是说Family是第一级列,Qualifier是第二级列。两个是父子关系。
– 权限控制、存储以及调优都是在列族层面进行的;
– HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
– 目前为止HBase的列族能能够很好处理最多不超过3个列族。
Timestamp时间戳:
– 在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间 戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,
最新的数据版本排在最前面。
– 时间戳的类型是64位整型。
– 时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫 秒的当前系统时间。
– 时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突, 就必须自己生成具有唯一性的时间戳。
Cell单元格:
– 由行和列的坐标交叉决定;
– 单元格是有版本的(由时间戳来作为版本);
– 单元格的内容是未解析的字节数组(Byte[]),cell中的数据是没有类型的,全部是字节码形式存贮。
• 由{row key,column(=<family> +<qualifier>),version}唯一确定的单元。
HBase体系架构
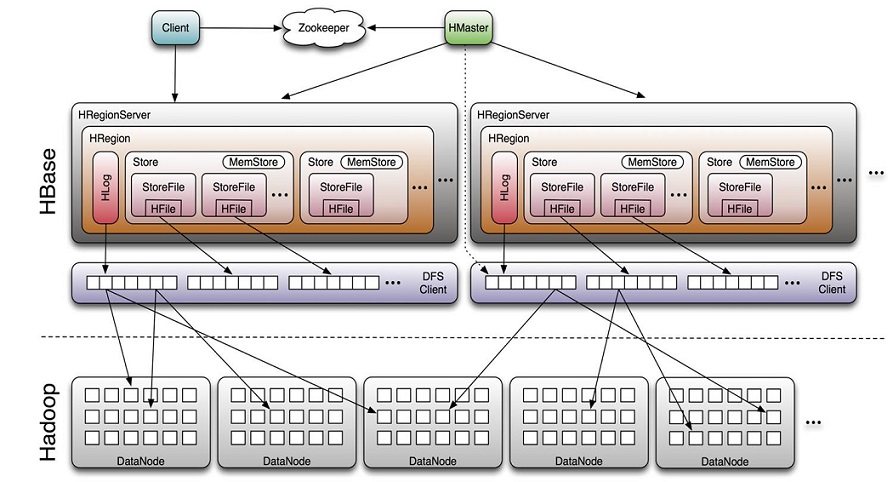
Client
• 包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
• 保证任何时候,集群中只有一个master
• 存贮所有Region的寻址入口。
• 实时监控Region server的上线和下线信息。并实时通知Master
• 存储HBase的schema和table元数据
Master
• 为Region server分配region
• 负责Region server的负载均衡
• 发现失效的Region server并重新分配其上的region
• 管理用户对table的增删改操作
RegionServer
• Region server维护region,处理对这些region的IO请求
• Region server负责切分在运行过程中变得过大的region
HLog(WAL log):
– HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是 HLogKey对象,HLogKey中记录了写入数据的归属信息,
除了table和 region名字外,同时还包括sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,
或者是最近一次存入文件系 统中sequence number。
– HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的 KeyValue
Region
– HBase自动把表水平划分成多个区域(region),每个region会保存一个表 里面某段连续的数据;每个表一开始只有一个region,随着数据不断插 入表,
region不断增大,当增大到一个阀值的时候,region就会等分会 两个新的region(裂变);
– 当table中的行不断增多,就会有越来越多的region。这样一张完整的表 被保存在多个Regionserver上。
Memstore 与 storefile
– 一个region由多个store组成,一个store对应一个CF(列族)
– store包括位于内存中的memstore和位于磁盘的storefile写操作先写入 memstore,当memstore中的数据达到某个阈值,
hregionserver会启动 flashcache进程写入storefile,每次写入形成单独的一个storefile
– 当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、 major compaction),在合并过程中会进行版本合并和删除工作 (majar),
形成更大的storefile。
– 当一个region所有storefile的大小和超过一定阈值后,会把当前的region 分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡。
– 客户端检索数据,先在memstore找,找不到再找storefile
– HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表 示不同的HRegion可以分布在不同的HRegion server上。
– HRegion由一个或者多个Store组成,每个store保存一个columns family。
– 每个Strore又由一个memStore和0至多个StoreFile组成。
如图:StoreFile 以HFile格式保存在HDFS上。

二、docker部署
环境说明
| 操作系统 | docker版本 | ip地址 | 配置 |
| centos 7.6 | 19.03.12 | 192.168.31.229 | 4核8g |
软件版本
| 软件 | 版本 |
| openjdk | java-8-openjdk-amd64 |
| hadoop | 2.9.2 |
| hbase | 1.3.6 |
| zookeeper | 3.4.14 |
说明:openjdk直接用apt-get 在线安装,其他软件从官网下载即可。
目录结构
cd /opt/
git clone https://github.com/py3study/hadoop-hbase.git
/opt/hadoop-hbase 目录结构如下:
./
├── config
│ ├── core-site.xml
│ ├── hadoop-env.sh
│ ├── hbase-env.sh
│ ├── hbase-site.xml
│ ├── hdfs-site.xml
│ ├── mapred-site.xml
│ ├── regionservers
│ ├── run-wordcount.sh
│ ├── slaves
│ ├── ssh_config
│ ├── start-hadoop.sh
│ ├── yarn-site.xml
│ └── zoo.cfg
├── Dockerfile
├── hadoop-2.9.2.tar.gz
├── hbase-1.3.6-bin.tar.gz
├── README.md
├── run.sh
├── sources.list
├── start-container1.sh
├── start-container2.sh
└── zookeeper-3.4.14.tar.gz
由于软件包比较大,需要使用迅雷下载,下载地址如下:
https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
https://mirror.bit.edu.cn/apache/hbase/hbase-1.3.6/hbase-1.3.6-bin.tar.gz
https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
构建镜像
docker build -t hadoop-hbase:1 .
创建数据目录
mkdir -p /data/hadoop-cluster/master/ /data/hadoop-cluster/slave{1,2}/
创建网桥
docker network create hadoop
运行镜像
cd /opt/hadoop-hbase
bash start-container1.sh
拷贝hdfs文件到宿主机目录
docker cp hadoop-master:/root/hdfs /data/hadoop-cluster/master/
docker cp hadoop-slave1:/root/hdfs /data/hadoop-cluster/slave1/
docker cp hadoop-slave2:/root/hdfs /data/hadoop-cluster/slave2/
拷贝zookeeper文件到宿主机目录
docker cp hadoop-master:/usr/local/zookeeper/data /data/hadoop-cluster/master/zookeeper
docker cp hadoop-slave1:/usr/local/zookeeper/data /data/hadoop-cluster/slave1/zookeeper
docker cp hadoop-slave2:/usr/local/zookeeper/data /data/hadoop-cluster/slave2/zookeeper
使用第2个脚本,挂载宿主机目录,运行镜像
bash start-container2.sh
开启hadoop
启动hadoop集群
bash start-hadoop.sh
注意:这一步会ssh连接到每一个节点,确保ssh信任是正常的。
Hadoop的启动速度取决于机器性能
运行wordcount
先等待1分钟,再执行命令:
bash run-wordcount.sh
此脚本会连接到fdfs,并生成几个测试文件。
运行结果:
...
input file1.txt:
Hello Hadoop input file2.txt:
Hello Docker wordcount output:
Docker 1
Hadoop 1
Hello 2
wordcount的执行速度取决于机器性能
关闭安全模式
执行命令:
hadoop dfsadmin -safemode leave
启动hbase
/usr/local/hbase/bin/start-hbase.sh
注意:等待3分钟,因为启动要一定的时间。
进入hbase shell
/usr/local/hbase/bin/hbase shell
三、HBase的Shell命令
查看列表
hbase(main):001:0> list
TABLE
users
users_tmp
2 row(s) in 0.2370 seconds
如果出现
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
说明hbase集群还没有启动好,需要等待一段时间。
创建表
hbase(main):002:0> create 'users','user_id','address','info'
0 row(s) in 4.6300 seconds => Hbase::Table - users
添加记录
hbase(main):002:0> put 'users','xiaoming','info:birthday','1987-06-17'
0 row(s) in 0.1910 seconds
获取记录
取得一个id的所有数据
hbase(main):003:0> get 'users','xiaoming'
COLUMN CELL
info:birthday timestamp=1594003730408, value=1987-06-17
1 row(s) in 0.0710 seconds
更新记录
hbase(main):004:0> put 'users','xiaoming','info:age' ,''
0 row(s) in 0.0150 seconds hbase(main):005:0> get 'users','xiaoming','info:age'
COLUMN CELL
info:age timestamp=1594003806409, value=
1 row(s) in 0.0170 seconds
获取单元格数据的版本数据
hbase(main):006:0> get 'users','xiaoming',{COLUMN=>'info:age',VERSIONS=>1}
COLUMN CELL
info:age timestamp=1594003806409, value=
1 row(s) in 0.0040 seconds
全表扫描
hbase(main):007:0> scan 'users'
ROW COLUMN+CELL
xiaoming column=info:age, timestamp=1594003806409, value=
xiaoming column=info:birthday, timestamp=1594003730408, value=1987-06-17
1 row(s) in 0.0340 seconds
删除
删除xiaoming值的'info:age'字段:
hbase(main):008:0> delete 'users','xiaoming','info:age'
0 row(s) in 0.0340 seconds hbase(main):009:0> get 'users','xiaoming'
COLUMN CELL
info:birthday timestamp=1594003730408, value=1987-06-17
1 row(s) in 0.0110 seconds
删除整行
hbase(main):010:0> deleteall 'users','xiaoming'
0 row(s) in 0.0170 seconds
统计表的行数
hbase(main):011:0> count 'users'
0 row(s) in 0.0260 seconds
清空表:
hbase(main):012:0> truncate 'users'
Truncating 'users' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 4.2520 seconds
四、web服务验证
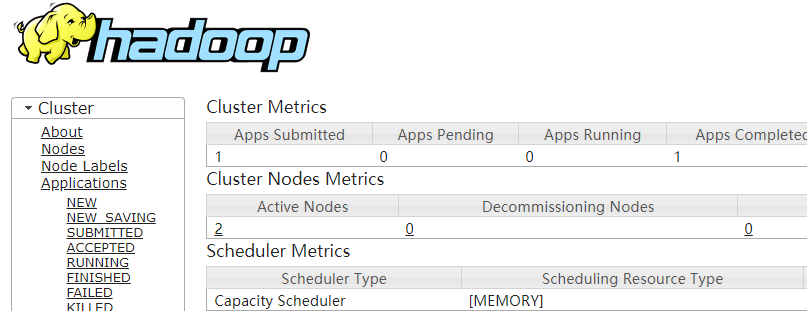
hadoop管理页面
http://ip地址:8088/
效果如下:

hdfs 管理页面
http://ip地址:50070/
效果如下:

hbase 管理页面
http://ip地址:16010/
效果如下:
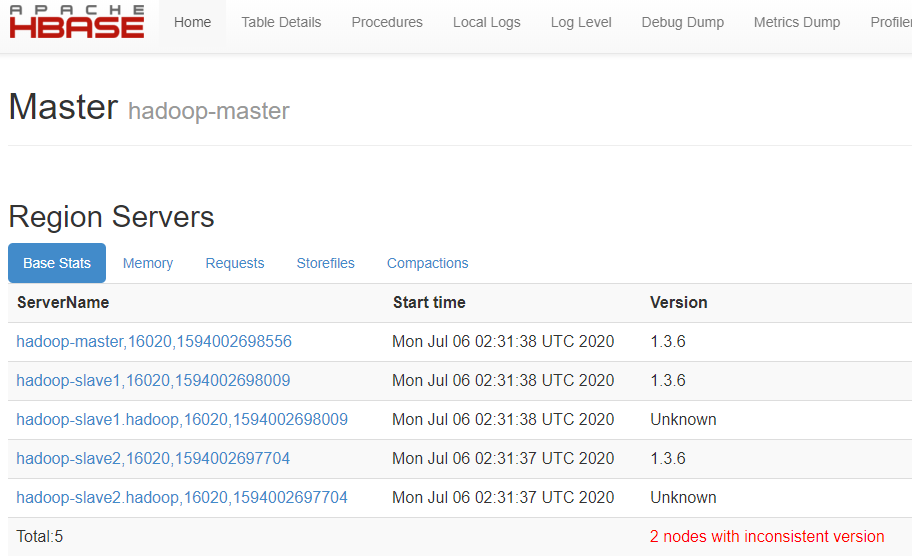
注意:这里出现的 2 nodes with inconsistent version,不用理会,不影响正常运行。
参考链接:https://developer.aliyun.com/ask/136178?spm=a2c6h.13159736
本文参考链接:
https://www.cnblogs.com/raphael5200/p/5229164.html
https://blog.csdn.net/qq_32440951/article/details/80803729
https://www.jianshu.com/p/a1524dccb1e4
https://www.bbsmax.com/A/6pdDLqOGdw/
基于docker快速搭建hbase集群的更多相关文章
- 用 Docker 快速搭建 Kafka 集群
开源Linux 一个执着于技术的公众号 版本 •JDK 14•Zookeeper•Kafka 安装 Zookeeper 和 Kafka Kafka 依赖 Zookeeper,所以我们需要在安装 Kaf ...
- Docker快速构建Redis集群(cluster)
Docker快速构建Redis集群(cluster) 以所有redis实例运行在同一台宿主机上为例子 搭建步骤 redis集群目录清单 . ├── Dockerfile ├── make_master ...
- 快速搭建Jenkins集群
关于Jenkins集群 在Jenkins上同时执行多个任务时,单机性能可能达到瓶颈,使用Jenkins集群可以有效的解决此问题,让多台机器同时处理这些任务可以将压力分散,对单机版Jenkins的单点故 ...
- 庐山真面目之十微服务架构 Net Core 基于 Docker 容器部署 Nginx 集群
庐山真面目之十微服务架构 Net Core 基于 Docker 容器部署 Nginx 集群 一.简介 前面的两篇文章,我们已经介绍了Net Core项目基于Docker容器部署在Linux服 ...
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- 使用 Ansible 快速部署 HBase 集群
背景 出于数据安全的考虑,自研了一个低成本的时序数据存储系统,用于存储历史行情数据. 系统借鉴了 InfluxDB 的列存与压缩策略,并基于 HBase 实现了海量存储能力. 由于运维同事缺乏 Had ...
- 基于HDInsight 3.4 HBase集群规划参考
基于linux 创建HDInsight HBase集群,选择最小配置,zk(3).NN(2).WN(2),集群节点默认组件服务规划如下 NN0: Active NameNode /HDFS ZKFai ...
- VMware 克隆linux后找不到eth0(学习hadoop,所以想快速搭建一个集群)
发生情况: 由于在学习hadoop,所以想快速搭建一个集群出来.所以直接在windows操作系统上用VMware安装了CentOS操作系统,配置好hadoop开发环境后,采用克隆功能,直接克 ...
- centos7 快速搭建redis集群环境
本文主要是记录一下快速搭建redis集群环境的方式. 环境简介:centos 7 + redis-3.2.4 本次用两个服务6个节点来搭建:192.168.116.120 和 192.168.1 ...
随机推荐
- 2019 ccpc秦皇岛
1006 (dfs) #include <bits/stdc++.h> using namespace std; const int inf = 0x3f3f3f3f; const dou ...
- Testing Beta Round (Unrated)
比赛链接:https://codeforces.com/contest/1390 A. 123-sequence 题意 给出一个只含有 $1,2,3$ 的数组,问使所有元素相同至少要替换多少元素. 题 ...
- Codeforces Round #622 (Div. 2) A. Fast Food Restaurant(全排列,DFS)
Codeforces Round #622 (Div. 2) A. Fast Food Restaurant 题意: 你是餐馆老板,虽然只会做三道菜,上菜时还有个怪癖:一位客人至少上一道菜,且一种菜最 ...
- Educational Codeforces Round 88 (Rated for Div. 2) C. Mixing Water(数学/二分)
题目链接:https://codeforces.com/contest/1359/problem/C 题意 热水温度为 $h$,冷水温度为 $c\ (c < h)$,依次轮流取等杯的热冷水,问二 ...
- Codeforces Round #529 (Div. 3) F. Make It Connected (贪心,最小生成树)
题意:给你\(n\)个点,每个点都有权值,现在要在这\(n\)个点中连一颗最小树,每两个点连一条边的边权为两个点的点权,现在还另外给了你几条边和边权,求最小权重. 题解:对于刚开始所给的\(n\)个点 ...
- C# TCP应用编程二 同步TCP应用编程
不论是多么复杂的TCP 应用程序,双方通信的最基本前提就是客户端要先和服务器端进行TCP 连接,然后才可以在此基础上相互收发数据.由于服务器需要对多个客户端同时服务,因此程序相对复杂一些.在服务器端, ...
- Rsyncd 同步服务
目录 数据备份的策略 三种数据备份 三种数据备份的比较(转载) 不同数据备份类型组合说明(转载) Rsyncd 服务传输模式(remote synchronizetion deamon) 本地传输模式 ...
- (转载)RTMP协议中的AMF数据 http://blog.csdn.net/yeyumin89/article/details/7932585
为梦飞翔 (转载)RTMP协议中的AMF数据 http://blog.csdn.net/yeyumin89/article/details/7932585 这里有一个连接,amf0和amf3的库, ...
- 在利用手背扫描图像+K因子 对室内温度进行回归预测时碰到的问题
1. 关于多输入流: 由于本Mission是双输入, 导师要求尽量能使用Inception之诸, 于是输入便成了问题. 思考: 在Github上找到了keras-inceptionV4进行对网络头尾的 ...
- Tensorflow+InternalError: Blas GEMM launch failed
[参考1:]https://stackoverflow.com/questions/37337728/tensorflow-internalerror-blas-sgemm-launch-failed ...