Kubernetes Pod OOM 排查日记
一、发现问题
在一次系统上线后,我们发现某几个节点在长时间运行后会出现内存持续飙升的问题,导致的结果就是Kubernetes集群的这个节点会把所在的Pod进行驱逐OOM;如果调度到同样问题的节点上,也会出现Pod一直起不来的问题。我们尝试了杀死Pod后手动调度的办法(label),当然也可以排除调度节点。但是在一段时间后还会复现,我们通过监控系统也排查了这段时间的流量情况,但应该和内存持续占用没有关联,这时我们意识到这可能是程序的问题。
二、现象-内存居高不下
发现个别业务服务内存占用触发告警,通过 Grafana 查看在没有什么流量的情况下,内存占用量依然拉平,没有打算下降的样子:
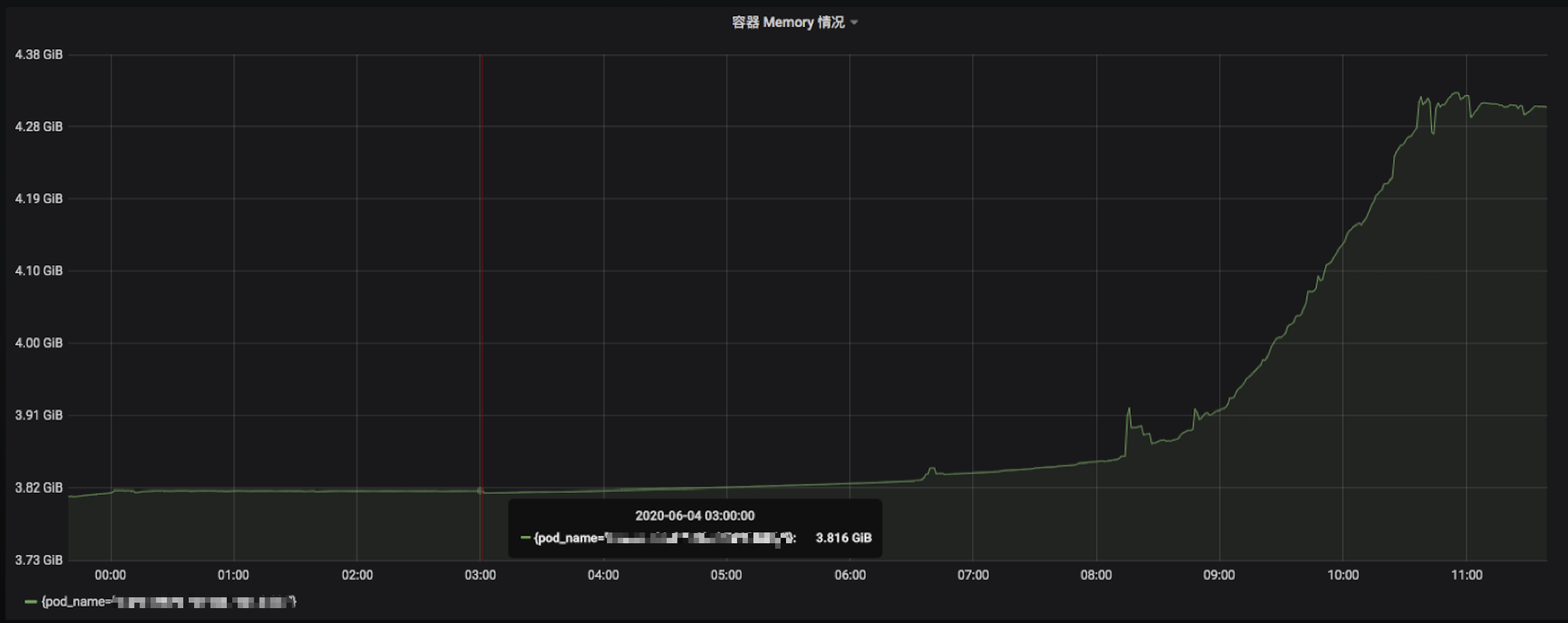
并且观测的这些服务,早年还只是 100MB。现在随着业务迭代和上升,目前已经稳步 4GB,容器限额 Limits 纷纷给它开道,但我想总不能是无休止的增加资源吧,这是一个很大的问题。
三、Pod频繁重启
有的业务服务,业务量小,自然也就没有调整容器限额,因此得不到内存资源,又超过额度,就会进入疯狂的重启怪圈:

重启将近 200 次,告警通知已经爆炸!
四、排查
猜想一:频繁申请重复对象
出现问题服务的业务特点,那就是基本为图片处理类的功能,例如:图片解压缩、批量生成二维码、PDF 生成等,因此就怀疑是否在量大时频繁申请重复对象,而程序本身又没有及时释放内存,因此导致持续占用。
内存池
想解决频繁申请重复对象,可以用最常见的 sync.Pool
当多个 goroutine 都需要创建同⼀个对象的时候,如果 goroutine 数过多,导致对象的创建数⽬剧增,进⽽导致 GC 压⼒增大。形成 “并发⼤-占⽤内存⼤-GC 缓慢-处理并发能⼒降低-并发更⼤”这样的恶性循环。
场景验证
在描述中关注到几个关键字,分别是并发大,Goroutine 数过多,GC 压力增大,GC 缓慢。也就是需要满足上述几个硬性条件,才可以认为是符合猜想的。
通过拉取 PProf goroutine,可得知 Goroutine 数并不高:

没有什么流量的情况下,也不符合并发大,Goroutine 数过多的情况,若要更进一步确认,可通过 Grafana 落实其量的高低。
从结论上来讲,我认为与其没有特别直接的关系,但猜想其所对应的业务功能到导致的间接关系应当存在。
猜想二:未知的内存泄露
内存居高不下,其中一个反应就是猜测是否存在泄露,而我们的容器中目前只跑着一个进程:

显然其提示的内存使用不高,也不像进程内存泄露的问题,因此也将其排除。
猜想三:容器环境的机制
既然不是业务代码影响,也不是GC影响,那是否与环境本身有关呢,我们可以得知容器 OOM 的判别标准是 container_memory_working_set_bytes(当前工作集)。
而 container_memory_working_set_bytes 是由 cadvisor 提供的,对应下述指标:

从结论上来讲,Memory 换算过来是 4GB+,石锤。接下来的问题就是 Memory 是怎么计算出来的呢,显然和 RSS 不对标。
原因
从 cadvisor/issues/638 可得知 container_memory_working_set_bytes 指标的组成实际上是 RSS + Cache。而 Cache 高的情况,常见于进程有大量文件 IO,占用 Cache 可能就会比较高,猜测也与 Go 版本、Linux 内核版本的 Cache 释放、回收方式有较大关系。

出问题的常见功能,如:
- 批量图片解压缩。
- 批量二维码生成。
- 批量上传渲染后图片。
解决方案
在本场景中 cadvisor 所提供的判别标准 container_memory_working_set_bytes 是不可变更的,也就是无法把判别标准改为 RSS,因此我们只能考虑掌握主动权。
开发角度
使用类 sync.Pool 做多级内存池管理,防止申请到 “不合适”的内存空间,常见的例子: ioutil.ReadAll:
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
…
for {
if free := cap(b.buf) - len(b.buf); free < MinRead {
newBuf := b.buf
if b.off+free < MinRead {
newBuf = makeSlice(2*cap(b.buf) + MinRead) // 扩充双倍空间
copy(newBuf, b.buf[b.off:])
}
}
}
}
核心是做好做多级内存池管理,因为使用多级内存池,就会预先定义多个 Pool,比如大小 100,200,300的 Pool 池,当你要 150 的时候,分配200,就可以避免部分的内存碎片和内存碎块。
但从另外一个角度来看这存在着一定的难度,因为你怎么知道什么时候在哪个集群上会突然出现这类型的服务,何况开发人员的预期情况参差不齐,写多级内存池写出 BUG 也是有可能的。
让业务服务无限重启,也是不现实的,被动重启,没有控制,且告警,存在风险。
运维角度
可以使用定期重启的常用套路。可以在部署环境可以配合脚本做 HPA,当容器内存指标超过约定限制后,起一个新的容器替换,再将原先的容器给释放掉,就可以在预期内替换且业务稳定了。
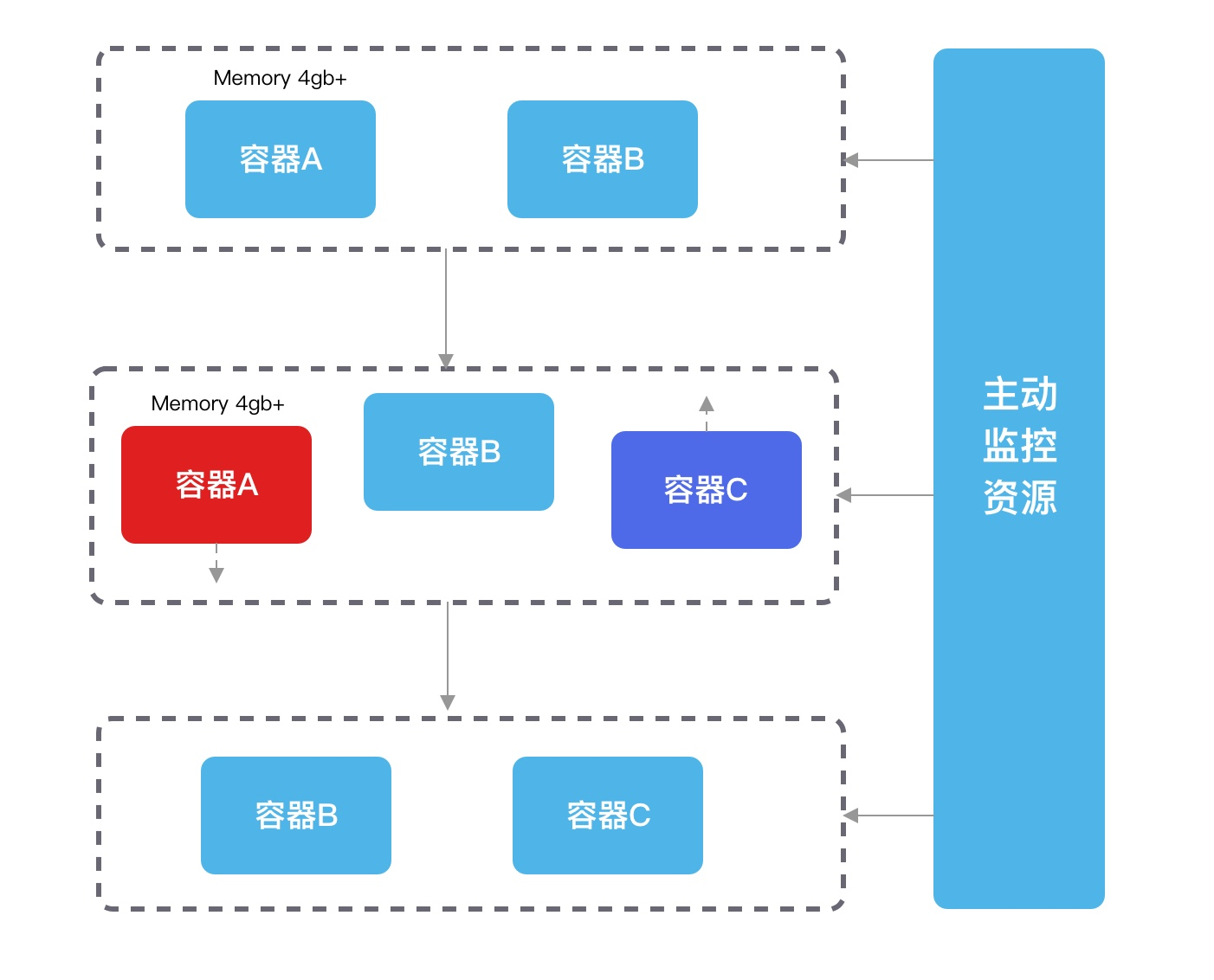
总结
根据上述排查和分析结果,原因如下:
- 应用程序行为:文件处理型服务,导致 Cache 占用高。
- Linux 内核版本:版本比较低(BUG?),不同 Cache 回收机制。
- 内存分配机制:在达到 cgroup limits 前会尝试释放,但可能内存碎片化,也可能是一次性索要太多,无法分配到足够的连续内存,最终导致 cgroup oom。
从根本上来讲,应用程序需要去优化其内存使用和分配策略,又或是将其抽离为独立的特殊服务去处理。并不能以目前这样简单未经多级内存池控制的方式去使用,否则会导致内存使用量越来越大。
而从服务提供的角度来讲,我们并不知道这类服务会在什么地方出现又何时会成长起来,因此我们需要主动去控制容器的 OOM,让其实现优雅退出,保证业务稳定和可控。
最后
最近在写基于Golang的工具和框架,还请多多Star.
YoyoGo 是一个用 Go 编写的简单,轻便,快速的 微服务框架,目前已实现了Web框架的能力,但是底层设计已支持多种服务架构。
Github
https://github.com/yoyofx/yoyogo
https://github.com/yoyofxteam
Kubernetes Pod OOM 排查日记的更多相关文章
- 使用describe命令进行Kubernetes pod错误排查
我有一个pod名叫another,用kubectl create创建后发现过了29分钟,状态还是处于ContainerCreating阶段. 使用kubectl describe命令检查: 从错误消息 ...
- Kubernetes Pod故障归类与排查方法
Pod概念 Pod是kubernetes集群中最小的部署和管理的基本单元,协同寻址,协同调度. Pod是一个或多个容器的集合,是一个或一组服务(进程)的抽象集合. Pod中可以共享网络和存储(可以简单 ...
- Kubernetes Pod 驱逐详解
原文链接:Kubernetes Pod 驱逐详解 在 Kubernetes 中,Pod 使用的资源最重要的是 CPU.内存和磁盘 IO,这些资源可以被分为可压缩资源(CPU)和不可压缩资源(内存,磁盘 ...
- 99% 的人都不知道的 Kubernetes 网络疑难杂症排查方法
原文链接:Kubernetes 网络疑难杂症排查分享 大家好,我是 roc,来自腾讯云容器服务 (TKE) 团队,经常帮助用户解决各种 K8S 的疑难杂症,积累了比较丰富的经验,本文分享几个比较复杂的 ...
- 【转】又一次线上 OOM 排查经过
又一次线上OOM排查经过 最近线上一个服务又出现了频繁Full GC的情况,导致提供的业务经常超时.问题出现非常不稳定,经过两周的时候,终于又捕捉到了一次Full GC,于是联系运维做Heap Dum ...
- Kubernetes Pod 镜像拉取策略
Kubernetes Pod 镜像拉取策略 官方文档:https://kubernetes.io/docs/concepts/containers/images/ • IfNotPresent:默认值 ...
- Kubernetes Pod 资源限制
Kubernetes Pod 资源限制 官方文档:https://kubernetes.io/docs/concepts/configuration/manage-compute-resources- ...
- Kubernetes Pod 调度约束
Kubernetes Pod 调度约束 可以将pod调度到指定的节点Node内 默认:根据节点资源利用率等分配Node节点. nodeName用于将Pod调度到指定的Node名称上 nodeSelec ...
- Python Django撸个WebSSH操作Kubernetes Pod(下)- 终端窗口自适应Resize
追求完美不服输的我,一直在与各种问题斗争的路上痛并快乐着 上一篇文章Django实现WebSSH操作Kubernetes Pod最后留了个问题没有解决,那就是terminal内容窗口的大小没有办法调整 ...
随机推荐
- 《利用Python进行数据分析》自学知识图谱-导航
项目简介 Project Brief <利用Python进行数据分析-第二版>自学过程中整理的知识图谱. Python for Data Analysis: Data Wrangling ...
- C++ 线性筛素数
今天要写一篇亲民的博客了,尽力帮助一下那些不会线性筛素数或者突然忘记线性筛素数的大佬. 众所周知,一个素数的倍数肯定不是素数(废话).所以我们可以找到一个方法,普通的筛法(其实不算筛,普通的是判断一个 ...
- 【week1错题集】
day9[2.f] # day9 题2.f ''' 有如下文件,t1.txt,里面的内容为: 葫芦娃,葫芦娃, 一根藤上七个瓜 风吹雨打,都不怕, 啦啦啦啦. 以r模式打开文件,从‘风吹雨打..... ...
- WPF入门教程(一)---基础
这篇主要讲WPF的开发基础,介绍了如何使用Visual Studio 2013创建一个WPF应用程序. 首先说一下学习WPF的基础知识: 1) 要会一门.NET所支持的编程语言.例如C#. 2) 会一 ...
- .net core 拦截socket
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Net ...
- Statezhong shiyong redux props
在构造方法中使用props给state赋值不允许, 原因需要检查
- Spring葵花宝典
一 Spring简介 Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架 为了解决企业应用开发的复杂性而创建 二 Spring功能 1. 方便解耦 简化开发 Spring就是一 ...
- layui在odoo12上的应用,用widget覆盖原字段视图
layui是一个前端框架,提供了许多前端的组件等,layui的详情自己官网地址:https://www.layui.com/doc/去查看 下面说一下最近用layui遇到的问题和解决方式: 问题:近期 ...
- odoo12的视图常见属性和操作
1.菜单视图属性: 常用属性: name是展示在用户界面中的菜单项标题 action是点击菜单项时运行的窗口操作的XML ID parent是父级菜单项的XML ID.本例中父级项由其它模块创建,因此 ...
- linux的PS进程和作业管理(进程调度,杀死进程和进程故障-僵尸进程-内存泄漏)
Ps进程和作业管理 1.查看进程ps 1.格式 ps ---查看当前终端下的进程 3种格式: SYSV格式 带 - 符号 BSD格式 不带 - 符号 GNU格式 长选项 2.ps -a ...